基于随机森林算法的清水河流域生态系统健康评价
2021-01-29王文川梅宝澜李磊徐雷
王文川, 梅宝澜, 李磊, 徐雷
(华北水利水电大学 水资源学院,河南 郑州 450046)
气候变化以及人类活动的加剧引发了水土流失、植被破坏、极端洪水等一系列问题,进而导致流域生态系统遭受了不同程度的破坏。因此,生态系统的健康状况引起了人们的广泛关注[1]。生态系统健康的概念产生于20世纪70年代,RAPPORT D J[2]在全球生态系统普遍退化的背景下讲述了生态系统健康的内涵。流域生态系统健康,一方面是指从生态系统自身出发,其本身能够保持结构完整性、稳定性以及自我修复性;另一方面是指人类活动与自然生态之间的相互影响,能够促进人类经济社会和谐发展,充分发挥流域生态系统的服务功能。在流域生态系统健康备受重视的今天,对流域生态系统健康状况进行评价,及时掌握流域生态健康状况以及为人类社会发挥服务功能的情况,可为今后流域内的水资源管理与保护、生物多样性、流域可持续发展等提供有益的借鉴。
针对流域生态健康评价,国内外学者对此进行了大量的研究。国外起步较早,如美国、英国、澳大利亚等国家建立了不同的评价标准体系[3-8],许多学者也从不同角度进行了研究[9-12]。国内这方面的研究起步较晚,主要是对流域生态健康体系[13-15]以及评价方法的研究。其中,针对评价方法的研究主要包括层次分析法[16]、综合指数法[17]、模糊物元模型法[18]、灰色关联分析法[19]等。这些方法偏于受主观因素的影响,且在流域影响因素较多、评价指标较多的情况下,这些方法对处理高维非线性样本数据的适应能力不强[20]。随着数据信息的不断增加,刻画流域生态系统健康的要求更加细致,需要更多的指标来衡量一个流域的生态系统健康情况,由此凸显传统评价方法的不足。因此,探讨合适的评价方法就显得十分必要。随机森林算法是一种机器学习算法,该方法不同于指标赋权法,它不会造成主观上的偏差;它能够根据数据信息进行驱动,利用计算机强大的数据处理能力解决高维非线性数据样本的问题;不需要做特征选择,对数据的泛化能力强,即便是有一部分特征数据缺失,随机森林算法仍能够维持一定的准确度,并在计算过程中得出特征的重要性排序。
清水河是宁夏境内直入黄河的第一大支流,对其进行流域生态系统评价可以判断其健康状况,并依据评价结果对其进行修复。习近平总书记于2019年9月18日提出,推进黄河流域生态保护和高质量发展,已上升为国家重大发展战略。保护好母亲河是中华民族永续发展的大计,要从根本上解决黄河流域面临的生态保护与社会经济发展之间的结构性矛盾[21-22]。因此,本文以清水河流域生态系统健康评价为例,提出基于随机森林算法的流域生态系统健康评价方法,更加准确地揭示清水河流域的生态健康状况,以期为清水河流域生态保护和高质量发展提供参考依据,并为保护和恢复清水河流域生态系统健康提供理论支撑。
1 研究区域与研究方法
1.1 研究区域
清水河是宁夏境内入黄河的最大支流,发源于六盘山北端东麓沽源县开城乡黑刺沟,自南向北流经宁夏的固原、同心县城,在中宁县泉眼山注入黄河,其流域形状如图1所示。地理位置在东经105°00′~107°07′,北纬35°36′~37°37′,河道平均比降为1.49‰。清水河流域总面积为14 481 km2,其中宁夏境内面积为13 511 km2,甘肃境内面积为970 km2[23]。

图1 清水河流域图
1.2 研究数据
本文研究范围为清水河流域原州区段,选取7个控制断面,分别为原州城区、三营镇、头营镇、彭堡镇、开城镇、中河乡以及寨科乡。从生境结构、水生生物、生态压力3个方面进行评价,其中:生境结构的评价指标为水质状况指数、枯水期径流量占同期年均径流量比例、河道连通性3项;水生生物的评价指标为大型底栖动物多样性综合指数、鱼类物种多样性综合指数、特有性物种保持率3项;生态压力的评价指标为水资源开发利用强度、水生生境干扰指数2项。将流域评价体系分为目标层、准则层、指标层3个层次,目标层即为流域生态系统的健康状况,准测层即为生境结构、水生生物、生态压力3个方面,指标层即为上述8项指标。本文数据来源于文献[24],其值见表1。
根据生态环境部发布的《地表水环境质量评价方法》《河流生态调查技术方法》,文中将此次研究的8项指标的评价结果根据不同的标准划分为优秀、良好、一般、较差、差5个级别,具体见表2。

表1 清水河流域(原州区段)7个控制断面的评价体系与数据
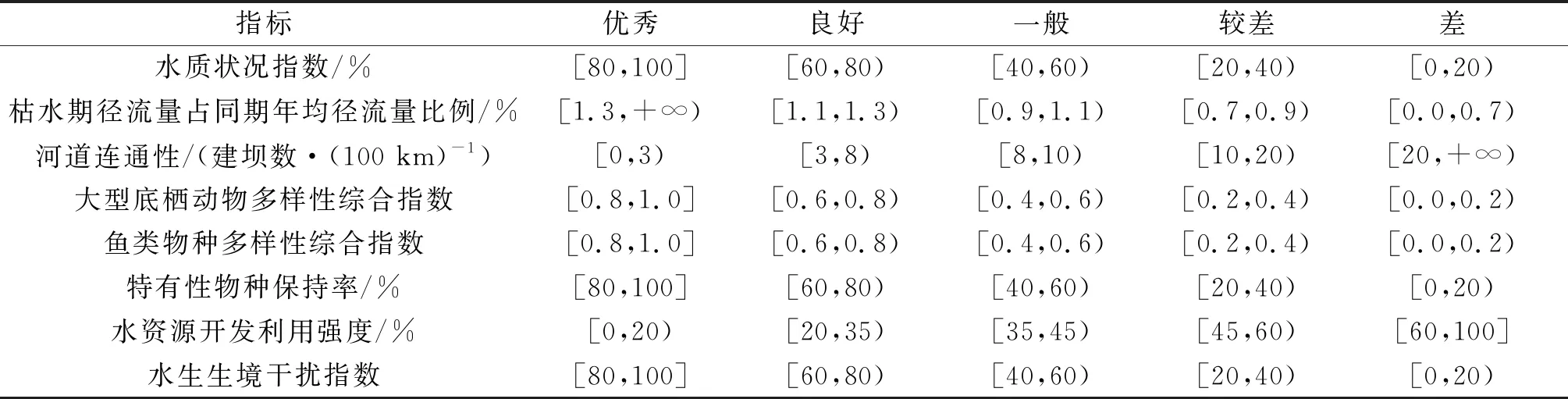
表2 清水河流域(原州区段)8项指标的评价等级
1.3 随机森林算法
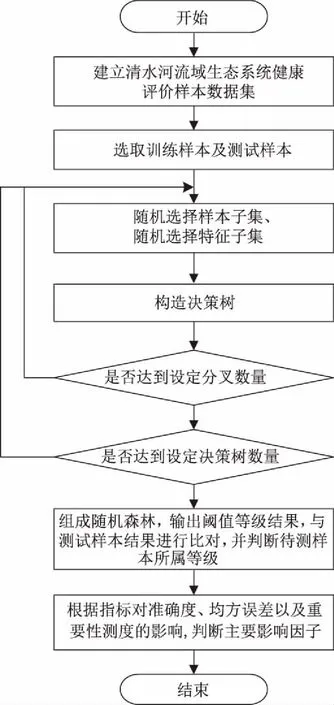
随机森林算法是由加州大学伯克利分校的Leo Breiman提出的,属于集成机器学习方法[25]。随机建立多决策树组成森林,决策树之间无关联,每棵决策树采用Bootstrap法进行有放回采样,根据所有决策树回归目标的平均值作为最终回归结果。随机森林算法可以视为由大量弱回归器(决策树)集合而成的强回归器。具体步骤如下,算法流程图如图2所示。
步骤1 构建自助样本集:基于bootstrap法从原始样本中有放回地抽取样本,得到m个自助样本集。
步骤2 构建决策树和袋外数据集:利用步骤1得出的m个自助样本集,分别构建m棵决策树,并将未选中的样本组成m个袋外数据用于检测。
步骤3 随机选取属性:每棵决策树都有分叉节点,从n个属性中随机选取l个属性(l 步骤4 递归分解:自顶向下地从每个分叉点进行划分的候选属性中,按照节点不纯度最小的原则对每棵决策树进行分解,直到满足条件为止。 步骤5 得到结果:对每棵决策树的结果求平均,得到整个随机森林的最终结果。 在随机森林算法中,决策树数量与分叉数量这两个参数对回归精度影响较大。决策树数量设置过小,容易造成随机森林算法训练的不够充分,进而造成模型“欠拟合”;数值设置过大,则容易造成训练过度,进而造成模型“过拟合”。分叉数量若设置过小,容易造成模型训练过度,进而造成模型“过拟合”;若设置过大,容易造成模型训练不足,进而造成模型“欠拟合”。无论是“欠拟合”还是“过拟合”均会影响模型的最终精度。 图2 随机森林算法流程图 根据上文给出的清水河流域生态系统健康评价指标体系与数据,可构建基于随机森林算法的流域生态系统健康评价模型。具体步骤如下,流程如图3所示。 步骤1样本数据集建立。根据表2的评价等级阈值,在每个区间内生成200组样本,随机内插到1 200组样本中,再将5个评价等级与7个控制断面数据列为12组数据,共得到1 212组数据,将此作为样本数据集。 步骤2样本设置。从1 212组数据集中,随机选取600组样本数据作为训练样本,其余612组样本数据为测试样本,其中评价等级与控制断面数据需要放在测试样本中。 步骤3随机森林模型构建。利用MATLAB R2016a软件,安装随机森林工具箱,将样本中的8项评价指标值作为输入向量,评价等级作为输出向量,建立“8输入、1输出”的基于随机森林算法的流域生态系统健康评价模型。 步骤4模型参数设置。构建决策树,随机选取属性,设置分叉数量,进行递归分解。决策树数量ntree与分叉数量mtry对模型结果影响较大,建立ntree从10到100每10棵递增,mtry从1到10每1个递增的循环计算模型,选取均方差作为误差判断标准,根据均方差最小值来选取最优方案,输出结果。通过指标分析,对其评价等级进行估计,将结果当作模型先验输入。 步骤5阈值设定。根据步骤4,选择最优的决策树与分叉数,并将测试样本中5个评价等级的结果设置为阈值。 步骤6模型结果输出。根据新的阈值设定,将7个待测样本的输出结果与阈值对比,得出最终评价结果。 步骤7主要影响因子判断。将1~8分别设为水质状况指数、枯水期径流量占同期年均径流量的比例、河道连通性、大型底栖动物多样性综合指数、鱼类物种多样性综合指数、特有性物种保持率、水资源开发利用强度、水生生境干扰指数。由于计算过程中指标的浮动对模拟结果的准确性、均方误差以及重要性测度误差均有影响,则对此进行排序,可识别出主要影响因子。 图3 基于随机森林算法的流域生态系统健康评价模型 模型计算结果如图4—7所示。从图4中可以看出,在10至100棵决策树计算过程中,总是在分叉数量为5时误差值达到最小,可认为针对该评价体系与评价指标在分叉数量达到5时,计算结果最优。从图5中可以看出,在决策树数量达到50棵时,误差值达到最小,则认为当决策树为50棵时,计算结果最优。 图4 决策树数量为10到100棵时,分叉数量对误差的影响结果 图5 决策树数量对误差的影响结果 图6 清水河流域(原州区段)生态系统评价结果 通过计算可以得出:据评价标准所对应的结果值,判断[0,1.172)为优秀,[1.172,2.185)为良好,[2.185,3.124)为一般,[3.124,3.844)为较差,[3.844,4.752]为差。据此标准,由图6可以判断:原州城区和彭堡镇的生态系统健康评价结果为差,但彭堡镇的非常接近较差;三营镇、头营镇的生态系统健康评价结果为较差,但头营镇的相对较好;开城镇、中河乡以及寨科乡的为一般,其中开城镇与寨科乡的非常接近良好。 图7(a)—图7(c)分别表示8项因子对模拟准确度、均方误差、重要性测度的影响。综合来看:8项指标中,对评价结果影响程度较大的指标为水资源开发利用程度和枯水期径流量占同期年均径流量的比例,其次为大型地栖动物多样性综合指数和河道连通性,再次为水生生境干扰指数和水质状况指数,影响最小的为鱼类物种多样性综合指数和特有性物种保持率。 为验证评价结果的合理性,用支持向量机模型对清水河流域生态系统进行健康评价,其模型计算过程可参考文献[26]。得出的评价标准为:[0,0.970)为优秀,[0.970,1.908)为良好,[1.908,2.948)为一般,[2.948,4.058)为较差,[4.058,5.066)为差。原州城区的生态系统健康评价结果为差,三营镇、头营镇和彭堡镇的评价结果为较差,开城镇、中河乡以及寨科乡的为一般。与随机森林算法结果的比较见表3。 由表3可以看出:两种模型的评价结果中只有彭堡镇的不同,随机森林算法的结果为差,支持向量机模型的结果为较差。但从随机森林算法计算的评价数值上来看,彭堡镇的计算结果非常接近较差的标准。因此,这两种方法的评价结果基本一致,说明提出的基于随机森林算法的清水河流域生态系统健康评价方法是合理的、可靠的。 通过比较两种机器学习方法对清水河流域生态系统的健康评价情况可知:随机森林算法具有参数选取易、模型精度高、泛化能力强和计算简便等优点;支持向量机模型具有小样本学习能力强、计算步骤简便、可操作性强的优点。随机森林算法相较于支持向量机模型,其计算速度快且不需要对数据进行归一化处理,在训练过程中,能够检测不同特征之间的影响。因此,笔者认为随机森林算法更加适用于处理这类问题。 本文基于随机森林算法构建了清水河流域(原州区段)生态系统健康评价模型,得到如下结论。 1)当随机森林决策树数量为50棵、分叉数量为5时,评价结果误差最小。 2)原州城区与彭堡镇的生态系统健康评价结果为差,三营镇与头营镇的评价结果为较差,开城镇、中河乡以及寨科乡的评价结果为一般。 3)水资源开发利用程度与枯水期径流量占同期年均径流量比例两项指标对评价结果影响最为显著,为此次评价的重要影响因子。 4)将随机森林算法的评价结果与支持向量机模型的评价结果进行对比,二者基本一致。验证了随机森林算法用于流域生态系统健康评价的合理性和有效性。 5)随着流域生态系统健康评价指标体系越来越完善,需要计算与分析的数据也会越来越多,随机森林算法通过数据之间的潜在信息与关联性,能够高效、快捷地判断当前流域生态系统的健康状态。文中提出的方法可为今后流域生态系统健康评价提供一种新的途径,也可为黄河流域生态保护与高质量发展提供参考。
2 清水河流域生态系统健康评价
2.1 模型构建
2.2 模型计算结果



3 结果分析与讨论
4 结语
