城市激光点云语义分割典型方法对比研究
2021-02-06刘启亮袁浩涛
杨 柳,刘启亮,袁浩涛
(中南大学地球科学与信息物理学院地理信息系,湖南 长沙 410083)
0 引言
近年来,车载或地面激光扫描技术已成为城市三维信息快速获取的重要手段,并广泛用于智能交通、环境保护、智慧城市等领域[1,2]。点云语义分割旨在从杂乱无序的点云中识别与提取地物目标[3],是城市激光点云数据处理的核心任务之一[4,5]。由于城市激光点云数据中目标多样、密度不均且存在缺失等[6,7],从中提取地物目标一直是一项具有挑战性的难题[8-10]。长期以来,点云语义分割主要依赖人工设计的特征描述子[11-16],包括属性特征[17-19](如颜色、高程、反射强度等)、局部几何特征[20-22](如法向量、曲率、主方向等)以及宏观特征[23,24](如形状、特征值分布、离散度等)。基于上述特征描述子,国内外学者主要采用两种策略提取点云目标[25]:1)逐点聚类或分割的策略,即逐点分析局部邻域内特征描述子的差异,采用聚类分析法将点云分割为不同目标[26-30];2)面向对象的策略,即将点云分割为一系列均质的对象,依据对象特征通过聚类识别点云中的目标[31-36]。然而,人工设计的特征描述子仅能够表达点云低层次的基础特征,难以识别建模场景中高层次语义特征,严重影响了上述点云语义分割方法在复杂城市场景中的应用效果[37]。
近年来,深度学习在图像模式识别领域的突破性进展为城市激光点云语义分割提供了新的研究思路,深度网络可从数据中自动提取从底层到高层的特征,建立从低层次特征到高层次语义的映射关系[38]。当前,国内外学者尝试将深度学习思想引入点云语义分割领域[39],研究方法主要分为以下3类:
(1)基于体素或多视图的方法。为使深度网络能够适应散乱的点云数据,首先对点云数据进行规则化处理,再采用深度网络进行点云语义分割。基于体素的方法利用固定大小的三维格网对空间进行划分,落在同一格网中的点被视为一个体素,从而将点云数据转化为三维规范数据并输入3D CNN网络中,以识别输入对象的类别[40-42];多视图方法通过选择不同的方向将三维点云投影为二维图片,并在二维图片上应用2D CNN实现类别判断[43,44]。上述方法对于原始点云数据的规则化处理不利于点云细节特征的提取。
(2)基于原始点云的方法。为避免体素化或投影带来的信息损失,相继提出了一些直接针对原始不规则点云数据的深度网络。例如:PointNet[45]首次将散乱的三维坐标作为网络的输入,并引入对称函数使得网络对点云的输入顺序不敏感,但其对局部细节信息的学习能力不足;改进的PointNet++[46]通过将原始点云划分为局部小区域,在小区域中迭代使用PointNet以实现局部细节信息的学习;PointCNN[47]使用卷积操作融合邻域特征以得到局部特征的一维表示;为得到更有效的多尺度细节信息,Guo等[48]从不同层次的卷积操作中提取特征并进行融合,将融合后的特征输入分类器进行点云目标识别。上述针对点云设计的深度网络奠定了深度学习方法在点云语义分割中应用的理论基础,但其仅针对单个点进行操作,难以适应城市大场景的语义分割任务。
(3)面向对象的方法。为提高点云语义分割的效率,在点云语义分割的深度网络构建中引入了面向对象的策略。例如:基于超点图的深度网络(SPG)[49]首先对海量点云过分割得到超点,基于超点提取抽象特征并构建拓扑连接图,然后引入长短期记忆网络实现地物语义分割;Wang等[50]通过将原始点云划分为点簇以缩减数据量,并利用卷积神经网络学习点簇的特征进行地物提取,使得深度网络在大场景的应用成为可能;罗海峰等[51]采用连通分支与基于体素的归一化方法对原始点云分割得到目标对象,再利用深度网络对目标对象的二值图像进行语义分割。
综上,基于深度学习的点云语义分割研究已成为近年来点云数据处理的热点,但其在城市激光点云语义分割任务中的应用效果尚缺乏客观的对比与评价,如PointNet、PointNet++、PointCNN等网络仅在室内场景的点云语义分割中进行了验证;此外,深度网络是否能够提取比人工设计的特征描述子更“高级”的特征尚缺乏验证。为此,本文试图通过实验对比分析,探索如下问题:1)当前基于深度学习的点云语义分割方法是否真的优于基于特征描述子的方法?2)不同类型的点云语义分割深度网络在不同类型城市激光点云数据中的表现存在多大程度的差异?
本文采用3组开放城市激光点云数据集——Semantic 3D[52]、Oakland[53]及TerraMobilita/iQmulus 3D urban (Paris数据集)[54],对当前4种代表性点云语义分割深度网络(PointNet、PointNet++、PointCNN、SPG)以及一种基于特征描述子的方法(层次化点云语义分割方法)进行对比研究,分别采用总体精度、精度、召回率及F1指数对上述5种方法的应用效果进行定量评价,为实际应用中选择点云语义分割方法及点云语义分割深度网络的设计优化提供借鉴。
1 城市激光点云语义分割方法
1.1 层次化点云语义分割方法
层次化点云语义分割方法[8]采用面向对象的策略提高点云语义分割的效率,融合点云的几何、纹理和强度等多类型特征进行分割和分类,并借助层次化的语义分割策略,降低了不同类型目标相隔较近时的提取误差。如图1所示:首先利用点云的距离、颜色、强度等信息计算得到的综合距离生成超级体素(一种内部均质但形状大小均不固定的点云簇);进而依据不同地物几何特征的差异性(如建筑物立面、地面等表现为法向量的一致性、杆状地物表现为主方向一致性、树冠等表现为颜色一致性等)将超级体素分为面状、杆状、球状体素,分别采用法向量、主方向及颜色等信息聚类3种类型的超级体素;最后依据先验知识计算分割区域的显著性,对分割区域依据显著度进行层次化排序,以显著性最大的区域为中心区域与其邻近区域聚类得到目标,直到所有目标均被识别。为判断地物目标的类别,层次化点云语义分割方法利用人类先验知识设置每种地物目标的几何特征约束(如长度、宽度、拓扑关系等),对地物目标类别进行标记。

图1 层次化点云语义分割方法流程Fig.1 Flow chart of hierarchical semantic segmentation of point clouds
1.2 PointNet
PointNet[45]直接将原始点云数据作为输入,解决了深度网络应用于点云语义分割的两大难点(图2):1)无序性,点云本质上是一长串无序点集合,点的顺序不影响点云对于物体形状的表达;2)旋转不变性,相同的点经过一系列刚性变换(如旋转、平移等),坐标会发生变化,但其表达的形状并未改变。PointNet通过引入对称矩阵使得点云输入顺序不影响学习结果。具体地,PointNet将最大池化函数作为对称函数,在使用对称函数前,卷积操作仅在单个点上操作,可提高每个点的特征维度。经过若干卷积层后在每个维度上分别使用最大池化函数,得到每个维度上最显著的特征信息,尽可能保留点云中最重要的高维特征,并使保留的特征与输入顺序无关,对称函数的操作如图3所示。针对旋转不变性问题,PointNet在提取高维特征之前,通过网络学习一个类似于仿射变换矩阵的变换矩阵,以规范点云的输入方向,从而使网络对点云的刚性变换不敏感。

图2 PointNet整体框架(改自文献[45])Fig.2 Overall framework of PointNet

图3 对称函数示意Fig.3 Illustration of symmetric function
1.3 PointNet++
PointNet采用对称函数仅能获取点云数据的全局特征,忽略了点云的局部结构,影响了其针对复杂场景的泛化能力。PointNet++[46]为一种层次化的深度网络结构(图4),可将点云划分为相互重叠的局部区域,利用卷积算子从小区域中捕获点云的局部特征,并将其作为下次分组的小单元,与其他特征构成高级别的小区域,从而实现更高级别的特征提取,直到得到整个点云的高级特征。PointNet++在小区域内迭代使用PointNet,充分考虑了点云的局部自相关,更有利于提取细节特征,可减少特征损失。

图4 PointNet++整体框架(改自文献[46])Fig.4 Overall framework of PointNet++
1.4 PointCNN
为解决点云数据的无序性问题,同时捕捉点云数据的局部相关性,Li等针对图像数据的卷积算子在点云数据中进行了扩展,提出了PointCNN网络[47]。PointCNN采用转置矩阵(图5)处理点云无序性问题,使得无序点云能够规范到统一的抽象空间,从而避免输入顺序的影响。与PointNet采用对称函数处理点云无序性相比,PointCNN可降低特征的损失。为学习点云的局部特征,PointCNN在图像卷积算子的基础上构建了X卷积算子(X-Conv),每次卷积时,X卷积算子寻找最邻近中心点的K个点,将其特征融合。随着网络的加深,参与运算的点越来越少,但每个中心点上的特征逐渐增加,以此实现与卷积算子相同的信息融合效果。在网络整体架构上,PointCNN首先通过学习变换矩阵消除点云无序性的影响,而后通过X卷积算子不断融合局部信息,实现网络对于局部信息的学习。在每次卷积中,X卷积算子寻找中心点的K邻域,再通过加权求和融合K邻域的特征,使其能达到与规则数据中卷积算子融合邻域特征同样的效果(图6)。
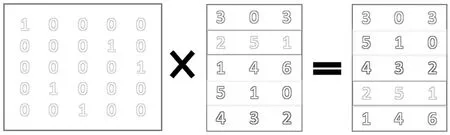
图5 转置矩阵示意Fig.5 Illustration of transformation matrix

图6 X卷积算子示意(改自文献[47])Fig.6 Illustration of X-Conv operator
1.5 基于超点图的深度网络(SPG)
上述点云深度学习方法虽然解决了点云的无序性和旋转不变性等问题,但网络每次输入的点数固定,要求点云数据输入前必须人为划分为统一大小,一定程度上切断了部分点的拓扑关系;而且点云数据量大,直接基于单个点的操作降低了网络处理的效率,限制了其在大场景中的应用。针对以上问题,Landrieu等引入基于对象和图的思想,构建了一种基于超点图的深度网络(SPG)(图7),实现了大规模场景地物目标识别[49]。

图7 SPG网络结构[49]Fig.7 Structure of SPG net
SPG首先采用一种弱监督分类方法,依据点的线性、平面性和散射特征将点云划分为一系列几何同质且富有意义的几何形状,即超点。超点的引入大大缩减了网络处理的数据量,基于超点间的拓扑关系构图很好地保留了点云间的拓扑关系。由于基于超点构建的图远小于基于单个点构建的图,从而使得网络处理大场景点云数据成为可能。对于每个超点,采用PointNet学习其抽象特征,并将该特征作为基于图结构神经网络的输入。为同时学习更高级的语义特征和图结构的拓扑信息,又将门控循环单元(GRU)通过图的形式串联,每个GRU的输入特征由其对应的超点以及与其拓扑相邻的超点对应的GRU的输出共同组成,通过这种图相连的形式进行信息传递,得到分割结果。
上述城市激光点云语义分割方法的异同与主要特点总结于表1。

表1 城市激光点云语义分割方法对比Table 1 Comparison of the five semantic segmentation methods for laser point clouds in urban areas
2 实验设计
本文分别采用Semantic 3D数据集中的bildstein3、Oakland及Paris数据集,对以上5种方法进行测试。对于4种基于深度学习的方法,分别从原作者处获取核心网络代码,修改后使其适用于3个基准数据集的语义分割任务;对于层次化点云语义分割方法,由于原作者未公布源代码,本文独立实现了该方法。所有算法均在一台32 G内存、64位8核处理器(3.5 GHz)的工作站上测试,操作系统为ubuntu 16.4,深度学习环境在cuda 9.0和tensorflow 1.2下搭建,算法编程语言为Python 3.6。本文采用机器学习模型评估常用的“留出法”(hold-out)对基于深度学习方法进行评估。为平衡评估结果的保真性与训练模型的可靠性, 依据当前机器学习领域的研究经验,从每个数据集中随机选取每种类别70%的数据进行训练,剩余30%数据作为测试样本[55]。对于层次化点云语义分割方法,选用与基于深度学习方法相同的测试样本进行精度评价,评价指标包括总体精度、精度、召回率及F1指数。
为测试5种方法针对不同场景、不同形态目标的分割效果,本文选取了不同区域、不同采集方式、不同场景的3组点云基准数据进行测试。1)Semantic 3D数据集中的bildstein3数据是苏黎世联邦理工学院采用静态扫描仪采集的城市郊区点云数据,包含树木(点数:3 174 966)、建筑物(点数:592 462)、硬景观(点数:540 129)、汽车(点数:92 875)4类地物,地物不规则且点密度较大。2)Oakland数据集是使用搭载了SICK LMS激光雷达扫描系统的智能车辆Navlab11在芝加哥大学校园收集的,包含树木(点数:290 251)、线状(点数:7 264)、杆状(点数:10 460)、建筑物(点数:129 096)4类地物,地物较规则且点密度较低。3)Paris数据集由法国国家测绘局(IGN)开发的移动扫描系统在巴黎密集城市环境中获得,去除噪声、未标记点及地面点后,保留树木(点数:207 454)、建筑物(点数:7 025 886)、汽车(点数:322 305)3类地物,地物数据差异较大,点密度也较大。
3 实验结果分析
3.1 5种方法精度评价
分析5种方法的实验结果(图8-图10,彩图见附录1)及语义分割评价结果(表2-表4)可知:1)针对Semantic 3D数据集中的bildstein3数据集,层次化点云语义分割方法效果最佳,其识别精度为92.6%。对于每种地物而言,层次化点云语义分割方法除对树木的提取精度、召回率、F1指数及硬景观的精度低于SPG外,对其余地物的提取效果均优于其他方法;基于深度网络的方法在该数据集上的识别精度从高到低依次为SPG(88.1%)、PointCNN(81.4%)、PointNet++(68.4%)、PointNet(61.3%),且这4种方法对数量较少的地物识别效果普遍较差。2)针对Oakland数据集,SPG识别精度高达96.3%,层次化点云语义分割方法精度为94.8%,PointNet、PointNet++及PointCNN的精度分别为68.7%、49.4%和69.3%。5种方法对线(杆)状地物识别结果的F1指数均低于树木和建筑物,PointNet和PointNet++几乎无法识别线(杆)状地物。3)针对Paris数据集,SPG识别精度最高(98.2%),其次为层次化点云语义分割方法(97.4%),但其对汽车和树木的识别精度均高于SPG,而对建筑物立面的识别精度低于SPG,这主要是因为地物遮挡对建筑物造成了一定的空洞,导致点云结构与人工设置的语义参数不符;PointNet++和PointCNN整体效果较好,精度分别为95.0%和95.5%,但二者对树木的识别精度较低;PointNet的地物识别效果最差,无法识别汽车和树木。

表2 bildstein3数据集语义分割结果评价Table 2 Evaluation of semantic segmentation results of different methods for bildstein3 dataset %

表3 Oakland数据集语义分割结果评价Table 3 Evaluation of semantic segmentation results of different methods for Oakland dataset %

表4 Paris数据集语义分割结果评价Table 4 Evaluation of semantic segmentation results of different methods for Paris dataset %
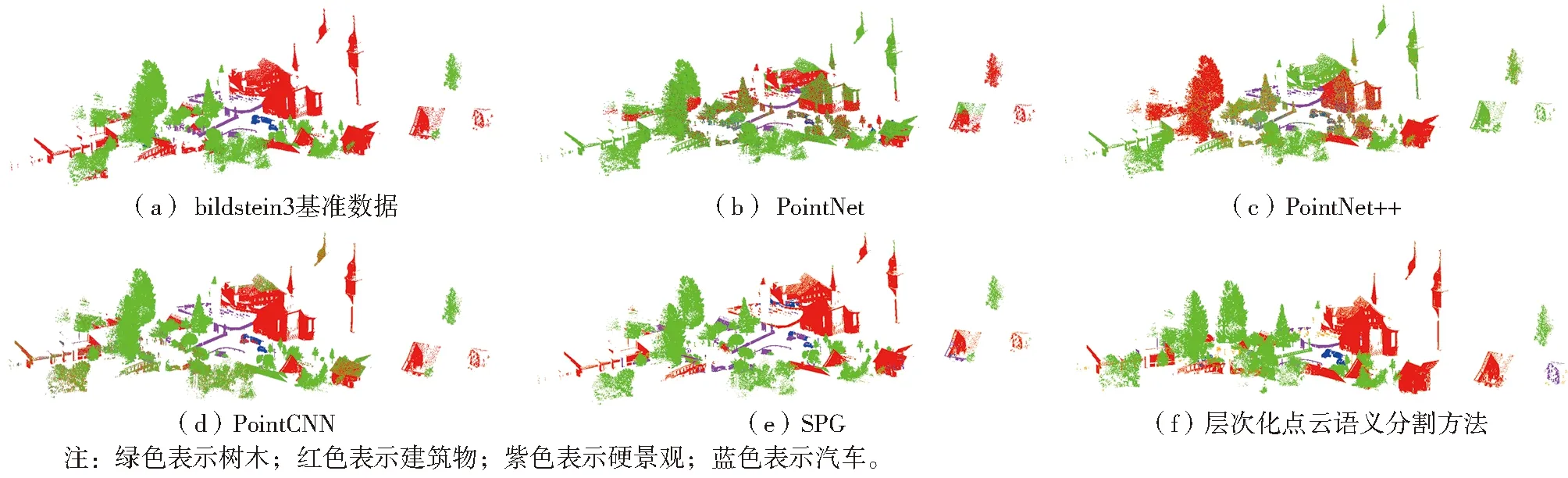
图8 bildstein3数据集实验结果对比Fig.8 Semantic segmentation results of bildstein3 dataset

图9 Oakland数据集实验结果对比Fig.9 Semantic segmentation results of Oakland dataset

图10 Paris数据集实验结果对比Fig.10 Semantic segmentation results of Paris dataset
分析5种方法的运行效率(表5)可知:1)SPG的效率最高,虽然层次化方法也采用基于对象的思想,但其生成的超级体素的数量远多于SPG构建的超点;此外,层次化方法生成超级体素、层次化提取目标过程耗时较多。2)PointCNN效率最低,主要是由于X卷积算子的计算效率较低。

表5 5种方法运行时间比较Table 5 Running time of the five methods min
3.2 两个问题探讨
(1)当前基于深度学习的点云语义分割方法是否真的优于基于特征描述子的方法?通过实验对比,发现当前基于深度网络的代表性方法(PointNet、PointNet++、PointCNN和SPG)虽然采用了大量训练数据(数据集的70%),但其语义分割质量仍普遍低于基于特征描述子的层次化点云语义分割方法,虽然SPG在Oakland和Paris数据集上的识别总体精度略高于层次化方法,但考虑到SPG需要大量的训练样本,这种精度提升可以忽略。这一结论说明,基于深度学习的方法理论上的优势并没有真正在当前方法中得到充分体现,其主要原因可能在于:1)当前应用于点云语义分割的深度网络尚难以提取能真正反映目标本质的“高级特征”,在单一数据集上训练提取的特征可能不如当前广泛采用的特征描述子稳健,深度网络的架构设计还需进一步优化;2)现有深度网络缺乏对地物目标语义信息和先验知识的描述,这些信息和知识往往是基于大量的总结和归纳而得,仅通过一个或几个数据集的训练学习难以准确捕捉这些语义信息和先验知识,尤其是当目标数量较少时(如bildstein3数据集),当前深度网络结构的特征提取能力尚存在欠缺。3)层次化分割方法有效实现了地物的多尺度信息建模,可在一定程度上克服现有深度网络普遍存在的“过平滑”问题,有利于识别不同大小的地物目标。
(2)不同类型的点云语义分割深度网络在不同类型城市激光点云数据中的表现存在多大程度的差异?通过实验发现SPG的地物语义分割质量最高,其主要原因在于:SPG与PointNet++和PointCNN相比,不仅能够构建点云的局部特征,而且可通过图的形式描述点云的空间关系,这种空间关系可能更有利于学习点云目标的语义信息。由于PointNet++与PointCNN能够构建点云的局部特征,其语义分割质量大部分情况下优于PointNet。PointCNN比PointNet++效果更好,这主要是由于PointCNN能够学习不同邻域点对中心特征的贡献权重,获取的局部信息更全面,而PointNet++仅能获得局部最显著的特征。当目标数量较少时,当前基于深度学习方法的语义分割质量明显降低,这亦表明训练数据的数量和多样性严重影响网络的学习效果。虽然SPG网络语义分割精度较高,但其相比层次化语义分割方法没有优势,主要原因可能在于超点降采样与PointNet提取特征时(最大池化)导致信息损失。
4 结论与展望
针对深度学习方法在城市激光点云语义分割任务中的应用效果缺乏客观的对比与评价的问题,本文选取4种代表性的点云语义分割深度网络(PointNet、PointNet++、PointCNN、SPG)以及1种基于特征描述子的层次化点云语义分割方法,在3种公开数据集上进行对比分析,结果发现:1)当前基于深度学习的点云语义分割方法的实际效果不如基于特征描述子的层次化点云语义分割方法,尤其是当目标数量较少时,深度网络的目标识别质量稳定性较差;2)在测试的4种深度网络中,同时考虑点云局部特征与空间关系的SPG网络在测试数据集中效果最佳,且运行效率最高。
通过本文的实验与分析,未来基于深度网络的点云语义分割研究在以下方面需要继续深入:1)面向城市点云语义分割的基准数据集设计,深度网络的语义分割效果严重依赖训练样本数量、质量和多样性,虽然当前针对图像分类的大规模基准数据集已经出现,但适用于城市点云语义分割的大规模基准数据集尚未构建;2)在深度网络构建过程中融入先验知识和语义约束,充分融合深度学习和基于特征描述子方法的优点,降低深度网络的训练成本;3)面向对象思想在点云深度网络设计中具有一定的优势,但是对象生成的误差以及对象间特征融合过程中的过拟合等问题依然需要深入研究;4)地物间的空间关系以及地物的多尺度特征在深度网络设计中需引起充分重视。
