基于Transformer重建的时序数据异常检测与关系提取
2021-02-05孟恒宇李元祥
孟恒宇,李元祥
(上海交通大学航空航天学院,上海 200240)
0 概述
异常检测是时序数据分析最成熟的应用之一,定义为从正常的时间序列中识别不正常的事件或行为的过程[1]。有效的异常检测被广泛用于现实世界的多个领域,如量化交易、网络安全检测[2]、汽车自动驾驶[3]和大型工业设备的日常维护等。以在轨航天器为例,由于航天器昂贵且系统复杂,不能及时检测到危险可能导致严重甚至无法弥补的损害,异常随时可能发展为严重故障。因此,准确、及时地检测出异常能够帮助航天工程师在第一时间给出应对措施。
基于重建的异常检测是目前时序数据异常检测的主流方法。文献[4]将深度学习用于异常检测任务中,使用基于长短期记忆(Long-Short Term Memory,LSTM)网络的自动编码器(Auto-Encoder,AE)来检测时序数据异常,该方法被成功应用于许多工业领域[5-7]。基于重建的异常检测算法首先使用正常数据训练自动编码器来重建序列,然后通过相同的模型重建异常序列,获得重建误差序列,最后利用阈值或其他方法分割出异常发生的子序列。
然而,LSTM序列式传播的特点导致检测算法难以实现并行化,大幅增加了计算耗时,尤其是随着数据量指数级增长,过多的训练耗时会影响模型的及时更新[8-9]。此外,LSTM等深度学习的“黑箱”特点使得提取到的特征很难有对应的物理含义,如在记录人为操作的故障数据集中,需要找出人为指令与异常的对应关系,此关系难以体现在LSTM模型中[10]。
近年来,Transformer模型成为完成自然语言处理(Nature Language Processing,NLP)任务的主要方法。自然语言同样是一种序列数据,但其中语义存在跳跃性,这类似于时序数据中因人为因素而导致的状态变化,而Transformer模型可以很好地处理这一问题。因此,本文以注意力机制作为时序数据异常检测手段,提出一种基于Transformer模型的时序数据异常检测方法——掩膜时序建模(Mask Time Series Modeling,MTSM)。使用自注意力机制并行地重建数据以加快速度,通过可视化关系矩阵分析人为因素与异常发生的关系,并在存储数据集和NASA航天器数据集上进行实验,比较不同工况下的重建及异常检测效果。
1 相关工作
本节阐述以Transformer作为特征提取器的自动编码器工作原理及其优点,并介绍从重建误差序列中获取异常动态阈值分隔的过程。
1.1 嵌入注意力机制的自动编码器
注意力机制起源于人类眼球的注意力[11-12],该机制能够帮助眼球从繁冗复杂的图像细节中获取最重要的部分。广义的注意力机制是指从大量信息中将权重分配给重要信息的过程。针对时序数据,不同时间步的数据其重要性应当是不同的。
假定输入序列为Χ=[x1,x2,x3],输出序列为Y=[y1,y2,y3],目标为根据输入序列X得出输出序列Y。假定有一组序列对<X,Y>,则自动编码器的任务是学习该序列对的映射关系。自动编码器由编码器Encoder和解码器Decoder组成,不同的任务使用不同的特征提取器[13]。本文以NLP领域的Transformer模型作为自动编码器的Encoder和Decoder。
Encoder针对不同的输入xi映射出不同的隐含编码ci,将这种非线性映射定义为:

Decoder对ci-1做符合要求的解码,得到输出序列Y。每一个i时刻的yi根据ci-1和i时刻之前的y1,y2,…,yi-1来生成,其对应的非线性映射函数定义为:

由此,可以根据输入的X序列依次得到输出的Y序列。可以看出,不同于一般的自动编码器,不断更新的隐含编码ci利用了注意力机制,在计算不同时间步时使用了不同的ci权重向量,也就是分配了不同的注意力。在计算ci时,第t个输入xt对yi的权重计算公式为:

Transformer是完全基于自注意力机制的特征提取器,其两个关键结构如图1所示[14]。图1(a)所示为注意力计算部分,其中,Query和Key经过矩阵相乘缩放到0和1之间,再通过Softmax得到注意力得分,之后计算Value的注意力得分加权和,得到最终输出。图1(b)所示为Transformer编码器结构,其中,输入序列经过一层嵌入后成为一个多维序列,经过位置嵌入后的数据输入多层的转换层中,每一层转换层由多头注意力机制、层正则化和前向传播模块组成,同时加入了残差连接。

图1 注意力计算机制与Transformer编码器结构Fig.1 Attention computing mechanism and Transformer encoder structure
与传统序列传播的LSTM从前到后依次输入序列不同,严格来说,Transformer没有方向性,其直接输入整段序列。此特性可使模型同时学习当前时间步周围的时间步信息。
1.2 基于重建误差动态阈值分割的异常检测
由重建误差序列可分割出异常子序列[15],如图2所示。

图2 基于重建的异常检测示例Fig.2 Examples of reconstruction-based anomaly detection
文献[16]提出一种动态阈值分割方法,其设yi为原始序列第i时间步的信号值为模型重建出的序列第i时间步的信号值,从而计算得到重建误差序列动态阈值分割指根据ei求出动态阈值ε,其定义如下:

其中,μ(·)是均值,σ(·)是标准差,z是权重系数。每一个时间步的误差阈值εi是动态的,取决于之前整个阈值序列ε的最大值,计算公式如下:

在式(5)中,ea是上一个异常发生之后的所有正常序列,Pj是所有的正常序列,表达式如下:

可以看出,动态阈值检测综合了均值和标准差,其根据误差累积的情况不断更新阈值,检测到异常后再更新阈值。在整个过程中,只需要调整一个参数即权重系数z。目前,该方法已经应用到NASA实际的生产环境中。
2 本文方法
为提高基于LSTM模型异常检测的计算效率,同时探索深度模型的特征在物理世界的含义,本文提出以Transformer作为自动编码器特征提取器的掩膜时序建模(MTSM)方法。
2.1 模型的输入与输出
在传统基于循环神经网络(Recurrent Neural Network,RNN)的模型中,对于多数重建的时间步,通常是从整段时间序列中取一段长度来重建下一步(LSTM信息传播的步数是有限的),重建序列即是将分步的预测拼接成一段完整的序列,如图3(a)所示,其中,灰色为模型输入部分,白色为重建部分。可以看出,这一过程是单向的,仅有重建时间步之前的数据影响重建这一时间步。而Transformer模型与基于RNN的模型不同,其一次性读取整段时序数据,在NLP任务中,可以从一个单词的左右文字学习这个单词的作用。因此,本文设计一种新的数据输入输出方式,如图3(b)所示。在获取一段完整序列并分割成小序列时,不是重建这一段小序列的最后一节数据,而是预测这一段小序列的中间一节数据,从而利用重建数据左右两边的信息来实现重建。

图3 基于RNN的模型与本文模型的输入输出示意图Fig.3 Schematic diagrams of input and output of RNN-based model and the proposed model
假设被掩膜(Mask)掉的重建序列长度为L(i一般取1),重建序列之前的输入序列长度为Li-,重建序列之后的输入序列为Li+,则每次异常检测要延迟Li+个时间步才能进行。当Li+=0时,MSTM的输入输出数据退化到一般的输入输出过程,如图3(b)所示。这就带来一个问题,即在在线检测中,如果需要将目标时间步之后的数据作为模型的输入,势必会影响检测的实时性。但如果类似NLP,加入之后数据可以提升检测效果的话,则可以在工程上做取舍,即在需要检测精度高时增长目标时间步之后数据输入的长度,而在需要及时性时减少甚至取消这部分输入。这一点将在下文实验部分加以讨论。
2.2 模型结构
受Mask Language Modelling启发,本文提出MTSM方法用于时序数据的重建。
如图4所示,对于输入序列Χ=[x1,x2,…,xn],选择其中将要重建的时间步(如x4),用[mask]标志代替,从接下来的模型中屏蔽掉。经过一层位置嵌入后进入Transformer编码器,得到编码后的序列encoded sequence,即上文提到的memory(但与一般的memory不同,此时的memory不包含要重建的x4),再经过一个简单的decoder之后获取序列。损失函数定义为被屏蔽的x4预测值与真实值之间的关系。换言之,MTSM是从被Mask的时间步两边的数据或者说上下文数据重建时间步,这充分利用了Transformer无向性的特点。此外,综合利用上下文信息,也可以提高重建的精度。

图4 MTSM方法建模过程Fig.4 Modeling process of MTSM method
2.3 关系提取
Transformer的一大优点是可以捕捉跨距离的依赖关系。针对NLP任务,研究者常利用此特性分析某个词在整句话中的作用,从而捕捉到较为直观的语义特征。本文利用这一特性进行人为指令与异常的关系提取,以探索异常检测中的人为因素影响。
首先对人为指令和异常的关系进行解释。以NASA航天器数据集为例,通过一键热编码(one-hot encoding)的形式记录地面操作人员的相关指令。如图5所示,事实上航天器仅传回了一个传感器遥测值,但与此同时NASA将地面操作人员的24种或54种指令的实行情况随信号的时间步编码在一起,这样不仅可以将其作为故障检测的数据集,同时也可以用来分析人为指令在异常发生中的关系。假设信号在102时间步~104时间步发生异常,计算102时间步与100时间步、101时间步人工指令的相关系数,如果102时间步与101时间步的相关系数较大,则说明101时间步造成了102时间步的异常。

图5 NASA航天器数据集中异常与人为指令的关系Fig.5 Relationship between anomaly and manual command in NASA spacecraft dataset
关系提取的具体实现过程如下:将Query的信号数据全部掩膜,只将人为指令传入模型,而输入保留全部数据,训练完毕后逐层可视化相关系数矩阵,找出异常发生时哪些时间步的人为指令权重较大,从而获得所提取到特征对应的物理含义。
3 实验结果与分析
本文在存储数据集和NASA航天器数据集上进行实验,比较不同工况下的重建及异常检测效果,并通过可视化关系矩阵进行所提取特征的物理含义分析。
3.1 不同工况下的时序数据重建
时序数据异常检测数据集的标注需要昂贵的专家成本,尤其是详细标注异常发生的开始和结束时刻的数据集。由于此类数据集规模通常较小,因此基于算法效果检验的实验结论存在一定偶然性。同时,基于重建误差的异常检测要求模型在输入正常数据时重建误差较小,输入异常数据时重建误差较大。因此,本文先使用含有不同工况的存储数据集[17-18]进行重建效果对比。
本文使用的存储系统数据集来自于Ostwestfalen-Lippe应用科学大学的智慧工厂项目。这个高存储系统由4条传送带和2条导轨组成,每条传送带包含3个感应传感器,共有18个通道。数据集提供了4种工况,即无故障(正常)未优化、无故障(正常)已优化、有故障(异常)未优化和有故障(异常)已优化。基于此数据集,可以在工况是否异常和是否被优化两个维度上比较算法的优缺点。
图6为存储数据集通道3数据的重建结果对比。通过比较4种不同工况下的重建序列可以看出,优化后的数据比未优化的数据更平稳,杂波更少,异常数据比正常数据多了一段急剧上下波动的异常。

图6 存储系统数据集上的重建结果Fig.6 Reconstruction results comparison of storage system dataset
表1为4个子集上的重建结果绝对误差对比。可以看出,Transformer方法在有异常的数据集上重建的绝对误差更大,这说明异常发生时Transformer的表现更鲁棒。

表1 存储系统数据集上重建误差对比Table 1 Reconstruction error comparison in storage system dataset
表2是训练到收敛的平均用时对比,相关硬件为NVIDIA GTX-1080TI、16 GB内存、Intel E5处理器。可以看出,由于Transformer放弃了LSTM的序列式推进,其注意力机制模块完全可以并行,因此用时普遍较少,最多可以节约80.7%的时间。
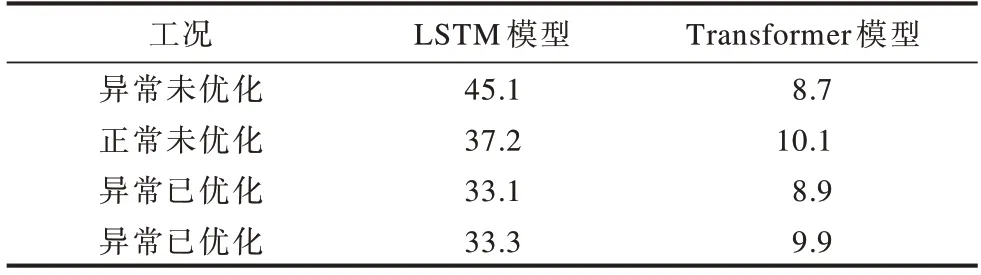
表2 存储数据集上训练耗时对比Table 2 Training time comparison in storage system datasetmin
3.2 时序数据异常检测
3.2.1 NASA航天器数据集
NASA开源的专家标注的真实世界航天器故障数据集[16]包括火星科学实验室好奇号(Mars Science Laboratory rover,MSL)和土壤水分主动被动探测卫星(Soil Moisture Active Passive,SMAP),共计82个通道、105个故障,数据集描述如表3所示。

表3 NASA航天器数据集描述Table 3 Description of NASA spacecraft dataset
3.2.2 Point-based指标
对于序列数据的异常检测,一种常用的检测指标为Point-based指标,即当预测异常与真实值有交集时记为True Positive,预测异常与任何真实值均无交集时记为False Positive,真实值与任何预测值均无交集时记为False Negative,其中,精确率(Precision)、召回率(Recall)与F1值的计算均与一般的检测任务相同。
如上文所述,本文模型的检测实时性主要取决于重建序列使用的输入序列长度,尤其是位于重建序列之后的输入序列长度Li+。此外,Transformer的层数和有无多头机制也会对检测效果造成影响。本节比较了不同参数配置对时间消耗的影响(硬件配置同上),如图7和表4所示。可以看出,本文模型的Point-based指标达到与LSTM相近的效果,并且可以大幅减少时间消耗,与LSTM模型相比节约了84.4%的时间。同时可以看出,多头机制在这个时序数据任务中几乎没有发挥作用,这可能是因为数据维度过少(只有25维或55维),而一般NLP任务的词会嵌入512维度的词向量空间。

图7 时间消耗与F1得分对比Fig.7 Comparison of time consumption vs F1 score

表4 图7实验的详细参数Table 4 Detailed parameters of the experiment in Fig.7
针对异常在线检测问题,由实验数据可以看出,设置Li+即延迟在线检测时,异常检测的精度更高。而放弃利用两边信息即Li+=0时,虽然检测的精度有所下降,但是避免了在线检测的延迟,这也符合之前假设,即利用两边的信息可以加强建模,从而提升整体效果,并且输入数据长度越长精度越高。因此,针对在线检测问题,需要具体考虑不同场景的需要。
3.2.3 Range-based指标
文献[19]指出,Point-based指标对时序数据并不准确。图8所示的3个例子均被记作True Positive。从左到右可以看出:第1个例子有一个真实故障,算法检测出1个故障;第2个例子有2个真实故障,检测算法却混淆为1个;第3个例子有1个真实故障,算法却识别为2个。

图8 Range-based时序检测指标示意图Fig.8 Schematic diagram of Range-based indicator of time series detection
虽然Point-based的精确率和召回率均为100%,但是物理意义不同。因此,文献[19]提出Range-based指标,相较于Point-based指标,其增加了OverlapReward值。第i个真实异常Ri与预测值集合P的OverlapReward计算如下:

其中:ω(·)是重叠尺寸函数,用于衡量真实异常子序列与预测异常子序列的重叠大小;γ(·) 是重叠基数函数,用于衡量一个真实异常子序列与几个预测异常子序列对应,一般与真实异常重合的预测值越多,得分越低;δ(·)是位置偏置函数,如取前缘优先(Front-end Bias)时,预测异常的前缘与真实异常的前缘越接近则得分越高,取中心优先(Middle-end Bias)时,预测异常的中心与真实异常的中心越接近则得分越高。
表5比较了Range-based的不同位置偏置函数设置。如果设置为前缘优先,则Transformers模型优势更明显,即检测出异常的前缘相比真实值更接近。设置为中心优先,则Transformer模型也有一定优势。但如果完全不考虑异常的位置,则Transformer模型不占优势,这体现了Transformer模型在高层次语义上的优势。

表5 Range-based F1得分对比Table 5 Comparison of Range-based F1 scores
3.3 异常人为因素分析
本文选用一个6层Transformer模型的关系矩阵进行可视化,部分实验结果如图9所示。已知这个序列在1 899时间步~2 099时间步、3 289时间步~3 529时间步和4 286时间步~4 594时间步处发生异常,可见注意力矩阵的可视化效果非常直观。对于Anomaly0,1 870时间步处所有的点的相关性都极强。因此,极大可能1 870时间步处发出的人为指令造成了之后的故障。对于Anomaly2,可以发现4 390时间步处点的相关性更大,这比真实异常开始处有延迟,但对应了从4 430时间步开始的预测异常,可以看出模型将4 430时间步之后认为异常并认为4 390时间步处的指令依然关系极大。自上而下,中间层如Layer3提取到的特征就并不直观,可能是相关的高层语义特征,而到模型的最后一层Layer5,特征又变得直观。以上逐层关系矩阵的变化反映了编码到解码的过程[20]。
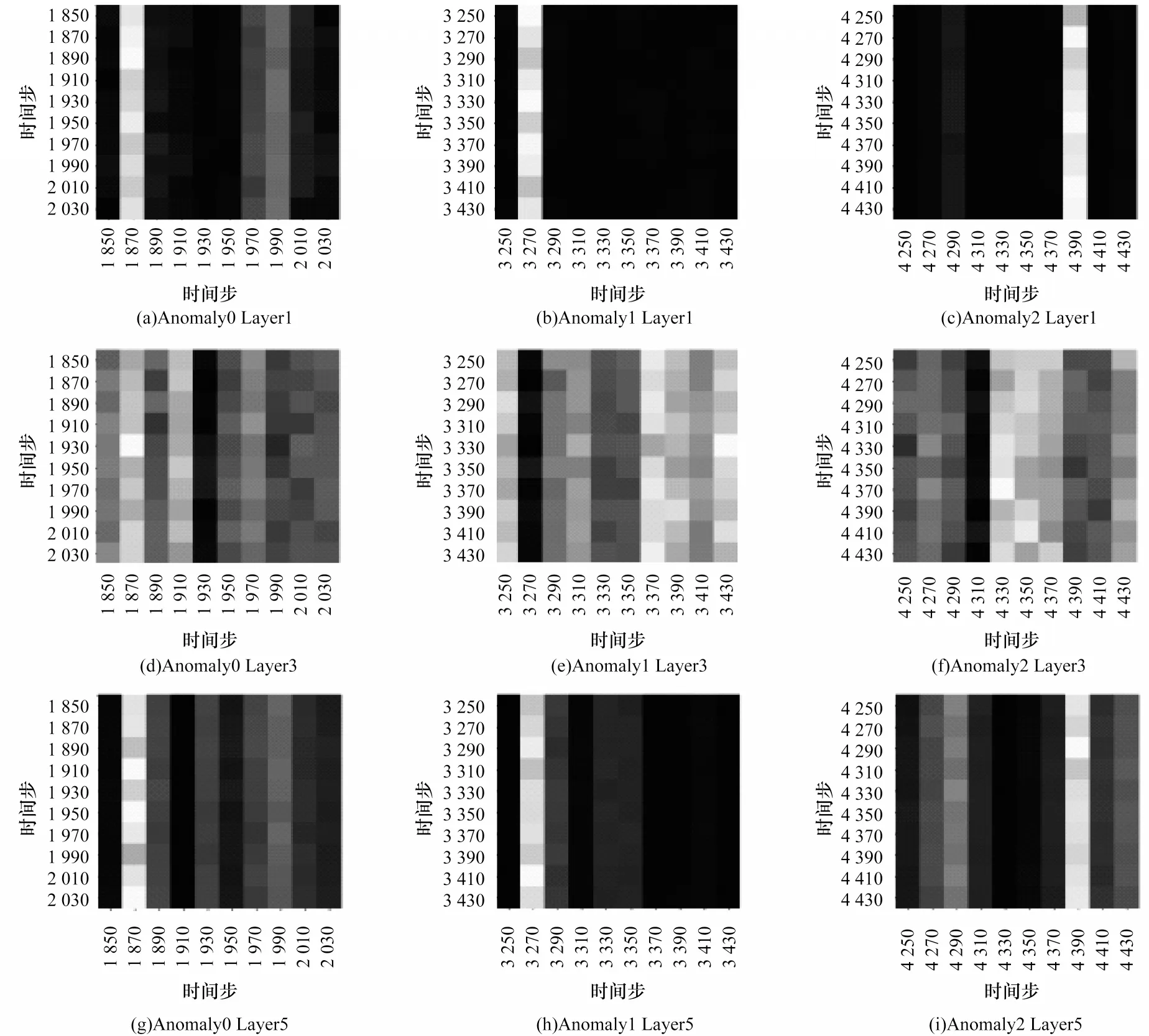
图9 关系矩阵部分可视化结果Fig.9 Partial visualization results of relation matrix
4 结束语
目前,基于LSTM的异常检测已经被部署到很多实际应用场景中。本文针对现有异常检测方法计算效率低和提取到的特征意义不明显这两个问题,提出基于Transformer重建的MTSM方法。实验结果表明,与LSTM模型相比,Transformer模型减少了80.7%的训练耗时,并且对应了关系矩阵的物理含义,而Mask的使用则提高了重建和检测的精度,在重建任务中建模更鲁棒,Range-based检测指标的F1得分达到了0.582。下一步将继续提高重建精度并建立规模更大的数据集,以避免实验结论的偶然性。
