多重检验加权融合的短文本相似度计算方法
2021-02-05石彩霞李书琴
石彩霞,李书琴,刘 斌
(西北农林科技大学信息工程学院,陕西杨凌 712100)
0 概述
文本相似度计算是文本处理领域的关键性技术,广泛应用于自然语言处理(Natural Language Processing,NLP)的信息检索、文本分类、自动问答和文本重复性检测等多种任务中[1]。近年来,文本相似度计算在电子商务、新闻推送、推荐系统等热门领域也受到极大关注[2]。
目前,文本相似度计算方法主要分为三类,一是基于字符串的计算方法,如通过统计文本共有字词数量计算相似度的N-gram[3]和Jaccard[4]算法,二是基于语料库的计算方法,如忽略词序、句法结构等关键性要素利用词向量[5]基于词袋模型计算相似度的VSM[6]和LSA[7]等,三是基于深度学习的计算方法,如基于深度学习语义匹配模型的DSSM[8]、通过神经网络生成词向量以计算相似度的Word2vec[9]和Glove[10]等。文献[11]基于CNN并引入多注意力机制,通过关注词汇间和句子间的语义信息来计算句子相似度。文献[12]提出一种Siamese LSTM方法,其利用记忆单元使LSTM能够存储长序列信息,从而解决RNN长期依赖的问题。
现有多数文本相似度计算相关研究仅考虑单一文本特征而进行相似度计算。马慧芳等人[13]融合词项共现距离相关度和类别特征来计算短文本相似度。邓涵等人[14]从句子结构角度对句法和依存关系进行分析计算。YANG等人[15]将浅层句法结构化特征用依赖树表示并计算相似度,但该方法不能分析句子的深层语义信息。张小川等人[16]融合主题相似度因子和词语共现度因子提出基于LDA的短文本相似度计算算法,但其未考虑文本的语义、词序和主题关联性等特征。
短文本具有句子简短、词语较少、语义丰富和特征稀疏的特点,本文综合考虑短文本的多种特征因素,如共现词、词频及语义信息等对文本相似度的影响,在分析传统文本相似度计算方法的基础上,利用基于深度学习的方法计算相似度,通过阈值对相似度值进行检验筛选,并将改进的Damerau-Levenshtein距离算法、考虑词频的语义相似度计算算法、基于Word2vec与LSTM的相似度计算算法3种考虑单因素的计算方法进行加权融合,应用于短文本相似度计算,从而使得计算结果更加准确合理。
1 相关工作
1.1 改进的Damerau-Levenshtein距离算法
Levenshtein距离[17]于1965年由苏联数学家Vladimir Levenshtein提出,其又被称为编辑距离(Edit Distance),主要用于比较2个字符串的相似度。Levenshtein距离是指将一个字符串序列通过插入、删除和替换等单字符操作转变为另一个字符串所需的最小操作数量。
短文本具有句子简短的特点,相似文本之间会有较多的共现词,适合通过编辑距离计算相似度。Frederickj Damau提出了改进Levenshtein距离的Damerau-Levenshtein距离[18],其考虑置换操作对编辑距离的影响,但本质依然是编辑距离。Damerau-Levenshtein距离的计算方式如下:
设有2个字符串S和T,其中,S为长度为m的源字符串,T为长度为n的目标字符串,用dlS,T表示S和T之间的Damerau-Levenshtein距离,则可以构造(m+1)×(n+1)阶矩阵Di,j=D(s1,s2,…,si,t1,t2,…,tj),0≤i≤m,0 ≤j≤n,通过式(1)来计算2个字符串之间的Damerau-Levenshtein距离:
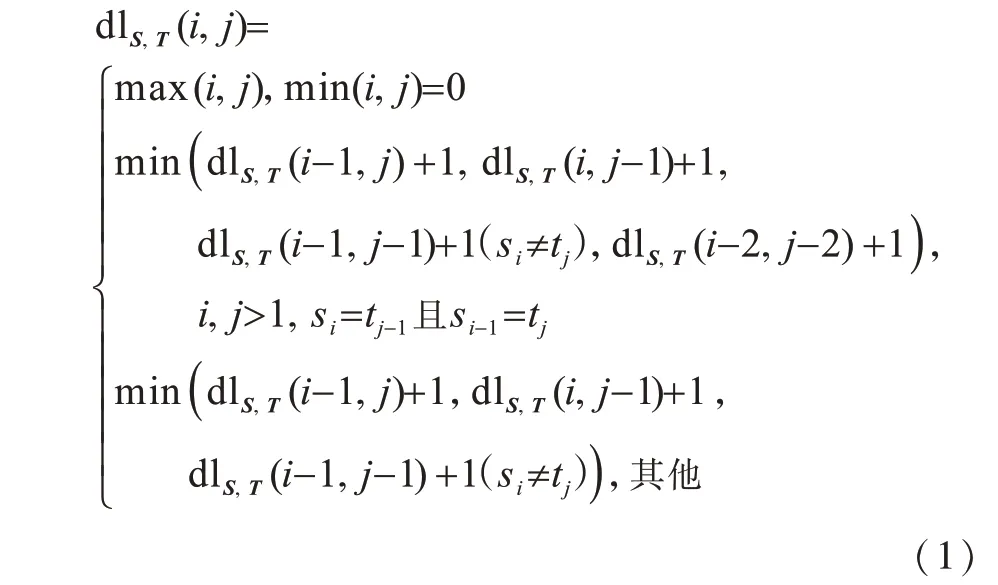
由式(1)计算得到的Damerau-Levenshtein是一个正整数,如果用其衡量相似度,将缺少一个限定值作为界定是否相似的标准,因此,本文提出DLR(Damerau-Levenshtein-Ratio),其将2个文本的编辑距离转化为比值形式,通过式(2)计算DLR以表示2个文本之间的相似度:

其中,Lmax表示字符串S和T长度的最大值。DLR的计算过程伪代码如算法1所示。
算法1Damerau-Levenshtein-Ratio计算算法

1.2 考虑词频的语义相似度计算算法
传统基于句子形态的文本相似度计算算法[19]利用词形、句长和词序特征计算相似度,但它们忽略了文本的语义信息,导致效果不佳且对短文本不适用。短文本会因词语数量较少而引起语义稀疏性,因此,本文在计算语义信息的基础上,通过词频对词语赋予权重,并且考虑未收录词和文本语义不全对相似度的影响,分别计算只有关键词和含有非关键词2种情况下的文本相似度,取两者较大值作为文本的相似度值。
定义S1、S2为2个待计算相似度的句子,令KS1={w1,w2,…,wm}为句子S1的关键词集合,其中,wk表示从S1中提取到的关键词,同样地,KS2={w1,w2,…,wn}为句子S2的关键词集合,则利用传统基于知网知识库的方式计算句子S1和S2关键词的语义相似度如下:

短文本具有句短词少的特点,使得词频大的词语对句子相似度计算有较大影响,因此,本文根据词频对词语赋予权重,句子S1中的词语w1对句子S2的相似度为w1对S2中全部词语相似度的最大值。改进后S1对S2的关键词集合的相似度计算如式(4)、式(5)所示:
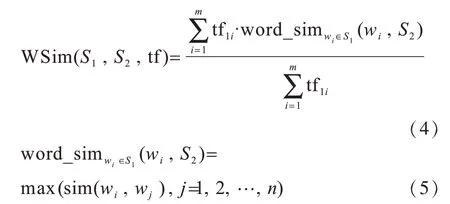
其中,tfi表示词语i在短文本中的词频。
在知网知识库中,一个词语具有多个义项,而每个义项又由多个义原组成。知网中2个词语的义项相似度是通过第一基本义原、其他义原、关系义原和关系符号义原组合后加权表示的[20],义项相似度计算如式(6)所示。假设词语w1和词语w2的义项分别表示为w1={s11,s12,…,s1m}、w2={s21,s22,…,s2n},则词语w1和词语w2的相似度为词语w1和词语w2义原相似度的最大值,如式(7)所示。
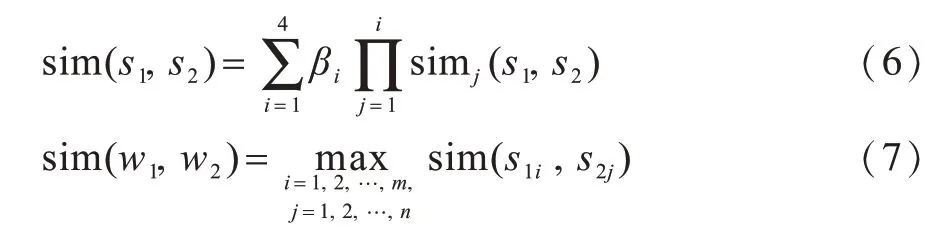
在式(6)中,β1≥β2≥β3≥β4,sim(s1,s2)表示义项s1和义项s2的第一义原相似度,以此类推。4种因子按照文献[21]取值,β1=0.4,β2=0.3,β3=0.2,β4=0.1。吴健等人[22]认为节点深度对义原相似度有一定影响,通常通过2个义原之间的路径距离来计算义原相似度,如下:

其中,d表示2个义原在层次结构中的路径距离,α是调节参数,取值为1.6。
令句子S1和句子S2的相似度KTSim为KSim和TSim的最大值,如式(9)所示。KSim表示仅有关键词时句子的相似度,计算公式如式(10)所示,TSim表示含有非关键词时句子的相似度,计算公式如式(11)所示。TSim的计算方式与KSim相同,只是两者参与计算的词语数量不同。
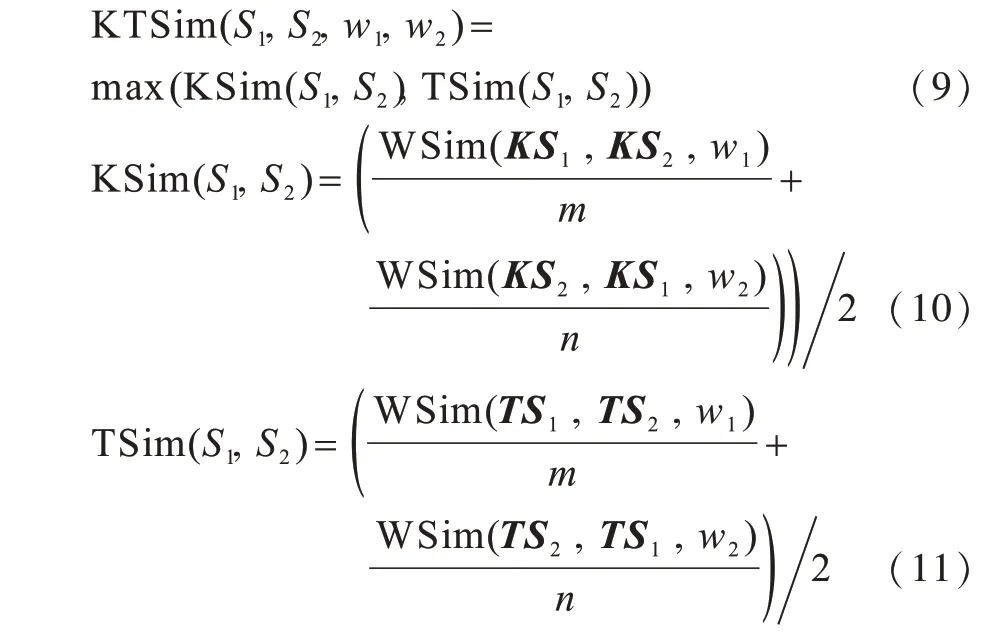
1.3 基于Word2vec与LSTM的相似度计算算法
Word2vec即为词向量,是由Google公司开源的一款深度学习模型[9],作用是将自然语言中的词语或者文字转化为计算机可以理解和处理的向量形式。Word2vec可分为CBOW(Continue Bag-of-Word)和Skip-gram 2种模型。CBOW输入某个特征词的上下文关联词的词向量,输出该特征词的词向量,而Skip-gram相反,其输入特征词对应的词向量,输出特征词的上下文对应词的词向量。
HOCHREITER等人[23]提出长短期记忆(Long Short-Term Memory,LSTM)网络,其为一种特殊的RNN,使用记忆单元替换原RNN中的隐层节点,以达到学习长期依赖信息的目的。LSTM的计算过程如式(12)~式(17)所示,其中,式(12)和式(13)表示更新记忆细胞的状态,式(14)~式(16)分别为增加历史信息的输入门、遗忘历史信息的遗忘门和输出门,式(17)表示利用tanh作用于当前记忆细胞状态,再由输出门输出最后信息。
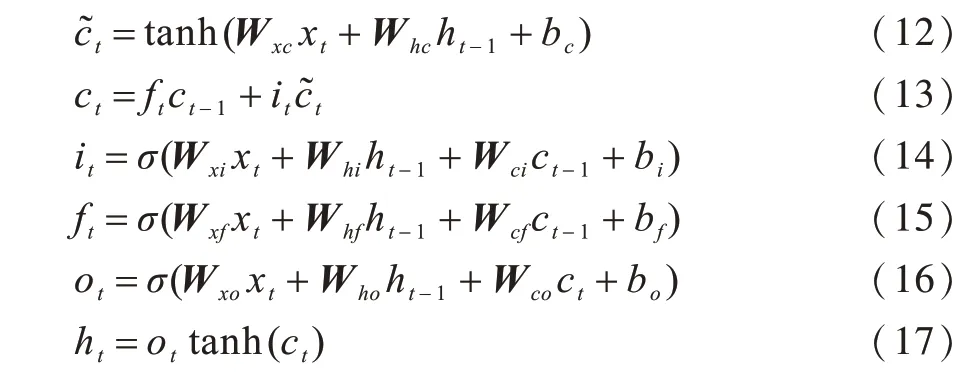
其中,Wxy为权重矩阵,表示从神经元x到y的权重,ct表示当前细胞状态表示候选值,x表示记忆单元的输入,h表示输出,b表示偏置权重。
Skip-gram相较于CBOW模型有更高的语义准确率,其可以通过跳跃词汇来构造词组,避免因窗口大小限制而丢失文本的语义信息。因此,本文采用Skip-gram模型作为训练框架,训练窗口设置为5,词向量维度设置为100。以LSTM为基础,由输入层将输入的句子按照单个词语在词典中的特定位置关系得到编号序列,嵌入层利用Word2vec模型将由输入层得到的词语编号序列映射为词向量,再将得到的词向量作为LSTM层的输入,将LSTM层输出的结果进行拼接并作为全连接层的输入,利用Dropout防止过拟合,最终由输出层输出2个文本的相似度值。基于Word2vec与LSTM的相似度计算模型结构如图1所示。
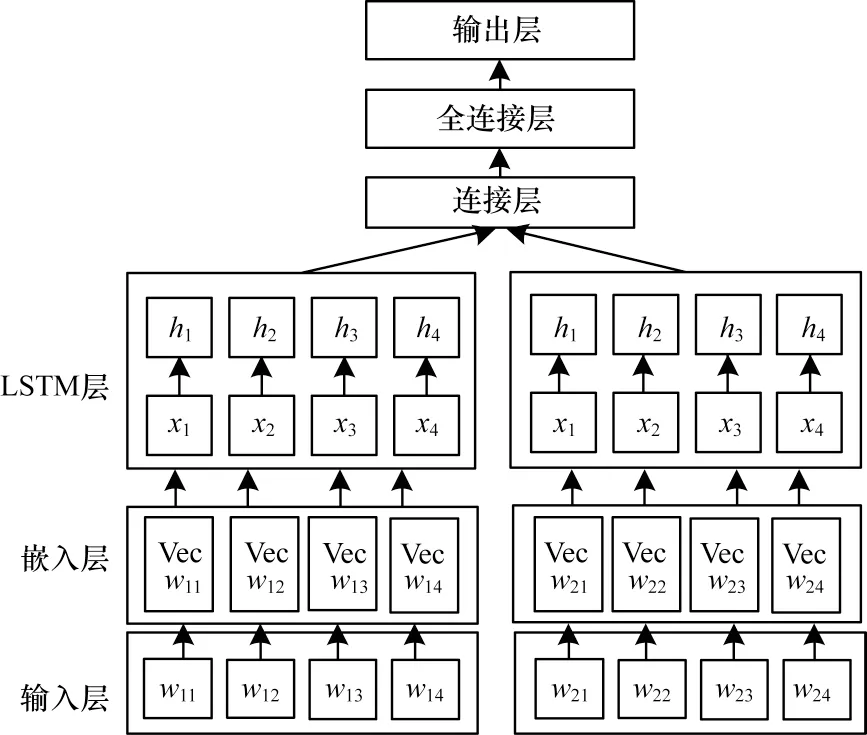
图1 基于Word2vec与LSTM的相似度计算模型结构Fig.1 Structure of similarity calculation model based on Word2vec and LSTM
2 多重检验加权融合的相似度计算
基于改进Damerau-Levenshtein距离的相似度计算(DLRSim)算法考虑2个短文本之间的词序和共有词,从短文本句短词少的结构特征角度计算相似度;基于语义的相似度计算(KTSim)算法为解决短文本的特征稀疏性问题,加入词频并考虑关键词和非关键词对短文本相似度的影响,结合知网义原信息从词语的义原层面计算句子的相似度;基于Word2vec与LSTM的相似度计算(WLSim)算法从深度学习的角度构建模型,将文本转化为词向量然后对语义等特征进行学习从而计算相似度。
为将上述3种相似度计算算法进行有效融合并应用于短文本的相似度计算,本文提出多重检验加权融合的相似度计算(MCWFS)方法,通过实验对以上3种相似度计算方法分别确定一个相似度阈值,当2个文本间的3个相似度值中至少有2个大于对应阈值时,认为两者可能相似,则进行加权融合以及相似度计算,否则认为两者不相似。上述操作可以避免文献[24]中因一种相似度小于阈值而被认为不相似从而无法参与下一阶段运算的情况,最终使得相似度计算结果更加准确。本文通过线性加权融合方法计算相似度值的公式如下:
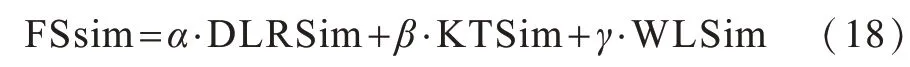
其中,权重因子满足α+β+γ=1,通过实验调节权重因子从而确定它们的最佳取值组合。
相似度计算过程伪代码如算法2所示,MCWFS方法的计算流程如图2所示。
算法2相似度计算算法

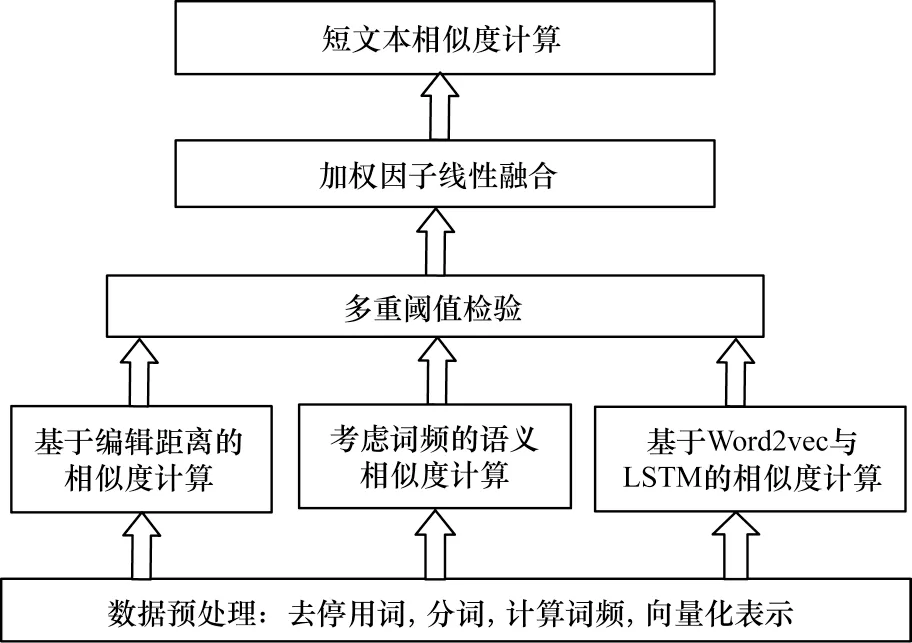
图2 MCWFS方法计算流程Fig.2 Calculation flow of MCWFS method
3 实验结果与分析
3.1 实验数据
为验证本文方法的有效性,采用蚂蚁金融NLP挑战数据集(https://pan.baidu.com/s/1yEeThJi_HHxwQjbrG3O ArQ),该数据集信息如表1所示,每行由序号、2句短文本和1个相似性标志位组成,共包含102 477组句子对。首先对数据集进行预处理,去除格式不正确的句子对,采用百度停用词表对文本去除停用词,并使用HanLP工具包进行分词并统计词频。在预处理后剩余的102 373组句子对中,正样本为18 668组,负样本为83 705组。本文选取80%的数据作为训练集,20%的数据作为测试集,以进行模型训练。

表1 实验数据集信息Table 1 Experimental dataset information
3.2 实验环境与度量标准
本文实验环境为Windows7操作系统,使用MyEclipse作为开发工具,数据库采用MySql5.6版本,使用Java和Python2.7开发语言实现本文相似度计算方法,开发环境采用JDK1.8。
在结果分析中,本文主要采用F1值作为3种检验阈值的选择标准,同时采用文本信息处理领域常用的召回率(Recall)和准确率(Accuracy)作为相似度计算质量评价指标,将本文方法分别与传统方法、无检验的相似度计算方法、未融合的相似度计算方法进行比较,最后通过Python将实验对比结果进行可视化展示。在评价指标中,准确率是指所有被正确预测为正和负的样本数占总样本数的概率,精确率(Precision)是指正确预测为正的样本占全部预测为正的样本的比例,召回率是指在实际为正的样本中被预测为正样本的概率,F1值是精确率和召回率的加权调和平均。4种指标的计算公式分别如式(19)~式(22)所示:

其中,TP表示实例是正类实际也被预测为正类的样本数量,TN表示实例是负类实际也被预测为负类的样本数量,FN表示实例是正类实际被预测为负类的样本数量,FP表示实例是负类实际被预测为正类的样本数量。
3.3 结果分析
3.3.1 检验阈值选择
实验通过调节相似度阈值,对比DLRSim算法、KTSim算法和WLSim算法的F1值,从而确定3种相似度的检验阈值标准,结果如图3所示。从图3可以看出,在F1值取值最大时,对于DLRSim算法、KTSim算法和WLSim算法,相似度阈值分别取0.40、0.42和0.47。因此,本文将3种检验阈值分别设置为t1=0.40、t2=0.42、t3=0.47。
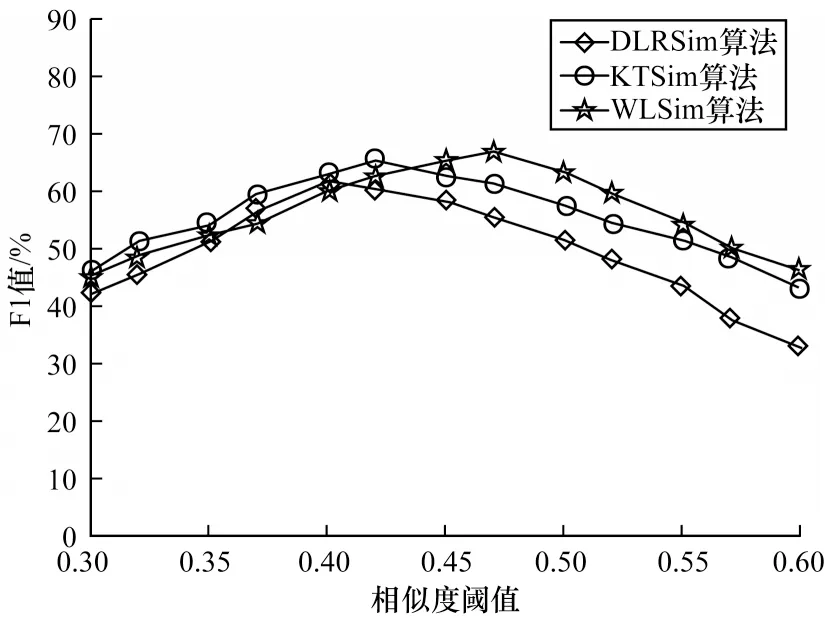
图3 不同算法的F1值对比结果Fig.3 Comparison results of F1 values of different algorithms
3.3.2 加权因子调节
为对满足多重检验标准的文本进行加权融合相似度计算,本文运用控制变量法对加权融合的加权因子进行调节,选择相似度阈值取不同值时的召回率作为评价指标,调整α、β和γ的取值组合,通过观察召回率来确定参数的最佳取值组合。由于实验数据较多,表2选取相似度阈值为0.42、0.44、0.46、0.48和0.50时的数据进行展示。从表2可以看出:减小DLRSim算法所占权重,召回率会明显增大,这是因为DLRSim算法主要从文本的编辑距离角度计算相似度,影响因素主要为共有词,因此其占比相对较小;增大KTSim算法的加权因子,召回率有所提升,因此,基于语义考虑词语义项的KTSim算法对召回率影响较大;基于深度学习模型的WLSim算法具有学习能力,可有效保持对历史信息的较长记忆,获取整个文本的语义特征信息,在序列化数据处理时有一定优势,因此,其影响力更大一些。通过对比最终确定加权因子取值为:α=0.21,β=0.36,γ=0.43。
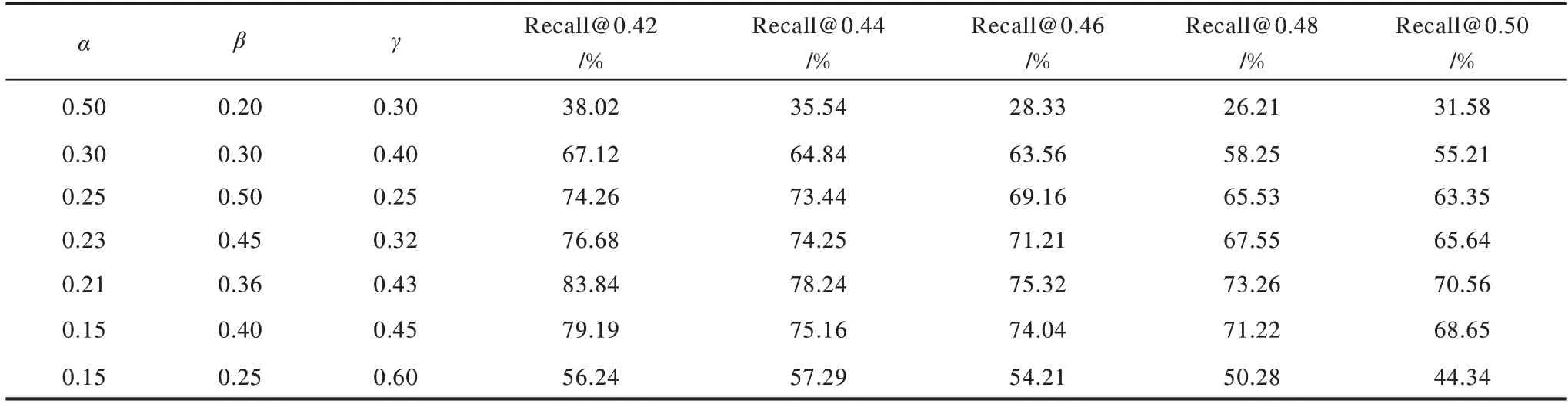
表2 不同加权因子取值组合下的召回率对比结果Table 2 Comparison results of recall under different combination of weighted factors
3.3.3 不同方法的实验结果对比
本节将从以下4个方面对不同方法的实验结果进行对比:
1)词频对短文本相似度的影响
为验证词频对短文本相似度的影响,将KTSim算法与文献[21]中的HowNet算法进行实验对比,选取词频不同的2组短文本,分别用2种算法计算相似度,数据结果如表3所示。从表3可以看出,对于词频不为1的文本,2种算法相似度计算结果差异较大,而对于词频都为1的文本,2种算法计算结果的差异较小,但KTSim算法的计算结果优于HowNet算法。
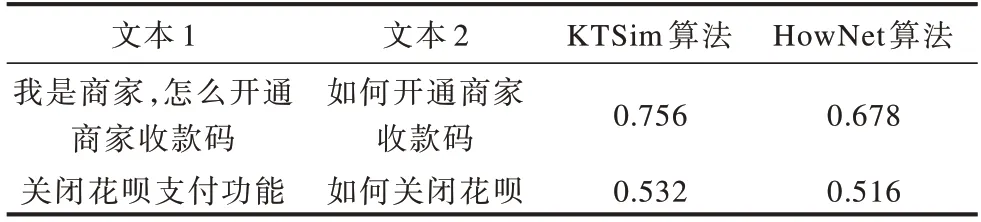
表3 词频对相似度计算结果的影响Table 3 Influence of word frequency on similarity calculation results
2)检验方法对比
为验证本文多重检验方法的准确性,以不同阈值下的准确率作为评价标准,将本文多重检验融合(MCWFS)方法与无检验融合(NCWFS)方法和层层检验融合(ECWFS)方法进行实验对比。NCWFS即无阈值检验而直接加权计算,ECWFS中只要有一种相似度值不满足阈值则认为不相似,不进行加权运算。从图4可以看出,MCWFS方法的效果优于NCWFS方法,这是因为无检验融合方法无法对只有一种相似度值过大的情况进行筛选,从而将异常值引入运算,将实际不相似的文本判定为相似,降低了准确率。ECWFS方法的效果相对较差,原因是层层检验会因为一种相似度值不满足阈值而无法参与加权运算,使得计算中将较多相似文本判定为不相似,降低了准确率。随着阈值的增大,方法的准确率增势趋于平缓后开始下降,这是因为不相似的短文本数逐渐趋于实际值,然后又大于实际值,而判断正确的相似文本数在减少。相比ECWFS方法和NCWFS方法,MCWFS方法在准确率上平均分别提高16.01%和7.39%,即多重检验融合方法具有明显优势。
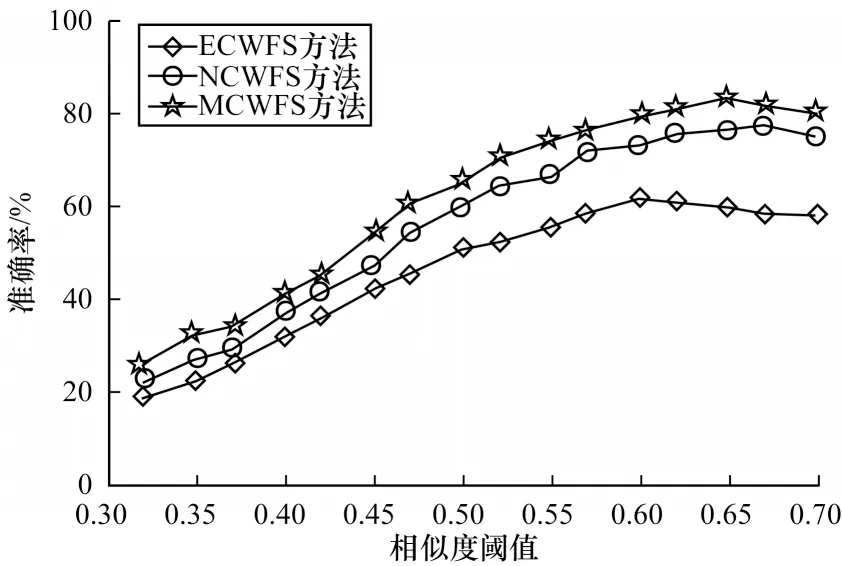
图4 3种检验方法的准确率对比结果Fig.4 Accuracy comparison results of three test methods
3)融合方法对比
为验证加权融合方法的有效性,将其与未融合的DLRSim、KTSim和WLSim算法进行对比,以不用阈值时的召回率作为衡量标准,结果如图5所示。从图5可以看出,在相同阈值情况下,MCWFS方法的召回率最大,其具有明显优势,原因是该方法对3种对比算法所考虑的不同角度的文本特征进行了加权计算并筛选异常值,从而提高了召回率。
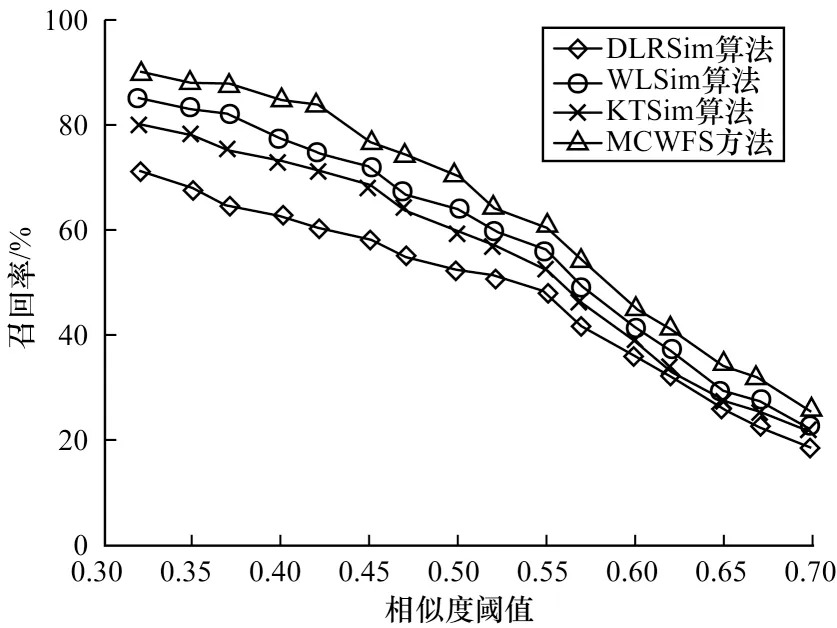
图5 融合和未融合方法的召回率对比结果Fig.5 Comparison results of recall between fusion method and non-fusion methods
4)与传统相似度计算方法的对比
将本文多重检验加权融合计算方法与传统的Jaccard相似度计算方法、基于Word2vec的余弦相似度计算方法[25]和利用WordNet[26]计算词语和句子相似度的方法进行实验对比,以不同阈值下的F1值作为评价标准,结果如图6所示。
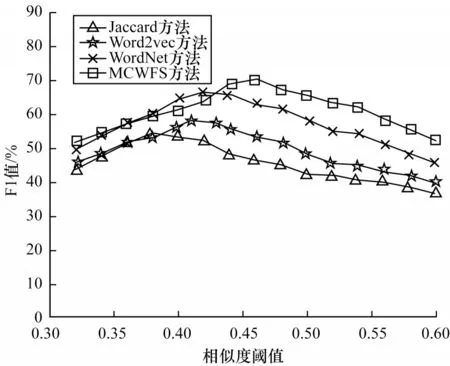
图6 不同方法的F1值对比结果Fig.6 Comparison results of F1 values of different methods
从图6可以看出,4种方法的F1值变化趋势大致相同,MCWFS方法在相似度阈值为0.46时F1取得最大值70.21%,而Word2vec方法和WordNet方法分别在阈值为0.41和0.42时F1取得最大值,分别为58.26%和66.25%,Jaccard方法在阈值为0.38时F1取得最大值53.26%。Jaccard方法的主要影响因素为2个文本之间的共有词,其无法利用更丰富的信息进行计算,因此,F1值最小。WordNet方法需要大规模的语料库,无法计算词库未收录的词语的相似度值,Word2vec方法虽然解决了文本的数据稀疏问题,但是其将词向量进行余弦运算,并不能代表语义关系,容易出现将相似词语较多但语义相悖的文本计算为相似文本的问题。而本文MCWFS方法具有明显优势,因为其既考虑了文本的表型特征,也考虑了语义等信息,同时对异常值进行筛选,使相似度计算更加准确。
利用4种方法计算短文本相似度的数据结果如表4所示,从表4可以看出,本文方法计算性能最优。

表4 不同方法的相似度计算结果对比Table 4 Comparison of similarity calculation results of different methods
4 结束语
针对传统文本相似度计算方法准确率较低的问题,本文结合短文本句子简短、特征稀疏和语义丰富等特点,提出一种多重检验加权融合的短文本相似度计算方法。该方法通过改进编辑距离从句子表型特征计算短文本相似度,考虑文本简短对相似度的影响而加入词频作为词语权重,从语义角度计算相似度,同时利用深度学习模型进行计算,解决语义相似度对大规模语料库的依赖问题。在此基础上,将满足多重检验标准的3种相似度值进行加权融合并用于短文本相似度计算,以降低异常值对相似度值的影响并提高计算结果的准确率。实验结果表明,该方法的计算性能优于WordNet、Word2vec等方法。
受中文短文本数据集较少的影响,本文的阈值和加权因子的取值选择对数据具有依赖性和针对性,下一步将利用不同领域的数据集,通过机器学习的方式对参数进行选取。此外,基于深度学习的LSTM模型在处理短文本时具有一定优势,但对于较长文本而言其存在局限性,因此,后续考虑加入Attention机制使该模型更加灵活高效。
