基于DSP处理器的片上ROM功耗优化实现*
2021-02-07张莹月黄嵩人
张莹月, 黄嵩人**
(1.湘潭大学 物理与光电工程学院,湖南 湘潭 411105;2.湖南进芯电子科技有限公司,长沙 410205)
随着SOC的不断发展,片上存储器的容量的不断增大,片上存储器消耗的功耗也随之增大[1]。当前,SOC芯片中片上缓存和存储器所占的面积已经超过了50%,降低片上存储器的功耗对于降低系统的功耗相当重要,存储器的功耗的优化是降低系统能耗最有前景和最有可能成功的方法。这也是未来低功耗设计的一个重要方向[2]。
1 现有的基于DSP上ROM优化方案
1.1 无优化的片上ROM设计
DSP[3-4]作为一种实时快速地实现各种数字信号运算的微处理器,其对运算能力的要求很高。由于ROM的非易失性[5-8]和可靠性,且DSP应用于手持式设备,所以用ROM来进行存储固化的bootloader,科学函数库,功能函数库以及主应用程序。如图1所示,为ROM 的代码分区功能结构图。

图1 ROM 代码分区功能结构图Fig. 1 Structure diagram of ROM code partitioning function
1.2 现有的片上ROM优化方案
图2所示的是直接整块进行访问的不足,现在提出了一种对存储器进行物理分区分组的方法来进行功耗的优化,这种分区可以通过控制电路来选择和关断不同的区,这样没有访问的区就关断,实现存储器低功耗。如图3分区结构框图所示,对存储器进行等分,将存储体分了两个区,一个区是32 k,这样,当64 k分成两个32 k时,可以进行单独访问其中的任意一个区,其中每个存储器分区都可以通过存储器分区的访问次数乘以每次的访问能耗估计到。图4所示的是其中一个区的内部结构图,把空间分成了32个块的子存储体。单对存储器而言,它的功耗来源主要是来自存储单元阵列、译码器和外围电路。一个m列n行的现代CMOS存储器的近似统一公式为:P=VDDIDD,其中,IDD=Iarray+Idecode+Iperiphery=[miact+m(n-1)ihld+[(n+m)CDEVintf]+[CPTVintf+IDCP],整体结构如图4所示,把其中一个区分成32个子模块,这么做可以把存储器的工作功耗限制在整个存储阵列的有限区域内,那么未被使用的存储器单元应当只消耗维持数据所消耗的功耗。其实这是属于底层存储器分割技术[9],通过分割,把一个位线分成几个位线,它们只在被寻址时才启动,从而降低了每一次读过程的切换电容,这样做可以使本地字线和位线的长度保持在一定的界限内,提高速度,提高访问效率和缩短寻址时间。A[14:5]是行列选择信号,A[4:0]用来选择每一个子存储体,这就是块地址,块地址只用来激活被寻址的块。未被寻址的块处于关闭状态,他们的灵敏放大器和行和列译码器都不工作,这样可以节省较多的功耗。

图2 优化前方案框图Fig. 2 The block diagram of the scheme beforeoptimization

图3 现有优化方案框图Fig. 3 Block diagram of the existing optimization scheme
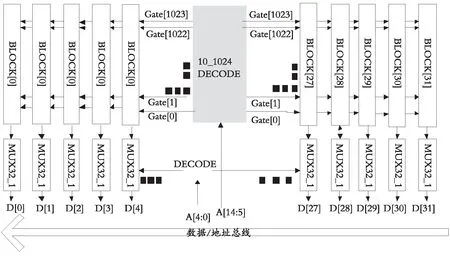
图4 区内结构框图Fig. 4 Block diagram of the structure in the area
但是这种一个区的物理分割太多,额外的逻辑电路会增多,在版图层面互联线的并行走线会很多,影响速度、延时和功耗;分区又太少,访问驱动的面积没有达到最小的效果;而且这种方式并没有考虑这些被访问的地址的频繁度,没有对地址进一步的进行改进,这样在时间分布上,对ROM进行访问时驱动的存储块的面积明显不是最优的,导致功耗的浪费。
2 改进后的基于DSP上ROM优化方案
2.1 进行重新分区进行优化
在嵌入式系统中降低存储器的功耗,主要在两个方面,一是降低访问存储器时的能耗,在数据占主导的嵌入式系统应用中是功耗预算的主要部分,二是降低DSP处理器和存储器之间的通信带宽,最小化处理器和存储器之间信息交换的能耗。至于存储器的传输优化中,优化处理器和存储器之间的带宽是一个很好的方法,它既可以降低存储器的功耗又能降低总线的功耗。方案主要是从降低访问存储器的能耗来降低功耗的。
基于上述提到的现有的分区的种种缺点,在上述现有的分区的基础上进行重新分区以及运用地址聚类的方式对其访问轮廓进行修改达到降低功耗的目的。如图5所示,把64 k等分成4个16 k的存储块,这样可以进一步减小每次驱动的面积,从而使功耗也随之降低。但是,任意小的分区是不被允许的,因为过多的小存储组会浪费大量的面积,并且严重增加线路开销,从而增加通信和执行能耗。当存储器组增加后,由于增加了复制寻址和控制的逻辑电路以及增加了传递信息的信息源,明显增大了功耗、访问时间和面积,所以寻找一个最佳分区极为重要。在本款高性能定点的DSP中的ROM,采用了等分4块组的方法进行分区,使每一块的驱动面积比之前更小,降低了功耗。不会因过多地分区,导致功耗和面积的增加,影响DSP的功耗和面积。同时也保证了DSP的性能不受影响。图6所示,是每个16 k的底层结构框图,可以看出,它被分割为32个子存储体,这样分割会减少每一读操作时切换电容。从而减小功耗,这是底层降功耗的常用方法。译码单元应紧密的搭接到存储器内核,否则就会造成布线的极大浪费,以及由此引起的延时和功耗的增加。所以在每一组的ROM中采用对称的方式把译码器放在各个子存储体的中间的位置,这样也有利于延时的优化和此存储器的功耗的降低。

图5 优化后方案框图Fig. 5 Block diagram of the optimized scheme
2.2 进行地址重组进行优化
提出了在合理分区的基础上与地址聚类技术相结合,相比于直接分区,这样的做法可以让能耗降低5%~55%。地址聚类是指重组(通过其他硬件)送给存储器的地址路径,这样可以使存储器分区的工具最大化[10]。
在DSP正常工作时会启动固化的bootloader,对科学函数库,功能函数库以及主应用程序访问频繁,在频繁访问的科学函数、功能函数中有些基函数会被更加频繁的访问,应用程序中有部分程序也被频繁调用。把这些访问次数较多的地址所映射的数据放在其中一个存储器块中,这样对于访问频繁的地址所映射的数据就可以在一个块中被访问,就不用驱动整个ROM,没访问的存储块就被关闭,这样功耗就会降低的比较可观。由于大量的访问都集中在一个小的、高能耗的存储器中,降低了ROM访问的平均热量,如图7所示,热门地址所映射的数据放在第一个和第二个存储块中,这样,第一个和第二个存储块会被更加频繁的访问,那么就会进一步地缩小频繁访问的存储空间范围,进而优化功耗。综上所述,在对ROM合理分区的基础上对地址路径的重组,使得ROM在底层的位线分割更优化从而减小了读操作的切换电容。合理分区后,对ROM进行访问时,可以禁止或者关断不访问的区块,这样访问小块能减少驱动面积从而降低功耗,同时访问小块也能缩短延时,在SOC上其中一个重要问题就是采用的是同步时钟,所以延时是一个必须要考虑的问题,这样的分区方式就保证了整个处理器的性能。再者,从处理器核和ROM之间的传输和信息交换所消耗的能量的角度来说,分块缩短了时延。在一定范围内,缩短延时能改善带宽,从而在一定程度上,降低处理器核和ROM之间传输功耗。再对其进行地址路径进行重组,把相对访问频繁的地址映射到其中某个区,可使热门地址所映射数据的访问比较集中,ROM访问的平均能量会减小从而降低功耗。

图6 优化后区内结构框图Fig. 6 Block diagram of the structure in the optimized area

图7 地址重组方案框图Fig. 7 Block diagram of address reorganization scheme
2.3 进行时钟优化后进行优化
在降低ROM功耗时显然要考虑在整个存储器分区系统中译码器和控制信号的能耗,外围电路的工作功耗的维持功耗很大,因此要把像灵敏放大器这样的电路在不工作的时候关断。
提出的分区方式就是通过额外的控制电路,进行每个区块独立译码,访问时才打开译码器,这样会降低了较多功耗。同时在嵌入式电路中外围电路的性能对整个数字系统的速度和功耗具有极大的影响。如图6所示放置方式,这种放置方式无论从走线上还是从版图上对于ROM的功耗优化是积极的,但是作为一个嵌入式片上器件来说,不能仅仅考虑自身的性能与功耗,而是要从整个DSP性能与功耗的角度考虑。图6固然是最想要的结果,但由于整个数字系统时序优化[11]还有其他性能的要求、面积的限制、成本、DSP整个微处理器的布局规划的要求等,采用了如图8所示的方式对外围电路整体位置进行摆放,可进一步优化处理器的时序,即改善了处理器与ROM之间的传输带宽,从而降低了处理器核与ROM之间进行信息交换的能耗。虽然在这种情况下对于存储器自身的功耗是不利的,但基于整个DSP整体性能角度的考虑,必须要在传输功耗和自身功耗之间进行折中,明显,方案选择了前者。如果在这种情况下,要进一步降低ROM自身的功耗,必须在前面所有的基础上降低电压,对于降低功耗来说,降低电压是非常有效的方法,但是嵌入式系统比外部存储器有更多的系统电源要求,所以降低电压时也要进行折中考虑。

图8 外围电路位置摆放框图Fig. 8 Block diagram of peripheral circuit position
3 测试结果
图9所示是改进前的ROM功能波形仿真图,一共有4个端口,一个读使能,一个是时钟端,还有一个地址端和数据端。由图8可知,当时钟上升沿来临时,读使能处于低电平,此时读入地址,当使能结束,时钟处于高电平时,读出数据。此ROM可以在1.62~1.98 V和-40~125 ℃范围内正常工作。由图10和图11的仿真波形可知,此ROM功能的正确性。

图9 此ROM 的时序功能图Fig. 9 Sequence function diagram of this ROM

图10 改进前ROM功能仿真波形图Fig. 10 ROM function simulation waveform before improvement

图11 改进后ROM功能仿真波形图Fig. 11 ROM function simulation waveform after improvement
图12和图13是这款DSP的热点分布图,高亮区域为高温区,即区域电流很大,为高功耗区。图12是优化前的热点分布图,由图12看出,图中有明显的高温亮点,此区功耗较大;图13是最后优化后的热点分布图,可以看出,优化后与优化前相比,ROM周围区域已无明显亮点,且整个DSP范围内亮点减少,功耗降低。
表1是在DSP内核电压1.8 V和IO电压3.3 V情况下,改进前后DSP的功耗变化数据。
由表1可以看出:在主频不同时如从15 Mhz到150 Mhz,从表1数据可以看出,随着频率的提高,ROM对整个处理器影响越大,功耗降低得越明显,在150 M时,从153 mA降低到137 mA。总体上,优化后比优化前功耗降低了大约11.3%。

图12 改进前芯片热点图Fig. 12 Chip hotspot map before improvement

图13 改进后芯片热点图Fig. 13 Chip hotspot map after improvement

表1 改进前后功耗数据对比表Table 1 Comparison of power consumption data before and after improvement
4 结 论
针对片上ROM应用于DSP时现有的功耗优化方法对DSP的速度、时延、和整体功耗的不良影响特点,提出了一种合理分区结合地址重组的方法,使片上ROM 应用于DSP时得到更大的功耗优化;又基于DSP本身性能、面积、成本的前提下,在前面所提的合理分区和地址重组的基础上改变外围电路位置的摆放,通过时序的优化改善带宽,降低处理器核和片上ROM的传输功耗。方案已经成功流片并改版,并且已通过测试验证该方案的正确性。
