基于参数子空间和缩放因子的YOLO剪枝算法
2021-02-05杨民杰梁亚玲杜明辉
杨民杰,梁亚玲,杜明辉
(华南理工大学电子与信息学院,广州 510641)
0 概述
自2012年AlexNet[1]获得ImageNet大型视觉识别比赛(ImageNet Large Scale Visual Recognition Competition,ILSVRC)冠军以来,以AlexNet为代表的基于深度学习的卷积神经网络受到广泛关注并得到深入发展,一系列深度学习神经网络相继出现,例如用于分类任务的Vgg[2]、GoogleNet[3]和ResNet[4]等网络以及用于目标检测任务的Rcnn[5]、FastRcnn[6]、FasterRcnn[7]、YOLOv3[8]和SSD[9]等网络。随着神经网络逐渐加深,其应用于视觉任务的网络精度已逐渐接近甚至超过人类的视觉识别水平[10],而网络模型占据的存储空间、计算时长和计算量等均不断增加,对嵌入式设备的计算性能提出更高要求,所需设备成本与电量能耗均增大。然而嵌入式设备在计算能力、存储能力以及电量能耗等方面均有一定限制[10],为了在嵌入式设备中成功部署相关的深度学习神经网络,需在保持神经网络分类或检测精度的同时对其进行压缩。
神经网络压缩算法主要包括低秩近似算法、剪枝算法、量化算法、知识蒸馏算法和紧凑型网络设计算法等。低秩近似算法是将稠密的满秩矩阵表示为若干低秩矩阵的组合,低秩矩阵又分解为小规模矩阵的乘积,从而达到简化的目的。文献[11]提出一种线性组合卷积核基底算法,用f×1+1×f卷积核替代f×f卷积核进行低秩近似。剪枝算法是通过修剪神经网络中冗余滤波器进行网络优化,删除神经网络权重矩阵中不重要的部分权重,仅保留有用部分,再重新对网络进行微调。量化算法是用低精度参数权值代替神经网络中32 bit的浮点型参数权值,目前大多数低精度的方案采用INT8型参数代替FP32型参数,通过牺牲部分精度降低占用空间。知识蒸馏算法是指通过迁移学习将预先训练好的复杂网络的输出作为监督信号去训练简单的网络,以达到压缩网络的目的。紧凑型网络设计算法是重新构建可达到原精度的小型网络,例如MobileNet和ShuffleNet网络。
由于剪枝算法无需考虑应用领域、网络架构和部署平台,符合神经网络应用于嵌入式平台的实际需求,因此本文采用剪枝算法压缩网络。现有关于剪枝算法的研究大部分基于图像分类网络,但在人工智能应用场景中,目标检测网络的应用领域更广泛,在该网络上进行剪枝更困难。YOLO网络是一种端到端的目标检测网络,属于One-stage网络,One-stage网络包括特征提取和训练分类器2个阶段,而Two-stage网络目标检测方法包括区域选择、特征提取和训练分类器3个阶段,该网络进行区域选择后产生大量冗余的候选区域,会耗费较多推理时间。与Two-stage网络相比,One-stage网络耗时更短,因此YOLO网络推理速度更快。在嵌入式设备端,推理速度是评价实用性的重要参考指标,YOLO网络中的YOLOv3网络与同样作为Onestage的SSD网络准确率相同,但是其运算速度比SSD网络快3倍[8],因此,本文选择YOLOv3网络来设计剪枝算法。
剪枝算法分为结构化剪枝算法和非结构化剪枝算法。结构化剪枝算法是通过从深度神经网络中剪去整个滤波器对网络进行简化来减少推理时间。非结构化剪枝是单独对每一层参数剪枝,这会造成不规则内存访问情况,从而降低推理效率。文献[12]利用二阶泰勒公式展开并选择参数进行剪枝,将剪枝看做正则项来改善训练和泛化能力。文献[13]根据神经元连接权值大小修剪训练后网络中不重要的连接,以减少网络参数。上述研究均采用非结构化剪枝算法基于单个权重进行剪枝,剪枝后的网络需配置专门的软件或硬件来加速运行。为使剪枝后的网络能在普适平台上运行,文献[14]引入结构化稀疏性,每个卷积单元根据其对网络在验证数据集上准确率的影响程度分配分值,通过去除分值低的卷积单元进行剪枝,然而该方法耗时较长,仅适用于小模型。文献[15]通过移除网络中权重值在0附近的滤波器及其连接特征图来降低计算成本,且无需稀疏卷积库支持,但当网络的权重值的分布非常集中或者权重值大部分不在0附近时,该方法剪枝效果较差。
文献[16]利用批量归一化(Batch Normalization,BN)层缩放因子γ在训练过程中衡量通道的重要性,去除不重要的通道压缩模型提升计算速度。在此基础上,本文提出一种利用参数子空间和缩放因子的YOLO剪枝算法,使用参数子空间避免卷积层滤波器权重剪枝范数标准差过大,采用双准则剪枝策略分别利用卷积层和BN层对YOLOv3网络进行剪枝。
1 双准则剪枝算法
剪枝算法的核心思想是寻找一种合适的评价指标去除冗余滤波器。现有剪枝算法大部分基于滤波器范数的大小,如果滤波器所产生对应特征图的L2范数接近0,则表明滤波器范数较小,该特征图对网络贡献较少,即该滤波器对网络的重要性较低。根据上述原理可对网络中滤波器按照重要性排序,并删除重要性较低的滤波器。该做法的前提是滤波器符合两个理想条件:1)滤波器范数标准差较大;2)滤波器最小范数接近0。但是大部分滤波器不符合上述条件,特别是目标检测网络滤波器。为此,本文提出基于参数子空间和BN层缩放因子双准则的剪枝算法,其具体流程如图1所示。
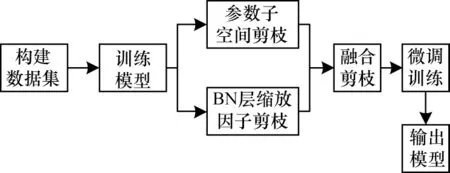
图1 本文剪枝算法流程Fig.1 Procedure of the proposed pruning algorithm
1.1 基于参数子空间的剪枝算法
参数子空间是采用k均值聚类算法将卷积层滤波器聚类得到的不同子空间,在其中进行剪枝可避免滤波器范数标准差较大以及滤波器最小范数接近0。k均值聚类算法是一种迭代求解的聚类分析算法,也是基于样本集合划分的聚类算法。该算法将样本集合划分为k个子集并构成k个类,将n个样本分到k个类中,每个样本与其所属类中心的距离最小且仅属于1个类。k均值聚类算法的复杂度为O(mnk),m为样本维数。k均值聚类算法的步骤为:1)随机选取k个样本作为k个类的中心,将样本逐个指派到与其最近中心的类中,得到1个聚类结果;2)更新每个类的样本均值作为新的类中心;3)重复步骤1和步骤2,直到收敛或符合停止条件(没有(或最少)样本被重新分配给不同的聚类、没有(或最少)聚类中心发生变化、误差平方和局部最小)为止。
k均值聚类算法以n个样本集合X为输入,以样本集合的聚类C*为输出,具体过程如下:

4)如果迭代收敛或者符合停止条件,则输出C*=C(t);否则令t=t+1,返回步骤2。
在剪枝过程中,本文使用的YOLOv3网络有较多连续的残差结构,如果对残差结构的每一层进行剪枝,则会造成部分网络层的通道数不同,无法通过捷径(shortcut)进行相加运算,导致网络不能正常运行。因此,本文避开残差结构中相连的卷积层进行剪枝,但是这些卷积层参数量仍会随着1×1卷积(conv)层通道数的减少而降低,如图2和图3所示。图2为未剪枝的残差结构,其中第一层参数量为128×256×1×1+128=32 896,第二层参数量为256×128×3×3+256=295 168。图3为已剪枝的残差结构,其中第一层参数量为37×256×1×1+37=9 509,第二层参数量为256×37×3×3+256=85 504。可以看出,在避开相连卷积层进行剪枝后,未剪枝的卷积层参数量会出现明显下降,从而简化算法并减少计算量。

图2 未剪枝的残差结构Fig.2 Residual structure without pruning

图3 剪枝后的残差结构Fig.3 Residual structure after pruning
选择非残差结构需要相加的卷积层,对每个卷积层的滤波器进行k均值聚类分析,使用肘部法则确定每个卷积层的k值。k均值聚类是以最小化样本与质点平方距离误差(loss)作为目标函数,若将各簇质点与簇内样本点的平方距离误差和称为畸变程度,则一个簇的畸变程度越低表明簇内结构越紧密,一个簇的畸变程度越高表明簇内结构越松散。畸变程度通常随聚类类别的增加而减小,但对于有一定区分度的数据样本,在k值达到某个临界点时畸变程度将急剧减小,此时聚类性能较好。基于畸变程度的变化,YOLOv3不同卷积层可训练不同k均值聚类模型,从而得到每个卷积层最适合的聚类类别数。图4和图5分别表示第63层和第103层卷积层在不同k值下各簇质点与簇内样本点的平方距离误差。
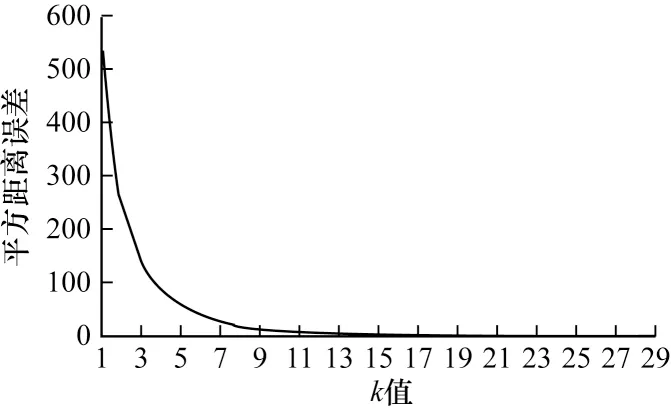
图4 第63层卷积层的聚类loss曲线Fig.4 Cluster loss curve of the 63rd convolution layer

图5 第103层卷积层的聚类loss曲线Fig.5 Cluster loss curve of the 103rd convolution layer
由于本文在聚类分析前先将卷积层每个滤波器的权重进行求和,再对求和后的权重进行聚类分析,因此聚类分析针对单层网络进行,在单层网络上使用肘部法则确定k值。使用该方法对每个卷积层用不同k值进行聚类分析得到各卷积层聚类结果。计算卷积层每个聚类类别中滤波器的权重,将其按照由大到小排序,并根据一定比例去除权重较小的滤波器。本文使用基于参数子空间的方法对单层卷积层进行剪枝实验,剪枝率设置为50%,采用平均精准度均值(Mean Average Precision,MAP)作为剪枝效果的评价指标。图6为第63层卷积层在不同k值下MAP的变化,可以看出,当k为4时剪枝所得MAP值最大,k=4即为图4中聚类loss曲线的畸变临界点。图7为第103层卷积层在不同k值下MAP的变化,可以看出,当k为4时剪枝所得MAP值最大,k为4即为图5中聚类loss曲线的畸变临界点。由此可证明,使用肘部法则选出的k值有效。先用k均值聚类再根据权重排序进行剪枝,可避免滤波器范数标准差较大以及滤波器最小范数接近0。

图6 第63层卷积层在不同k 值下的MAP变化曲线Fig.6 MAP variation curve of 63rd convolution layer with different k values
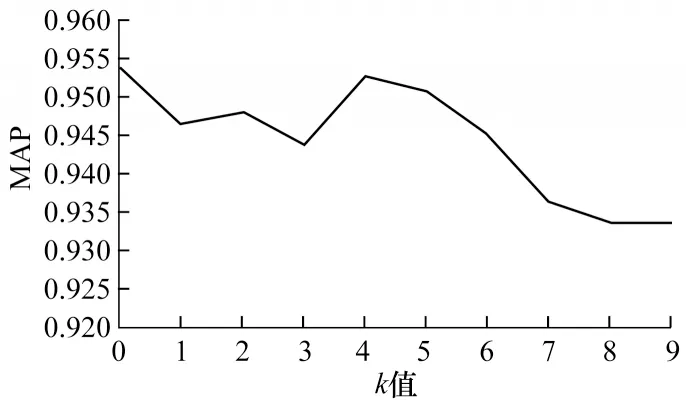
图7 第103层卷积层在不同k 值下的MAP变化曲线Fig.7 MAP variation curve of 103rd convolution layer with different k values
1.2 基于BN层缩放因子的剪枝准则
由于BN层可有效防止梯度爆炸并加速网络收敛,因此其被应用于各种卷积层神经网络中,位于卷积层之后,以对卷积层后的特征图完成归一化操作。然而若BN层仅在卷积层后进行归一化,再直接将数据送入下一层进行卷积计算,则网络将无法学习输出的特征分布。由于BN层后有ReLu激活层,若BN层后的特征图数据大部分小于0,那么其经过ReLu激活层后将失去大部分特征值,因此,BN层需通过优化缩放系数γ和偏移系数β对数据进行归一化处理,使网络能学习到输出的特征分布。
算法1BN层缩放因子剪枝算法

在算法1中,μB和分别为输入的均值和方差。卷积层每个滤波器均会产生1个特征图,每个特征图BN层在归一化时有唯一的缩放系数γ与其对应,通过缩放值可选择冗余的特征图,再由特征图选出冗余的滤波器,从而根据缩放系数大小来判断滤波器的重要性。本文利用缩放系数γ从BN层角度更全面地判断滤波器的冗余程度。
1.3 双准则融合剪枝
双准则融合剪枝是结合参数子空间和BN层缩放因子两种剪枝算法去除冗余的滤波器以实现最精简的网络结构。参数子空间剪枝算法是从卷积层角度寻找网络中冗余的滤波器,BN层缩放因子剪枝算法是从BN层角度寻找不重要的滤波器,本文将原始YOLOv3网络结构通过上述两种算法进行剪枝,以最大化压缩网络。
算法2双准则融合剪枝算法
双准则融合剪枝算法将训练数据、原始YOLOv3网络结构和初始化权重以及剪枝率P为输入,以剪枝后网络为输出,具体过程如下:
1)原始YOLOv3网络在训练数据上进行训练。
2)选取可剪枝的网络卷积层。
3)对选取的卷积层运用肘部法则,得到每个卷积层剪枝需要的k值。
4)对选取的卷积层进行聚类操作,得到参数子空间。
5)在参数子空间进行权重排序,根据剪枝率得到需要删除的滤波器。
6)在步骤2后,对每个卷积层的BN层缩放因子进行排序,根据剪枝率得到需去除的滤波器。
7)将步骤5和步骤6中得到的滤波器求并集。
8)在步骤2后去除步骤7中的滤波器总和,得到精简的网络结构。
9)在训练数据上对新的网络结构进行微调,得到最终需要的网络模型。
10)若剪枝结果不理想,则重新选择剪枝率并返回步骤5。
在上述过程中,剪枝率由实验获得,在保持网络精度下结合参数子空间和BN层缩放因子两种剪枝方法可最大限度地压缩网络。
2 实验与结果分析
将本文提出的基于参数子空间和BN层缩放因子的双准则剪枝算法(以下称为本文双准则剪枝算法)与其他剪枝算法在CIFAR10分类数据集上的网络精度和浮点计算量进行对比,并将参数子空间剪枝算法、BN层缩放因子剪枝算法和本文双准则剪枝算法在YOLOv3网络中得到的实验结果进行对比,以分析本文方法的剪枝性能。
2.1 不同剪枝算法的对比
将不同剪枝算法在CIFAR10数据集上实验结果进行对比,如表1所示(“—”表示数据不详,60U40是双准则融合剪枝算法的剪枝率,其中60%的剪枝率属于BN层缩放因子剪枝算法,40%的剪枝率属于参数子空间剪枝算法)。可以看出,PF[17]算法的浮点计算量仅减少27.6%,网络精度却下降1.73%,这是因为该算法主要考虑滤波器权重的绝对值问题,默认了权重分布需遵循滤波器范数标准差较大以及滤波器最小范数接近0这两个条件,对剪枝网络和数据有一定的限制。CP[18]算法采用LASSO回归方式选择剪枝通道,但由于是逐层剪枝,因此剪枝后的网络精度下降较多。LCCT[19]算法由于在卷积结构中加入LCCL加速卷积层,增加了训练难度,因此浮点计算量无明显减少。SFP[20]算法采用动态剪枝方式,但由于其剪枝策略仍根据权重的范数并保留BN层的偏置系数,因此造成剪枝精度随机下降。AMFSF[10]算法引入注意力机制进行剪枝,并采用范数计算注意力的重要性,但其会忽略部分剪枝细节从而降低网络稳定性。与其他算法相比,本文双准则剪枝算法从权重和BN层两个角度进行剪枝,在保证剪枝精度基本不变的情况下,其在ResNet56网络中浮点计算量减少46.3%,在ResNet110网络中浮点计算量减少45.6%。与其他剪枝算法相比,本文双准则剪枝算法在分类过程中具有较好的剪枝效果。

表1 不同剪枝算法在CIFAR10数据集上实验结果的对比Table 1 Comparison of experimental results of different pruning algorithms on CIFAR10 dataset
2.2 YOLOv3剪枝效果对比
本文以Ubuntu18.04软件为实验平台,采用i9-9900K CPU和2080ti显卡,使用Deer数据集,其中训练集有4 367张图像,测试集有519张图像。将参数子空间剪枝算法、BN层缩放因子剪枝算法和本文双准则融合剪枝算法在YOLOv3网络中不同剪枝率下的剪枝效果进行对比,结果如表2~表4所示(70U40是双准则融合剪枝算法的剪枝率,其中70%的剪枝率属于BN层缩放因子剪枝算法,40%的剪枝率属于参数子空间剪枝算法)。可以看出:参数子空间剪枝算法可去除所选卷积层50%的滤波器,MAP值下降约0.029,计算时间从每张图像0.010 3 s下降到每张图像0.008 0 s,网络参数量下降约50%;BN层缩放因子剪枝算法可去除所选卷积层80%的滤波器,MAP值仅下降约0.007,计算时间下降到每张图像0.007 3 s,网络参数量下降约80%;本文双准则剪枝算法的MAP值下降约0.032,计算时间下降到每张图像0.006 6 s,网络参数量下降约85%。

表2 YOLOv3网络中参数子空间剪枝算法在不同剪枝率下的实验结果Table 2 Experimental results of parameter subspace pruning algorithm in YOLOv3 network at different pruning rates
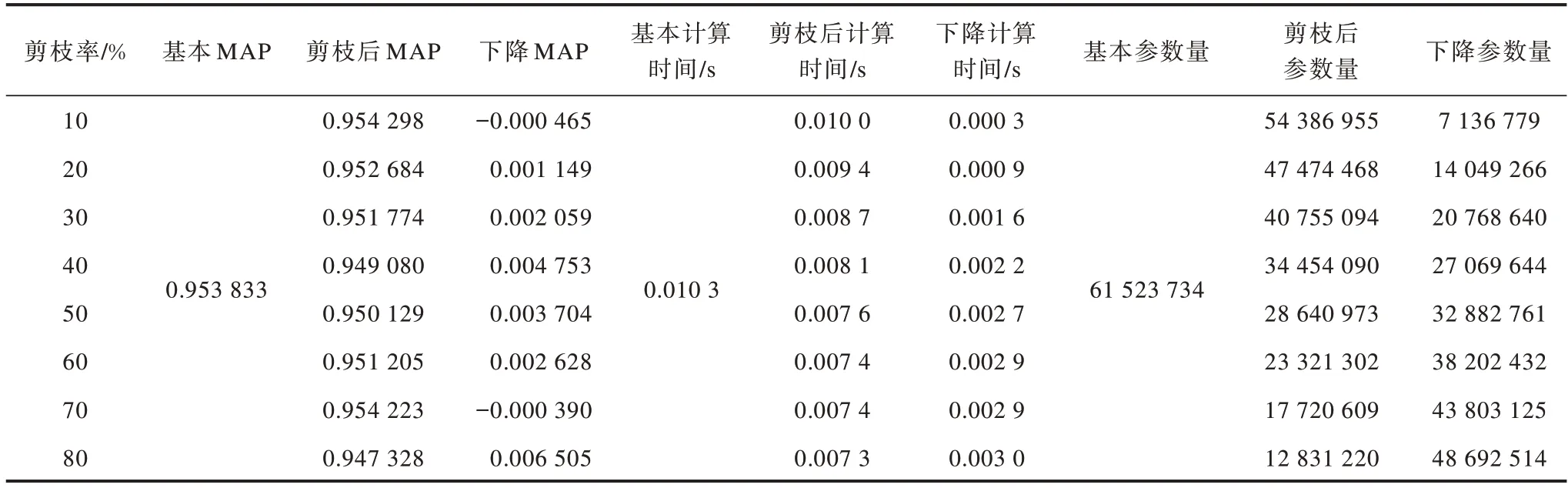
表3 YOLOv3网络中BN层缩放因子剪枝算法在不同剪枝率下的实验结果Table 3 Experimental results of BN layer scaling factor pruning algorithm in YOLOv3 network at different pruning rates

表4 YOLOv3网络中本文双准则融合剪枝算法在不同剪枝率下的实验结果Table 4 Experimental results of double criteria fusion pruning algorithm in YOLOv3 network at different pruning rates
3 结束语
为保证目标检测YOLOv3网络在嵌入式设备上正常运行,本文提出一种结合参数子空间和BN层缩放因子的双准则剪枝算法。采用参数子空间剪枝算法避免权重分布过于集中,使用BN层缩放因子剪枝算法去除不重要的滤波器,同时利用卷积层和BN层进行剪枝以最大化压缩网络。实验结果表明,与PF、CP等剪枝算法相比,该算法可保持较高网络精度且计算量更少。下一步将对网络量化进行研究,在保证网络精度的同时进一步压缩网络并提升计算速度。
