基于密度核心的出租车载客轨迹聚类算法
2021-02-05田智慧马占宇魏海涛
田智慧,马占宇,魏海涛
(1.郑州大学信息工程学院,郑州 450001;2.郑州大学地球科学与技术学院,郑州 450052)
0 概述
近年来,数据挖掘、无线通信、移动定位等技术发展迅速,持有GPS定位信息的移动设备以及基于位置信息服务(Location Information Service,LBS)的终端应用产生了海量时空轨迹数据[1]。这些时空数据蕴含着丰富的语义信息,可用于提取移动对象的运动特征模式和预测移动对象的运动行为[2-4],已成为目前空间数据挖掘方面[5-7]的研究热点。轨迹大数据可以分为两大类:一类是由出租车以及其他携带GPS交通工具生成的坐标序列;另一类是移动物体利用特殊装置(如信号基站、连接WiFi信号)而产生的带有时间戳的地点坐标序列[8]等。这些轨迹数据包含行人的出行规律[9]、交通拥堵规律[10]和社会活动模式等信息。轨迹聚类的目的是挖掘轨迹大数据的移动模式,通过分析聚类结果得到移动对象的出行规律。其中,研究出租车轨迹聚类对城市规划和管理、出租车调度以及城市发展具有积极意义。
文献[11]提出了移动微聚类(Moving Micro Clustering,MMC)的概念,通过应用BIRCH算法中的微聚类思想来改进移动对象的聚类过程,并利用聚类特征描述MMC的特征信息。文献[12]对OPTICS算法加以改进,提出一种基于时间维度的T-OPTICS轨迹聚类算法。该算法增加了轨迹的时间语义信息,提高了聚类结果在时间维度的准确性。文献[13]构建分段及归组轨迹聚类框架TRACLUS,利用提取到的轨迹特征点将轨迹分为多段,使粒度更细致,在此基础上利用DBSCAN聚类算法再进行归组,以避免丢失部分轨迹信息。但是DBSCAN聚类算法对参数敏感,需要利用专家先验知识获得参数并反复调整得到最优值。文献[14]提出基于路网的聚类算法框架NETSCAN,将路段聚类为一组密集路径簇后,再根据密集路径之间的相似性度量对轨迹进行聚类。文献[15]提出一种基于MFTSM的轨迹聚类算法,利用基于区域计算的位置距离解决轨迹的连续性问题。文献[16]提出一种T-CLUS轨迹聚类方法,在将原始轨迹划分成粒度较小的子段后再进行聚类,得到子轨迹对象的增广聚类序列,根据可达距离图分析不同参数的聚类效果。文献[17]提出一种基于结构相似度的轨迹聚类算法,通过提取轨迹方向、速度、转角和位置等组成的结构特征信息计算相似性度量,并基于结构相似性度量进行轨迹聚类。文献[18]在聚类算法上采用外包矩形作为核心轨迹的搜索邻域,同时重新定义轨迹核心距离与轨迹可达距离,通过邻接表代替空间索引,从而降低算法的复杂度。
现有的轨迹聚类大多基于DBSCAN、OPTICS和K-means等算法,聚类时需要计算所有轨迹或者轨迹段相互间的相似性距离,在面向海量出租车载客轨迹数据时会消耗大量的计算资源,降低算法效率。本文通过引入密度核心[19]的概念,提出一种新的载客轨迹聚类算法。计算轨迹点的变向角和速度,根据变向角阈值、累积变向角阈值和速度阈值提取轨迹特征点,以减少轨迹的数据量,加快计算速度。同时,根据聚类节点中致密核心轨迹与参与聚类轨迹的相似度距离判断轨迹的匹配程度,从而聚合相似轨迹,提高聚类的执行效率。
1 轨迹数据处理
1.1 车辆轨迹模型
出租车轨迹数据一般包含出租车营运设备编号(ID)、经纬度信息、出租车营运状态、卫星定位时间和车辆速度等属性,表1给出了出租车轨迹数据的部分属性信息。根据营运状态可将出租车轨迹分为载客轨迹和空载轨迹。载客时出租车营运状态记为1,空载时出租车营运状态记为0。为研究出租车在不同营运状态下的移动模式,本文以载客轨迹为研究对象。同时为更好地描述轨迹,对轨迹及其相关属性进行形式化描述。以TD表示载客轨迹集合,TD={T1,T2,…,TN}。载客轨迹T是由出租车在连续的时间段内行驶生成的载客轨迹点组成的集合,表示为T={pi|1≤i≤n},其中,n为出租车载客轨迹点的个数,pi为载客轨迹点。轨迹点pi是由经度、维度和时间戳组成的三元组,表示为pi=(latitude,longitude,timestamp)。
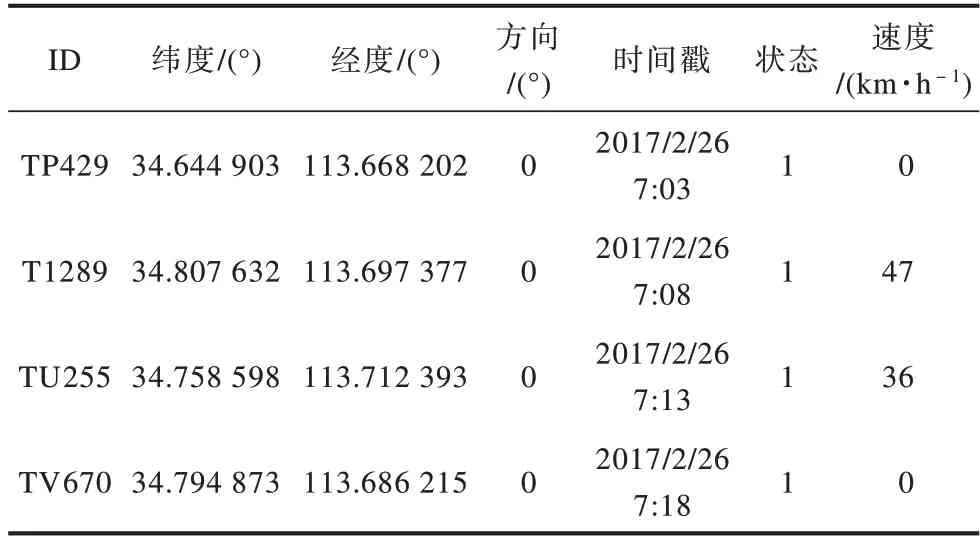
表1 出租车轨迹属性信息Table 1 Attribute information of taxi trajectory
1.2 轨迹清洗
出租车在行驶过程中,所获取GPS信息的准确度会受到各种地理环境或者天气因素的影响,生成的轨迹数据可能会包含一些噪声数据(如偏移点、回溯点和丢失点)。如图1所示,出租车在轨迹点p7偏离正确轨迹方向。由于噪声数据会影响轨迹聚类的精度,因此需要对轨迹数据进行降噪处理。轨迹降噪的目的就是寻找到轨迹原始数据中的噪声数据并对其进行平滑处理,以此消除噪声值。本文采用卡尔曼滤波法对出租车轨迹数据进行降噪处理。卡尔曼滤波模型是一种线性最优滤波器,本文利用该模型构建一个预测模型,以准确反映出租车轨迹前一个状态和当前状态的关系。在此基础上,根据噪声点的误差值对出租车轨迹进行清洗,最终消除噪声点。
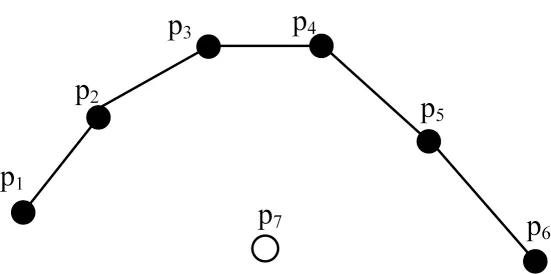
图1 噪声数据示意图Fig.1 Schematic diagram of noise data
1.3 轨迹特征点提取
出租车在行驶过程中,GPS采样的频率较高,导致轨迹中存在大量的冗余数据点,这些重复的轨迹点在进行存储和计算时会消耗大量的资源。提取轨迹特征点的目的是在保证轨迹形状基本不变的情况下尽可能减少重复轨迹点的个数。目前的轨迹特征点提取方法主要是选取道路交汇口轨迹采样点和方向变化较大的轨迹采样点,如文献[16-18]方法,其选择轨迹点方向变化超过预先设置的角度阈值的采样点作为特征点。这种方法虽然可以选取到有价值的关键点,但忽略了轨迹方向的累积变化对特征点选取的影响。当角度阈值设置过大时,在选取轨迹特征点的过程中会丢失部分有价值的轨迹采样点。如图2所示,由于载客轨迹的所有变向角{θ1,θ2,θ3,θ4,θ5,θ6}都小于角度阈值,因此这些采样点不能被选取为轨迹特征点,显然轨迹丢失了部分特征点。为解决这一问题,本文在角度阈值的基础上增加了累积角度阈值和速度阈值,以更精准地选取轨迹的特征点,如图3所示。
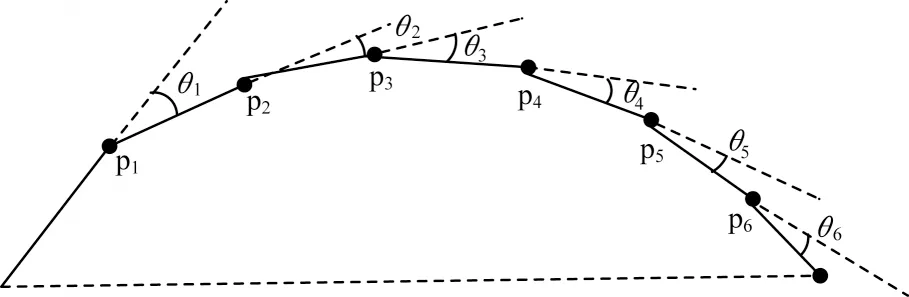
图2 累积变向角Fig.2 Cumulative turning angles
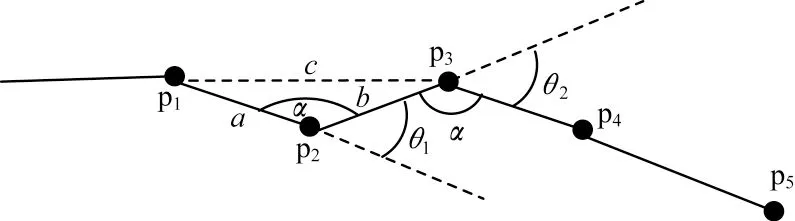
图3 轨迹特征点Fig.3 Trajectory feature points
相邻轨迹采样点p1~p3的速度分别表示为轨迹点p2的夹角表示为α,轨迹段长度a、b、c表示轨迹点p2邻边和对边的长度,夹角α的计算公式如下:

轨迹点的变向角反映了轨迹运动的变化趋势。轨迹采样点p2、p3的变向角分别表示为θ1和θ2。为便于轨迹运动趋势的相似度计算,指定外向角θ1为正值,内向角θ2为负值。由式(1)可以得到变向角θ的计算式如下:

轨迹采样点的速度变化一定程度上反映了出租车轨迹的运动模式,轨迹采样点pi的速度变化可用式(3)表示:
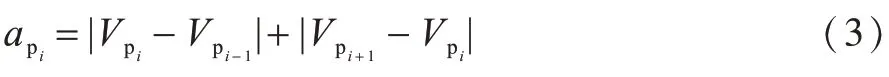
轨迹特征点提取是轨迹聚类的基础,影响到轨迹聚类的准确率和执行效率。本文借鉴文献[17]中的角度阈值算法并加以改进,在角度阈值的基础上增加累积角度阈值和速度阈值,以更精准地保留轨迹的细节信息。本文设计的特征点提取算法步骤如下:
步骤1遍历轨迹中的点序列,提取道路交汇点作为轨迹的特征点,利用式(1)、式(2)计算轨迹点的变向角,选取变向角大于ω1的轨迹点确定为轨迹特征点。
步骤2如果轨迹点累积的变向角大于累积变向角阈值ω2,那么该点也会被保留为特征点。在此基础上,利用式(3)计算轨迹点的变速大小选取大于速度阈值ε的采样点作为轨迹特征点,并将这些特征点组成的轨迹作为轨迹聚类的基础单位。
2 基于密度核心的轨迹聚类算法
2.1 DSP距离
SP(Sum-of-Pairs)距离[20]表示两条轨迹匹配点之间距离的总和,其要求两条轨迹具有相同数量的点,并且按照两条轨迹上点的顺序一一对应,将匹配点的距离求和作为轨迹相似性度量。由于该度量方法要求两条具有相同点数量的轨迹,因此不适用于轨迹长度不同的出租车载客轨迹。本文对SP距离进行改进,提出DSP(Double Sum-of-Pairs)距离,在计算两条轨迹的相似度时,根据每条轨迹自身的轨迹点去匹配另一条轨迹的点,每个轨迹点匹配到的是另一条轨迹上距离自己最小的轨迹点。因此,两条轨迹相互之间匹配到的轨迹点并不相同。由于双向计算轨迹相似度,避免了偶然性,因此可使匹配轨迹的相似度更精确。以轨迹TA和TB为例:轨迹TA到轨迹TB的距离如图4(a)所示,以轨迹TA的每个点到轨迹TB中点的最短距离和的均值表示;轨迹TB到轨迹TA的距离如图4(b)表示,以轨迹TB的每个点到轨迹TA中点的最短距离和的均值表示。
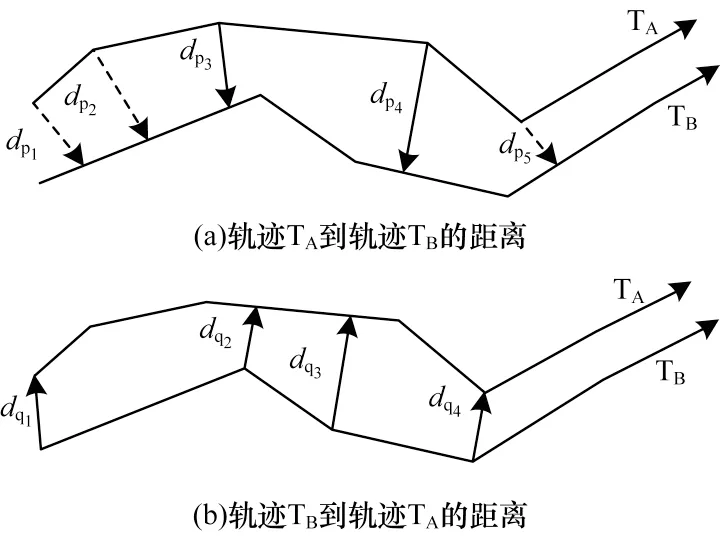
图4 轨迹对之间的相互距离Fig.4 Mutual distance between trajectory pairs
DSP距离的形式化描述如下:给定两条轨迹TA和TB,TA={p1,p2,…,pn},TB={q1,q2,…,qm}。轨迹TA中任意一点pi到轨迹TB的距离定义为pi轨迹点与TB={q1,q2,…,qm}中任意轨迹点的最小距离,如式(4)所示:

其中,q(j1≤j≤m)表示轨迹TB中的一个轨迹点。由于出租车轨迹的长度不同且受轨迹方向的影响,因此轨迹TB中的点qj到轨迹TA的距离不同于上述情况。轨迹TB中任意一点qj与轨迹TA的最小距离如式(5)所示:

定义轨迹TA到轨迹TB的距离dAB为TA中所有点到TB的距离和的均值,如式(6)所示:

同理可得轨迹TB到轨迹TA的距离dAB,如式(7)所示:

对dAB和dBA求和并取平均值可以得到DSP相似性度量,如式(8)所示:

2.2 C-Tra聚类算法
在传统的DBSCAN、OPTICS等聚类算法中,查询邻域内的轨迹对象数目需要扫描一次全部轨迹数据,轨迹聚合时需要再扫描一次全部数据,当数据量增大时,聚类的时间效率就会大幅下降。为降低聚类算法的复杂度,本文提出一种新的聚类算法C-Tra。该算法定义聚类节点作为一种数据结构来储存聚类过程中生成的聚类簇,每一个节点储存一个类簇。所有的聚类节点构成轨迹聚类集合,如式(9)所示:

聚类节点包含类簇的细节信息,由轨迹列表CTrList、致密核心轨迹h、轨迹数量n构成,如式(10)所示:

其中,轨迹列表CTrList为聚类簇中所有轨迹组成的集合,如式(11)所示,列表中的轨迹随着聚类过程满足聚类条件而动态增加,直到聚类完成,轨迹列表停止更新。
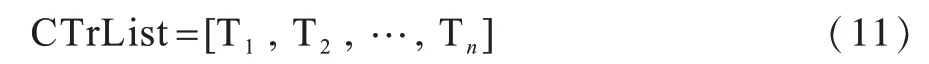
聚类节点中的致密核心轨迹h是轨迹密度最高的轨迹,轨迹Ti的轨迹密度如式(12)所示:

其中:Tj表示聚类簇中的其他轨迹;当x<0时,χ(x)=1,而在其他情况下,χ(x)=0;dc为截至距离。
在本文设计的C-Tra算法中,参与聚类的轨迹T与每一个聚类节点的致密核心轨迹的相似度距离集合如式(13)所示:

在simlist集合中,最小的相似度距离si如果小于聚类阈值,则轨迹T可分配到此距离对应的聚类节点中。当所有参与聚类的轨迹聚合到对应的聚类节点,即完成轨迹聚类。在C-Tra聚类算法中,聚类节点的致密核心轨迹需要动态确定,每当有新的轨迹添加到聚类节点中,节点就会根据轨迹列表中全部轨迹的密度重新确定致密核心轨迹,以保证聚类结果的准确性。
C-Tra聚类算法的伪代码如下:


该算法的具体步骤如下:
步骤1选择参与聚类的第一个轨迹T1并将其放入第一个聚类节点c1中([T1],T1,1),此时聚类节点的数量M=1(见算法第1行~第3行)。
步骤2选择轨迹列表中的轨迹线T(ii=1,2,…,N),分别计算轨迹Ti和所有聚类节点c(kk=1,2,…,M)的致密核心轨迹hk的相似度轨迹距离,选择相似度d=最小的聚类节点cF。(见算法第4行~第10行)
步骤3如果d小于聚类阈值θ,则将Ti添加到聚类节点c(F见算法第11行~第18行)。
步骤4如果d不小于聚类阈值θ,则创建一个新的聚类簇cM([T]i,Ti,1),M=M+1(见算法第19行~第23行)。
3 实验与结果分析
为验证C-Tra聚类算法的性能,在河南省超算中心的CPU节点上进行实验。该节点拥有2颗CPU处理器,内存为128 GB。实验数据为郑州市出租车GPS轨迹数据,时间为2017年2月26日,这些数据是1.2万余辆出租车的GPS记录,每条记录包含约30个字段信息,包括经纬度、状态、速度、方向、温度、湿度等。经过对轨迹数据的预处理,选取设备编号、运营状态、纬度、经度、时间戳这五个属性存储在ORACLE 11g中进行实验。
3.1 特征点提取前后的存储空间对比
依次选取不同数量的载客轨迹数据,如表2所示,将这些轨迹数据在提取特征点前后分别存储于.txt文件中。选取参数ω1=25、ω2=60、ε=65提取轨迹特征点。特征点提取前后轨迹数据存储空间对比如表2所示。可以看出,通过提取特征点能够大幅降低轨迹存储的数据量,减小内存空间的消耗。
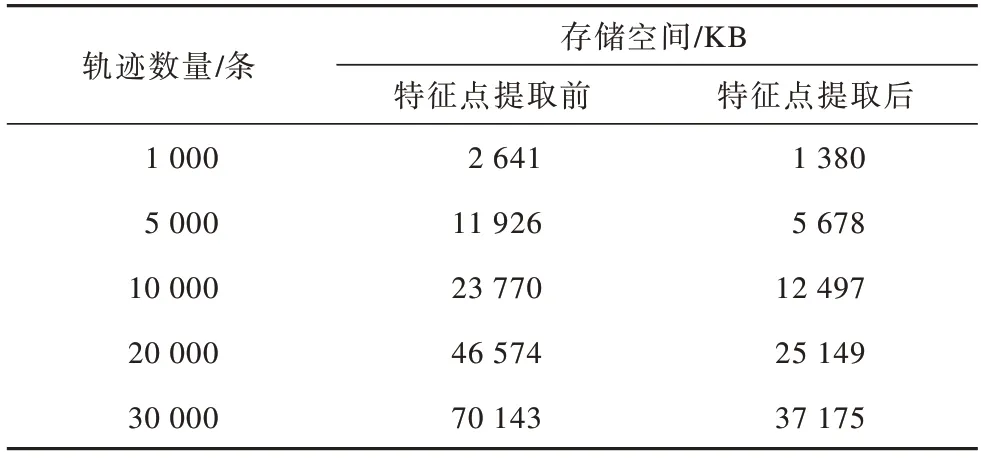
表2 特征点提取前后存储空间对比Table 2 Comparison of storage space before and after feature point extraction
3.2 聚类结果与效率评价
C-Tra聚类算法的特性是快速高效,适用于大数据量的载客轨迹。本文选择郑州市2017年2月26日午高峰(11:00—14:00)的出租车轨迹数据,选取其中10 000条轨迹作为实验数据集进行验证。对本文C-Tra算法与TRACLUS、OPTICS算法的实验结果进行对比。表3列出了3种算法的时间复杂度,其中,M表示聚类簇的数目。图5给出了3种算法的聚类效果,可以看出,本文算法可以实现对载客轨迹的聚类,且聚类的轨迹更加集中,聚类效果更为明显。由于本文算法使用整体轨迹进行聚类,因此聚类后轨迹的长度较长,保留了轨迹的整体信息,能够准确反映载客轨迹的热点路径。

表3 3种算法的时间复杂度对比Table 3 Comparison of time complexity of three algorithms
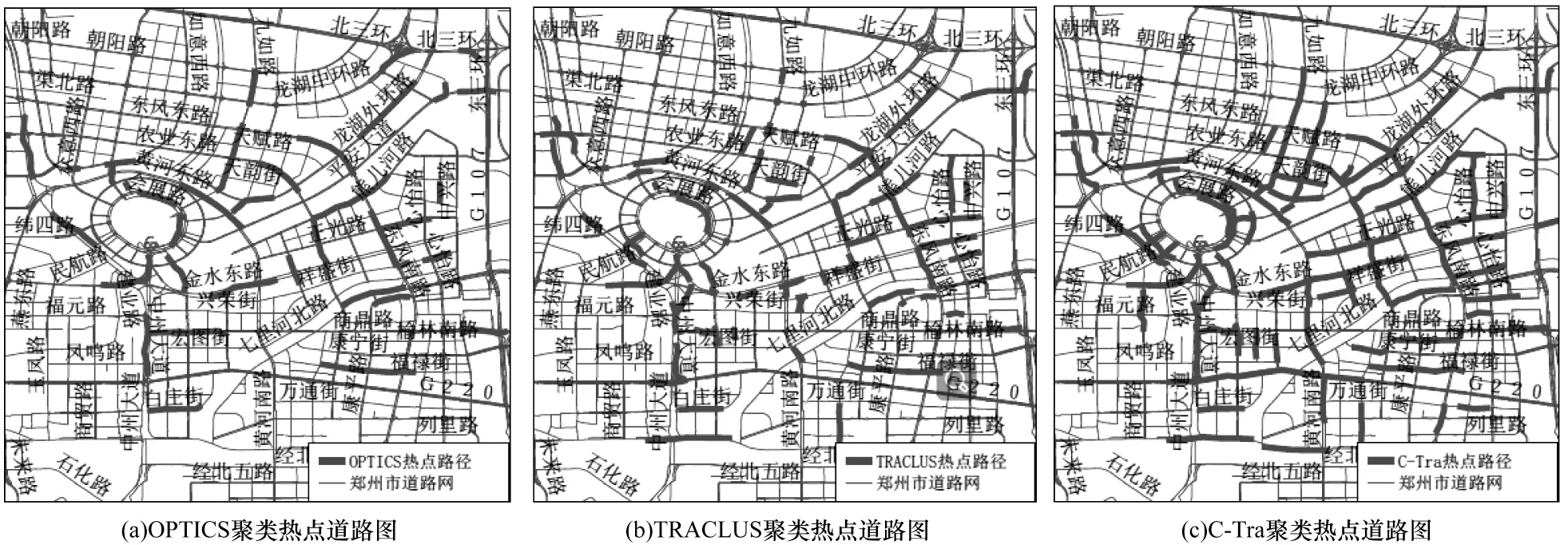
图5 3种算法的聚类效果对比Fig.5 Comparison of clustering effect of three algorithms
3种算法在出租车载客数据实验时的相关参数和运行时间如表4所示。可以看出,相对于TRACLUS和OPTICS算法,C-Tra算法具有更高的执行效率。

表4 3种算法的参数设置和运行时间对比Table 4 Comparison of parameter setting and running time of three algorithms
4 结束语
本文研究出租车载客轨迹聚类问题,考虑载客轨迹特性并从提高算法执行效率角度出发,提出具有线性复杂度的聚类算法C-Tra。根据轨迹的方向和速度提取特征点以精简轨迹,通过改进SP距离使算法适用于长度不同的出租车载客轨迹,同时利用致密核心轨迹计算动态聚类节点的核心轨迹,完成轨迹聚类。实验结果表明,与TRACLUS和OPTICS算法相比,本文算法对于出租车轨迹聚类具有较高的执行效率,可为城市规划管理和交通拥堵治理提供借鉴。
