HDF5格式多群截面数据库AXELIB的加工与验证
2021-02-10张乐瑞梁钊毓佘顶石磊
张乐瑞, 梁钊毓, 佘顶, 石磊
(1.清华大学 核能与新能源技术研究院,北京 100084; 2.清华大学 先进核能技术协同创新中心,北京 100084; 3.清华大学 先进反应堆工程与安全教育部重点实验室,北京 100084)
多群截面数据库是核反应堆物理输运计算和燃耗计算的基础,可提供物理计算过程中用到的所有核数据信息,包括核素的基本物理信息、核反应截面信息和燃耗相关信息等。评价核数据库需要进行处理加工才能得到物理程序直接使用的多群截面数据库。现在世界上使用较为广泛的评价核数据库是由美国国家核数据中心管理下的截面评价工作组制作发布,并由国家核数据中心进行维护的ENDF/B库[1]。评价数据库加工软件中使用较为广泛的是美国洛斯·阿拉莫斯国家实验室开发的NJOY软件[2]。NJOY将ENDF格式的核数据转化为可供各种计算机程序使用的数据库格式的核数据处理系统,采用模块化程序结构来生成点截面或多群截面数据。大多数反应堆物理计算程序都有其专用的多群截面数据库。使用较为广泛的WIMS库为栅格物理程序WIMS提供多群截面数据[2],国际原子能机构组织的国际合作项目WIMS库更新计划负责对WIMS库进行更新[3]。DRAGON库是给栅格物理程序DRAGON[4]提供核数据的多群截面库[5]。DRAGON库采用的自动化的加工系统PyNjoy2012[6-7]来实现数据库的自动加工。此外,还有一些物理软件采用的是MATXS格式转换得到的多群截面数据库[8-11]。现有的多群截面数据库采用文本格式和二进制格式。数据库采用的文本格式,用户虽能直接看到库中的具体核数据,但是该格式占用空间大,计算机读取速度缓慢。二进制格式的数据库读取速度快占用空间小,克服了文本格式的缺点,但是用户无法直接查看库中的核数据。综合现有的2种数据库格式的优缺点,可以考虑研制基于分层数据结构(hierarchical data format version 5,HDF5)[12]的多群截面数据库。HDF5由美国伊利诺伊大学厄巴纳-香槟分校开发,用于存储和管理数据,支持无限种数据类型,是可移植和扩展的,可实现高效地输入输出高容量和复杂的数据。HDF5格式既能保持二进制格式占用空间小,计算机读取速度快的优点,还能便于用户快速查看某一特定的核数据信息。
本文基于核数据处理软件NJOY2016开发了新的核数据后处理模块AXER来生成HDF5格式的多群截面数据库AXELIB,从多群截面库的加工和数值验证分析2个方面进行讨论。
1 多群截面数据库的加工
1.1 AXELIB的加工流程和方法
图1所示为多群截面库AXELIB的加工流程。ENDF-6格式的评价核数据库ENDF/B经过核数据库加工软件NJOY中相应模块:MODER、RECONR、BROADR、UNRESR、THERMR和GROUPR分别进行格式转化,共振重造和线性化,多普勒展宽,不可分辨共振能区处理,热化处理和分群处理得到GENDF格式的多群数据库,其后通过自主开发的后处理模块AXER对GENDF格式的截面数据和ENDF-6格式的燃耗数据进行加工得到最终的HDF5格式多群截面数据库AXELIB。
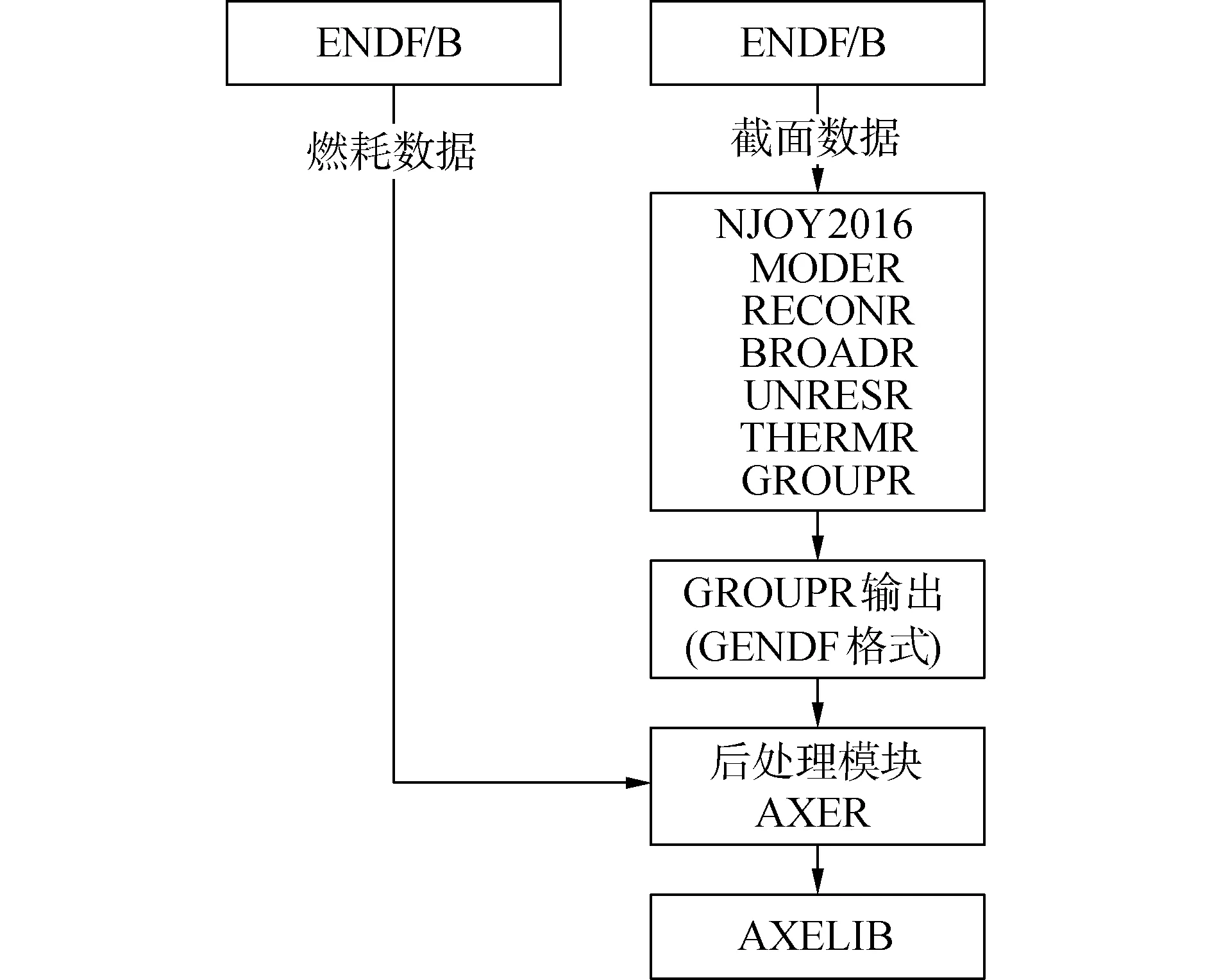
图1 AXELIB加工流程Fig.1 Flow chart of AXELIB generation
在整个加工流程中,后处理模块AXER的功能主要有3点:1)对GENDF文件中的截面数据进行再次加工;2)对衰变和裂变产额相关的评价核数据库进行提取加工得到燃耗数据库;3)生成尽可能保留核数据信息格的HDF5格式化的数据库。
NJOY产生的GENDF格式文件中的核数据缺少裂变相关的数据χg和νσf,在AXER模块中裂变相关数据为[8,13]:
(1)
(2)
(3)
式中,χg、χd,g、χi,d,g、σf,g′→g、σf,g、νg、νd,g和φg分别表示裂变谱、缓发中子裂变谱、按寿命分组的第i组缓发中子裂变谱、裂变矩阵、裂变截面、每次裂变释放的中子数、每次裂变释放的缓发中子数和加权通量。
在AXER模块中散射矩阵为:
σscat,g′→g=σdiffusion,g′→g+σn2n,g′→g+σn3n,g′→g
(4)
式中:σscat,g′→g、σdiffusion,g′→g、σn2n,g′→g和σn3n,g′→g分别表示散射矩阵、扩散矩阵、(n,2n)反应矩阵和(n,3n)反应矩阵。需要说明的是,在非热能区,扩散矩阵为散射核静止的散射矩阵;在热能区,扩散矩阵为散射核热运动的热散射矩阵。
此外,AXER会对GENDF格式文件中的热能区总截面数据进行修正,减去总截面中散射核静止的散射截面,加上散射核处于热运动时的热散射截面。除了对GENDF格式文件中的核数据进行处理外,AXER同时还能对评价数据库中的衰变和裂变产额数据进行提取,加工得到压缩的燃耗数据库。AXER采用一种基于半衰期和裂变产额定量化分析的方法[7]产生压缩燃耗库,该方法已被应用于产生DRAGLIB中的燃耗链数据,其可靠性已经得到了充分的验证。该压缩方法的基本思路是将精细燃耗链中半衰期短且裂变产额小的核素进行合并压缩。制定的精细燃耗库中核素的合并标准是半衰期小于30 d且裂变产额小于0.01%。
1.2 AXELIB的自动化加工方法
加工好的数据库中包含几百种核素,每一个核素都需要有相应的NJOY输入和输出卡片,为了实现数据库的自动化加工,本文基于已有的PyNjoy2012系统[6-7]开发了PyNjoy2016系统。该系统的优点是只需要设置必要的参数便可以产生NJOY输入卡片,同时能够自动调用NJOY进行数据库的加工。此外,该系统保留了加工过程中所有核素的PENDF格式和GENDF格式的输出文件和NJOY输入输出卡片,避免了当设定的数据库参数改变时的重复加工。
图2所示为PyNjoy2016系统的自动化加工流程图。图中Python输入卡中包含加工需要的各种参数(温度、本底截面、能群结构等),该输入卡调用PyNjoy脚本PyNjoy.py中的self.pendf(),self.gendf(),self.axelib()和self.burnupAXE()函数以产生NJOY的输入卡片,同时执行NJOY2016,并在特定的目录下产生PENDF、GENDF文件和AXELIB数据库。
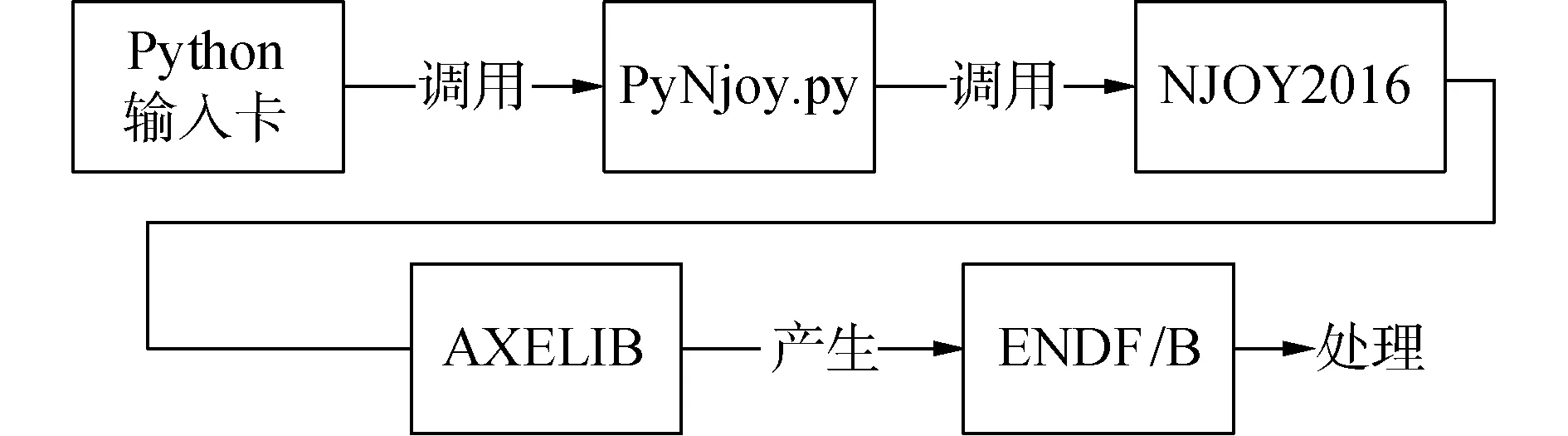
图2 AXELIB自动加工系统PyNjoy2016的加工流程Fig.2 The generation flow of AXELIB automated generation system PyNjoy2016
如图3为PyNjoy脚本PyNjoy.py中各函数的功能,其中self.pendf()函数将评价数据库加工得到PENDF格式文件,self.gendf()函数将PENDF格式文件加工得到GENDF格式文件,self.axelib()函数将GENDF格式文件加工得到AXELIB。如需加工压缩燃耗数据库则需要调用self.burnupAXE()函数。
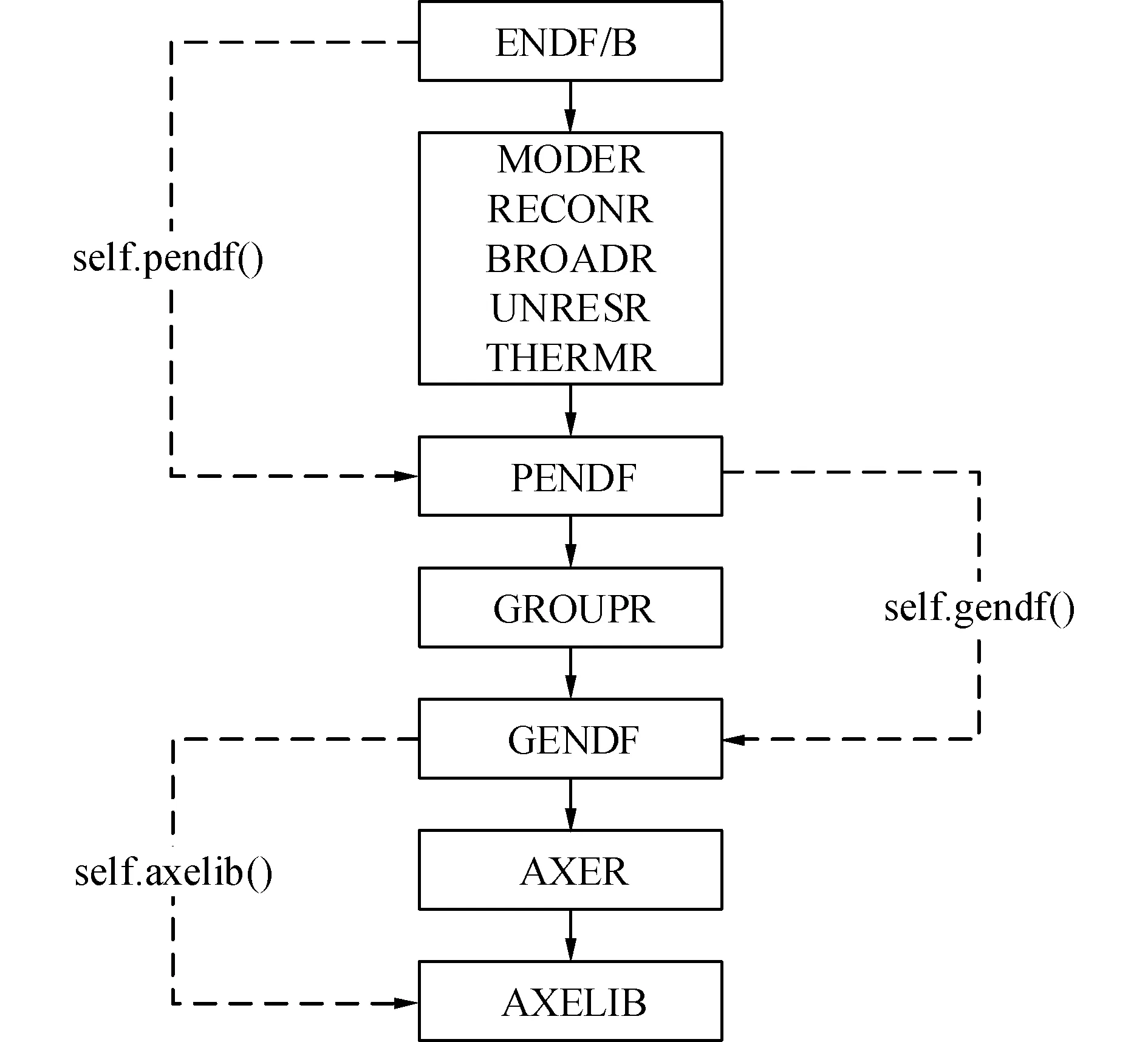
图3 PyNjoy脚本中各函数功能Fig.3 Functions of PyNjoy.py
1.3 AXELIB的格式和特点
AXELIB多群截面数据库包含了2个HDF5格式文件:NUCLIDES.h5(核素文件)和DEPLETION.h5(燃耗文件)。其中截面等相关核数据存储在NUCLIDES.h5文件中;裂变产额和衰变等相关燃耗数据存储在DEPLETION.h5文件中。
NUCLIDES.h5文件采用3层循环的树状结构来存储核数据。3层循环由外到内分别为核素循环、温度循环和本底截面循环。
DEPLETION.h5文件中将所有核素分为子核和母核2大类,以此描述了不同核素间的转换关系。表1所示为DEPLETION.h5文件中存储的具体燃耗信息。
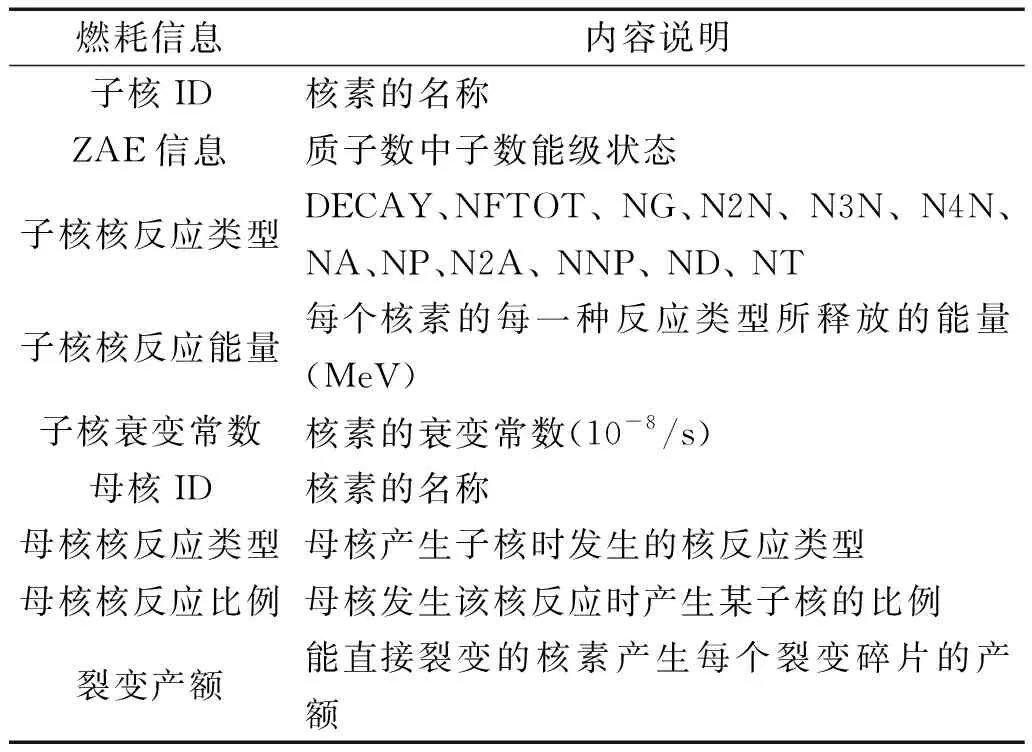
表1 DEPLETION.h5文件的内容Table 1 Contents of DELETION.h5
最终加工得到的AXELIB多群截面数据库的特点如表2所示。

表2 加工得到的AXELIB的特点Table 2 The processed AXELIB characteristics
2 AXELIB数值验证和分析
2.1 数值验证
为了验证加工流程和方法的可靠性和最后加工出的多群截面数据库AXELIB的准确性,本文针对高温气冷堆HTR-10的真实燃料球[14-15]进行了临界计算和燃耗计算并对计算结果进行了分析。HTR-10燃料球半径为3 cm,其中半径2.5 cm的区域为TRISO包覆颗粒随机弥散分布的燃料区,其余部分为石墨壳。图4和图5分别给出了HTR-10燃料球和TRISO包覆颗粒模型示意图。
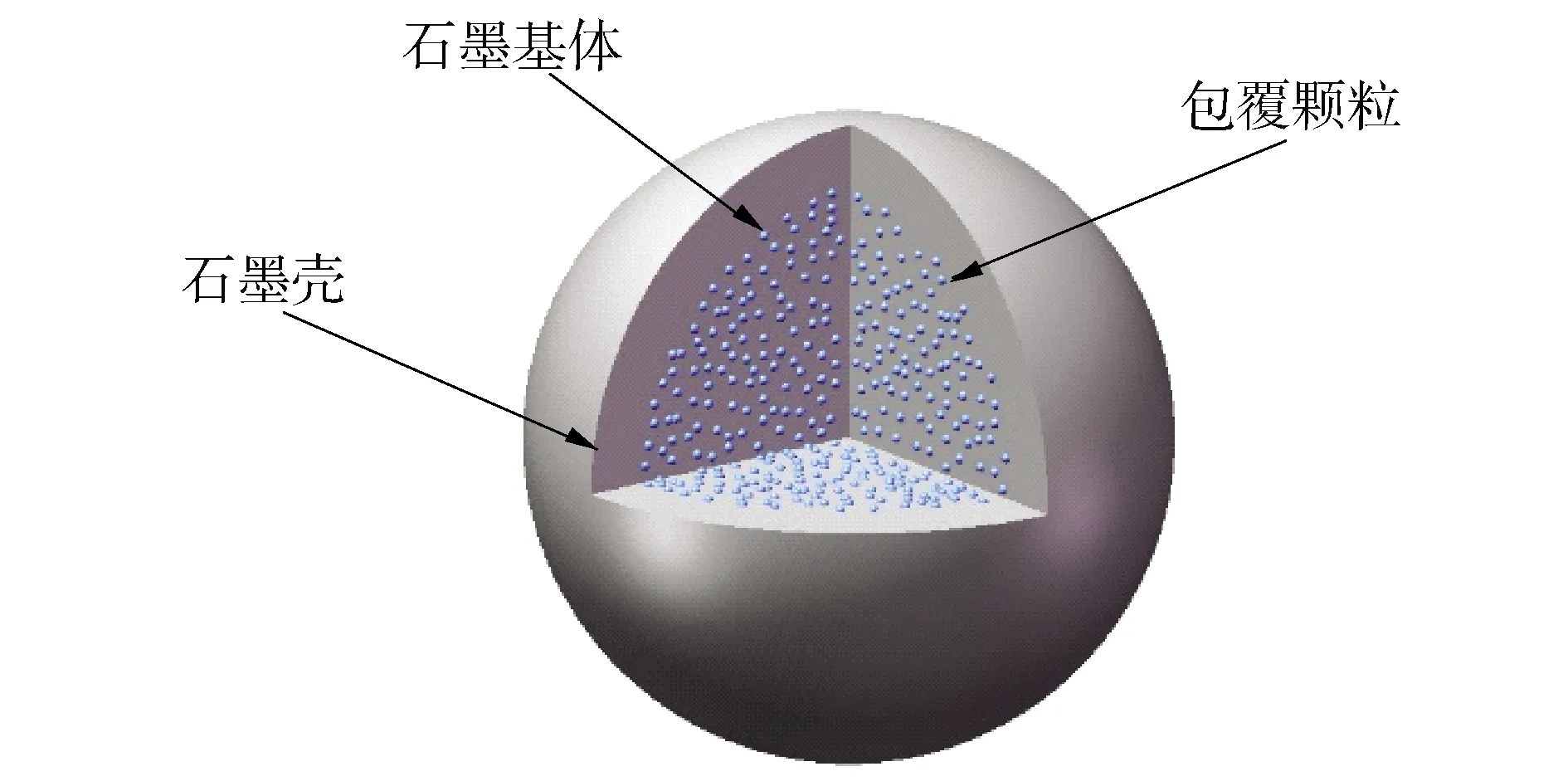
图4 HTR-10燃料球Fig.4 HTR-10 fuel ball
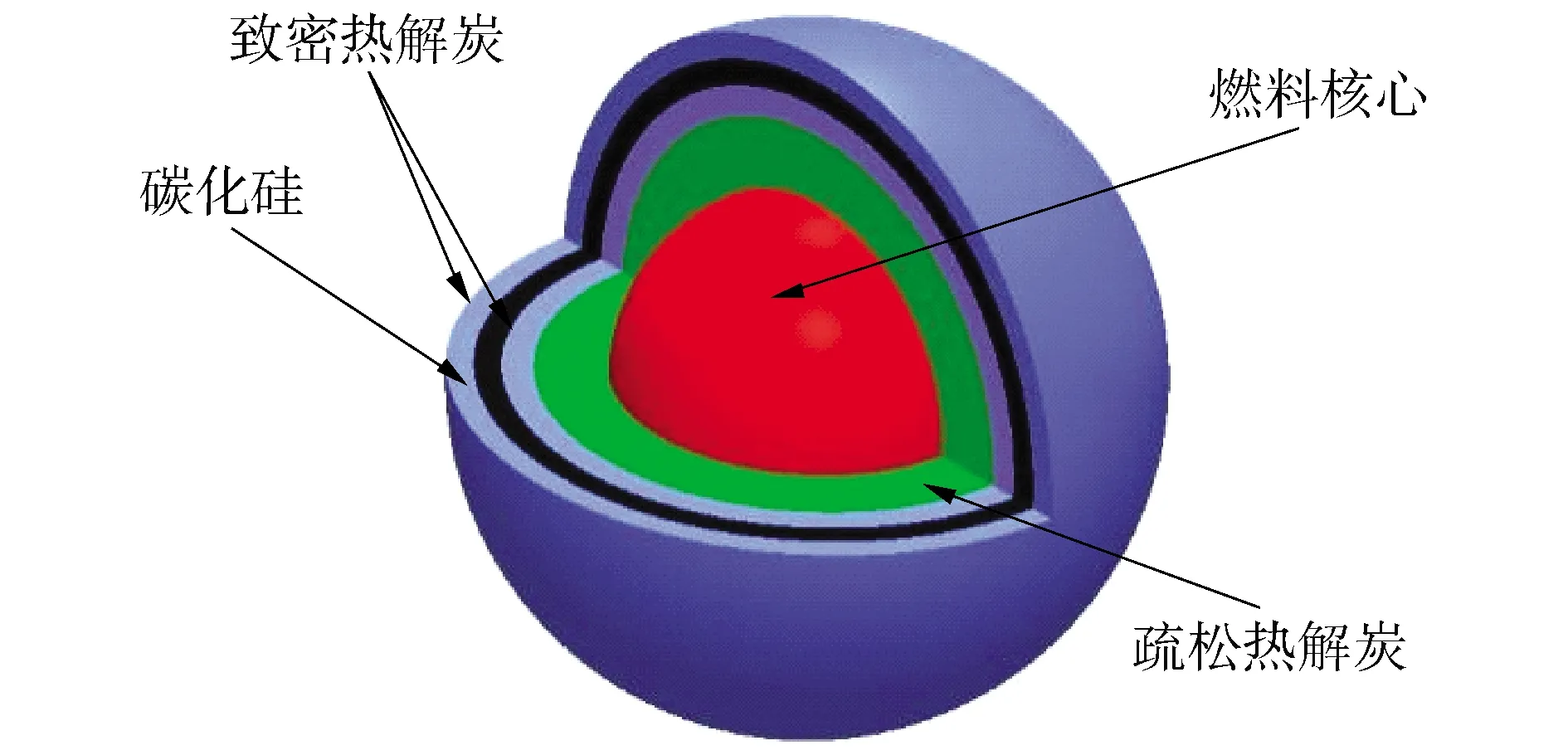
图5 HTR-10燃料球的TRISO包覆颗粒Fig.5 TRISO coated particle in HTR-10 fuel ball
表3和表4分别给出了燃料球和包覆颗粒的计算参数。

表3 HTR-10燃料球的基本参数Table 3 HTR-10 fuel ball characteristics
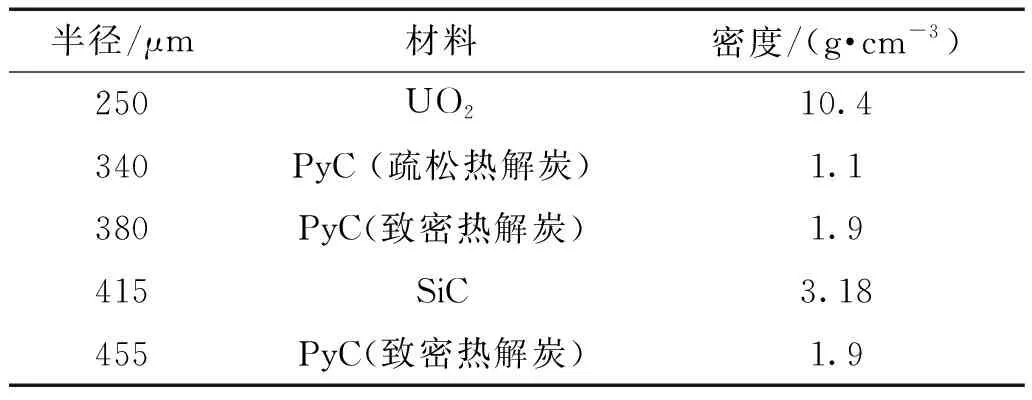
表4 TRISO包覆颗粒的基本参数Table 4 TRISO coated particle characteristics
计算过程中用到的栅格物理程序是清华大学核能与新能源技术研究院自主开发的高温堆栅格物理程序XPZ[16],同时将麻省理工学院开发的蒙特卡罗程序OpenMC[17]的计算结果用作参考解。栅格物理计算程序XPZ可用于高温堆燃料元件的输运计算和燃耗计算,生成堆芯扩散或输运计算所需要的均匀化群常数库。XPZ采用等价理论进行共振处理;采用改进的双重非均匀性计算模型与方法对随机介质进行均匀化处理;采用碰撞概率法和矩阵指数法来分别求解输运方程和燃耗方程。HTR-10真实燃料球的临界计算结果1.681 39,与OpenMC的计算结果1.682 03相比XPZ的结果偏小64×10-5。
除keff数据外,本文还对比分析了XPZ和OpenMC计算得到的中子能谱和有效截面。图6所示为燃料核心区域的中子能谱,可以看出XPZ和OpenMC的能谱在整个能区内都符合得较好,尤其是共振能区,在热能区和快区有较小差别。图7所示为238U的辐射俘获有效截面,XPZ和OpenMC计算得到的有效截面的最大相对偏差在15%以内。
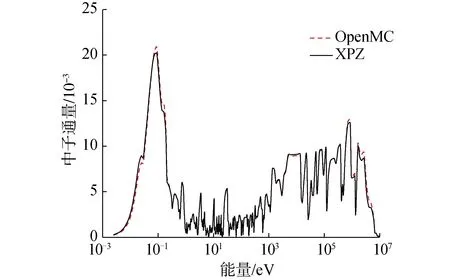
图6 燃料核心的中子能谱Fig.6 Neutron spectrum in kernel
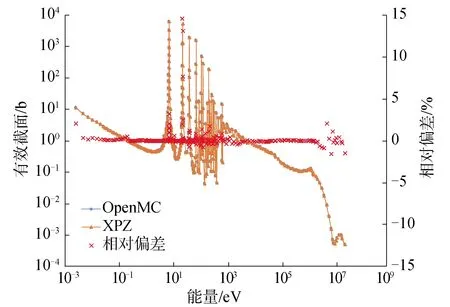
图7 238U辐射俘获有效截面Fig.7 238U radioactive capture effective cross sections
改变燃料球中TRISO颗粒的填充率,可以得到如表5所示的不同填充率下的HTR-10燃料球临界计算结果。在填充率5%~30%内,XPZ与OpenMC的计算结果的偏差都在200×10-5以内,是一个可以接受的范围。可以发现在低填充率时,XPZ的计算结果相对于OpenMC偏小;在高填充率,XPZ的结果相对于OpenMC偏大。
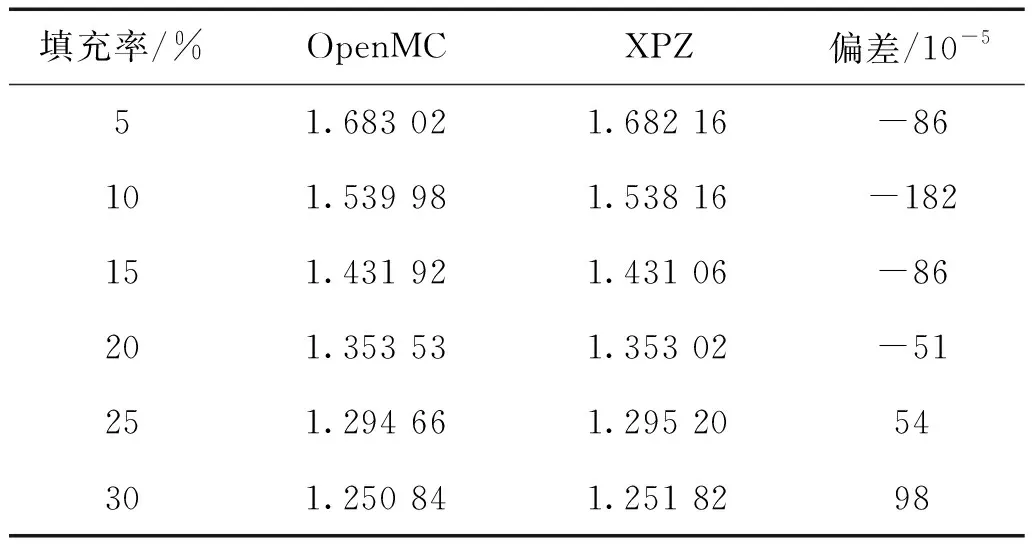
表5 不同填充率的HTR-10燃料球临界计算结果Table 5 HTR-10 fuel ball critical calculation results at different filling ratios
改变燃料球中235U的富集度,可以得到如表6所示的不同富集度下的HTR-10燃料球临界计算结果。在富集度从0.75%~20%内,XPZ的计算结果都比与OpenMC的结果偏小,所有偏差都在250×10-5以内,是一个可以接受的范围。在低富集度时,XPZ的计算结果与OpenMC的结果偏差较大,随着富集度的增大,二者的偏差变小。
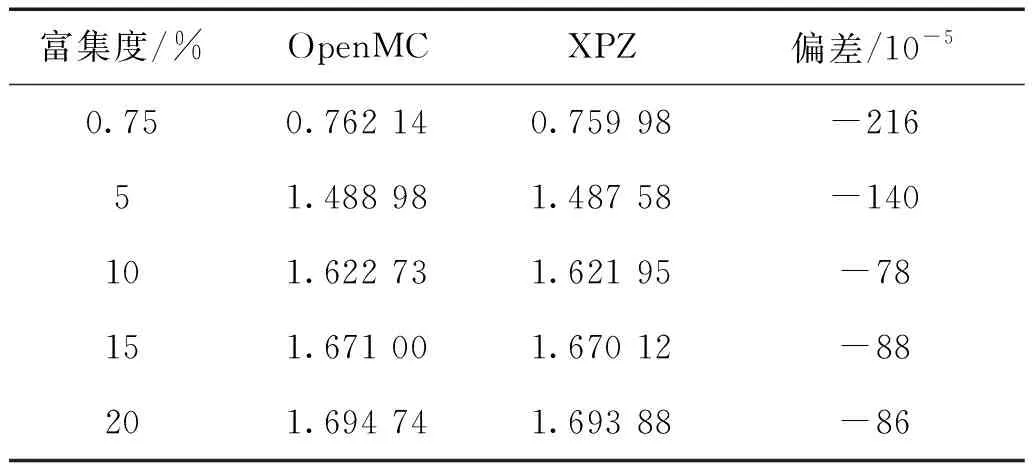
表6 不同富集度的HTR-10燃料球临界计算结果Table 6 HTR-10 fuel ball critical calculation results at different enrichments
临界计算的结果表明了AXELIB中重要核素核数据的可靠性,为了进一步检验AXELIB全部核素核数据尤其是燃耗数据的准确性,本文对HTR-10真实燃料球进行了燃耗计算,设置的功率密度为74.074 W/g。图8所示为燃耗计算结果,在每个燃耗步下,XPZ与OpenMC的计算结果间的偏差都在300×10-5以内,最大的偏差是出现在燃耗末期的256×10-5。燃耗计算的结果进一步表明了核数据库加工方法的可靠性和由此加工得到的HDF5格式的多群截面数据库AXELIB的准确性。
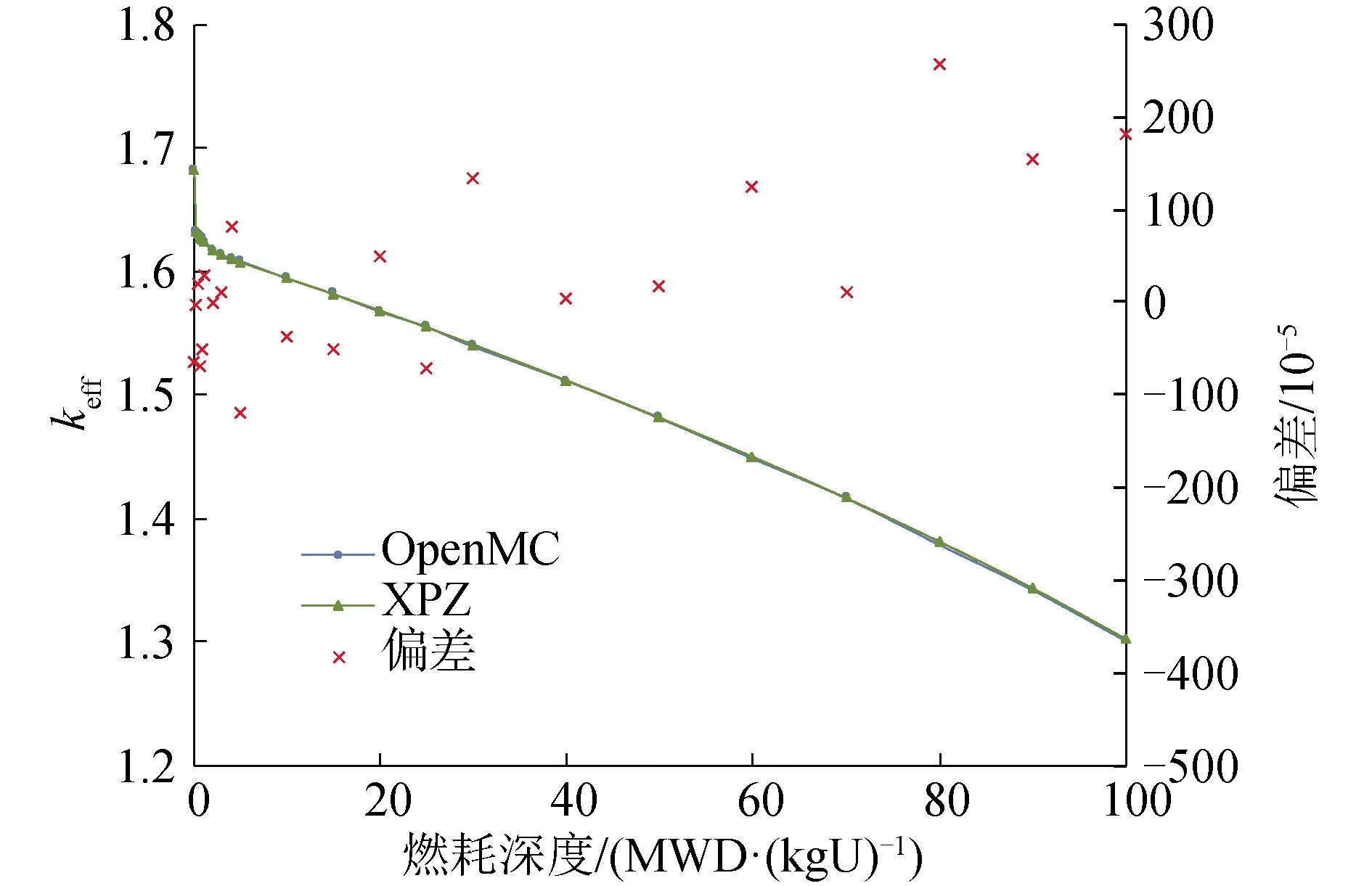
图8 HTR-10真实燃料球燃耗计算结果Fig.8 HTR-10 realistic fuel ball burnup calculation results
2.2 评价数据库版本对于计算结果的影响
本文基于不同的评价数据库ENDF/B-VII.0、ENDF/B-VII.1、ENDF/B-VIII.0加工得到相应的多群截面数据库AXELIB,将其用于HTR-10燃料球的临界和燃耗计算中以研究评价数据库版本对计算结果的影响。在研究过程中将基于ENDF/B-VII.0库的XPZ计算结果作为比较基准。真实HTR-10 燃料球基于不同评价库版本的临界计算结果,可以看出基于ENDF/B-VII.0库的XPZ计算结果1.691 94与ENDF/B-VII.1和ENDF/B-VIII.0库的XPZ计算结果之间的偏差分别可达-578×10-5和-1 055×10-5。
表7所示为XPZ基于不同ENDF/B评价数据库版本的不同填充率的HTR-10燃料球临界计算结果,可以看出在填充率为5%时,基于ENDF/B-VII.0库与ENDF/B-VII.1库和ENDF/B-VIII.0库的XPZ计算结果之间的偏差最大,分别为-581×10-5和-1 058×10-5,随着填充率增大,计算结果的偏差逐渐变小,在填充率为30%时,偏差分别为-77×10-5和-225×10-5。
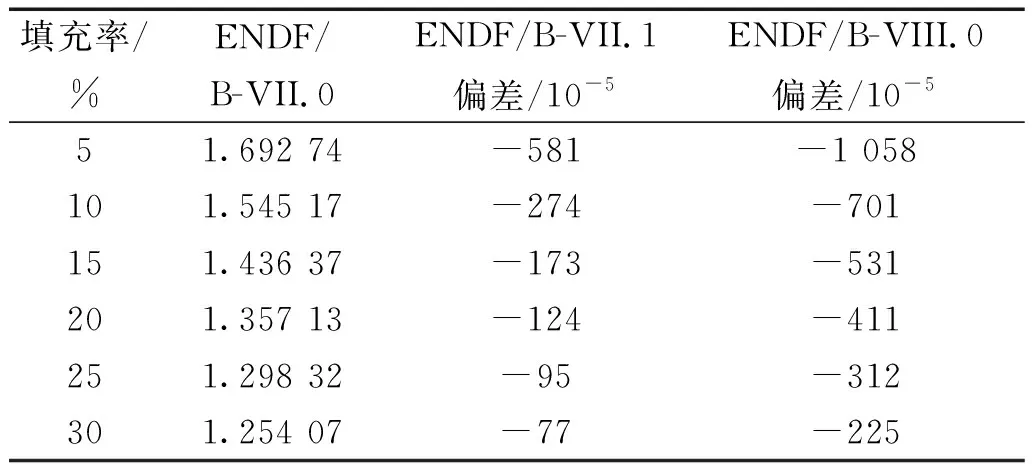
表7 基于不同ENDF/B评价数据库版本的不同填充率的HTR-10燃料球临界计算结果Table 7 HTR-10 fuel ball critical calculation results at different filling ratios based on different ENDF/B versions
表8所示为XPZ基于不同ENDF/B评价数据库版本的不同富集度的HTR-10燃料球临界计算结果,可以看出在富集度为0.75%时,基于ENDF/B-VII.0库与ENDF/B-VII.1库和ENDF/B-VIII.0库的XPZ计算结果之间的偏差最大,分别为-2 461×10-5和-2 208×10-5,随着富集度增大,计算结果的偏差逐渐变小,在富集度为20%时,偏差分别为-505×10-5和-1 041×10-5。
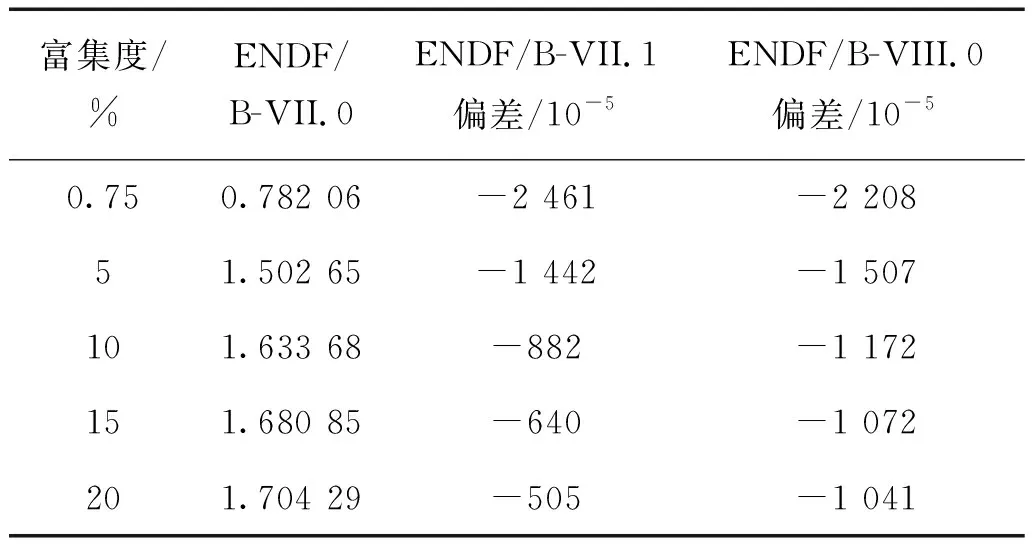
表8 基于不同ENDF/B评价数据库版本的不同富集度的HTR-10燃料球临界计算结果Table 8 HTR-10 fuel ball critical calculation results at different enrichments based on different ENDF/B
图9所示为XPZ基于不同版本评价数据库的HTR-10真实燃料球燃耗计算结果,可以看出相较于基于ENDF/B-VII.0库的计算结果,在整个燃耗范围内,基于ENDF/B-VII.1库的计算结果的相对偏差为-0.30%~-0.50%;ENDF/B-VIII.0库的相对偏差为-0.45%~-0.65%。
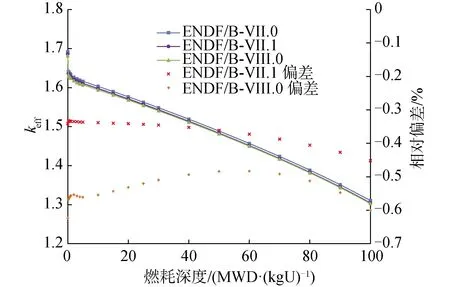
图9 基于不同ENDF/B评价数据库版本的HTR-10真实燃料球燃耗计算结果Fig.9 HTR-10 realistic fuel ball burnup calculation results based on different ENDF/B versions
由以上基于不同评价数据库版本的XPZ计算结果可知评价数据库版本对于临界计算和燃耗计算结果都会产生较大的影响,这和评价数据库中截面等核数据的更新有关。
3 结论
1)本文基于评价核数据库加工处理程序NJOY2016开发了新的核数据处理模块AXER,通过加工评价数据库ENDF/B生成了读写速度快便于用户快速进行数据查找的HDF5格式多群截面数据库AXELIB;同时开发了数据库加工系统PyNjoy2016,实现了多群数据库的自动化自动加工。
2)通过对不同算例的数值计算,验证了数据处理方法的可靠性和加工出的AXELIB的准确性。
3)研究发现了不同版本的ENDF/B评价数据库版本会对数值计算结果产生较大影响,尤其是基于VII.0库与VIII.0库的计算结果差异很大。
未来可进一步研究不同评价库版本中具体核素截面对计算结果的影响。此外,根据不同的共振处理方法的要求,可对核数据信息进行不断的完善和合理的处理修正。
