基于YOLOV3的干垃圾品质检测方法
2021-01-30张欧
张欧
(上海环境物流有限公司 上海市 200063)
1 引言
随着全国生活垃圾的与日俱增,给资源环境和经济社会可持续发展带来较大压力[1]。2019年上海市正式实施《上海市生活垃圾管理条例》,该条例将通过法律的强制性推动垃圾分类,并在居住区普遍推行生活垃圾分类制度。垃圾分类品质的好坏直接影响到后端的垃圾回收处置,目前垃圾中转站对垃圾分类品质的评判主要靠人工为主,人工检测存在成本投入高、效率低、误检率高等缺点。
传统的机器视觉技术早已应用于简单的垃圾种类识别[2],其识别精度并不高,随着近些年深度学习技术的发展,机器识别技术也进入一个全新发展阶段。特别是图像检测领域,图像检测是指在图像中判别物体的类型并标注出物体所在的位置。基于深度学习的检测框架先后出炉[3],一类是基于two-stage 的目标检测框架,比如RCNN,Fast RCNN,Faster RCNN,将检测任务分为回归(location)和分类任务。还有基于one-stage 的目标检测框架,例如YOLO/YOLOV2/YOLOV3,SSD 等,同时完成检测和回归任务,将目标检测问题当作成一个回归问题,网络结构简单,检测速度快,基本能满足实时检测的要求。
目前大部分研究集中在垃圾前端的垃圾种类识别,而对复杂环境下的垃圾定位和识别很少有人研究,本文采用基于深度卷积神经网络的YOLO V3 算法对干垃圾倾倒过程中垃圾的水流进行识别分析,为干垃圾后端处置提供实质性指导。
2 实验数据采集
本次实验的干垃圾图像数据采集于上海市某垃圾中转站,在不同光照强度、不同背景、不同角度、不同远近大小的情况下,通过工业高清摄像机抓拍干垃圾车向垃圾集装箱中倾倒垃圾的过程,获得干垃圾倾倒的照片,并筛选出两大类图像,第一类干垃圾图像:照片中没有水流但有类似水流的长条形塑料袋;第二类干垃圾图像:照片中有水流,水流的数量不等。
两类干垃圾图像共采集到8000 张,其中第一类图像2000 张,第二类图像6000 张,然后将所有收集到的图像统一剪裁为512×512像素。为了提高训练结果的泛化性能,在模型训练时通过数据增强增加了数据集的多样性,对图片进行随机旋转180、随机水平翻转、随机垂直翻转和图像裁剪等处理。水流类别有小水流(smallwater)、大水流(bigwater)和其他(other,此类别为类似水流的絮状干垃圾,如长条垃圾袋等)三种。
3 YOLOV3基本原理
YOLOv3[3]是YOLO (You Only Look Once)系列目标检测算法中的第三版,相比之前的算法,尤其是针对小目标,精度有显著提升。YOLOv3 主要改进有:调整了骨干网络结构、利用多尺度特征进行对象检测、对象分类用Logistic 取代了softmax。
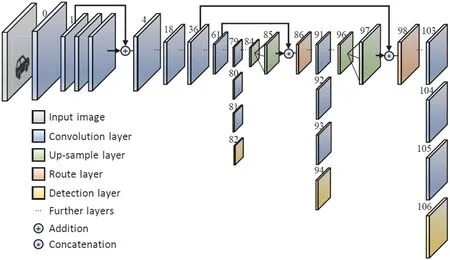
图1:YOLOv3 网络结构
YOLOv3 以darknet-53 为骨干网络,其网络结构如图1所示,darknet-53 借用了ResNet 的思想,每个残差模块由两个卷积层和一个快捷连接组成,整个YOLOv3 结构里面只有残差模块,没有池化层和全连接层,YOLOv3 应用残留跳过连接来解决深度网络的梯度消失问题,并使用上采样和级联方法保留细粒度的特征以用于小物体检测,每个卷积层后面都接一个批次归一化层和一个LeakyRelu 激活层,并引入ResNet 残差模块以解决网络深度加深时所出现的训练退化问题。YOLOv3 最突出的特征是以特征金字塔网络相似的方式在三个不同的尺度上进行检测,使其可以检测各种大小的对象。
更详细地,当将R,G 和B 的三个通道的图像输入到YOLOv3网络中时,将输出有关物体检测的信息(即预测框坐标,物体得分和类别得分)。从三个检测层,使用非最大抑制对三个检测层的预测结果进行合并和处理,确定最终的检测结果。
4 实验与结果分析
整个实验均基于深度学习框架TensorFlow 进行,编程语言为Python,实验依靠迁移学习用经ImageNet 数据集训练的Darknet-53参数进行初始化,训练时设置批次大小为4,优化器采用随机梯度下降算法(Stochastic Gradient Descent,SGD),初始学习率为0.0001,动量为0.9,权重衰减正则系数为0.0005,在此基础上将网络所有层训练80 个迭代次数。在训练过程中通过比较损失大小,保存损失最小的模型参数,通过多次试验优选得到最终的权重文件并冻结为检测模型。
为评估YOLOV3 算法对干垃圾中水流的检测有效性,采用平均准确率均值(mean Average Precison,mAP)来作为衡量模型性能的指标。mAP 是指所有类别目标的平均准确率(Average Precision, AP)的均值,它可以作为目标检测的实际度量标准。
本文实验的数据集是由8000 张复杂环境下干垃圾照片组成,其中第一类照片(此类照片无水流但有类似水流的絮状干垃圾,因此只有other 这类标注信息)2000 张,第二类照片(有水流,标注类别有smallwater 和bigwater)6000 张。由于模型应用的环境特别复杂,干垃圾形态多种多样,导致类似水流的絮状物容易被误识别为水流,为了降低此类絮状物干垃圾(如长条的垃圾袋等)的误识别率,本文实验训练了两个不同的数据集样本,具体样本如表1所示。数据集I 中只包括第二类照片,即只包括有水流的干垃圾照片;而数据集II 则包括了两类的所有照片。对于两种数据集的模型训练,训练集和测试集的数据均按8:2 的比例随机从各自样本中随机抽取。
通过对数据集I 和数据集II 的数据进行模型训练,分别得到两个稳定的模型,模型1 和模型2。将两个模型分别对各自样本集中的测试集进行检测,即模型1 检测数据集I 中的1200 张测试集照片,模型2 检测数据集II 中1600 张测试集照片,具体检测结果如表2所示。
通过测试可以发现,模型1 测试的mAP 为75.4%,统计发现模型1 对絮状干垃圾的识别率较高,特别在水流很小的情况下,很容易将絮状干垃圾误识别成水流。而模型2 测试的mAP 相对模型1 高出8%,同时发现模型2 对絮状干垃圾的误识别率明显少于模型1,其出现误识别的情况较少,即使当水流很小的时候,也很少出现误识别,准确率明显提高。
图2 显示了模型2 对干垃圾中水流的部分典型识别结果,紫色框为大水流(bigwater),蓝色框为小水流(smallwater),从图3(a)和3(b)可以发现,模型2 能准确的识别出干垃圾中的水流。同时在水流较小且存在较多类似水流的絮状干垃圾的情况下,模型2在识别出小水流的同时不会对絮状干垃圾误识别。通过实验说明,在复杂环境下,当干垃圾中存在类似水流的絮状物干垃圾时,通过对这些类似水流的絮状物干垃圾进行单独标注,并与水流类型进行区分,将此类单独标注的絮状物干垃圾照片与含水流的干垃圾照片合并成一个数据集,并放入YOLOV3 中进行训练,能提高模型的精度,同时能很大程度上减少模型的误识别率(即明显降低了模型对絮状物的误识别率)。

表1:数据集样本数量

表2:数据集I 和数据集II 的测试数据检测结果比较

图2:模型2 的识别结果
5 结束语
针对复杂环境下干垃圾倾倒过程中水流的检测识别,本文详细阐述了基于YOLO V3的水流检测方法,包括数据集采集、算法原理、模型训练和优化。通过实验结果对比发现,在复杂环境下,通过反向标注干垃圾照片中类似水流的絮状物垃圾,并将此类照片与有水流的照片一起放入模型中进行训练,能明显提高模型的精度,同时能有效地降低模型的误识别率,明显减少了模型对类似水流干垃圾的误识别。同时结果表明,基于YOLOV3 的干垃圾水流检测方法能够准确地识别出干垃圾中的水流,满足干垃圾品质识别的要求,可以取代人工检测,提高干垃圾品质识别的检测效率。
