嵌入式RISC-V乱序执行处理器的研究与设计
2021-02-05李雨倩焦继业刘有耀郝振和
李雨倩,焦继业,刘有耀,郝振和
(1.西安邮电大学电子工程学院,西安 710121;2.西安邮电大学计算机学院,西安 710121)
0 概述
嵌入式处理器目前已用于低功耗应用的各个领域,随着小型嵌入式设备(如物联网边缘设备)的广泛使用,对嵌入式系统功能、速度、资源等要求越来越高[1-3]。同时,增长较快的物联网市场具有长尾化特性,拥有众多细分市场,对于功耗有较高的要求[4-6]。处理器是物联网设备的核心部件,特别是嵌入式物联网设备对处理器有实时性的要求,对软件生态的依赖相对较低,应用需求也不尽相同,因此,迫切需要一种能够根据自身需求可定制的RISC指令集架构[7]。
在嵌入式领域中,ARM架构的处理器占据着主导地位,当前多数嵌入式处理器都基于ARM架构。ARM系列处理器通常只能做标准化设计,很难实现差异化处理。例如最常用的Cortex-M3和Cortex-M4处理器,Cortex-M3相比于Cortex-M0增加了除法,Cortex-M4相比于Cortex-M3增加了分支预测和浮点单元。ARM在提升处理器性能的同时,面积大幅增加。
现有的嵌入式微处理器多采用顺序单发射、顺序执行和顺序写回的方式,在保证处理器性能情况下势必会牺牲面积,制约了处理器性能面积比[8]。本文通过分析当前嵌入式处理器领域存在的问题,根据RISC-V指令集的特点,设计一款32位高性能低功耗的乱序执行处理器支持RV32ICM指令集架构。使用乱序执行方式降低处理器的面积,在保证处理器性能的情况下提高性能面积比。针对处理器运行速度的需求,系统采用并发方式执行指令,支持不同类型指令并行执行。为降低并行化开销,使用小面积低功耗的乘除法模块,并采用面积较小的缓存结构以平衡性能、硬件资源与代码大小。
1 RISC-V指令集
RISC-V(Reduced Instruction Set Computer-Five)作为一种开放自由的指令集体系结构,可以针对不同的应用灵活组合指令集进行芯片设计,满足从嵌入式设备到服务器等不同领域的处理器设计需求[9-10]。
RISC-V是一种新兴的开源指令集,没有专利限制,具有简洁的指令格式、模块化的指令集、可定制扩展、无条件码和分支延迟槽等优点,简化了RISCV处理器的设计[11]。国内外已有众多高校和企业对RISC-V指令集进行研发,阿里平头哥在2019年7月发布了高性能RISC-V架构处理器玄铁910;兆易创新也在2019年8月发布了一款基于RISC-V的32位通用MCU芯片GD32VF103系列。
RISC-V ISA由一个基本的整数指令集“I”和丰富的可选扩展组成,扩展用单个字母表示,例如“M”(整数乘法和除法)、“A”(原子指令)、“C”(压缩指令)等。其中整数集有3种不同的配置,分别具有32位、64位和128位数据宽度:RV32I,RV64I和RV128I,RV32E配置本质上是轻量级RV32I,其寄存器数量更少[12]。设计者可以选择实现具有定制扩展的指令子集,通过这些指令集的组合或者扩展以满足应用需求,同时可以降低资源开销和功耗。文献[13]较全面地描述了RISCV指令集。RISC-V指令集在嵌入式设计领域具有较大的优势和广泛的应用前景,随着高性能处理器的不断开发和应用,RISC-V指令集被更广泛地应用于高性能低功耗等领域。
2 处理器架构
乱序执行结构可加快处理器执行速度,提高系统运行速度[14]。本文设计了适用于微控制器的三级流水线结构,即“取指”“执行”和“写回”,具有顺序单发射、乱序执行和乱序写回的特点。图1所示为三级流水线架构。

图1 三级流水线架构Fig.1 Three-stage assembly line architecture
2.1 取指阶段
2.1.1 取指及生成PC
如图1所示,取指位于流水线的第1阶段。取指阶段从指令存储器中顺序取出指令存入IR寄存器,执行阶段从IR中取指令继续执行。在本文设计中,取指模块使用一个32位寄存器保存当前的PC值,顺序取指时下一个PC通过当前指令的位宽判断,若当前指令为16位指令时PC+2,当前指令为32位时PC+4。分支指令采用分支预测模块得到的跳转地址作为新的PC值,分支预测失败时使用执行阶段返回的正确的PC值。分支预测采用静态分支预测技术,根据当前指令的跳转方向预测指令是否发生跳转。对取得的指令在同一周期进行部分译码,判断指令是分支指令还是非分支指令,若是分支指令则需要得到分支指令的具体信息,通过得到的分支指令跳转地址偏移量和分支预测的结果生成PC值。
2.1.2 指令访问及AHB总线通道
取指模块作为总线系统中的主设备单元负责产生取指地址和相关控制信号。本文设计取指以及访存模块采用AHB总线接口协议,可方便集成ARM系列处理器中已经成熟的各种IP核[15]。
目前大多数RISC-V处理器所使用大面积紧耦合数据和指令存储器占用了较大的芯片面积,嵌入式设备中将增加处理器的成本[16-17]。因此,为实现快速取指挂载了指令Cache等高速存储器,指令可以通过总线系统从外部存储器(Icache)进行读取。
2.2 执行阶段
2.2.1 译码与指令派遣
译码与执行位于流水线的第2阶段。执行阶段将取指阶段存储在IR寄存器的指令进行译码和执行;译码模块可得到指令的操作类型、寄存器索引和立即数等信息。执行模块主要完成简单算术运算(ALU)、乘/除法(MulDiv)、访存指令的地址生成(AGU)、分支预测解析等任务。
译码模块主要由组合逻辑组成,在指令格式中,通过opcode将指令分组,指令的最低两位作为判断32位和16位指令的依据,funct部分可以判断指令的具体功能,立即数进行符号扩展为32位。根据指令的编码规则对指令进行译码,按照指令功能可生成3组指令信息,将指令信息派遣到ALU、Muldiv或AGU模块完成运算。RISC-V指令都是单操作数或两操作数指令并且写回策略每次只写回一条指令,因此,相关寄存器文件支持两个读端口和一个写端口操作。指令派遣流程如图2所示。
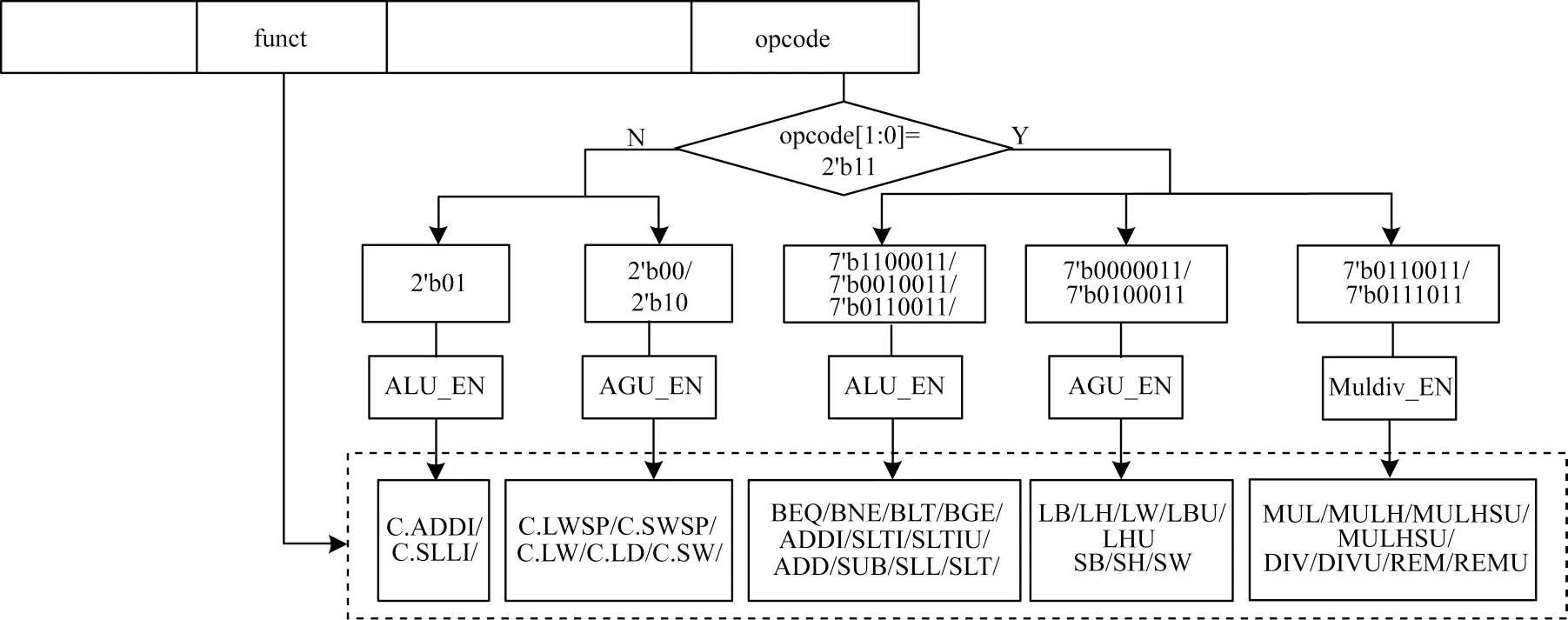
图2 指令派遣流程Fig.2 Command dispatch procedure
生成乘除法单元所需的信息总线(Info Bus)代码如下:

2.2.2 乱序并行执行单元
执行模块主要由3个功能子单元组成,可实现普通运算、乘除法运算、长指令访存等功能。不同通道的逻辑操作和内存访问相互独立,可实现指令集并行执行以获得更好的性能。普通ALU运算模块完成逻辑运算、加减法、移位等指令;访存地址生成模块完成Load、Store指令的地址生成;乘除法单元完成整数的乘除法运算。
嵌入式处理器的主要挑战就是功能单元利用率低和分段访问的问题,例如乘法和除法单元。图3所示为RISC-V各类型指令使用频率,数据来源于coremark与dhrystone 2个标准测试程序。由图3可知,使用频率最高的是基本整数运算指令,乘除法相关指令mul与div使用频率较低。乘除法单元在执行过程中短时间内偶尔被访问,并在相当长时间内保持空闲,长时间的空闲会导致显著的静态功耗。随着晶体管尺寸技术节点和阈值电压的缩小,静态功率的作用变得更加明显[18]。此外,这些利用率低的单元具有更大的面积(即晶体管数量),表明嵌入式系统中静态功耗不断增加。
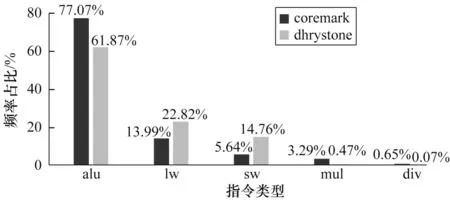
图3 RISC-V指令的使用频率Fig.3 Usage frequency of RISC-V instruction
降低并行化开销是提高依赖数据并行计算模型的计算系统能效关键因素之一,尤其是在处理工作负载不平衡和并行区域小的应用时。基于以上分析,本文设计了低功耗、小面积的多周期乘除法模块,该模块仅使用状态机进行控制和选择,节省了硬件开销。乘法器选用Booth设计,除法器使用加减交替法设计。乘法操作按照MULH(返回乘法结果高位)、MUL(返回乘法结果低位)的顺序执行,除法操作按照DIV(返回除法的商)、REM(返回除法的余数)的顺序执行,并将两条指令融合为单一的乘除法操作,仅执行一次乘除法操作。乘除法操作共用一个加法器进行资源复用可减少面积开销,使用加法器进行多次迭代运算可实现乘除法功能。结合单周期和多周期并行执行的设计,可以在减少对流水线运行影响的情况下实现降低并行化开销的目的,减小处理器的面积和降低功耗。
2.3 写回阶段
2.3.1 写回仲裁策略
写回阶段主要由访存模块和写回模块组成。如图1所示,写回阶段提交来自流水线的指令,将指令的运算结果写回到通用寄存器组中,并更新寄存器文件。因为在执行过程中多周期指令和单周期指令可以并行执行,所以在写回时可能会出现以下3种情况:
1)单周期指令顺序发射执行,在一个时钟周期内完成计算。多周期指令如果和正在执行的单周期指令没有发生数据冲突,则不影响单周期指令的执行,流水线不会产生断流的危害,单周期指令可以顺序写回。
2)多周期指令中乘除法指令和load指令的执行周期有所不同,所以在写回阶段可能发生同时写回到同一寄存器的情况,写回阶段将从长指令FIFO中读出第一条长指令信息,按顺序将第一条指令优先写回。因此,多周期指令属于顺序发射和顺序写回。
3)单周期和多周期指令在同一时期写回时,多周期指令写回的优先级更高,因为多周期指令一定在单周期指令之前发射。因此,如果将单周期与多周期指令统一考虑,则流水线属于顺序发射和乱序写回。
2.3.2 长指令数据访存
为满足CPU并行访问的需求,本文采用哈佛体系结构,即使用分离的指令和数据存储通过独立的总线系统分别访问。数据和指令的访问可以同时进行,可实现快速、无阻塞访问数据。分离的总线使得处理器可以在同一个周期内获得指令字(来自Icache)和操作数(来自Dcache),从而提高了执行速度和数据的吞吐率,减少访存冲突。当CPU访问数据时,需要经过总线控制单元BIU对信号进行译码,如图4所示,BIU对地址总线lsu2biu_haddr[31∶0]进行译码,根据不同的地址选择访问不同的外部模块或数据存储器。
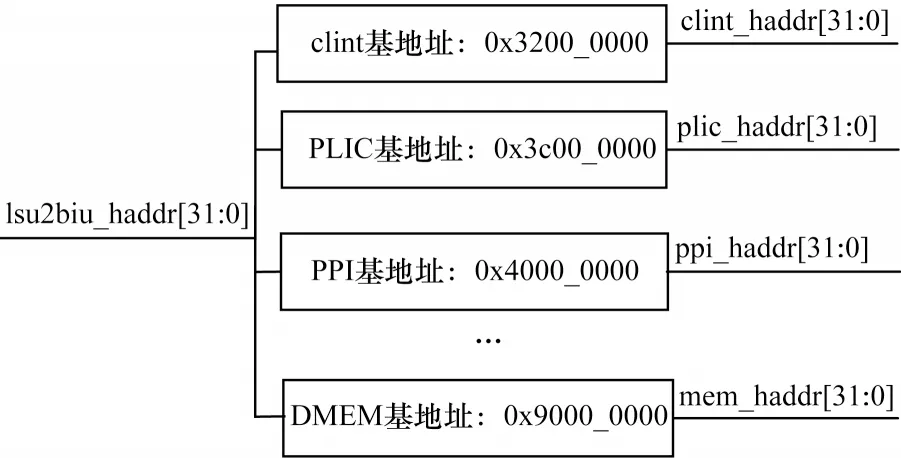
图4 总线地址译码逻辑结构Fig.4 Logic structure of bus address decoding
3 主要问题处理
3.1 分支预测处理
RISC-V具有简洁的分支跳转指令,包括无条件直接跳转(jal)、无条件间接跳转(jalr)和带条件直接跳转指令3种类型。其中带条件跳转指令将“比较”和“跳转”作为一条指令执行,减少了指令数目,从而简化了硬件设计。
在实际应用程序中,“while”“for”等循环语句使用频繁,循环语句需要用到条件分支指令,因此正确预测分支指令跳转方向和地址将减少流水线断流的危害。本文设计中使用简单的静态分支预测结构,在取指阶段对指令进行部分译码,得到分支指令信息。在条件分支指令中如果向后跳转则预测为跳转,向前跳转预测为不跳转,对于无条件跳转指令jal不需要进行预测直接跳转,在无条件间接跳转指令jalr中,如果rs1为寄存器0,则直接生成PC值;rs1若不是寄存器0,为防止RAW冲突,将暂停取指,等待执行完成后进行跳转。如果在执行阶段的分支预测解析模块通过ALU计算得到的跳转地址与预测结果不符,则会将正确的地址送入取指模块,更新PC值,并产生一个周期的流水线断流。分支预测状态示意图如图5所示。

图5 分支预测状态示意图Fig.5 State schematic diagram of branch prediction state
3.2 非对齐指令处理
本文设计支持RISC-V架构扩展压缩子集“C”,当处理器取指遇到地址非对齐的指令时,通常需要两个时钟周期取出一条指令。针对以上问题,使用剩余缓存技术,保存上一次取指没有用完的比特位供下一次使用。对于RV32非对齐情况,取出的32位指令为低16位与上一次取指的高16位,对于压缩指令只使用低16位,高16位暂存于剩余缓存中。
图6展示了4条待执行指令,其中前3条为16位压缩指令,第4条为32位指令。4条指令均存储在32位指令存储器0x0c-0x14的地址空间,其中第4条指令分开存储在0x10和0x14两个地址。
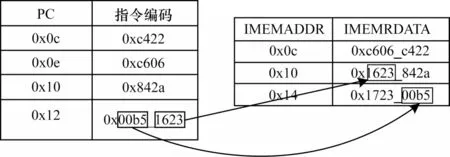
图6 指令编码及对应的数据存储地址Fig.6 Instruction coding and corresponding data storage address
表1为不加剩余缓存的情况,共需要对指令存储器进行5次读取操作。表2为添加剩余缓存的情况,第1次读取0x0c地址的指令,读出0xc606_c422,将0xc422送入IR寄存器,将0xc606送入剩余缓存寄存器中。第2次不需要读取指令存储器,使用剩余缓存的指令,第4条指令为32位指令,根据PC生成模块PC值会从0x10加2变成0x12,使用剩余缓存数据,剩余缓存为0x1623,判断不是16位指令后PC加2,读取0x14地址的指令,与剩余缓存里的数据组合成32位指令。由上述步骤可知,相同的4条指令不加剩余缓存需要5次读取操作,增加剩余缓存技术只需要读取3次存储器,可加快执行速度。
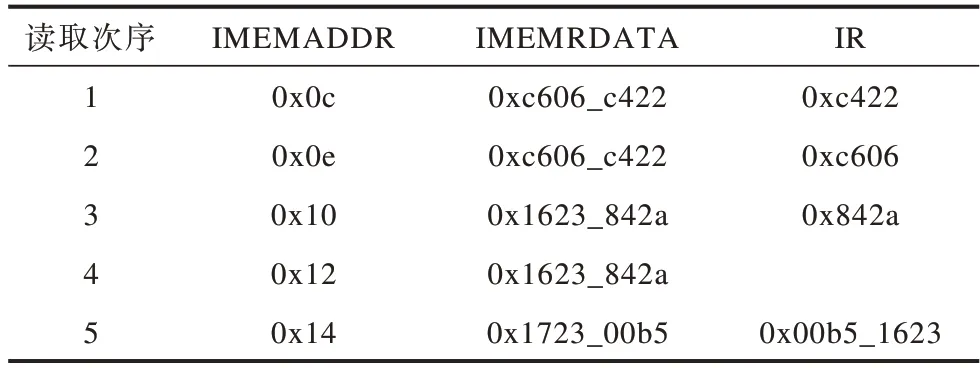
表1 不加剩余缓存的情况Table 1 Situation of without residual cache

表2 添加剩余缓存的情况Table 2 Situation of adding remaining cache
3.3 冲突解决
由于指令之间具有数据依赖性,RISC-V流水线可能会发生数据冲突等相关性问题,因此执行过程中需要处理流水线冲突问题。
1)如图7所示,第2条指令“div t5,ra,sp”需要用到第1条指令“li sp,6”的数据,这会引起RAW问题从而造成数据冲突。本文设计采用数据旁路技术,将第1条指令的计算结果直接送入下一条指令的译码模块。当执行除法指令时,在没有发生数据冲突的情况下,单周期指令可以继续发射、执行,当发生RAW相关性时,在一条相关的指令执行之前插入气泡,暂停流水线的执行。对于多周期指令和单周期指令写回模块发生的WAW相关性,多周期指令优先写回,避免此类冲突的发生。

图7 流水线数据的冲突Fig.7 Conflict of assembly line data
2)对于除法指令这样的长指令需要多个时钟周期才能完成除法运算,执行阶段可能会出现资源相关,使用握手协议暂停流水线。此外,采用哈佛体系结构,避免取指模块和访存模块发生争用存储器资源的相关冲突。
3)对于转移指令所引发的控制相关,使用分支预测技术减少流水线的断流。
3.4 处理器软件接口
在本文设计中开发了处理器相应的软件接口,包括外设寄存器名称、地址的定义以及外设的驱动代码、中断处理和启动代码等,对嵌入式软件开发人员透明,无需了解处理器内部结构,易于开发,并且ARM系列的软件移植方便。
4 验证与结果分析
4.1 指令集验证
本文使用硬件描述语言Verilog HDL将模块功能以代码来实现,通过开源的RISC-V基准指令集自测试用例,测试处理器是否符合指令集架构。该测试程序是由RISC-V架构开发者为了检测处理器是否符合指令集架构中的定义而编写的测试程序,汇编指令使用宏定义组织成程序点,测试指令集架构中定义的指令。结果表明,RV32ICM指令集所有指令均满足RISC-V指令集架构标准。
4.2 FPGA验证
片上系统(SoC)围绕处理器内核构建,具有一系列外部设备。本文FPGA实验平台为Xilinx Artix-7(XC7A35T-L1CSG324I)开发板,处理器核在50 MHz的时钟频率下进行测试。通过FPGA的软硬件协同仿真,使用该处理器核对外设进行控制,仿真结果满足嵌入式应用需求。此外,在同等环境下对RISC-V开源处理器蜂鸟E203和V-scale[19]处理器进行FPGA测试,表3为不同处理器的资源利用情况。

表3 基于FPGA的处理器资源利用情况Table 3 Resource utilization of processors based on FPGA
4.3 ASIC综合分析
在SMIC 0.11 μm的ASIC(Application Specific Integrated Circuit)技术节点上进行综合分析,进一步对比了Cortex-M3处理器以及开源RISC-V处理器蜂鸟E203、Zero-riscy[19]和V-scale等处理器,并从指令集、架构、性能等方面进行阐述。
1)Cortex-M3为ARM推出的面向标准嵌入式市场的高性能低成本处理器,采用ARM商业指令集架构,并且包含Thumb和Thumb-2两个子集。本文设计以及处理器蜂鸟E203、Zero-riscy和V-scale处理器均采用开源RISC-V指令集架构。RISC-V指令集相对于其他指令集架构更为简洁,例如在带条件分支跳转指令方面,传统处理器需要使用两条独立的指令,第1条指令先使用比较指令,比较的结果被保存到状态寄存器中。第2条指令使用跳转指令,判断前一条指令保存在状态寄存器中的比较结果为真时,则进行跳转。相对而言,RISC-V架构将比较与跳转两个操作放到了一个指令的方式减少了指令的条数,因此在硬件设计上更加简单。在压缩指令方面,ARM系列处理器使用的Thumb指令集,只有最基本指令的简化版本,可以将某些代码压缩20%~30%左右,但是从标准模式到Thumb模式的切换需要增加代码和时间消耗,代码的运行速度降低了约15%[20]。Thumb-2指令集虽无须状态切换,但是与标准的ARM代码相比,需要更多的Thumb-2指令实现相同的功能,额外的指令会使处理速度降低大约15%~20%。在RISC-V中大约50%~60%的指令可以用RVC指令代替,代码的大小可以减少约20%~30%,并且只需要在编译阶段完成,RISC-V的压缩指令和标准指令可以混合使用,无须状态的切换和额外代码开销[21]。因此,RISC-V压缩指令硬件设计更简单,执行效率更高。
2)如表4所示,在结构方面,本文设计的流水线深度与Cortex-M3以及V-scale相同,分为取指、执行、写回三级流水阶段。Cortex-M3和V-sclale处理器是顺序执行处理器,本文设计采用顺序发射、乱序写回的策略减少了流水线的断流。此外,设计了多周期乘除法器,对比Cortex-M3的单周期乘法器和2-12周期除法器具有更小的硬件开销。本文设计与Cortex-M3处理器均采用哈佛结构通过并行访问指令和数据来提高系统运行速度,并且采用了更适用于嵌入式系统的小面积缓存结构。
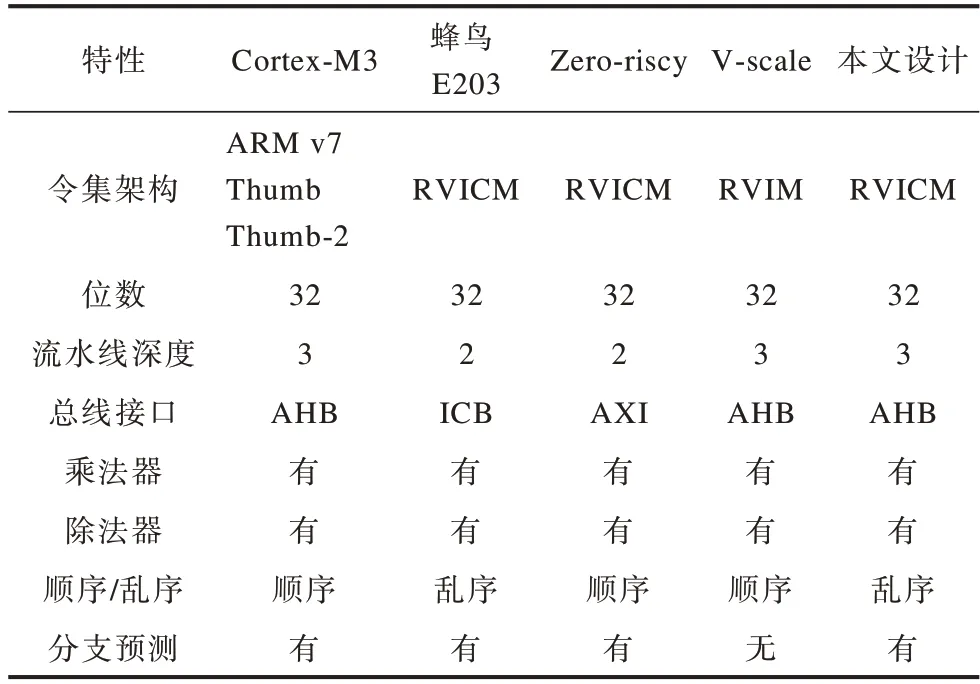
表4 不同处理器结构对比Table 4 Comparison of different processor structure
3)表5所示为逻辑综合结果对比。将本文设计与Cortex-M3处理器和蜂鸟E203处理器采用相同的工艺环境综合,面积上更具优势,较Cortex-M3小64%,较蜂鸟E203处理器小8%。功耗低于Cortex-M3处理器,略高于蜂鸟E203处理器。在性能方面,通过Dhrystone(DMIPS/MHz)跑分结果可知,本文设计性能与Cortex-M3相近。

表5 不同处理器基于ASIC技术性能对比Table 5 Comparison of different processor performance based on ASIC technology
5 结束语
本文针对小面积低功耗的嵌入式应用,设计了一款基于RISC-V指令集的32位乱序处理器。从取指、执行、写回3个阶段对流水线的设计进行分析,给出分支预测和数据冲突等问题的应对策略,且RV32ICM指令在测试平台均可验证通过,处理器核在Artix-7开发板实现逻辑功能。实验结果表明,本文系统面积较Cortex-M3减少64%,功耗降低0.57 mW,可应用于小面积高性能的嵌入式领域。目前该处理器已应用到基于RISC-V与Cortex-M0的双核异构系统中,面对嵌入式应用不断多样化和差异化的需求,下一步将面向特定的领域进行扩展,在RISC-V指令集预留的扩展指令空间中分配特定指令,设计协处理器的接口。
