基于先验MASK注意力机制的视频问答方案
2021-02-05许振雷董洪伟
许振雷,董洪伟
(江南大学物联网工程学院,江苏无锡 214000)
0 概述
随着通信技术水平的提高,视频成为目前最大的信息载体之一。“一图胜千言”生动形象地说明了图像在充当信息介质时的重要性,而视频携带的信息量更多,因此,如何使计算机理解视频中的内容成为学者们的研究热点。图像问答(Visual Question Answering,Visual QA)[1]任务为视频理解的父任务,其简单描述为给定一张图像和一个与图像内容相关的问题,计算机在理解图像内容和问题的基础上给出问题的答案。图像问答的子任务包括图像模式识别和自然语言处理。相对于图像问答,视频问答(Video Question Answering,Video QA)更具挑战性。
目前,视频问答研究发展较缓慢,其中一个重要原因就是数据集的整理(包括收集和标注)成本较高,且与视频相关的处理技术也不够成熟。视频采集过程中不能很好地截取核心内容片段的后果是,一方面若视频时间过长,将导致无关信息增多,难以吸引足够多的人来回答并标注问题,另一方面若时间过短将导致信息不足,造成回答者理解错误。
本文在现有注意力机制框架的基础上,提出先验MASK注意力机制模型。提取视频的关键帧并采用向上注意力机制Faster R-CNN模型获得关键帧的特征以及关键帧中的对象标签,将特征以及对象标签与问题文本分别进行3种注意力加权,采用先验MASK屏蔽无关答案,从而提高视频问答的准确率。
1 相关工作
目前,学术界和工业界对视频问答的研究较少,但有关其父任务,即图像问答[1]的研究非常多,且获得了较大进展。从模型的角度来看,图像问答任务主要聚焦于将图像特征与文本特征进行融合,从而实现端到端的训练。在图像处理领域,随着网络结构的不断提出,使用卷积神经网络(CNN)进行图像特征表达成为主流,此外,自然语言处理也得到迅速发展,从早期的词袋模型[2]、Word2vec[3]到近期的自然语言处理预训练模型Bert[4]、XLNet[5]等,计算机能够抽取语法以及语义特征,从而抽象地提取文本特征。在图像处理和自然语言处理相结合的任务,即图像问答任务中,如何将文本特征与图像特征进行有效融合,成为近年来的研究热点。2015年,ZHOU等人[6]提出图像问答的基线,引入iBOWIMG模型,如图1所示,用VGGNet[7]网络对图像进行特征提取,对问题以及答案实现词袋编码[2],继而将图像特征与问题特征相拼接,经过分类层输出每个答案的概率,并与真实答案进行误差计算从而实现梯度回传,达到训练的目的。
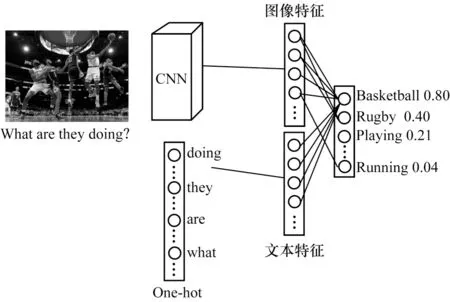
图1 iBOWIMG模型结构Fig.1 iBOWIMG model structure
文献[1]使用神经网络进行图像特征提取,利用循环神经网络LSTM[8]实现问题文本特征提取,将2个特征相拼接从而达到训练的目的,此外,使用语言模型从COCO[9]的图像标注中自动生成问题,同时规定答案必须是一个单词,包含物体、数量、颜色和位置4个主题,但是其仅支持一个问题且答案只能是一个单词,不具有现实意义。文献[10]提出注意力机制,并将注意力机制应用于图像问答领域。文献[11]将问题进行特征表达后形成卷积核并与图像进行卷积操作,以得到图像空间上的区域关注图,从而更准确地提取特征。文献[12]提出自上而下和自下而上相结合的注意力模型方法,并将其应用于视觉场景理解和视觉问答系统等相关问题,其中,基于自下而上的关注模型(一般使用Faster R-CNN[13])用于提取图像中的兴趣区域,获取对象特征,而基于自上而下的注意力模型用于学习特征所对应的权重,实现对视觉图像的深入理解。该方法在2017年VQA Challenge(https://visualqa.org/)比赛中取得了第一名,验证了其有效性。
上述均为图像问答的相关研究,可以看出,图像问答系统已经进展显著。文献[14]提出将C3D模型[15]与ResNet模型[16]提取的特征相结合,并再次与Glove[17]提取的Word2vec特征进行结合的方法,以进行注意力机制端到端的训练,自此视频问答逐渐成为研究人员关注的热点。如图2所示,由于视频含有时间序列,因此其问答任务相对图像而言难度更大。

图2 图像问答与视频问答Fig.2 Visual QA and Video QA
目前,国内外学者对视频问答的研究方法主要分为联合嵌入、视频描述以及注意力机制3种,具体如下:
1)联合嵌入是视频问答任务中最常见的一种方法,其使用卷积神经网络提取视频特征,同时利用递归神经网络提取问题文本的特征表达,然后将视频特征与问题特征相拼接并直接输入模型,从而生成每个答案的概率。对于视频特征而言,目前多数采用ImageNet[18]中的预训练模型(如VGGNet[19]、ResNet[16]以及GoogleNet[20])来提取图像特征;对于问题文本而言,多数采用LSTM和GRU[21]来提取文本特征。文献[22]提出Re-watching和Re-watcher 2种机制,以模仿人类阅读问题时不断观察视频的行为,然后将2种机制组成为forgettable-watcher模型。
2)视频描述方法,其将一段视频转换成自然语言描述的句子。该方法将视频转换成文本,从而利用自然语言处理的方法得到问题的答案。文献[23]提出一种分层记忆网络(Layered Memory Network,LMN)模型,从电影或电视剧字幕中提取单词和句子,利用LMN生成视频表达,然后通过语义匹配将问题与视频转换成文本从而生成答案。文献[24]使用预训练的Faster R-CNN[13]模型首先获取每一帧图像中的目标和位置属性信息,学习视频中的字幕信息得到相关的视觉标签,然后将获取的区域特征(目标和位置属性)、视频特征和问题文本特征输入到模型中,从而得到问题的答案。
3)注意力机制模型[25],其首先在机器翻译[26]任务中被提出,在循环神经网络中识别句子中不同部分的权重,从而使神经网络注意不同的单词。注意力机制在机器翻译任务中取得了较好效果,其也逐渐成为视频问答领域的研究热点。文献[27]提出一种联合序列融合(Joint Sequence Fusion,JSFusion)模型。联合语义张量(Joint Semantic Tensor,JST)在多模块序列之间采用密集的Hadamard积来生成3D张量,然后采用学习的自注意力机制突出3D的匹配向量。卷积分层解码器(Convolutional Hierarchical Decoder,CHD)通过卷积与卷积门模块发现JST模块生成的3D张量的局部对准分数,该模型作为一种通用的方法,能够应用于各种多模态的序列数据对,并用于视频检索、视频问答、多项选择以及空白填空等任务。文献[28]使用融合视频特征与问题特征的双重注意力机制来解决视频问答问题。文献[29]利用Appearance和Motion 2种注意力机制来加强问题与视频之间的关系,再使用RNN的变体AMU(Attention Memory Unit)来进一步处理问题,从而提高模型的预测性能。
2 ZJB-VQA数据集
目前,国内外学者对视频问答研究较少的主要原因是高质量数据集的获取与标注难度较高。2018年,阿里巴巴之江实验室举办的视频问答大赛开放了高质量的ZJB-VQA数据集,该数据集一共包含8 920个视频,每个视频包括5个问题,一共有44 600个问题,每个问题有3个不同的相似答案。该数据集涵盖日常生活的各方面,是目前质量较高的视频问答数据集,其中,每个问题以及答案都由人工进行标注,如图3所示。ZJB-VQA数据集的问题类型主要集中于color、doing、how many、yes/not和where。
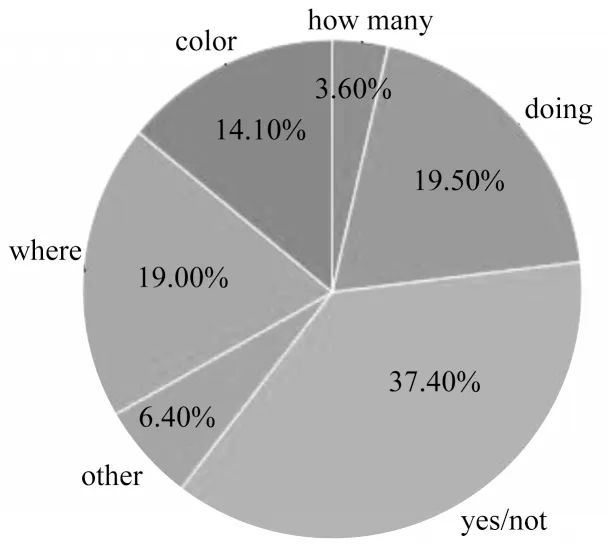
图3 ZJB-VQA数据集问题类型分布Fig.3 Problem type distribution of ZJB-VQA dataset
从表1可以看出,ZJB-VQA数据集中各类型问题以及答案的平均长度分布比较均匀,问题约为8个单词,答案约为1个单词。图4所示为数据集的答案分布情况,“standing”在答案中占比最高,达到28.3%,其次是“indoor”,关于颜色的词汇的出现概率也非常高,总和达到23%。
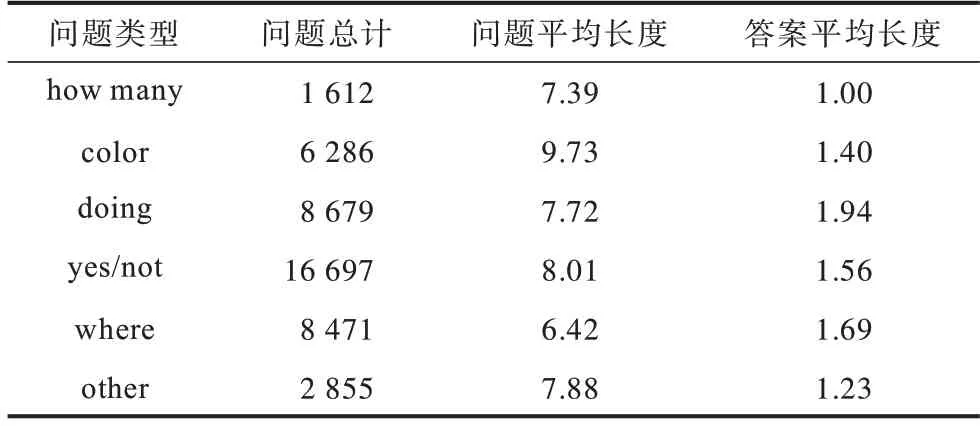
表1 ZJB-VQA数据集中问题及答案的长度统计结果Table 1 Statistical results of question and answer length of ZJB-VQA dataset
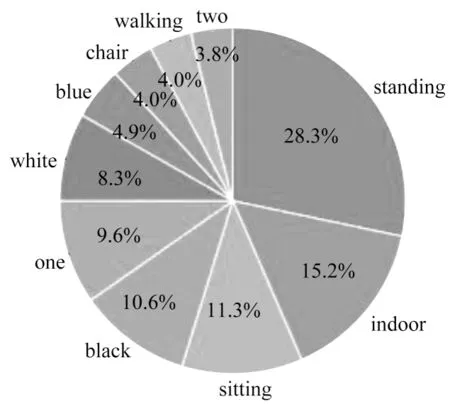
图4 ZJB-VQA数据集的答案类型分布Fig.4 Answer type distribution of ZJB-VQA dataset
ZJB-VQA数据集测试集的评价指标为准确率,每个问题有3个相似的答案,只要有一个答案和模型预测值完全匹配,就认为预测答案正确。准确率的计算公式如下:
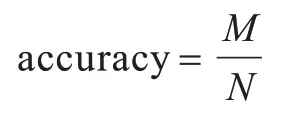
其中,M为回答正确的问题总数,N为测试集的总数。
3 本文视频问答方案
目前,多数视频问答方案没有考虑文本特征与视频特征之间的相关性,而这种相关性特征在回答任务中至关重要,如何使模型能够同时捕捉问题以及视频的兴趣点尤为关键,因此,本文针对一般性视频问答任务提出基于先验MASK注意力机制的VQA模型,模型结构如图5所示。模型输入为N个问题q、一个视频ν、问题先验信息prior以及视频标签attr,问题文本经过Word2vec之后与视频特征ν、视频标签attr进行注意力机制加权,最后在网络输出期间与问题先验信息prior作乘积,结果称为先验MASK,网络的最终输出为N个问题的预测答案。
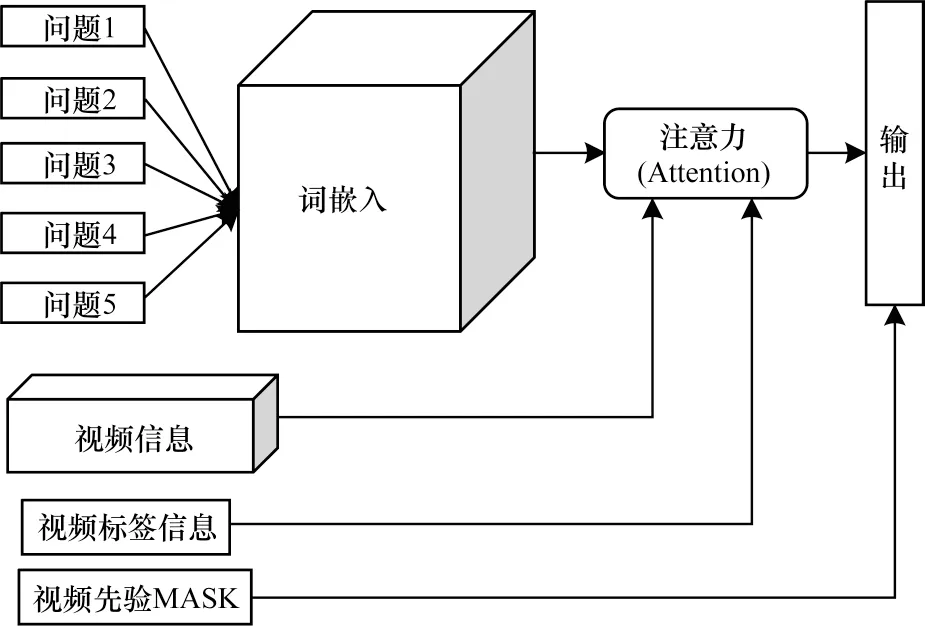
图5 先验MASK模型结构Fig.5 Prior MASK model structure
从图5可以看出,模型输入为N个文本问题,由于公开的数据集是1个视频对应多个问题(如ZJB-VQA数据集中1个视频对应5个相关问题),通过这种多输入学习方式能够让网络学习到更好的泛化特征。
在问题处理中,将文本统一为相同的长度,根据表1的结果,文本的平均长度约为8个单词,最长为18个单词,文本取14个单词作为问题输入长度时模型表现较佳。在视频处理中,视频中无用帧数量较多,如何处理冗余帧成为完成该任务的重点。如果使用全部帧进行训练会使训练时间大幅增加,且对机器的要求较高,因此,本文采用ffmpeg工具进行视频关键帧提取,ffmpeg是开源的音频、视频处理工具。本文设置关键帧个数为Lν,提取出的帧不足Lν时进行补充,多余Lν帧压缩为一帧,最终将每一个视频处理成L帧的图片集合,同时使用Faster R-CNN作为特征提取工具。如图6所示,Faster R-CNN是一个目标检测模型,该模型不仅能够检测目标,还可以使用边框标记出目标所属的类别以及在图片中的坐标位置。

图6 Faster R-CNN模型检测示例Fig.6 Faster R-CNN model checking example
本文采用Faster R-CNN模型,该模型将网络的最后一层输出作为特征,并使用一个IoU阈值进行筛选,对于每一个区域i,Vi表示该区域的特征,在视频问答任务中,特征的维度为M(预训练模型中M为2 048),给出该区域置信度较高的前P个对象,因此,对于视频中的一个帧而言,Faster R-CNN输出的维度为(P,M),对每个视频进行特征提取得到(Lν,P,M)维的特征以及每一帧中置信度最大的P个对象标签。对于Lν帧而言,共有Lν×P个标签,选择出现频率最高的w个标签作为最终输入模型的标签,方案使用的Faster R-CNN中的预训练ResNet-101 CNN模型是基于ImageNet训练的,使用基于Faster R-CNN的自上而下和自下而上相结合的注意力模型方法进行特征提取,设置置信度的阈值为0.2,可使Faster R-CNN得到多数可信度较高的标签。此时,方案获得了(L,P,M)维大小的特征以及w个视频标签。
对于网络结构中的注意力模块以及网络输出模块,本文提出3种注意力模型以及先验MASK,3种注意力模型分别为temporal-attention、attr-block-attention以及time-spatial-attention,三者从不同的角度来捕获视频与问题文本之间的关系。
3.1 temporal-attention模型
如图7所示,temporal-attention模型将问题特征与视频特征进行注意力加权,使模型根据问题来捕获视频中的关键点,将N个问题进行全局平均采样后的结果与视频特征进行哈达马点积,作为下一个网络的输入。对于问题特征的处理,本文使用双层双向LSTM进行网络表示。其中,问题q经过Glove[17]预训练向量Word2vec后得到q∈,Lq为句子的长度,300为预训练的Word2vec维度。经过LSTM层学习后所有的隐藏层维度均为O,进行全局平均池化后得到q′∈ℝl×O,视频特征ν∈,其中,L′为下采样使用的帧数,如ZJB-VQA数据集实验中实际使用了16帧。问题隐藏层特征Hq∈ℝO×O,将视频特征同样进行全局平均池化后得到Hν∈ℝM×O,fatt∈ℝq×O,其中,注意力权重o∈计算公式如下:
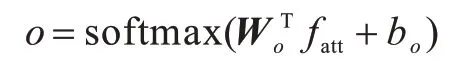
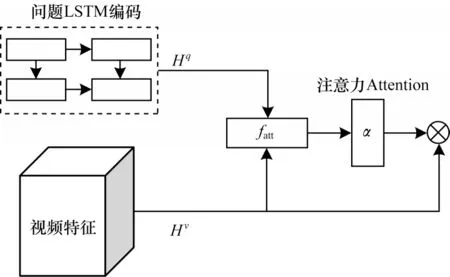
图7 temporal-attention模型结构Fig.7 temporal-attention model structure
3.2 attr-block-attention模型
temporal-attention模型关注视频特征与问题之间的关系,而attr-block-attention模型关注的是问题以及视频中通过Faster R-CNN提取出的标签之间的注意力。考虑例子“桌子上有什么?”,Faster R-CNN提取出“桌子”标签,容易将该标签与问题进行注意力加权。attr-block-attention模型结构如图8所示,使用attr-block-attention能够让模型在视频标签与N个问题中找到兴趣点,从而使模型学习更重要的信息。
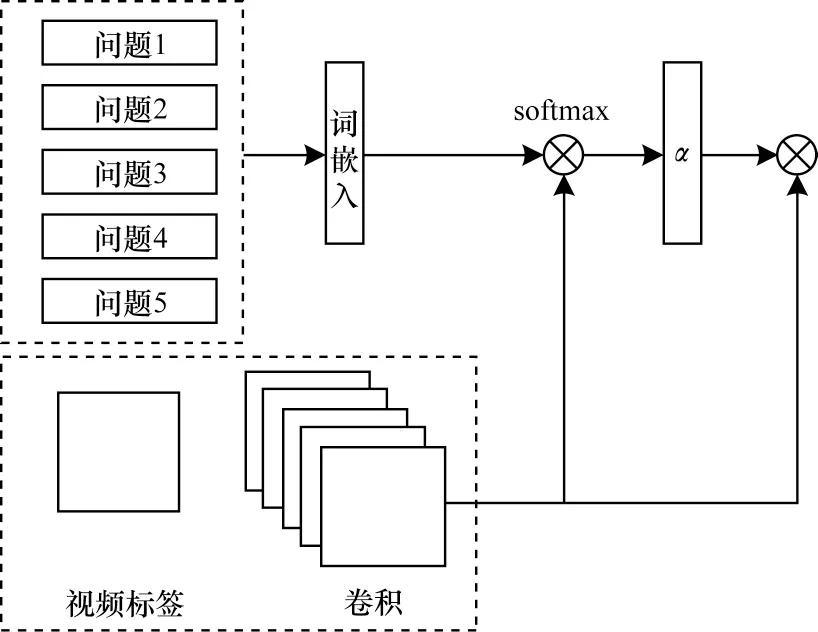
图8 attr-block-attention模型结构Fig.8 attr-block-attention model structure
3.3 time-spatial-attention模型
time-spatial-attention模型将问题特征与视频特征进行一系列的特征提取后,将其分别与问题以及视频作注意力加权,此时模型更能关注问题以及视频中的关键点,并作为下一个网络的输入。timespatial-attention模型结构如图9所示。
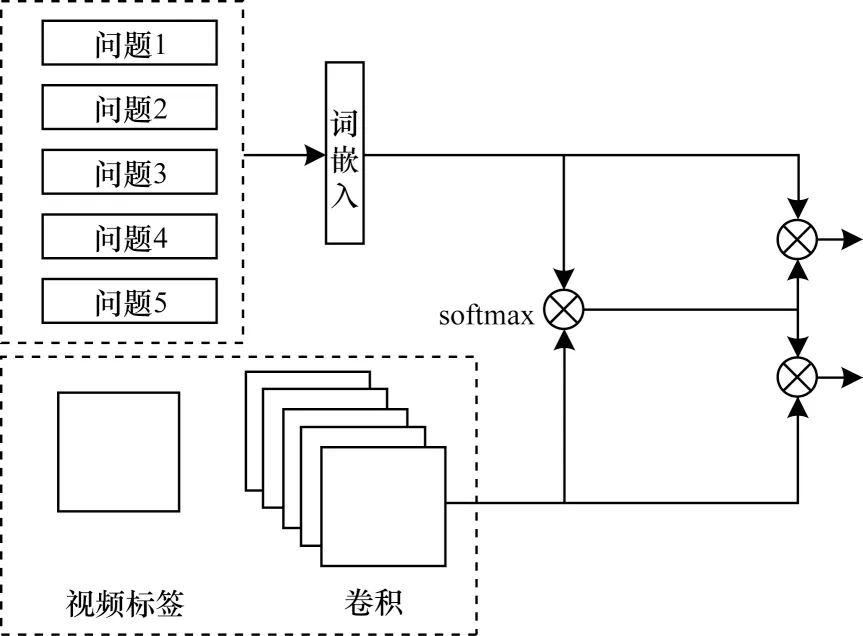
图9 time-spatial-attention模型结构Fig.9 time-spatial-attention model structure
本文将上述3种注意力机制的输入进行融合,直接取平均并与先验信息作加权,以得到最终的模型输出。
3.4 先验MASK
网络的输出答案有多种,但是针对某一种问题而言,其答案空间却有限,如图3所示,ZJB-VQA数据集的问题类型主要集中于how many、color、doing、yes/not以及where,比如对于yes/not问题类型而言,答案只有yes或not,不可能出现其他答案。因此,本文使用先验MASK将该答案控制在固定的输出空间之内,从而提升网络的预测性能。
4 实验结果与分析
使用2018年“之江杯”人工智能大赛视频组开放的数据集进行实验,将本文模型与下列模型进行性能对比:
1)VQA+模型,其为图像问答方法[1,30]的扩展,采用ResNet[16]网络进行特征提取,使用LSTM完成问题特征提取,然后输入到分类网络中得到问题答案。VQA+模型是“之江杯”第2名和第3名所采用的基本方案。
2)SA+模型[31],其通过LSTM提取问题文本中的单词特征,然后与视频帧的特征相结合并输入到分类网络中,得到问题的答案。
3)R-ANL模型[28],其为一种属性增强的注意力网络学习表示方法,采用多步推理与属性增强注意力相结合的方式得到答案。
4)DLAN模型[32],该模型采用一种分层的方式来解决视频问答问题,按照问题重要性来获取问题视频表达,从而回答问题。
由于LSTM网络不可并行,因此Transformer模型[33]将传统注意力机制的LSTM网络改为可并行化的矩阵操作,然后进行注意力加权以达到训练时序数据的目的。由于GPU发展迅速,Transformer的网络参数可以很大却不会延长网络的训练迭代时间。此外,本文中的所有实验均为一个视频对应多个问题,实验过程中发现多输入训练能够使训练速度加快且准确率提升。多输入训练与单独训练的对比结果如表2所示,可以看出,相对单独训练模式,在ZJB-VQA数据集上使用多输入训练模式时训练迭代加快且准确率提升。

表2 2种训练模式对比结果Table 2 Comparison results of two training modes
4.1 模型参数及环境设置
对于ZJB-VQA数据集,本文将文本问题个数设置为5,与ZJB-VQA官方数据集的训练集一致,同时将视频的关键帧个数Lν设置为40,Faster R-CNN得到的图像特征大小为2 048,将参数P设置为36,通过Faster R-CNN得到的标签个数w为96,句子长度Lq为14,所有网络的隐藏层权重O为256,下采样后使用的帧个L′为16。本文实验配置均采用64 GB内存,显卡为1张GTX 1080ti,CPU为i7。
4.2 模型对比实验
VQA+模型与SA+模型是视频问答的基准模型,R-ANL模型、DLAN模型与Transformer模型采用了注意力机制。针对前文3种模型temporal-attention(简称TA)、attr-block-attention(简称ABA)和timespatial-attention(简称TSA)以及先验MASK,本文分别进行实验,结果如表3所示。
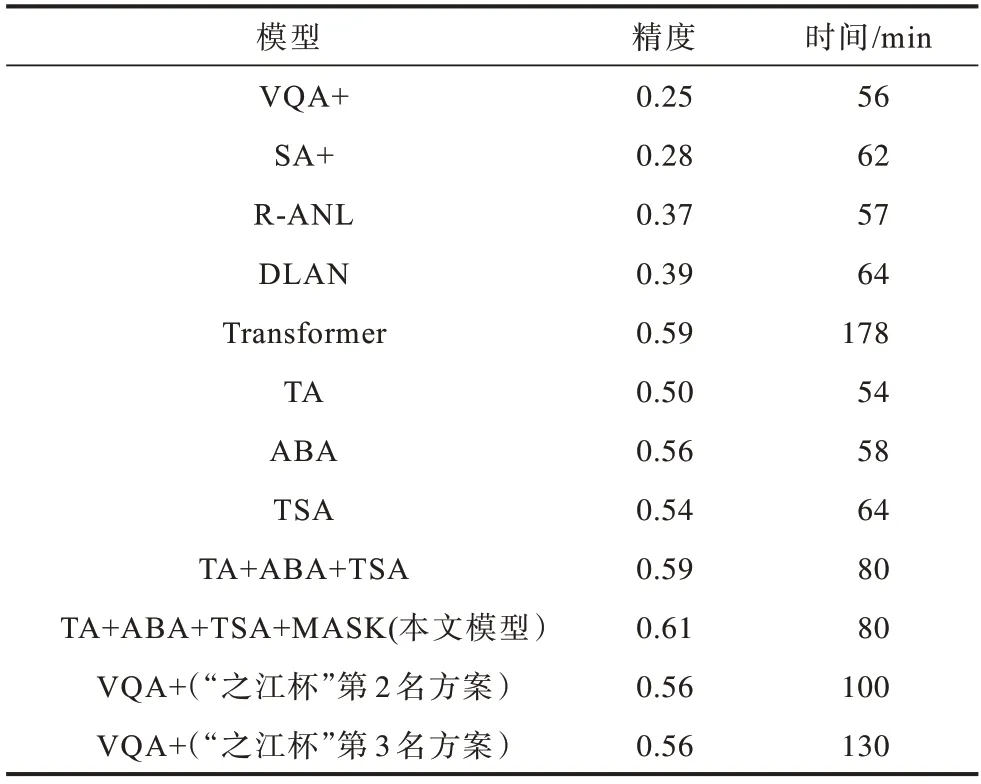
表3 ZJB-VQA数据集上各模型的性能对比结果Table 3 Performance comparison results of each model on ZJB-VQA dataset
从表3可以看出:
1)使用注意力机制的模型的泛化能力优于未使用注意力机制的模型。
2)本文提出的3个注意力机制组件(TA、ABA、TSA)均对模型精度有很大提升,将VQA+无注意力机制的模型精度提升到0.50以上,当3种注意力机制融合时可得到0.59的精度。虽然Transformer模型的精度也为0.59,但是其大幅增加了训练代价,训练时间约为本文模型的2倍。
3)本文提出的先验MASK可进一步提升模型精度,由于先验MASK仅对网络的最后一层输出进行处理,因此其未增加训练代价。
4)本文模型在2018年“之江杯”全球人工智能大赛视频问答组中的最终精度为0.61,而以VQA+为基准的第2名以及第3名方案的精度均为0.56。在现场演示阶段,本文模型在3 min之内得到5个测试样本的答案,表明其在精度和速度上均有良好的表现。
图10所示为本文模型在ZJB-VQA数据集上的训练准确率与损失值结果,其中,训练集与验证集以8∶2的比例划分。从图10可以看出,在训练迭代次数达到25时,训练集收敛开始波动,损失值下降变得平缓,说明模型已经达到饱和。验证集准确率提高缓慢,到30次迭代时模型设置了早停,从而保证模型的泛化性能,避免发生过拟合问题。
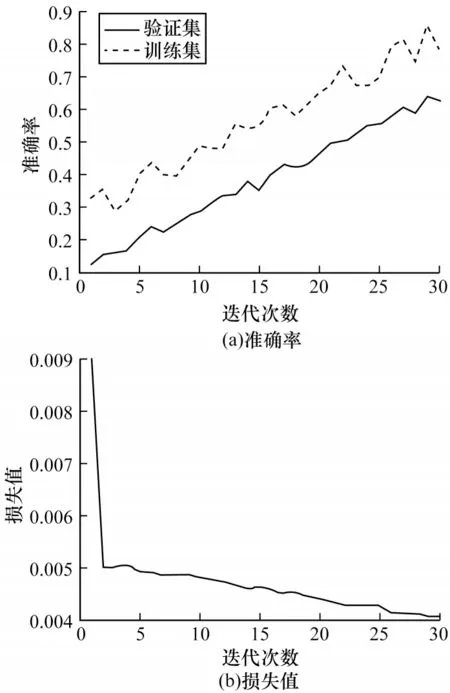
图10 本文模型在ZJB-VQA数据集上的实验结果Fig.10 Experimental results of the proposed model on ZJB-VQA dataset
4.3 实例展示
根据ZJB-VQA数据集的视频内容提出问题,利用本文模型对问题答案进行预测,如图11、图12所示。图11是一个女人坐在床边的视频,问题分别为“Is the person in the video standing or sitting?”以及“What color clothes does the person in the video wear?”,本文模型预测的答案分别为“sitting”以及“blue”,说明模型的预测结果符合视频场景。但是本文模型仍然存在不足,在图12中,第一个视频中一个男人拿着瓶子,女人将东西放到橱柜中,问题为“What is the woman in the video doing?”,模型预测为“looking things”,而答案是“putting things”,可见模型在预测一些包含复杂动作的场景时还存在局限性。

图11 模型预测正确示例Fig.11 Example of correct model prediction

图12 模型预测错误示例Fig.12 Example of incorrect model prediction
5 结束语
本文针对视频问答任务,构建一种先验MASK注意力机制模型,利用3种注意力从不同角度关注视频以及问题的兴趣点,通过先验MASK屏蔽与问题无关的答案,从而进一步提升模型性能。实验结果表明,相对VQA+、SA+等模型,该模型具有更高的精度与更快的速度。本文模型在2018年“之江杯”人工智能大赛中获得了视频问答组的冠军,验证了其有效性。后续将使用更深的网络(如ResNet-152模型)提取视频关键帧的特征,或使用BERT[4]和XLNet[5]等自然语言预训练模型提取问题特征,以提高视频问答模型的预测速度和准确率。
