基于模仿学习和强化学习的智能车辆换道行为决策*
2021-02-02宋晓琳曹昊天李明俊易滨林
宋晓琳,盛 鑫,曹昊天,李明俊,易滨林,黄 智
(湖南大学,汽车车身先进设计与制造国家重点实验室,长沙 410082)
前言
近年来,智能车辆已成为车辆工程领域的研究热点之一,具备自动驾驶系统的智能车辆相比传统车辆不仅更加安全、舒适,且有助于节约能源和降低污染物排放[1]。智能车辆自动驾驶系统通常由感知模块、行为决策模块、规划模块和控制模块等构成,其中行为决策模块是上层感知模块和下层规划控制模块间的重要桥梁,基于感知信息决策车辆应采取的行为,从而为下层规划控制提供目标引导,起着承上启下的关键作用,智能汽车换道行为决策是其中很重要的一种。
现有智能车辆换道行为决策方法按照决策机理,可以分为非数据驱动方法和数据驱动方法两大类。其中有限状态机(finite state machine,FSM)、动态博弈(dynamic game)等方法属于非数据驱动方法。例如冀杰等[2]将车辆行驶过程划分为车道保持、跟驰、变道和紧急制动4 种状态,构建有限状态机进行换道行为决策。Kurt 等[3]将决策过程进行层次划分,构造分层有限状态机用于决策,以此简化状态转移规则来提高决策时的规则查询效率。各类有限状态机方法均需要人为划分状态并制定状态转移规则,因而存在规则完备性的固有问题。有学者提出动态博弈方法,在换道行为决策时考虑车辆间的持续交互作用。Wang 等[4]将换道行为决策问题表述为微分博弈(differential game),假定自车和周边车辆进行非合作博弈,自车根据其他车辆的预期行为进行换道行为决策。Yu等[5]将自车及周边车辆视作斯塔克伯格博弈(Stackelberg game)参与者,估计周边车辆的驾驶激进度以确定其收益函数,通过在线求解动态博弈问题来确定自车换道行为。动态博弈方法求解平衡点的计算复杂度较高,在车载嵌入式计算平台上的实时性往往难以满足要求。
数据驱动方法主要包括模仿学习方法和强化学习方法等。模仿学习方法基于数据驱动,模仿专家驾驶员策略进行决策。例如Bojarski 等[6]使用卷积神经网络(convolutional neural networks,CNN)基于车载视觉传感器原始图像信息进行模仿学习决策控制,并在结构化道路场景和非结构化道路场景中进行了测试。Codevilla 等[7]在此基础上提出条件模仿学习方法,通过引入驾驶员指令来加速模仿学习并使驾驶员可在一定程度上干预决策以保障行车安全。Kuefler 等[8]则使用生成对抗网络(generative adversarial networks,GAN)模仿专家驾驶员进行决策,实验表明该方法能学习到诸如紧急状况处置等高阶策略。但模仿学习方法需要海量数据支持,存在模型训练成本较高、工作时无法根据环境变化在线调整优化策略、难以适应复杂多变的真实道路环境等不足。而强化学习可在与环境在线交互过程中学习得到优化策略,因此,近几年来强化学习在电子游戏[9]、机器人控制[10]和高级辅助驾驶系统[11]等领域取得一系列显著成果,因而有学者将其应用于智能车辆换道行为决策中。Mirchevska 等[12]使用深度Q 网络(deep Q network,DQN)深度强化学习方法进行智能车辆高速公路场景换道行为决策,仿真实验表明该方法决策性能优于传统基于复杂规则的方法。 Wang 等[13]采用连续的状态空间和动作空间,设计具有闭式贪婪策略的Q函数逼近器来提高深度Q 网络的计算效率,从而更快地学习得到了平稳有效的换道策略。然而,由于强化学习方法未利用先验知识,仅通过主动策略探索寻找优化策略,因而策略学习效率偏低,处理复杂问题显得能力不足,制约了其在智能车辆换道行为决策领域的应用。
针对强化学习方法策略学习效率偏低的问题,本文中将模仿学习引入强化学习,采用模仿学习从专家驾驶员示范数据中学习其宏观决策经验,换道行为决策时依据学习得到的专家驾驶员经验确定所需求解的换道行为决策子问题,构造多个强化学习模块分治处理不同的换道行为决策子问题,以此缩减强化学习所需求解问题的规模,降低优化策略学习难度,提高策略学习速度,从而使其比单纯强化学习方法能够处理更为复杂的智能车辆换道行为决策问题。
1 整体框架
本文中设计的智能车辆换道行为决策方法分为宏观决策和细化决策两层,如图1 所示。其中,每一换道行为决策周期t 所需输入信息It包括通过车辆总线获取的自车信息、通过感知融合获取的周边车辆信息和通过高精地图获取的道路信息。宏观决策模块使用模仿学习构建的极端梯度提升(extreme gradient boosting,XGBoost)模型,将It输入XGBoost模型的K 个基学习器CART 中,求和各基学习器输出s并通过Softmax变换得到宏观决策指令概率向量St,再依据St从车道保持、左换道、右换道中选择宏观决策指令Ct,缩减所需求解的换道行为决策问题规模。细化决策模块的3 个确定性策略梯度(deep deterministic policy gradient,DDPG)深度强化学习子模块DDPG_LK、DDPG_LLC 和DDPG_RLC 分别负责求解车道保持、左换道和右换道行为决策子问题,根据宏观决策指令Ct调用相应子模块,利用强化学习得到的优化换道行为决策策略,确定自车运动目标位置Pt,输出给下层模块后进入下一行为决策周期。

图1 行为决策方法整体框架
2 输入信息
由于车辆行驶时与周边车辆及道路均存在交互作用,因而换道行为决策时需要综合考虑自车运动状态、周边车辆运动状态及车道可通行性。图2 中carh 表示自车,自车的前方、后方、左前方、左后方、右前方、右后方6 个区域中最邻近周边车辆按顺时针方向标记为car1~car6。

图2 自车与周边车辆标识
换道行为决策输入信息如下。
(1)自车当前时刻t运动状态信息Sh,t:包括自车车速vh,t和纵向加速度ah,t。
(2)周边车辆当前时刻t 运动状态信息Si,t(i =1,2,…,6):包括与自车间纵向距离dyi,t、横向距离dxi,t和相对车速rvi,t。若某区域无周边车辆(如图2 中左前区域),则将距离设为∞,相对车速设为0。
(3)车道通行性信息Ir,t:由左侧车道标记和右侧车道标记flagl,t和flagr,t组成,记录自车相邻车道可通行状况,可供通行标记为1,不可供通行(如对向车道、非机动车道、路沿)标记为0。
最终,输入信息可用It表示为

3 宏观决策模块
本文中基于专家驾驶员宏观决策示范样本,构造XGBoost模型[14]模仿专家驾驶员选择宏观决策指令,选用分类回归树(classification and regression tree,CART)作为基学习器。模仿学习目标函数O(θ)定义为
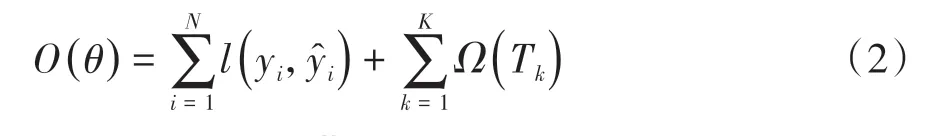
单个基学习器Tk的模型复杂度定义为
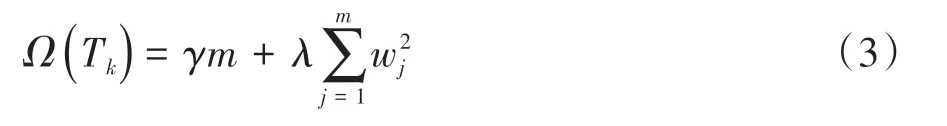
式中:m 为基学习器Tk的叶子节点数为节点权值的L2范数;权重系数γ、λ均取1。
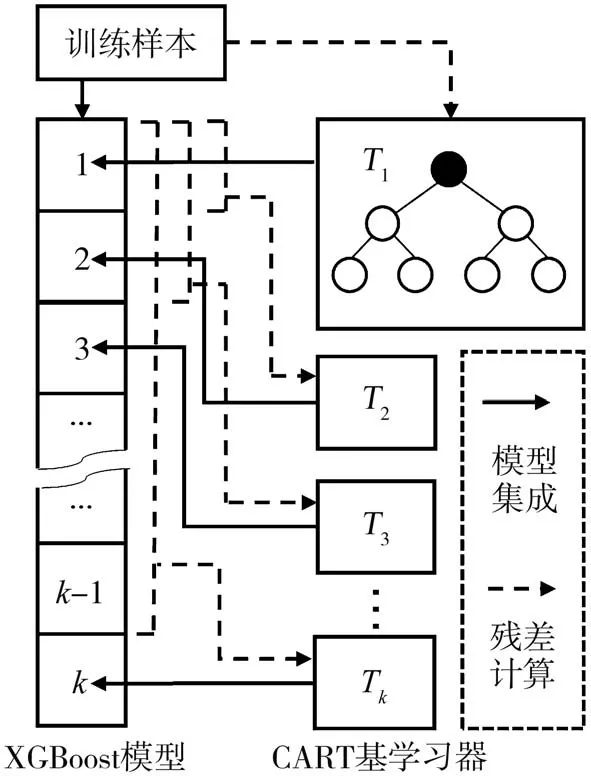
图3 XGBoost模型构建过程
XGBoost 通过集成一系列学习能力较弱的基学习器来获得较好的性能,模型构建过程如图3 所示。基于专家驾驶员宏观决策示范样本,不断训练CART基学习器拟合先前模型残差并集成入XGBoost 模型中,不断迭代直到训练预设数量基学习器或模型残差小于设定阈值。训练第k 个基学习器Tk时的学习目标函数为
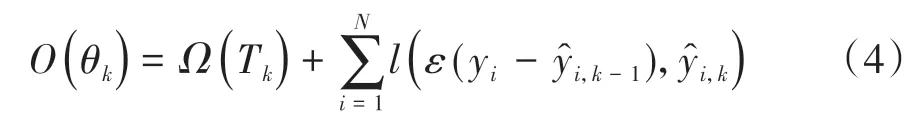
式中:θk为Tk的参数;Ω(Tk)为Tk的模型复杂度;yi-为前一轮迭代的模型残差为Tk的输出;学习率ε取值范围(0,1)。
如图1所示,换道行为决策时输入信息It传入宏观决策模块XGBoost 模型各基学习器,将各基学习器的输出向量s 求和后,利用Softmax 函数即可得到宏 观 决 策 指 令 概 率 向 量St=(p1,p2,p3),其 中p1,p2和p3分别是宏观决策指令应为车道保持、左换道和右换道的概率。选择概率向量St中最大概率值对应的宏观决策指令Ct输出,据此确定所需求解的换道行为决策子问题是车道保持、左换道还是右换道。
4 细化决策模块
4.1 马尔可夫决策过程定义
假定各换道行为决策子问题均满足马尔可夫性,将其构造为无模型马尔可夫决策过程(Markov decision process,MDP),表示为MDP(S,A,R,γ)。S为观测状态空间;s ∈S 为观测状态即输入信息It;决策动作空间A 为图4 所示目标车道中心线上的运动可达域,即自车本决策周期在车辆运动学约束下所能到达位置的集合;决策动作a ∈A,即自车本决策周期运动目标位置Pt;奖励R 表征环境对自车换道行为决策的反馈;γ ∈(0,1]为折扣系数,体现对短期奖励相比长期奖励的重视程度。

图4 运动可达域及运动目标位置
求解换道行为决策子问题即是寻找使该马尔可夫决策过程在无穷时域期望奖励值最大化的优化策略πopt:S →A

式中:t为决策时刻;k为决策时间步;Rt+k为第k时间步的奖励值;E[]为求数学期望。
4.2 DDPG深度强化学习
各子模块使用DDPG 深度强化学习方法[15]学习换道行为决策子问题的优化策略。利用具备强大非线性拟合能力的深度神经网络构造表征策略函数μ(s|θμ)的演员网络和表征动作价值评估函数Q(s,a|θQ)的评论家网络。通过经验回放[16]打破经历样本间时序相关性,同时采用类似DQN 的独立目标网络机制[17]来提高策略学习收敛性,DDPG 由主演员网络θμ、目标演员网络θμ,ta、主评论家网络θQ和目标评论家网络θQ,ta4部分构成。
如图1 所示,换道行为决策时细化决策模块根据宏观决策模块输出的宏观决策指令Ct,调用相应DDPG子模块的主演员网络,根据输入信息It确定自车本决策周期运动目标位置Pt,下发执行后将经历(It,Pt,It+1,Rt,Et)存入经验回放库中,其中It对应观测状态s,Pt对应决策动作a,It+1对应决策动作执行后更新的观测状态s",Rt为奖励值,Et记录是否满足终止条件。定期从经验回放库中随机采样经历样本,训练DDPG的主评论家网络和主演员网络。
训练主评论家网络以更加准确地评估动作价值,主评论家网络学习损失函数定义为
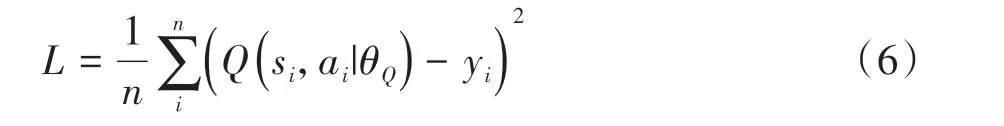
其中
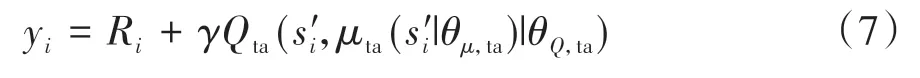
式中:n 为批采样经历样本数;Ri为经历样本i 奖励值;Q(si,ai|θQ)为使用主评论家网络估计的动作价值;Qta(s"i,μta(s"i|θμ,ta)|θQ,ta)为使用目标演员网络和目标评论家网络估计的未来动作价值。根据式(6)计算损失值,使用Adam 优化器按设定的学习率αQ更新网络参数。
训练主演员网络以优化换道行为决策策略,根据式(8)计算采样策略梯度值,使用Adam 优化器按设定的学习率αμ更新网络参数:

式中μ(s|θμ)为确定性策略。
目标演员网络和目标评论家网络无需训练,通过式(9)和式(10)所示更新方式使其网络参数缓慢逼近对应主网络:
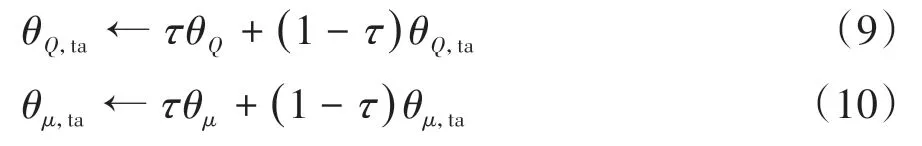
式中τ为目标网络参数更新率,0 <τ ≪1。
4.3 奖励函数设置
强化学习在奖励值引导下进行优化策略探索学习,因而奖励函数设置十分关键。为使换道行为决策策略兼顾安全性、通行效率及乘坐舒适性,各子模块奖励函数需包含如下3部分内容。
(1)安全性奖励函数:车辆行驶过程中,需与前后车辆间保持安全车距,安全性奖励函数可表示为

式中:Thf为自车与最近前车间的车头时距值;Thr为自车与最近后车间的车头时距值;Thb为车头时距阈值,Thb设定为4 s[18]。
(2)通行效率奖励函数:车辆在保证安全前提下,应尽可能以较高车速行驶,设置通行效率奖励函数为

式中:vh,t为自车当前车速;vl为当前路段限速;vf为当前路段车流速度。
(3)乘坐舒适性惩罚函数:车辆行驶过程中应避免频繁变速换道,以保证乘客乘坐舒适性,乘坐舒适性惩罚函数表示为

其中

式中:pa为急加减速惩罚项;plc为换道惩罚项。
则各子模块的复合奖励函数表示为

式中:ws、wv和wc为各项权重系数,调参确定的最佳权重系数取值为(0.9,0.8,0.4),归一化操作Normal用来将复合奖励函数取值范围变换到[0,1]区间。
5 实验与分析
5.1 专家驾驶员宏观决策示范样本采集
本文中使用图5 所示驾驶模拟器采集专家驾驶员宏观决策示范样本。其中虚拟驾驶环境为4.2 km 长的环形三车道高速公路,设置一辆可控自车和若干辆由自动驾驶模型[19]控制的环境车辆,各车辆均基于简化车辆运动学模型[20],道路全段限速90 km/h。
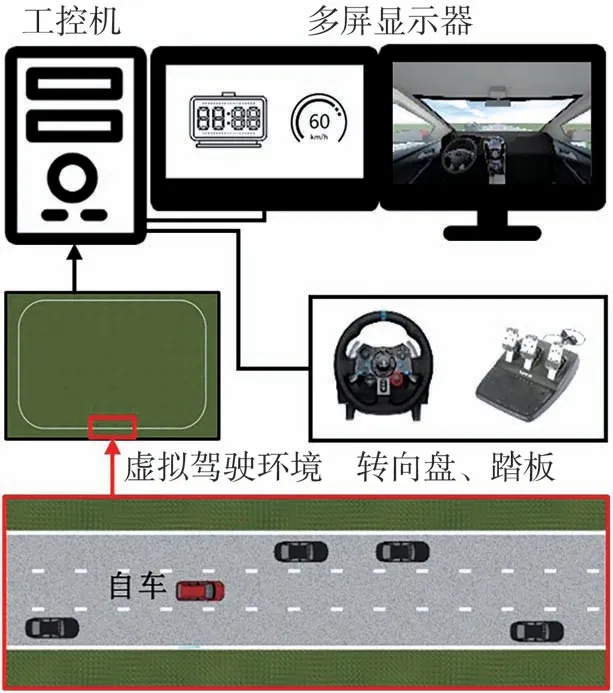
图5 驾驶模拟器及虚拟驾驶环境
由于不同驾驶员驾驶经验不同,因而宏观决策行为倾向性不同,为避免决策二义性问题,仅采集1名专家驾驶员的宏观决策示范样本。共进行10 轮模拟驾驶实验,每轮需驾驶自车在虚拟驾驶环境道路上行驶5 圈,以5 Hz 采样频率同步记录自车与环境车辆的状态、道路信息和驾驶员操纵输入。为避免疲劳驾驶,两轮实验间隔时间均大于15 min。
剔除驾驶员出现失误或违规的数据后获得约2.5 h 的原始数据。使用宽度为5 s、重叠量为2 s 的移动窗口从原始数据中提取样本:提取窗口起点时刻自车与周边车辆的运动状态信息和道路通行性信息,作为样本特征值;通过窗口范围内自车横向位置的极差判断驾驶员是否采取换道,将此宏观决策行为作为样本对应标签值。提取得到3 020 组专家驾驶员宏观决策示范样本,其中车道保持1 328 组,左换道873组,右换道819组。
5.2 宏观决策模块训练
为保障专家驾驶员宏观决策示范样本类别平衡,对车道保持类别样本进行下采样随机保留850组。网格调参确定的最佳XGBoost 模型训练参数设置如表1 所示。通过十折交叉验证评估模型性能,XGBoost 模型平均测试集分类准确率为91.46%,归一化混淆矩阵如图6 所示,算得kappa 系数值为0.87,表明构建的XGBoost 模型可以较好模仿专家驾驶员进行宏观行为决策。
使用专家驾驶员所有宏观决策示范样本训练得到最终XGBoost 模型。XGBoost 模型相比神经网络等黑箱模型的显著优势是其内在决策机理可知,因而安全性更高且易于迭代优化。可以通过统计XGBoost 模型中基于各学习特征组分裂的节点数目占比来获知其内在决策机理,如图7所示。由图7可看出,基于主车前方周边车辆car1~car3 的运动状态S1,t、S2,t、S3,t以及道路通行性信息Ir,t分裂的节点占比较高,对模型输出影响较显著,表明XGBoost 模型主要基于主车前方车辆的运动状态及道路通行性状况进行宏观决策。

表1 XGBoost训练参数设置

图6 归一化混淆矩阵
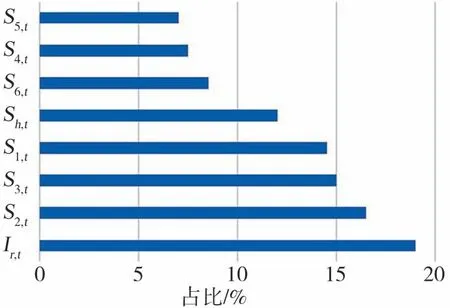
图7 分裂节点数目占比统计
5.3 细化决策模块训练
由于本文中着重研究换道行为决策,因而对下层模块进行简化处理:采用基于五次多项式的轨迹规划方法[21],并假定控制模块能使自车理想地跟踪目标轨迹行驶。
细化决策模块各DDPG 子模块网络结构如表2所示,训练参数设置如表3所示。通过与图5虚拟驾驶环境在线交互来训练各DDPG 子模块,每当自车行驶一圈或与环境车辆发生碰撞时终止当前训练轮次,重新随机初始化虚拟驾驶环境后开始新的训练轮次,直到完成设定轮次训练。
平滑处理后的训练过程中单步平均奖励值变化曲线如图8 所示,可看出经过约1 600 轮次训练后奖励值逐渐稳定在高位,策略学习收敛。由式(16)可知单步奖励理论最大值为1,但由于多数情况下自车需要在安全、通行效率和乘坐舒适性间平衡取舍,因而平均值必然小于1,图8中终端单步平均奖励值约为0.85,已较为逼近实际可达最优值。

表2 DDPG网络结构

表3 DDPG训练参数设置
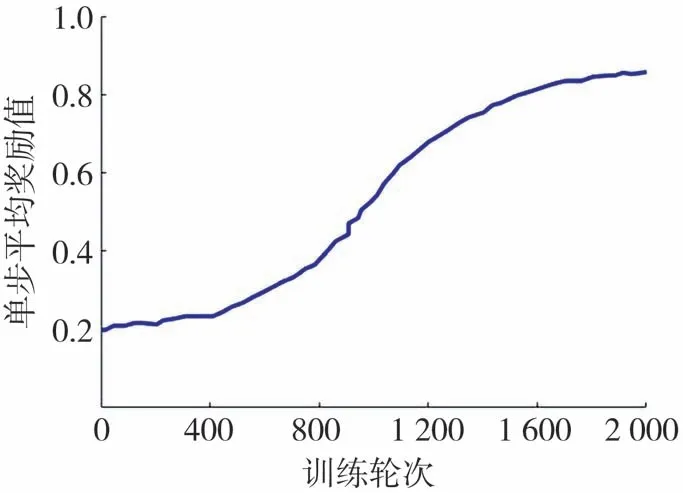
图8 单步平均奖励值变化曲线
5.4 测试比对
参与测试比对的换道行为决策方法如下。
(1)D_FSM:文献[19]提出的有限状态机方法。
(2)D_IL:基于多层感知机(multi⁃layer percep⁃tron,MLP)的行为克隆模仿学习方法,使用模拟驾驶实验采集的数据训练。
(3)D_RL:单纯强化学习方法,网络结构及奖励函数设置与本文细化决策子模块相同。
(4)D_IRL:本文中设计的模仿强化学习方法。
首先比对D_IRL 与D_RL 的策略学习速度。为消除随机因素影响,两者使用相同训练参数设置分别进行5 次训练,结果如图9 所示。由图9 可知,D_IRL 的平均终端奖励值相比D_RL 占优,且D_IRL平均策略学习收敛所需训练轮次数比D_RL 降低约32%,表明本文基于宏观决策指令缩减待求解换道行为决策问题规模的机制,有效降低了优化策略求解难度,显著提升了策略学习速度。

图9 策略学习速度对比
采用上述4 种方法分别控制虚拟驾驶环境中自车进行100 轮随机初始化的自动驾驶测试,以评估本文方法与各基线方法的换道行为决策策略综合性能,每轮行驶里程为1圈,结果如表4所示。
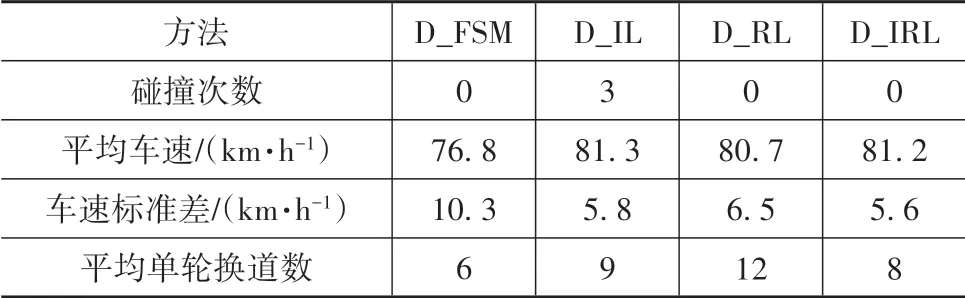
表4 自动驾驶测试统计结果
由表4可知如下结果。
(1)在安全性方面,D_IRL、D_RL和D_FSM 方法在测试中主车均未发生碰撞事件,而D_IL 有3 次碰撞记录,这可能是由于行为克隆模仿学习方法无法依据环境变化在线调整策略,遇到训练样本覆盖范围外的情形策略失效造成的,由此可见D_IRL 策略的安全性优于D_IL。
(2)在通行效率方面,D_IRL 策略的表现较优,测试中主车平均车速相比D_FSM 提升5.7%,相比D_RL提升0.6%,与D_IL基本持平。
(3)在乘坐舒适性方面,D_IRL 方法测试中主车车速标准差相比D_FSM 降低45.6%,相比D_IL降低3.4%,相比D_RL 降低13.8%,表明D_IRL 策略较少采取急加减速动作,乘坐舒适性较优。D_IRL 方法测试中主车平均单轮换道次数少于D_IL 和D_RL,减少了换道时横向加速度变化对乘坐舒适性的影响;D_IRL 方法测试中主车平均单轮换道次数高于D_FSM,这是因为D_FSM 基于规则的策略偏于保守,谨慎采取换道而比较容易引发紧急制动,而D_IRL 的策略则更加积极主动,通过更主动采取安全换道行为来提升通行效率,并通过规避部分不必要的紧急制动来提高乘坐舒适性,这一点在两者平均车速及车速标准差的对比中也可以得到体现。
综上所述,本文中设计的D_IRL 方法学习得到的换道行为决策策略的综合性能优于其他3 种基线方法,在安全性、通行效率和乘坐舒适性间取得了良好平衡。
5.5 场景测试
为了更直观地展现本文方法换道行为决策策略的性能,基于自动驾驶仿真软件Prescan 搭建两个典型场景进行换道行为决策测试。场景中主车的换道行为决策模块采用本文方法,环境车辆的运动由文献[19]的自动驾驶模型控制。两场景测试过程中的鸟瞰视角关键帧如图10 所示,图中主车为用红框标记的绿色车,各关键帧车辆实时速度也标注在图中,测试道路长度均为200 m。
由图10(a)可见:场景1中主车前后及两侧相邻车道均有环境车辆,且主车通行严重受制于前方白色车辆,主车换道行为决策模块根据输入信息,判定应采取左换道以获得更好的通行效率;主车安全换到左侧车道后,前向运动空间充足,平缓加速至目标车速行驶。
由图10(b)可见:场景2中位于主车同车道前方的红色车辆在开始阶段忽然制动减速,由于主车两侧相邻车道均有环境车辆且距离较近,主车换道行为决策模块根据输入信息,判定应采取减速从而避免与前车发生碰撞;待前车开始提速后,主车调整车速继续车道保持,以安全距离跟驰前车行驶。
由以上两个典型场景的测试结果可看出,采用本文方法学习得到的换道策略可以较好地应对主动换道、前方车辆急减速等情况,具备良好的工程应用前景。

图10 典型场景换道行为决策测试
6 结论
本文中设计了一种基于模仿强化学习的智能车辆换道行为决策方法,其中宏观决策模块XGBoost模型模仿专家驾驶员选择宏观决策指令,确定所需求解的行为决策子问题,在此基础上,使用细化决策模块对应DDPG 子模块强化学习得到的优化策略,确定车辆运动目标位置并作为行为决策结果下发执行。仿真结果表明,本文方法相比单纯强化学习方法在策略学习速度上有显著提升,且换道行为决策策略的综合性能优于有限状态机等现有方法。
本文研究中假定换道行为决策输入信息是准确无误的,实际情况中受车载传感器等因素影响,输入信息可能是不准确或不完整的。后续研究将考虑输入信息的缺失及噪声问题,以提高换道行为决策方法的鲁棒性。另外,如何在实车平台上应用本文中设计的换道行为决策方法也将是后续研究的重点内容。
