改进的图神经网络文本分类模型应用研究*
——以NSTL科技期刊文献分类为例
2021-02-01张晓丹
张晓丹
(中国科学技术信息研究所 北京 100038)
0 引 言
近年来,随着互联网数字资源的迅猛增长,如何从海量资源中挖掘出有价值的信息是数据挖掘领域的热点研究问题。文本大数据分类是这一领域的关键问题之一,多年来取得了丰富的研究成果。主要的分类方法可以归纳为两类:基于知识工程和基于机器学习的方法。基于知识工程的文本分类研究工作见文献[1-2]。这类方法的优点是分类准确度高,知识库可以处理复杂的类别,但主要缺点是知识库构造困难,且难以保证知识的覆盖率,所以适应性较差。基于机器学习的分类方法包括传统的机器学习方法(如:向量距离、Bayes、kNN、支持向量机(SVM)等)和近些年以来的深度学习网络[3],其中深度学习网络是目前效果最好的主流分类方法,但是不同深度学习分类方法的效果各有局限。
具有代表性的深度学习方法主要有RNN、CNN、Transformer等[5]。其中以LSTM/GRU为代表RNN方法不仅可以有效地处理不定长的线性序列文本数据,而且可以有效地捕获文本的长距离特征,但是由于RNN本身的结构设计,要求RNN在计算当前时刻的输出时要考虑到上一时刻的隐状态,从而导致RNN难以并行,运行速度慢,因此限制了RNN在文本信息提取中的发展和应用。CNN类方法利用了堆叠的卷积、非线性和池化操作来自动提取特征,在CNN的网络结构的设计中通常可以利用跨层连接机制来增加网络深度,从而提取更为有效的特征,但CNN在长距离特征捕获上性能低于RNN。图神经网络[6]方法是近几年发展起来的一种新的解决图形分类的方法,是目前深度学习领域研究的热点问题之一,具有处理不规则矩阵的功能,弥补了CNN等方法的局限。该模型对构建的拓扑关系图进行图卷积运算,获取特征从而实现文本分类。已在视觉发现、机器翻译等领域获得了很好的分类效果。但由于图神经网络方法的直推式原理,导致分类的效率不高。
科技文献大数据分类是文本挖掘的一个重要分支,随着科技文献剧增,传统的SVM、KNN等机器学习分类方法已难以满足科研人员的需求。如何为科研人员提供高效、准确的文献分类结果是文献挖掘领域的关键研究问题。随着深度学习的发展,为数不多的基于深度学习的分类方法逐渐在文献分类中得到应用。如RIOS使用CNN、李迪斐等使用RBM[3]等分类方法应用到文献分类中。虽然分类效果优于传统方法,但在准确率和效率方面仍然需要进一步提升。国家图书文献中心(National Science and Technology Library,NSTL)作为国家级的文献服务平台,拥有大量的外文文献资源,具有面向全国科技工作者提供文献服务的功能,目前所采用期刊分类号作为文献分类号的分类方法,分类效果不理想[3]。为了科研用户能得到更好的科研服务,提高文献的分类挖掘准确率和效率,提升国家级科研服务平台服务能力,本文拟将研究的深度学习方法应用到NSTL的服务平台上,以期为科研人员提供更好的知识获取平台
本文围绕图神经网络文本分类效率低的问题展开深入研究,提出了改进的图神经网络文本分类模型。该模型首先利用文本、句子及关键词构建多维的拓扑关系图和拓扑关系矩阵,再利用Markov Chain算法实现每一卷积层的节点采样,最后利用多级降维模型得到降维后的特征并实现分类。为了验证本文所提方法,分别采用现有的公用语料库和自行构建的 NSTL科技期刊文献数据语料库,对本文提出的方法进行了测试及比较。
1 改进的图神经网络文本大数据分类模型
由于图神经网络分类采用直推式的分类原理,导致该模型存在冗余训练和分类效率低下等问题。针对这个问题,文献[5]提出了基于归纳式推理的FASTGCN分类模型,该模型是在GCN模型的基础上采用归纳式的推理方式进行分类,拓扑关系图包含文本和关键词两种节点,蒙特卡洛算法需要递归到最后一层才能获得每一层的节点。虽然分类效率有所提升,但是分类准确率却不高。为了提高文本GCN的分类效率和准确率,本文对文本GCN和文本FASTGCN分类过程进行深入研究,提出了改进的图神经网络分类模型。该模型首先在构建的拓扑关系图中加入了具有语序特征的句子这一关键节点,同时,针对层节点需要递归到最后一层才能获得节点的采样问题,提出采用马尔可夫采样算法(Markov Chain)实现。由于Markov Chain的原理是层节点下一个状态只与当前状态有关,而与其他状态无关[6],因此在保证当前层节点准确率的前提下,采用此算法可大大降低采样效率。改进的分类模型如图1所示:
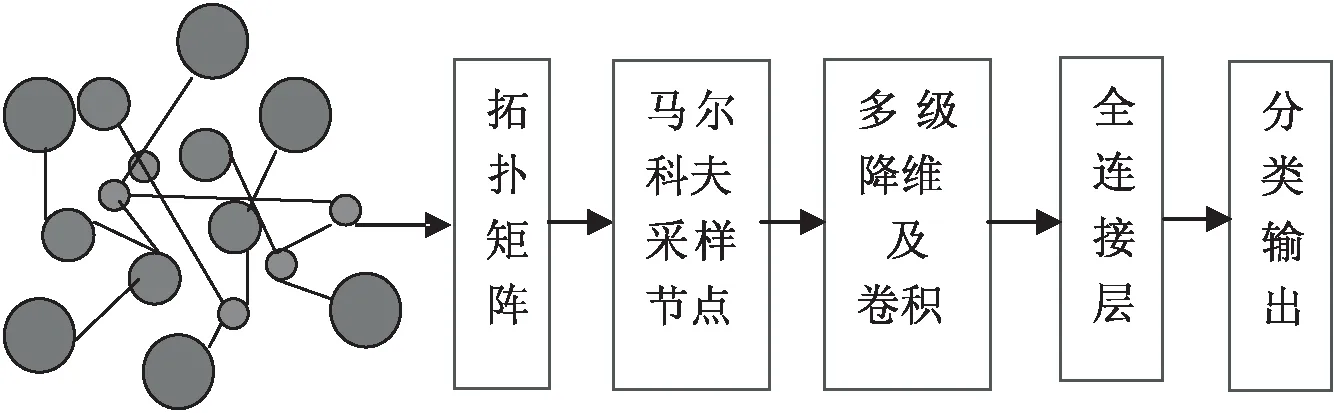
图1 改进的GCN文本大数据分类模型
从图1中可以看出,该模型由拓扑关系图、拓扑关系矩阵、Markov Chain采样、特征多级降维及卷积、全连接及分类输出等部分组成。其中,拓扑关系图是由文本、句子及关键词三种节点构成,不同的节点采用不同大小的圆表示。具有关系的不同的节点之间有线连接。拓扑关系图转换成拓扑关系矩阵后,通过Markov Chain采样算法实现各个卷积层的节点采样。再利用PCA多级降维进行特征降维和卷积,得到降维后的特征输入到全连接层,最后进行分类并输出分类结果。
为了避免直推式的分类原理,GCN采用归纳式推理方法实现分类。归纳式演化见公式(1)、公式(2)。
L(m-1)(v,:)=
l=0,1,…M-1
(1)
其中,获得的损失函数如公式(2)所示。
(2)
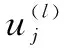
a.构建拓扑关系图。拓扑关系图由节点和边组成,其中节点包括文本、句子和关键词。边是具有关系的相邻节点之间的连线。在文本GCN和文本FASTGCN的拓扑关系图中,只有文本和关键词两类节点,忽略了句子这一带有语序特征的节点类型,因此,本文将句子节点加入拓扑关系图中,以期提高分类准确率。
文本节点是由待分类的文本组成。句子节点是从文本中抽取得到的。关键词节点是对文本进行分词得到的。拓扑关系包括文本与关键词,关键词与关键词,文本与句子,句子与句子及句子与关键词之间的关系等。
b.构建拓扑关系矩阵。拓扑关系矩阵是由拓扑关系图中相邻节点的关系值组成的矩阵,如关键词与关键词之间可以采用BERT等算法计算得出,文本与关键词之间可采用共现等关系表示,文本与句子采用共现等关系表示,句子与句子以及句子和关键词之间采用BERT等算法确定二者的相似性关系。其中,BERT是一种使用Transformer作为基本框架的预训练分类模型,对于位置向量中的维度,使用公式(3)和公式(4)来表示[9,11]:
PE(pos,2i)=sin(pos/100002i/d)
(3)
PE(pos,2i+1)=cos(pos/100002i/d)
(4)
其中,PE表示一个句子中所有词位置向量组成的矩阵。行表示词语,列表式位置向量,列的大小与BERT 中生成的词向量维度一样;pos为词在句中的位置,d为词向量的维度大小;i表示位置向量中某一维所在位置。如公式所示,奇数位置使用正弦函数计算得到,而偶数位置则使用余弦位置计算得到。遍历所有位置后,所得到的向量即所需的位置向量。
具体算法为:

Algorithm sentence,keyword ,BERT for s=1 to S do; for i=1 to I do: if (i%2==0) do: sin(pos/100002i/d) Else do: cos(pos/100002i/d) End for Write PE End for
c.基于马尔科夫链算法的采样。文本GCN分类模型需要对不输入节点进行采样,才能将节点分配到不同的卷积层,即多个batch,对每一层根据概率q(u)抽取数量为n的节点。前一层抽取的节点用来近似计算后一层的节点的向量,即前一层抽取出来的节点作为下一层抽取出来的节点的共享邻居集合。由于下一层的节点可以完全由上一层的节点计算得到,因此本文提出采用马尔科夫链(Markov Chain)模型实现上一层节点对下一层节点的评估和计算,可避免FASTGCN模型中需要递归到最后一层才能确定所有层节点的问题,提高节点的采样效率。具体算法为:

d.多级特征降维及卷积。以GCN为代表的多种深度学习方法都是通过构建多层网络,对分类目标进行多层表示,通过多个高层次特征表示数据的语序特征[7-8]。因此在多层卷积过程中,由于对数据高度依赖,使得需要处理的数据维度剧增,过高的数据维度会造成维度灾难,影响分类性能。如何降低特征维度,是目前深度学习研究的重要问题之一。基于PCA的降维方法旨在将多个不同特征指标转化为少数几个综合指标的优越性,而深度学习属于机器学习的一种,因此可以采用PCA方法实现特征降维。基于PCA的多级特征降维模型如图2所示。
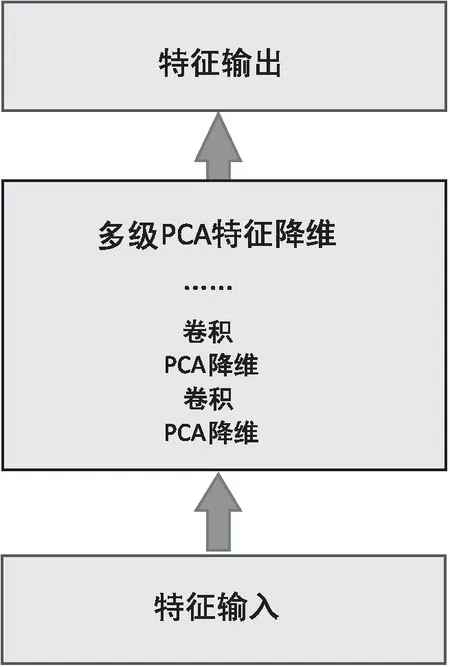
图2PCA多级特征降维模型
从图2可以看出,首先对输入的拓扑矩阵进行一级降维,即对矩阵进行数据采样,求均值,并与其转置矩阵进行相乘等操作,获得降维后的特征并输入到卷积层进行卷积。经卷积得到的特征再次进行二级降维,即进行采样、求均值及转置相乘。再将第二次降维后的特征输入到第二层卷积层进行卷积操作,依次类推,直至满足所设定的阈值即可,最后将得到的降维后的特征输入到全连接矩阵。主要步骤如下:
首先,采样。对拓扑矩阵进行全局采样,获得采样后的样本矩阵X。
其次,一级降维及卷积。通过PCA寻找一系列的标准正交矩阵来最小化重构误差,并求得X矩阵的前m个特征向量组成特征映射矩阵,实现降维。降维公式(5)为:
(5)
其中,F为PCA滤波器,R为采样矩阵,M滤波器的数量;将降维后的特征数据输入卷积层进行一级卷积。
第三,二级降维和卷积。对由上一级降维获得的特征矩阵执行相同的降维操作,获得降维后的矩阵M,输入到卷积层进行卷积。
第四,多级降维及卷积,直至误差在所设阈值范围内为止。
最后,矩阵输入全连接层。将降维后的特征输入到全连接层。
e.分类并输出分类结果:将全连接层的特征输入到分类层实现分类。
f.待分类文本分类。将批量的待分类文本采用以上步骤训练并分类,可以得到最终的分类结果并输出。
2 实 验
文本分类是个实验性较强的研究方向,且有常用的评价标准。本文为了验证所提出分类模型的准确率和效率,选择的测试指标除了准确率外,还增加了推理时间这一项。采用公用语料库20NG、Ohsumed及MR和自行收集的NSTL科技期刊文献数据语料库。选择常用的CNN、LSTM、文本GCN[10]等文本分类方法与本文提出的方法进行性能比较和评价。
语料库:
公用语料库:20NG数据库包括18 846个文件,20个类,训练集11 314条数据,测试集7 532条数据。Ohsumed医学的文献数据库来源于医药信息数据库MEDLINE10,包含了从1987-1991年5年间的270个医药类杂志的标题或摘要,包含348 566个文档。我们使用了1990年的16 890篇文献类别为2个,其中训练集3 680条数据,其余为测试集。MR语料库,是电影评论的语料库,每个语料都是一个句子。语料库中包含5 331个正向评价和5 331个反向评价。
自行构建的NSTL期刊文献语料库,选择2019年3-5月的20 000条科技文献作为语料,分为社会科学总论、军事、医药卫生、工业科技及航空航天等5个一级类别。每个类别中的数据为4 000条,训练数据为3 000条数据,测试数据为1 000条数据。
对以上所有数据集进行数据清洗和对原始数据进行标记并去除停用词和低频词等预处理,再进行测试。
参加测试的有CNN、LSTM、文本GCN及本文提出的方法。实验采用的程序是从网上下载的开源程序,因功能需要进行了部分更改。激活函数选择RELU;分类函数选择SOFTMAX函数;误差函数选择交叉熵函数,通过将模型分类结果与输入带有标签的文献分类对比获得误差,采用梯度下降方法反传误差对模型参数进行训练,直到误差在预设阈值范围。需要说明的是,本文所提出的方法,以NSTL语料库构建的拓扑关系图包含节点和边,其中,文本节点是由期刊文献的标题、摘要及关键词组成,句子节点是通过LSTM算法对文献摘要进行抽取得到的。关键词节点是对文献的摘要、标题进行分词得到的,包含文献的关键词。根据关键词所处的位置不同,不同的关键词具有不同的权重。即处于文献中标题和关键词位置的关键词具有较高的权重。边是相邻节点之间的连线,代表之间具有一定的关系。具体包括文献与关键词,关键词与关键词,文献与句子,句子与句子及句子与关键词之间的关系等。其中,关键词与关键词之间的关系,以及句子与句子之间的关系采用BERT算法实现。关键词与文献及句子与文献采用共现TFIDF算法实现,关键词与句子之间的关系采用word2vec算法实现。
在实验过程中,本文方法的拓扑关系图的节点数有2 121个,边数为5 861,类别数量为5,特征数量为500。当增加BATCH时,训练速度得到提升,同时,反向传播过程中,梯度下降法更加准确,训练更充分。另外,学习率会影响模型的收敛效果,学习率设置比较大时,梯度值不能收敛,学习率设置比较小则会延长训练时间导致过拟合。本文针对不同的学习率进行参数实验,实验结果表明,卷积层为3层, BATCH SIZE为512,学习率为0.01时,本文提出的模型的准确率及召回率最高。不同分类模型的分类测试结果如表1所示(其中,文本GCN、CNN、LSTM方法的实验数据参考文献[12]中的结果)。
测试结果可以看出,LSTM和CNN方法更依赖于词嵌入的预训练。而本文方法只使用语料的信息即可。GCN方法忽略了词的语序信息,而本文方法和LSTM、CNN方法都具有语序信息,有助于提高分类准确率。MR的语料句子都非常短,因此GCN及本文方法在准确率方面无法超过CNN和LSTM方法,主要因为文档和词之间的关系很少。

表1 多种分类模型分类结果对比
本文提出的分类方法在20 NG、 Ohsumed及NSTL语料库的分类准确率和推理时间,都有优势。因此,可以看出,拓扑关系图的句子节点对提高分类准确率具有优势,采用马尔科夫算法及多级特征降维策略可有效提高文本分类效率。
3 结 论
随着深度学习的发展,使得基于深度学习的文本大数据分类成为可能。本文针对图神经网络GCN模型存在的分类效率和分类准确率问题展开深入研究,提出了基于Markov Chain采样算法对节点进行采样,基于PCA多级降维和卷积的特征多级降维提取方法。最后,采用公用语料库和自行构建的NSTL文献语料库对本文提出方法的性能进行测试。实验结果表明,本文所提出的方法能有效提高NSTL科技期刊文献大数据分类的准确率及效率。
