一种新的复杂网络节点重要性评估方法
2021-02-05张宪立唐建新
张宪立,唐建新
(兰州理工大学计算机与通信学院,兰州 730050)
0 概述
复杂网络将现实社会中的复杂系统抽象为网络结构图以便于描述与理解,并利用节点与节点间的连边关系来描述系统中各组成部分之间的关系。在网络信息时代,人们通过社交网络获取和传递消息,社交网络的出现极大地便利了人们的生活,并将逐渐取代电视、广播和报纸等传统信息传播方式。在整个社交网络中通常由多个重要的节点控制信息传播,因此准确识别网络中的关键节点对于研究网络信息交互问题具有重要作用[1-2]。
在现实世界中,每个社交网络都可以被抽象为一张图,其中节点代表网络中的用户,节点间的连边代表用户之间的关系[3]。近年来,研究人员对识别复杂网络中具有影响力的传播者进行了大量研究并从不同角度分析节点中心性指标,例如,只考虑节点本身拓扑结构性质的度中心性(Degree Centrality,DC)[4],判定一个给定节点是否位于其他节点最短路径上的介数中心性(Betweenness Centrality,BC)[5],代表一个给定节点到网络中其他节点的距离之和的倒数的紧密中心性(Closeness Centrality,CC)[6]以及通过网络分解确定节点重要性的K核分解中心性(K-Shell decomposition centrality,KS)[7]和H指数中心性(H-index centrality,H)[8]。
由于现有基于中心性的节点重要性评估方法经常会出现重要程度不同的两个节点被赋予相同的权值,因此不能保证网络中所有节点的重要性得到准确度量。此外,网络拓扑结构、网络规模以及节点位置都会对评估指标的精确性与适用性产生较大影响,因此,研究人员综合考虑这些因素后对现有评估方法进行了改进。文献[9]通过对K核分解中心性进行再次分解提出混合度分解中心性,文献[10]考虑了节点及其邻居性质提出局部结构中心性,文献[11]基于网络拓扑结构提出混合度中心性,文献[12]根据节点位置及其邻居节点性质提出一种新的节点重要性评估方法,上述方法均是通过可调参数来调整评估性能。文献[13]提出一种两层架构的节点重要性评估方法,文献[14]采用多属性决策技术提高节点重要性的评估准确性,但由于此类方法的评估性能取决于所采取组合方式的性能,因此与节点真实的重要程度存在一定差距。
在现有评估方法的基础上,本文根据邻居节点的拓扑结构定义改进的H指数中心性(Improved H-index centrality,IH),通过IH计算节点本身及其邻居节点的IH值之和(ILH),并将节点自身及其邻居节点的ILH值分别作为节点质量和邻居节点的质量,同时利用万有引力定律公式定义改进的重力中心性(Improved Gravity Centrality,IGC)。
1 相关定义
令G(V,E) 表示一个无向无权的简单网络,其中:V={ν1,ν2,…,νn}表示G中节点的集合;E={(νi,νj)|νi,νj∈V}表示G中边的集合,且|V|=n,|E|=m。A表示G对应的邻接矩阵,如果节点νi和νj之间存在连边,则其元素Aij=1,否则Aij=0。在复杂网络中,评估节点重要性的方法主要分为:仅考虑节点本身及其邻居节点拓扑结构的局部评估方法,考虑节点在网络全局中的作用的全局评估方法及考虑节点在网络中所处位置的位置属性评估方法3种。
定义1网络中某个节点νi的度中心性为与该节点相连接的其他节点的数目,即该节点的邻居节点数。度中心性的计算公式为:

其中,n为网络中节点的总数。
定义2网络中某个节点νj的介数中心性为任意两个节点间的最短路径通过该节点的数量与节点间总路径数量的比值,介数中心性的计算公式为:
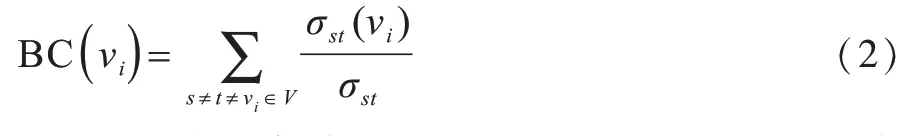
其中,σst为网络中任意两个节点s和t之间的最短路径数量,σst(νi)为通过节点νi的最短路径数量。当节点的介数中心性较大时,说明该节点在传输信息、物质和能量时负载较小。
定义3网络中某个节点νi的紧密中心性为该节点到其他节点的距离之和的倒数,紧密中心性的计算公式为:

其中,dij为节点νi到网络中某个节点νj的最短距离。
定义4 K核分解为重复去除网络中度值小于k(k=1,2,…)的所有节点及其连边,使得网络中剩下的节点的度值均大于等于k。通过对网络进行K核分解可计算出不同节点的ks值。首先将网络中所有节点的ks值设置为1,然后找到网络中所有度为1的节点并将这些节点及其连边关系删除,重新计算网络中节点的度后,再将度为1的节点及其连边关系删除,直至网络中没有度为1的节点。此时,网络中剩余节点的ks值设置为2,再重复执行上述操作,直至网络中没有度为2的节点。以此类推,直至网络中没有节点存在。节点的ks值越大,意味着该节点越接近于网络中心,最靠近中心的节点被称为K核分解中心性节点。
定义5 H指数中心性通过考虑邻居节点的度和节点自身的度来确定节点的重要性。节点中心性由节点自身及其邻居的性质决定,节点νi的H指数中心性计算公式为:
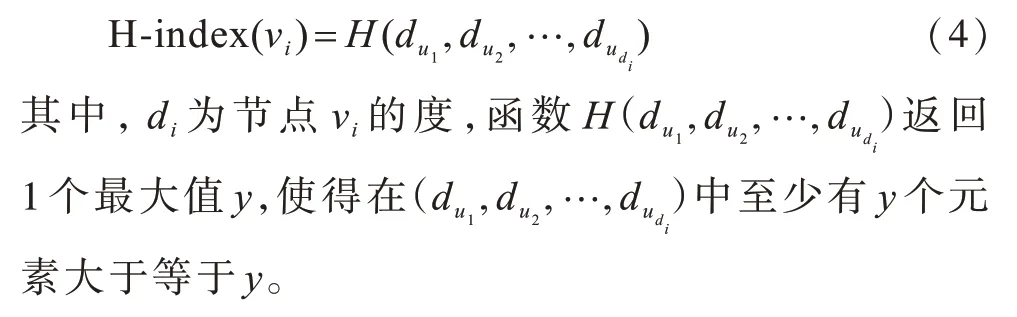
在上述定义中,度中心性、介数中心性和紧密中心性均只考虑网络图中单个节点的拓扑位置及其特征,仅从网络局部特性对节点重要性进行分析,而K核分解中心性及H指数中心性则从网络全局的拓扑结构来考虑节点的重要性,但其仍不能准确反映出网络中节点的重要程度。可见,仅考虑节点的单一影响因素不能准确评估网络中节点的性能与重要性。
2 节点重要性评估方法
一个节点可以被其邻居节点影响,然而节点的H指数对节点本身及其邻居节点信息的微小变化并不敏感,因此不利于评估节点在网络链路信息发生微小变化时的传播能力。此外,在多数情况下很难确保所收集的数据集完全正确且没有任何链路信息错误。对于一个节点,如果某些邻居节点的信息发生变化,该节点的H指数值不会受到影响,这是因为H指数只考虑具有高质量信息的邻居数量,少数邻居的微小变化不会引起节点整体传播能力的变化。对于基于度中心性和介数中心性等的节点重要性评估方法,少数边缺失或不正确的连接信息会对节点排序结果产生重要的影响。
然而,H指数对于重要程度不同的节点总是赋予相同的值,这导致了在区分这些节点的实际传播能力时存在分辨限制问题。针对该问题,本文提出一种改进的H指数中心性(IH),IH综合考虑了节点νi的所有邻居的性能,将节点的重要性进行进一步划分。节点νi的IH指数中心性计算公式为:
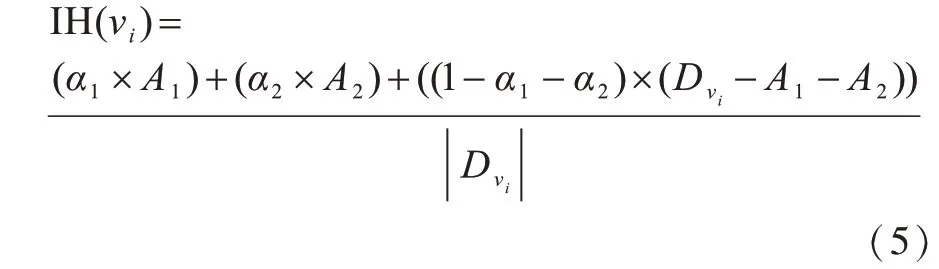
其中,α1和α2表示介于[0,1]的随机变量,A1表示在νi的邻居节点中度大于节点νi的节点个数,A2表示在νi的邻居节点中度等于节点νi的节点个数,表示节点νi的邻居节点集合,|表示节点νi的度。
节点νi及其邻居节点的ILH值计算公式为:
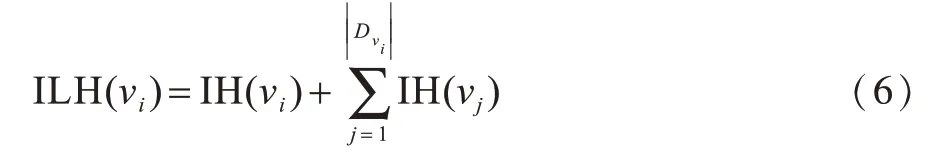
受万有引力定律的影响,本文以节点νi和节点νj的ILH值作为节点νi和节点νj的质量,两节点间的最短距离作为节点间的半径,提出改进的重力中心性。节点νi的改进重力中心性计算公式为:
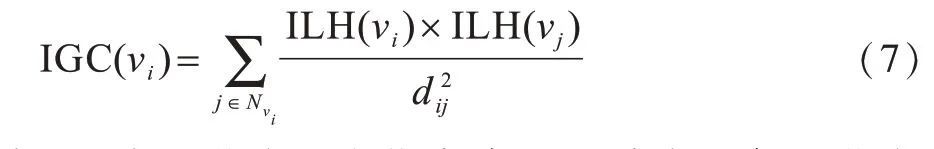
图1为一个简单网络的示意图,其中,节点数量|V|为13,边数量|E|为17。将本文IGC方法与DC、H、IH、ILH评估方法进行对比,结果如表1所示。在DC和H两种经典方法中,将所有节点分别赋予5种和3种不同的权值,即节点被划分为5种和3种等级,因此出现了重要性不一样的节点被赋予相同权值的情况,对于节点重要性的评估准确性较差。IH、ILH和IGC方法分别将所有节点赋予8种、9种和12种权值,即节点被划分为8种、9种和12种等级。本文IGC方法综合考虑了节点自身性质及网络拓扑结构,相比其他方法在区分节点重要性方面效果更佳,找出的重要节点准确性更高。
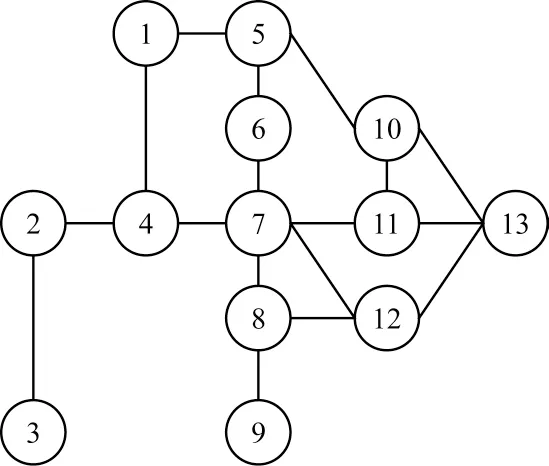
图1 一个简单网络的示意图Fig.1 Schematic diagram of a simple network
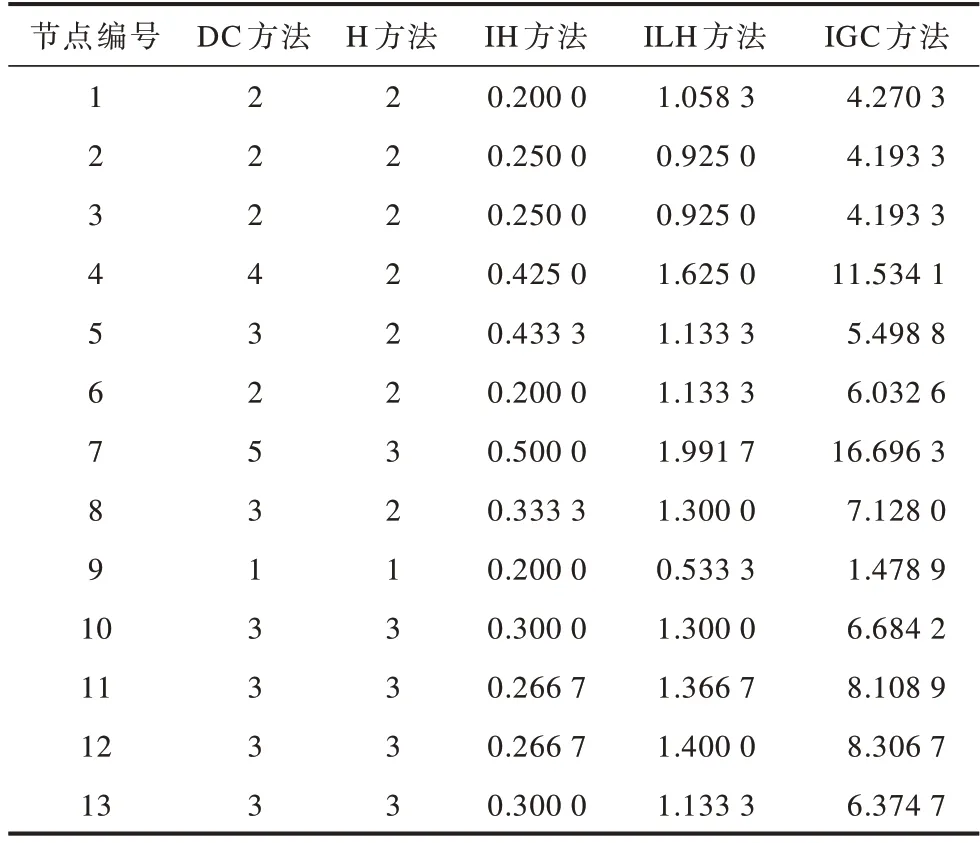
表1 简单网络中对应DC、H、IH、ILH、IGC方法的权值设置Table 1 Weight setting corresponding to DC,H,IH,ILH,IGC methods in a simple network
3 评价标准及方式
3.1 SIR传播模型
SIR传播模型[16]可用于评估网络中不同节点的传播能力。在标准随机SIR传播模型中,每个节点可以被分为易感(S)、感染(I)和恢复(R)3种不同状态[17-19]。在传播过程开始时,只有一个节点被设置为I状态,而其他节点均被设置为S状态。然后,受感染的节点将以概率α扩散至与之相连的所有易感节点,而受感染的节点将有可能以概率β进行恢复并被设置为R状态。在传播过程结束后,整个网络中只有I与R两种状态,而统计出的网络中易感节点的数量即为节点的传播能力。
在评估完节点的传播能力后,使用Kendall相关系数表示各中心性指标与真实数据之间的关系[20-21]。假设序列Χ=(x1,x2,…,xn)和序列Y=(y1,y2,…,yn)是两个与节点相关的序列,两个序列中的元素个数一致,且每个序列中的第i个元素都表示节点νi的某个属性值。将两个节点一一对应组成一个新的序列ΧY=((x1,y1),(x2,y2),…,(xn,yn)),取ΧY中的两个元素(xi,yi)和(xj,yj)(其中i≠j),若xi>xj且yi>yj或者xi<xj且yi<yj,则认为这两个元素一致;若xi>xj且yi<yj或者xi<xj且yi>yj,则认为这两个元素不一致。Kendall相关系数τ的计算公式为:

其中,C表示XY中任意两个元素所组成有序对中具有一致性元素对的数量,D表示XY中任意两个元素所组成有序对中具有不一致性元素对的数量。τ的取值范围为[-1,1],当τ>0时认为两个有序对正相关,当τ<0时认为两个有序对负相关。通过在SIR传播模型中得到的节点传播能力和中心性指标所计算出的Kendall相关系数可以较好地反映节点重要性评估方法的优劣,更优的中心性指标有助于更好地评估节点的重要性。
3.2 单调性
区分具有不同传播能力及等级的节点的能力是度量复杂网络中节点重要性评估方法的重要指标之一,而利用单调性(M)可以检验不同中心性序列对于节点重要性的区分能力[13,22]。序列R的M值计算公式为:
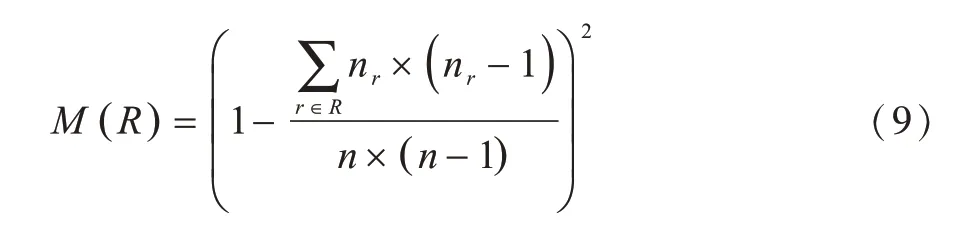
其中:n表示序列R中的节点数量;nr表示在等级r上的节点数量;M的取值范围为[0,1],其数值较大表示该方法具有较高的评估准确率。
4 实验数据集与结果分析
4.1 实验数据集
本文共使用6个真实网络数据集和2个人工网络数据集。真实网络包括Zachary空手道俱乐部工作成员关系网络(Karate)[23]、Krebs美国政治图书网络(Polbooks)[24]、爵士音乐家网络(Jazz)[25]、美国航空公司飞行路线网络(USair)[26]、Rovira Virgili大学电子邮件信息网络(Email)[27]和蛋白质相互关系网络(Yeast)[28]。人工网络包含小世界网络(WS)[29]和Lancichinetti-Fortunato-Radicchi随机网络(LFR)[30],人工网络都是通过Gephi软件自动生成。网络数据集的具体设置如表2所示,其中βth表示各个网络在SIR传播模型中的感染率阈值。
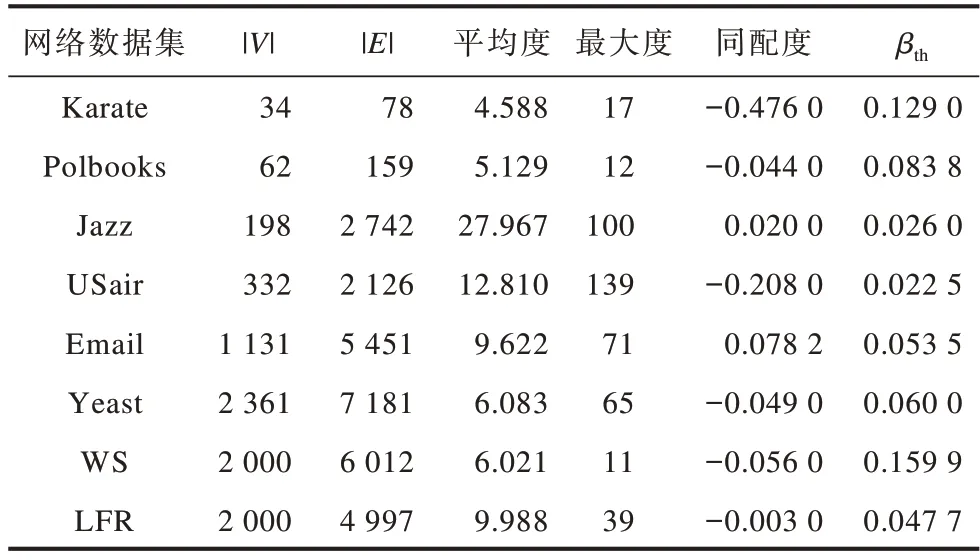
表2 网络数据集设置Table 2 Setting of network datasets
4.2 实验结果
为评价本文IGC方法的评估性能进行以下实验:1)确定评估方法和SIR传播模型之间的排序相关性,并计算出IGC方法相较于现有方法的评估准确率提升比例;2)将IGC方法与DC、BC、CC、KS和H方法进行单调性分析与比较。
4.2.1 准确性分析
为验证评估方法与SIR传播模型之间的排序相关性,通过计算节点传播效率得到网络中的最优传播者。在实验过程中:1)使用基于网络属性特征和拓扑结构的静态评估方法计算网络节点传播效率序列;2)基于网络数据集,采用SIR传播模型及Kendall相关系数τ开展动态传播模拟仿真,近似计算网络节点传播效率序列。在6个真实网络和2个人工网络数据集上,将本文IGC方法与5种评估方法进行比较,实验结果如图2所示,其中,β表示各个网络在SIR传播模型中的感染率,τ表示SIR传播模型与评估方法之间的Kendall相关系数,平行于纵坐标轴的虚线表示各个网络的感染率阈值βth。在LFR网络中,由于KS算法在感染率过低时效果不佳,为突出显示其他算法间的性能差异,因此本文在图2(h)中只呈现了τ≥0.4时的Kendall相关系数变化趋势。实验结果表明,本文IGC方法与现有方法相比在多数网络数据集中均具有更好的评估性能。由图2可以看出,在β值较小时,本文IGC方法的Kendall相关系数τ与现有方法相比有一定差距,但随着β的不断增大且接近βth时,IGC方法的评估性能要优于现有方法。在β>βth的情况下,δ=0.01时不同评估方法的Kendall相关系数τ的平均值σ(τI)计算公式为:

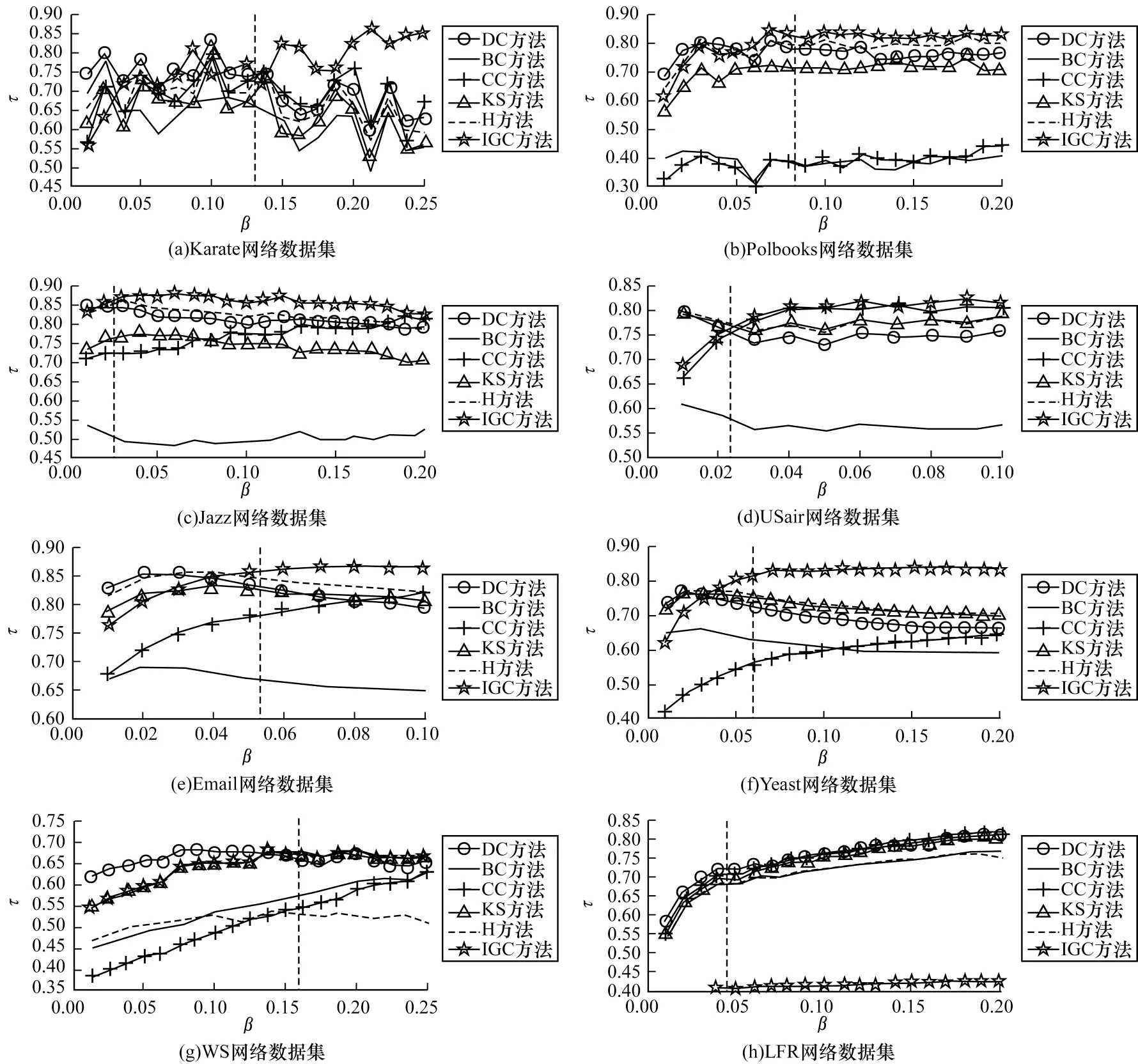
图2 在网络数据集上不同评估方法与SIR传播模型的Kendall相关系数变化趋势1Fig.2 The change trend 1 of Kendall correlation coefficient between different evaluation methods and SIR propagation model on the network datasets
网络数据集中不同评估方法的Kendall相关系数τ的平均值σ(τI)比较如表3所示。由此可以看出,本文IGC方法的σ(τI)在多数网络中要优于现有方法。
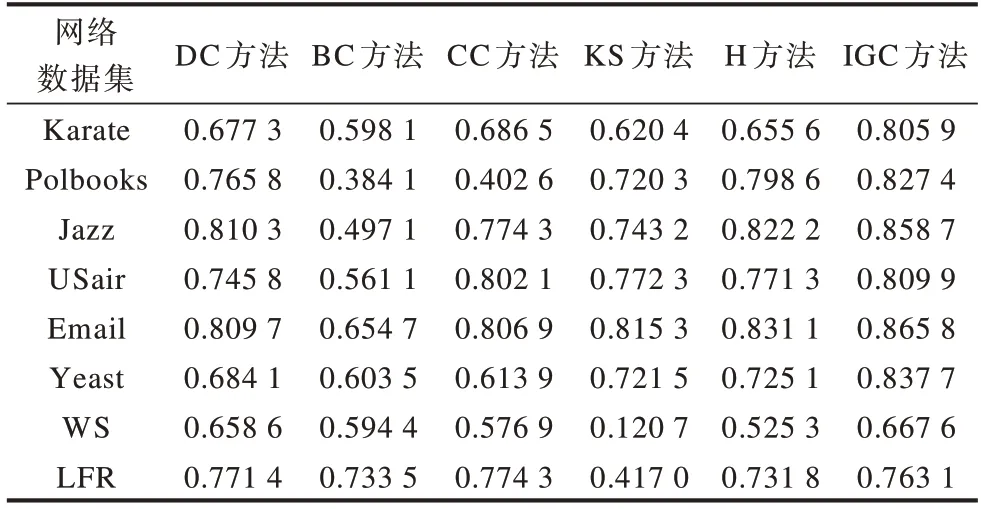
表3 网络数据集中不同评估方法的Kendall相关系数平均值比较Table 3 Comparison of average value of Kendall correlation coefficient of different evaluation methods in the network datasets
为衡量本文IGC方法相比现有方法的评估准确率提升比例,对Kendall相关系数τ的定义进行改进,计算公式修改为:
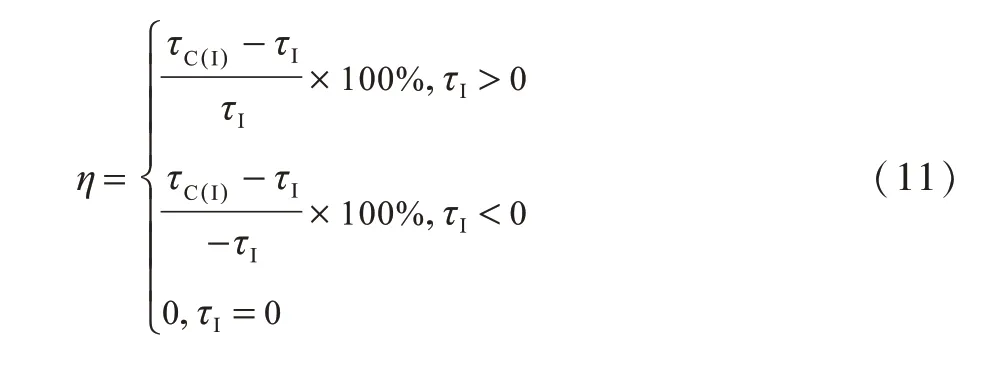
其中,τC(I)表示IGC方法和SIR模型之间的Kendall相关系数,τI表示现有方法和SIR模型之间的Kendall相关系数。当ηI>0时,意味着IGC方法优于现有方法;当ηI<0时,意味着IGC方法劣于现有方法;当ηI=0时,意味着IGC方法与现有方法相比无明显优劣区别。
图3表明在不同网络数据集中IGC方法与现有方法相比的评估准确率提升比例,其中,β表示在SIR传播模型中的不同感染率,η表示IGC方法与现有方法相比评估准确率的提升比例,平行于横坐标轴的虚线表示τC(IGC)曲线,平行于纵坐标轴的虚线表示各个网络的βth。在WS和LFR网络中,由于KS方法效果明显劣于对比方法,性能接近两个量级,因此为更直观呈现本文IGC方法和其他方法间的性能差异,本文在图3(g)和图3(h)中未呈现KS方法的Kendall相关系数变化趋势。
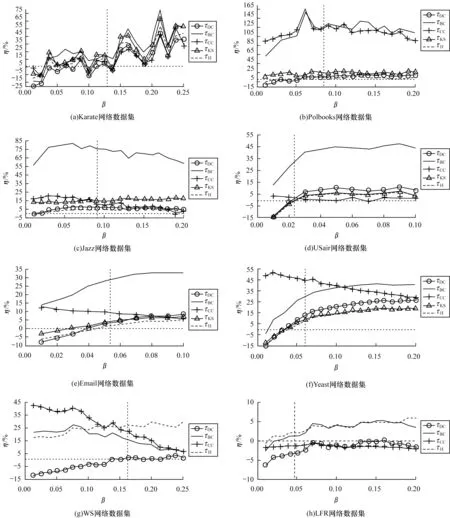
图3 在网络数据集上不同评估方法与SIR传播模型的Kendall相关系数变化趋势2Fig.3 The change trend 2 of Kendall correlation coefficient between different evaluation methods and SIR propagation model on the network datasets
由图3可看出,在β>βth时τC(IGC)相比τBC、τKS有较大的评估准确率性能提升,尽管在Polbooks和Email网络数据集中相比τKS优势不明显,但在网络数据集中的总体评估效果仍为最优。对于τDC、τCC和τH而言,在大部分网络数据集中τC(IGC)与其之间的η均大于0,即在这些网络数据集中IGC方法的评估准确性优于现有方法。
4.2.2 单调性分析
单调性用于评估排序节点的唯一性,当网络中的节点都被赋予不同的权值时所用评估方法的单调性最强,而当网络中的节点都被赋予相同的权值时,所用评估方法的单调性最弱。本文计算DC、BC、CC、KS、H和IGH方法的M值,如表4所示。可以看出,IGC方法在所有真实网络数据集中的M值均优于DC、CC、KS和H方法。然而在人工网络数据集中,IGC和BC方法均表现出较好的单调性,但从整体上看,IGC方法单调性更优,主要原因为IGC方法相比现有方法能将网络中的节点划分为更多不同的等级。
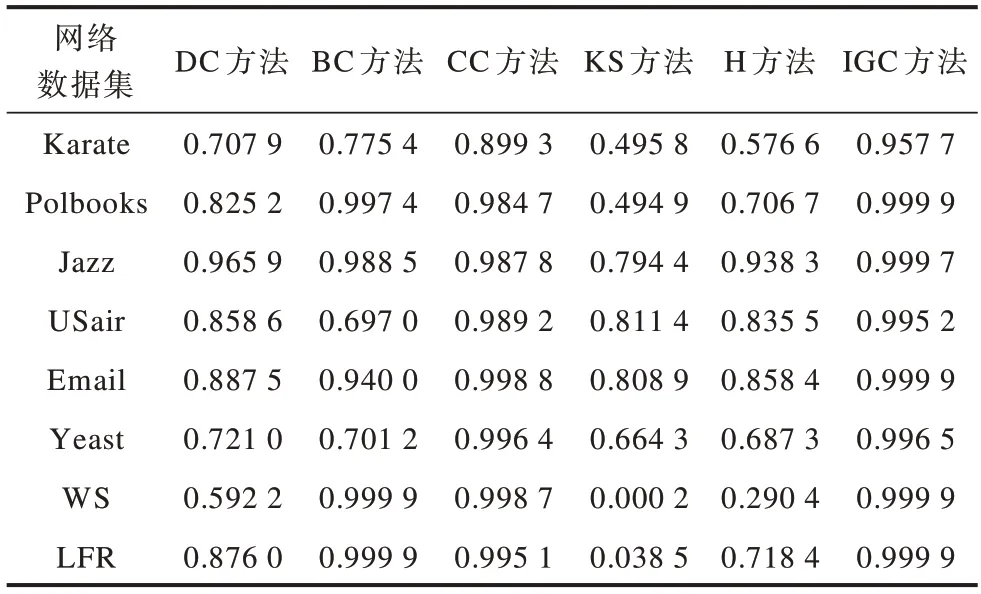
表4 网络数据集中不同评估方法的M 值比较Table 4 Comparison of M value of different evaluation methods in the network datasets
5 结束语
本文根据邻居节点的拓扑结构并结合万有引力定律,提出一种基于改进重力中心性的节点重要性评估方法。由于SIR传播模型的Kendall相关系数和单调性与节点真实传播能力之间有较强关联性,且对于具有不同传播能力的节点有较强的区分能力,因此通过实验验证了该方法的正确性与有效性,并表明其能准确地评估节点的重要性。下一步可将多种节点重要性静态评估方法与动态网络相结合,利用节点属性关联特性实现节点重要性排序。
