边缘计算设备的性能功耗测量与分析
2021-02-05袁佳伟宋庆增王雪纯姜文超金光浩
袁佳伟,宋庆增,王雪纯,姜文超,金光浩
(1.天津工业大学计算机科学与技术学院,天津 300387;2.广东工业大学计算机学院,广州 510006)
0 概述
在当前神经网络应用(人脸识别、自动驾驶等)普遍增长的背景下,大型与复杂的神经网络将面向商业化发展。根据IDC[1]预测,到2020年全球产生的数据总量将大于40 ZB,在这种情形下,以服务器为计算核心的集中式处理模式将无法高效处理边缘设备产生的数据。因此,边缘计算[2]就显得尤为重要,边缘计算数据处理更接近数据来源,具有实时和快速进行数据处理分析的优点[3],这对于神经网络的商业化而言至关重要。
EDGE TPU计算板是当前最新的边缘计算设备,该设备集成了专为运行神经网络所设计的专用集成电路(ASIC)芯片,在以较快的速度运行神经网络的同时又能保持较低的功耗。NVIDIA Jetson TX2是一款面向人工智能的超级计算机模块,采用Maxwell GPU架构引入了流式处理多处理器(SM)的全新设计,支持32位单精度和16位半精度运算。Jetson NANO在TX1基础上弱化了数据流,并显著改善了电源管理,拥有128个CUDA核心,支持32位单精度计算和16位半精度计算,其中半精度计算的吞吐量为单精度的两倍。
对于Jetson TX2与而言,在发布时研究人员分析了其与深度学习模型的适配度,该实验将神经网络在不同框架下实现,对比TensorFlow、Caffe2、PyTorch等框架不同时的能耗和延迟情况[4]。随后有多种神经网络基于TX2的实现与优化,以及调整TX2的工作模式来分析比较不同模式下运行神经网络的延迟与能耗[5]。
目前有实验将神经网络部署在Jetson NANO边缘计算板上,该实验对具有实时语义分段功能的卷积网络进行改进,使用深度卷积来代替普通卷积以减轻网络负担,获得了较好的效果,平均交并比和FPS分别达到54.47%和47[6]。
FPGA原是作为一种半集成电路而出现的,目前多用来加速神经网络,在2007年,研究人员将前馈神经网络部署在FPGA上,根据要实现的功能划分与片上资源提出了通量估计器,通过该估算器部署神经网络,能以较低的消耗运行前馈神经网络[7]。目前已经有研究人员将流行神经网络部署在FPGA上,对YOLO V2中的部分参数进行二值化处理,实现了基于混合精度的YOLO V2架构[8]。
当前神经网络提升性能的方法主要有避免使用全连接层[9]、缩小卷积核与减少通道数、将下采样时间尽量提前、对训练好的神经网络进行剪枝操作[10]、量化权重、使用霍夫曼编码方式表示权重等6种。其中前4种都可减少计算量与访存量,量化权重与用编码方式表示权重可以降低访存量。使用建立Roofline模型查看在当前平台上运行的神经网络受何种因素限制,进而采取对应的方式来加速神经网络。
目前较少有在EDGE TPU计算板上的应用及Jetson NANO与EDGE TPU的性能功耗评测分析,且多数的Roofline研究只涉及性能测量与比较。本文对多种开发板的理论速度与实际测量速度使用Roofline模型进行建模,比较不同平台的理论与实际模型,测量分析模型性能,并对设备性能功耗进行比较,为设备的商业化应用提供更全面的应用数据。
1 本文研究方法
本文选用Roofline[11]模型作为评判性能的工具,测量计算出各个神经网络在不同平台运行时的帧率与运行推断时所需算力,构建各个基于不同平台神经网络的Roofline模型,以直观地观测出模型的性能,根据该实验结果可对在边缘设备上运行的神经网络进行优化以提高运行速率。
利用外置功耗测量设备,分别测量出不同平台的待机与工作功耗,再根据模型运行速度计算得出效能功耗比模型[12],即可对比观测各个平台待机时功率与运行神经网络时的性能能耗比,本文在实验中添加了服务器级别GPU(K40、K80)作为对照组进行对比,来突出边缘计算具有较大的优势与极高的发展潜力。
EDGE TPU具有4 TOPS的峰值计算量与50 Gb/s的带宽,EDGE TPU又仅支持通过量化所产生的8位整型数据运算,8位整型乘法处理器占用的面积与消耗的能量均为IEEE754定义的FP16处理器的1/6。因此,EDGE TPU计算板在以较快的速度运行的同时,又能保持较低的功耗。
TPU在运行之前的准备工作中的重要数据处理步骤是量化,虽然量化会在一定程度上降低精度,但一般神经网络模型拥有较好的泛化能力,表1所示为单精度(FP32)和8位定点权重参数的Mobile Net V2[13]及Inception V4[14]的正确率,可见进行量化之后并没有对精度造成较大的影响。

表1 不同神经网络单精度和8位定点参数的正确率Table1 Accuracy of single precision and 8-bit fixed point parameters of different neural networks
本文采用常用的神经网络作为实验对象,如Mobile Net[15]与Inception[16]均为当前市场化应用较多的神经网络。4种常用神经网络基本情况如表2所示。

表2 4种常用神经网络基本情况Table 2 Basic situation of four common neural networks
2 Roofline模型的性能分析
为观察测试网络模型在3个平台上的表现,本文引入Roofline模型,该模型是一种常用的设备性能分析模型,它将计算性能、计算密度和存储性能等相关联[17],并在一个二维坐标系中表示出来,Roofline模型背后的假设是网络模型不适合片上高速缓存,因此神经网络在Roofline模型中的位置受计算力限制与内存带宽限制。在二维坐标系中,Y轴为每秒浮点运算次数,因此峰值计算速率形成Roofline模型中的“平坦”部分[18],X轴是计算强度,测量为每个访问的DRAM字节的浮点运算,内存带宽是每秒字节数。因为(OPS/s)(/OPS/B)=Byte/s,变成了Roofline的“倾斜”部分。如果没有足够大的计算强度,网络模型会受到内存带宽限制,并且在坐标系中位于倾斜部分下方。
为测绘计算平台的Roofline曲线,需要计算计算平台理论上的算力峰值和显存带宽:

其中,OPS表示算力,PRO用来表示处理器数量,OpePerSec表示每个处理器每秒钟操作数,将TX2、NANO和EDGE TPU计算板的参数分别代入式(1),得出的算力分别为1.3 TOPS、471 GOPS和4 TOPS(8位)。服务器级别GPU(K80、K40)的峰值算力数据也可计算得出8.74 TFLOPS(FP32)和4.29 TFLOPS(FP32)。
Roofline模型的另一个重要元素为内存带宽,峰值带宽的计算公式如式(2)所示:

其中,BW代表带宽,ClockRate代表时钟频率,BitW代表位宽。将参数代入式(2)可得K80、K40、TX2、NANO、Coral的理论带宽分别为480 Gb/s、288 Gb/s、58.3 Gb/s、25.6 Gb/s和50 Gb/s。
根据所得算力及带宽信息,可得3块边缘计算板的理论Roofline模型如图1所示。
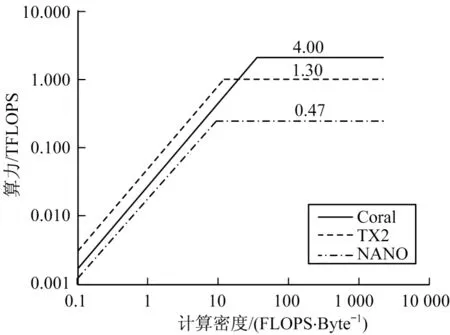
图1 TX2、NANO、Coral的Roofline模型Fig.1 Roofline model of TX2,NANO,Coral
图1中的Roofline图像采用对数直角坐标系,Coral算力值采用处理INT8数据类型算力值,从图1可以看出,Coral算力约为TX2算力的3倍和NANO的8倍。这是由于Coral开发板承载了EDGE TPU,该TPU改进结构以适应神经网络的部署以及使用量化8位定点数据的方式来加速计算。计算板的显存带宽受硬件实现、线路上的电磁干扰和其他诸多复杂的物理因素的影响[19]。使用CUDA自带的测试带宽的应用实例Bandwidth,实际测得TX2、NANO的带宽分别为33.2 Gb/s、14.7 Gb/s,另测得Coral的实际带宽约为30 Gb/s 。
TX2的实际Roofline模型如图2所示。

图2 TX2的实际Roofline模型Fig.2 Actual Roofline model of TX2
当计算强度到达40 OPS/Byte时,算力达到峰值,在坐标系中即平行X轴向右。虽然在实际中还有其他因素的影响使各个神经网络在图2中的位置并不能坐落在Roofline线上,但是每一个神经网络与Roofline线峰值的距离都反映了调整操作强度的好处[20]。对应Y轴距离的差值反映的是缓存阻塞之类的问题。当神经网络落点在斜线部分时,因受到带宽限制,故不能达到计算平台的峰值[21]。
NANO的实际Roofline模型如图3所示。

图3 NANO的实际Roofline模型Fig.3 Actual Roofline model of NANO
当计算强度到达32 OPS/Byte时,算力达到峰值,在坐标系中即平行X轴向右。若要建立关于EDGE TPU计算板的Roofline模型,则要对神经网络进行量化,由于原来的权重不适应EDGE TPU,因此要将浮点型参数变为整型参数,此外,参数的变化要求重新定义计算强度,因此,将计算强度改为每字节计算数[22]。
当计算强度到达136 OPS/Byte时,算力达到峰值,在坐标系中即平行X轴向右。从图4可以看出,Coral中的4种神经网络运行结果较好。

图4 Coral的实际Roofline模型Fig 4 Actual Roofline model of Coral
如图5所示,EDGE TPU计算板的Roofline的“倾斜”部分较长,峰值最高,在Coral上运行的神经网络均有较好的结果,4种网络中的3种算力值最高,这主要有以下2种原因:
1)经过量化处理的神经网络计算强度变大,在Roofline的图像上自然要向右移,对于受带宽限制(斜线区域)的神经网络改善较大。
2)Coral集成的EDGE TPU算力值较高,对于处于算力值限制(平行线区域)的神经网络有明显提升。

图5 合并后的实际Roofline模型Fig.5 Combined actual Roofline model
从图5可以看出:TX2的表现趋于稳定,TX2对于Inception V4的执行取得了最佳结果,在3种边缘计算版中具有最高带宽;TX2具有1.3T的峰值算力,具有强大的灵活性,支持多种深度学习框架,可以用来训练神经网络。
NANO的Roofline形状和TX2基本相似(NANO的构造和TX1的大部分参数相同),各个神经网络计算强度一样,但基于TX2运行的神经网络算力值约为基于NANO的2倍,比TX2和NANO在大小和价格上的差距要小得多。
3 功耗测量与分析
当设备在投入应用时,能耗往往是一个需要考虑的问题。本文使用性能/瓦特作为一个评测标准来进行分析,并且引入K40与K80[23]进行比较。
功耗测量设备型号为EXTECH-380803,误差为±0.9%,输入电流为220 V交流电。嵌入式设备能耗数据来自整块板卡能耗,K40与K80能耗数据来自显卡内部寄存器取值。测量Jetson NANO的能耗值示意图如图6所示。

图6 Jetson NANO能耗值测量示意图Fig.6 Schematic diagram of Jetson NANO energy consumption value measurement
虽然K80与K40只支持单双精度计算,但算力峰值仍超出3个边缘计算平台算力峰值,带宽远超边缘计算板带宽,K40与K80广泛应用于云端服务器[24-25]。
K80、K40的Roofline模型如图7所示。

图7 K80、K40的Roofline模型Fig.7 Roofline model of K80,K40
3.1 空闲功耗测量与分析
为测量出准确的空闲能耗,设边缘计算板均为开机后未运行任何任务的情况下,K80与K40均为P8[26]状态。
NANO、Coral、TX2、K40、K80的待机功率值如图8所示。其中,NANO、TX2、Coral为整个开发板功耗,K40与K80为单GPU在P8状态下的功耗可以看出,NANO实测最低为1.4 W,约为K80的1/40和TX2的1/5,边缘开发版中TX2待机功率最高。

图8 NANO、Coral、TX2、K40、K80待机功率Fig.8 Standby power of NANO,Coral,TX2,K40,K80 computing boards
3.2 工作功耗测量与分析
在工作状态下测量各个平台的功耗[27]如图9所示。可以看出,虽然K40与K80具有相当高的算力与带宽[28],但在此项比值中却占据了后两名,边缘计算板的性能功耗比对于服务器来说有较大的优势,其中EDGE TPU计算板的性能功耗比较高,远高于其他边缘开发板。Coral性能功耗比约为NANO的12倍和TX2的6倍,这意味着执行同样的任务,使用EDGE TPU计算板可以极大地节约能源[29]。
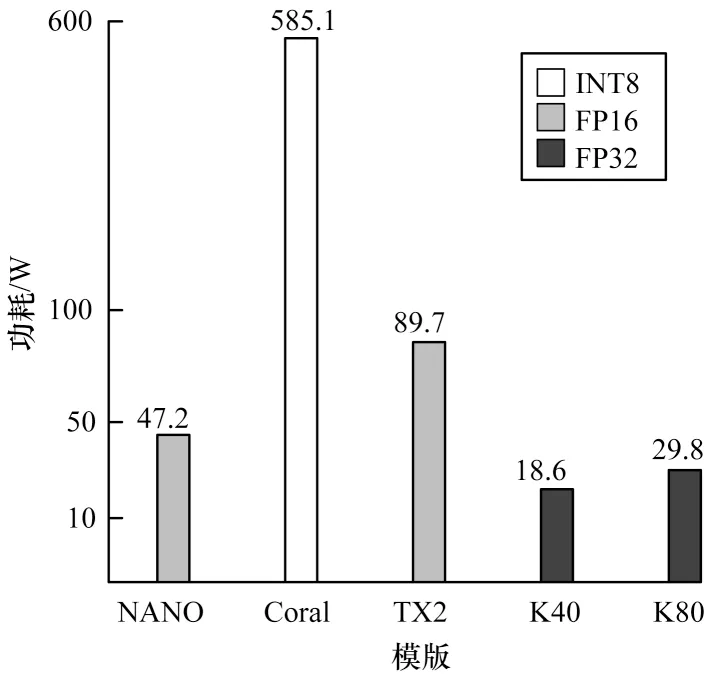
图9 NANO、Coral、TX2、K40、K80算力与功耗比值Fig.9 NANO,Coral,TX2,K40,K80 computing power to power consumption ratio
本文分别测试了4种神经网络(MNSSD V1、MNSSD V2、Inception V1、Inception V4)在3种硬件平台上实现的各项指标,实验结果如表3所示。
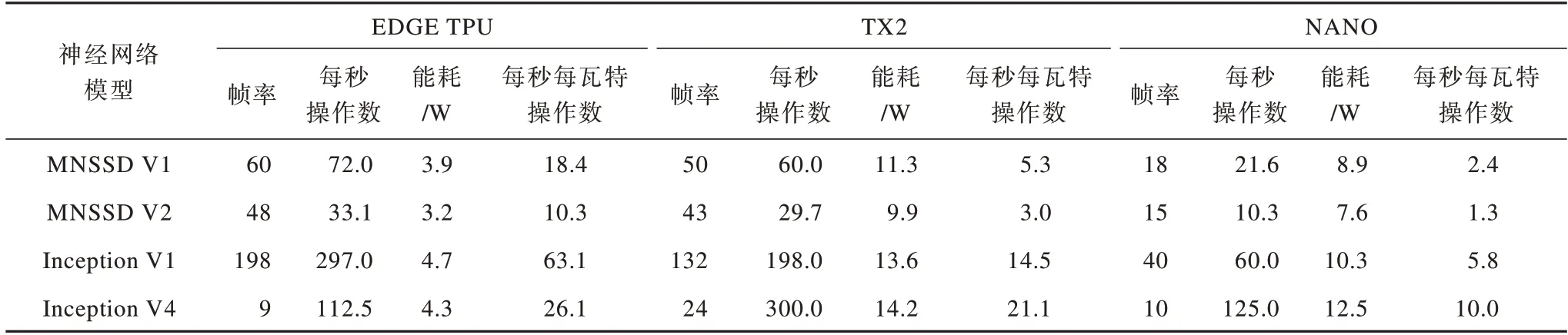
表3 4种神经网络的实验结果Table 3 Experimental results of four neural networks
4 模型改进
将传统模型VGG 16[30]在TX2上运行,每秒处理图片数约为31张,Roofline模型如图10所示。该模型在坐标系中的位置较为靠近斜线部分,说明在TX2上运行VGG 16时受访存量限制。为加快模型运行速度,更多地利用TX2的性能,对传统的VGG 16网络结构进行修改,将卷积核维度缩减到原来的1/5左右,减少通道数量以达到减小计算量与访存量的目的。实验结果表明,在准确度下降仅为5%左右的前提下,将每秒图片处理数提升至255张左右,极大地加快了模型运行速度。同时提高了TX2的资源利用率,将每秒操作数提升至0.83 TOPS左右。

图10 运行在TX2上的Roofline模型Fig.10 Roofline model running on TX2
5 结束语
本文以边缘计算板作为实验平台,分别建立了TX2、NANO、Coral开发板的理论与实际Roofline模型并进行综合比较,根据量化后的神经网络计算算力和访存量,并分析TX2、NANO、Coral 3块边缘计算板及云端服务器的功耗性能。实验结果表明,EDGE TPU计算板具有较高算力值与最优性能功耗比,其执行速度约为TX2的1.5倍和NANO的3倍,Coral的性能功耗比约为TX2的6倍和NANO的12倍。下一步将对边缘设备上运行的多种神经网络优化方式及其组合进行比较分析,研究在设备运算性能受限情况下如何最大化地优化神经网络。
