基于青藏高原动物资源数据的空间本体构建技术研究
2021-01-28张乃静侯瑞霞
张乃静,蒋 娴,侯瑞霞
(中国林业科学研究院资源信息研究所,北京 100091)
随着林业相关研究的不断发展,林业工作者在实际研究和应用中积累了大量的科学数据,并呈迅速增长趋势。面对海量的林业科学数据,共享数据给相关的科学研究和应用带来了便利,同时由于林业科学数据具有多源异构、复杂度高的特点,在共享中以元数据形式存储,在这些数据内部或与外部其他数据没有建立相互联系,无法表达这些数据的时空特征,同时缺少语义特征,造成数据的孤立与碎片,形成信息 “孤岛”,只能通过全文索引、关键词匹配等传统方法实现数据检索,忽略了林业科学数据之间的语义联系。如何在数据共享中准确、快速的定位发现目标数据成为亟待解决的问题。
为解决以上问题,需要在林业科学数据之间建立语义关联,表达数据之间的语义特征。本体是共享概念模型明确的形式化规范说明,可以发现并建立某一领域内概念及其属性之间的联系,解决知识共享中存在的隐藏知识和“语义鸿沟”等问题[1]。本文以青藏高原动物资源数据为基础,分析其数据语义特征,抽取相关概念、属性及联系,结合青藏高原动物资源的地理分布空间特征,构建基于青藏高原动物资源数据空间本体,以期发现并建立数据之间的语义关系网络,实现高效的数据发现。
1 本体理论概述
本体在不同的领域有着不同的含义,本体源于哲学,含义是“客观事物的系统化描述”。本体最初由Gruber[2]引入到人工智能领域,表示为“概念化的明确的规范说明”;Uschol等[3]作了更进一步的解释,本体有必要通过给定领域内的概念、以及其定义内部的联系去描述和具体化某一世界观,将事物进行概念化,本体是明确的描述和概念化的表达。在实际应用中,本体可以定义为4元组O{C,P,I,A},C是概念(Concepts)或类(Classes)的集合,表示实体(Entities)或对象(Objects);P是属性(Properties)的集合,表示类自身的属性(Attributes)或类之间的联系(Relations);I是概念或类的个体(Individuals)或实例(Instances)的集合;A是公理(Axioms)的集合,用于约束类和属性的联系。本体中概念和属性具有一定的层次结构[4]。本体的描述语言比较丰富,包括函数式语法(Functional-Style Syntax)[5],RDF/XML[6],Turtle[7]和OWL2/XML[8]等,这些本体描述语言提供了概念、属性和约束等基本建模元素,也提供了本体语义推理的支持,为方便阅读和理解本体构建方法,本文采用函数式表达语言构建本体。本体的建模过程非常复杂,需要众多资料和领域专家的支持,在以往本体建模研究中,研究者们开发了一些本体建模工具,其中以开源软件Protégé最为常用,本文也使用该软件进行本体建模,其最新版本为5.5.0。
2 本体建模
2.1 数据基本信息
本文使用的青藏高原动物资源数据来源于国家林业和草原科学数据中心(http://www.forestdata.cn),数据类型为文本半结构化数据,具体数据描述如表1所示。总计包含2 044条青藏高原动物的分类、形态特征、地理分布及采集信息等数据,其中“属分布”、“采集地”和“地理分布”等数据包含地理空间特征信息,这些数据是构建空间本体的基础。
2.2 本体概念的构建
概念是对象集合的抽象体现,本体中概念一般与领域知识库中的专业术语相对应,所以从数据中抽取并构建核心概念集的过程可以理解为从已有数据中提取专业术语,并加以归纳概况的过程。本文将核心概念集分为非地理空间概念集和地理空间概念集,并分别研究不同数据类型核心概念集的构建方法。
研究数据的主题是青藏高原动物资源,结合数据主题和数据内容,提取数据中领域术语词汇进行分层次逐级归类,并抽象为概念,例如表1中“鬣蜥科”、“牛科”和“雉科”都是动物分类学中的“科”,“科”是所有动物“科”的抽象概念,“科”的上级概念有“目”,下级概念有“属”,在数据中均有相关术语与之对应,按此方法可以将这些动物分类学术语词汇纳入到本体概念集中。此外数据中还包含“采集人”、“采集人单位”和“资料来源”等实体,因为这些词汇不是领域内的专业术语,根据需求以最小概念层次单元作为青藏高原动物资源本体的概念元素。构建的部分非地理空间概念集举例如表2所示。

表1 青藏高原动物资源数据举例

表2 非地理空间概念集
通过对青藏高原动物资源数据中涉及地理空间特征的原始数据进行归纳,分析并抽取构建本体所需的地理空间术语,发现这些数据均为非结构化文本数据,因为数据量较大,考虑到工作效率,首先使用NLPIR分词工具进行预处理,根据分词结果和词性标注抽取部分名词作为空间实体对象术语集,然后将这些术语进行归纳分类,具有相同属性的对象抽象为类名,作为概念集;抽取部分名词和动词作为属性集,但分词结果无法达到100%准确率,所以抽取过程需要人工参与。如表3所示,根据地理特征,概念集可分为两类:1)省市等行政区划概念,例如西藏、四川和江达等;2)地理地貌概念,例如高原、湖泊和河流等。
不管是在学术研究中,还是实际应用中,地理空间分类多种多样,比如按地理位置划分东北、华北地区等,按照地理地形分为北方、南方、西北和青藏地区等,按地貌分为高原、平原等。为了保证本体的客观性及可扩展性,本文地理空间实体概念分类体系参考了中国国家标准《GB/T 18521-2001地名分类与类别代码编制规则》[9],最终确定了本体地理空间概念的2个父类:自然地理空间实体和人文地理空间实体,并结合实际需求,确定了抽取概念所涉及的子类及其上下级关系,构建本体空间概念层次模型,结果如表4所示。
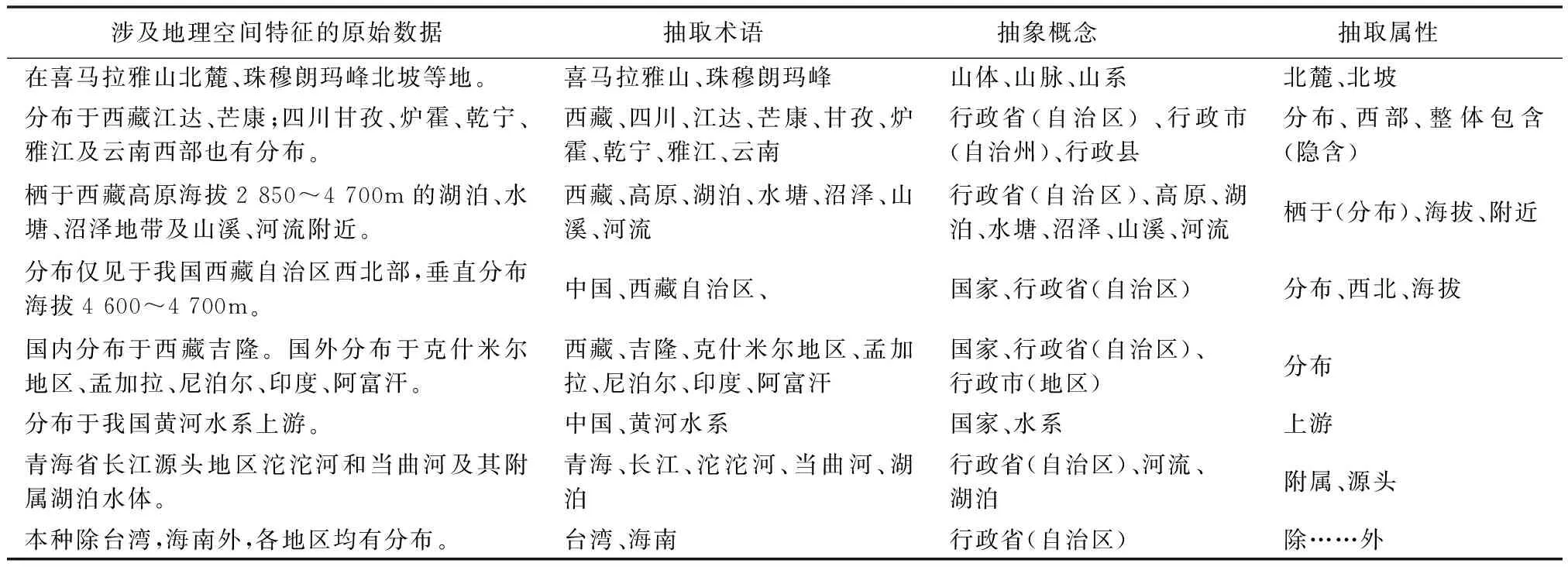
表3 地理空间概念及属性抽取方法
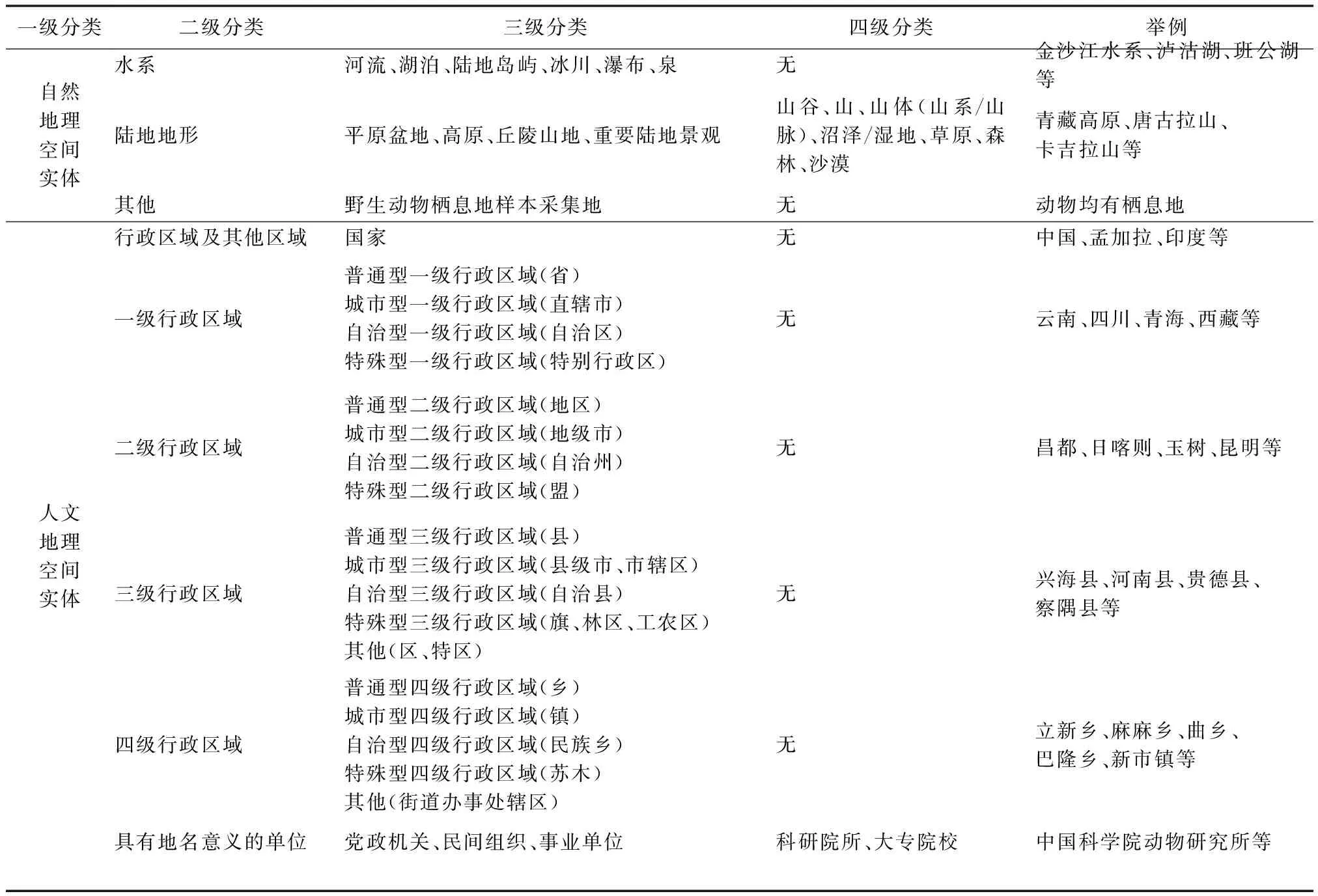
表4 地理空间概念集
2.3 本体属性集的构建
属性描述了概念或类的相互关系,本体中一般包含2种属性:对象属性(Object Property)和数据属性(Data Property)。对象属性用于描述概念等实体之间的联系,例如“异色树莺”属于“树莺属”;数据属性用于描述概念自身特有的属性,例如“异色树莺”有拉丁名“Cettiaflavolivacea(Blyth)”。在定义属性时,常使用定义域(Domain)、值域(Range)、逆属性约束(Inverse Properties)、不相交约束(Disjoint Properties)、基数约束(Cardinality Restrictions)等来约束属性的使用和取值范围,具体参考相关文献[10]。
结合表1和表2,枚举概念的对象属性和数据属性,最终从青藏高原动物资源数据数据获取的非地理空间属性集如表5所示。按OWL本体规则,本体描述的属性一般体现为主谓宾三元组中的谓语动词,所以本体属性一般为动词格式。在获取属性过程中,需要考虑对属性进行约束,例如在原始数据中词条数据中均包含唯一的“编号”,在本体属性中,需要使用“owl:hasKey”来约束“有编号”属性,以保证“编号”在本体的唯一性;上文描述“异色树莺”这种动物属于“树莺属”,相反,“树莺属”包含“异色树莺”这种动物,即“属于”和“包含”可逆性属性;“树莺属”又属于“鹟科”,所以“异色树莺”也属于“鹟科”,即“属于”为传递性属性;“树莺属”只能属于一个“鹟科”,而不能同时属于一个以上的科,即“属于”需要使用最大基数约束。对象属性的定义域和值域一般为概念或实例,数据属性的定义域一般为概念或实例,而值域为数据,本体数据类型使用XML的XSD数据类型表示,同时可以使用相应的XSD约束规则进行约束。
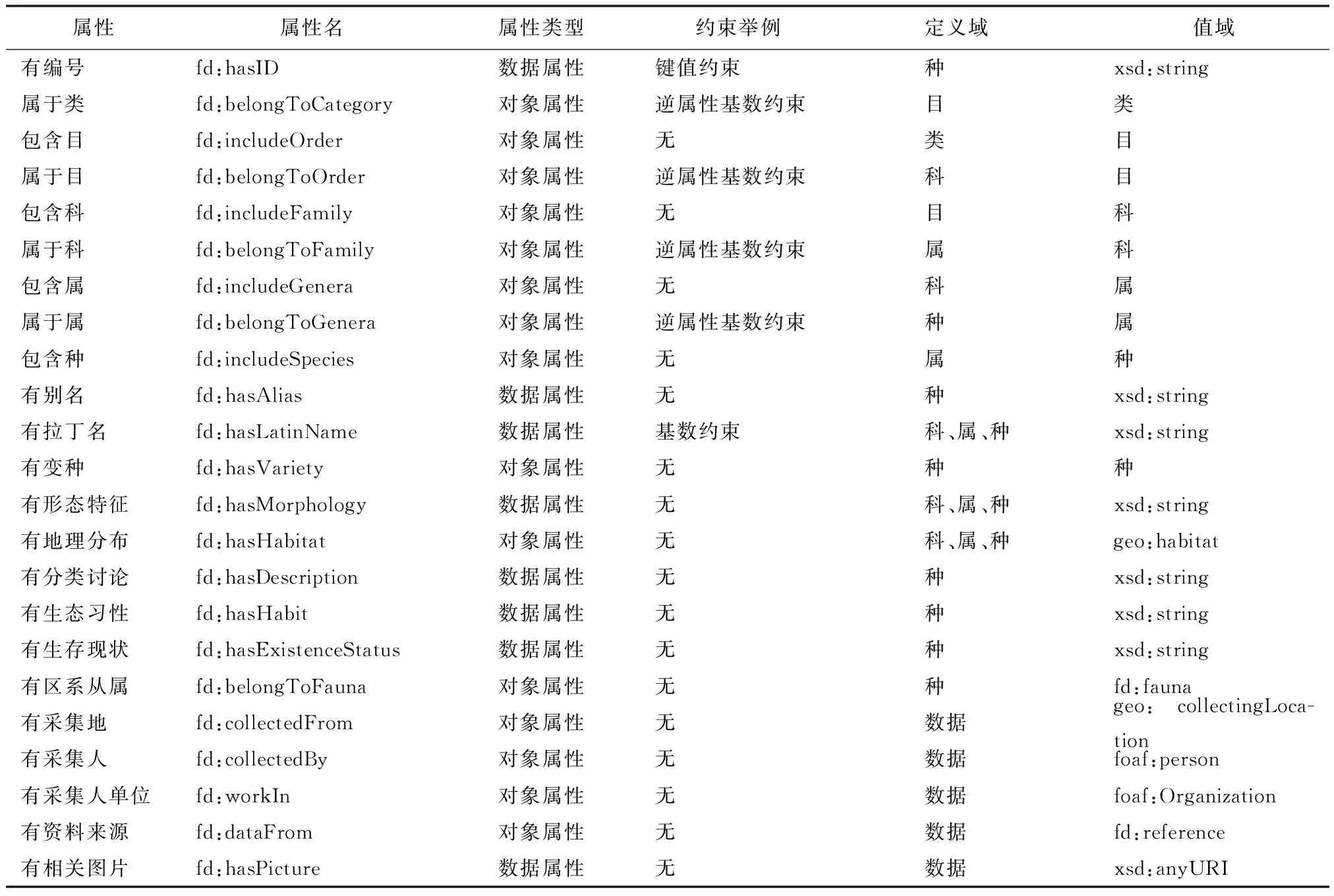
表5 非地理空间属性集
在构建地理空间概念集的同时,获取了部分具有地理空间特征术语词汇,例如“北坡”、“源头”和“上游”等,通过将这些词汇进行归类分析,确定这些术语词汇作用对象的空间关系,并进行分层次总结出研究相关的6类地理空间关系:拓扑关系、从属关系、方位关系、举例关系、位置关系和地理数据属性,具体属性如表6所示。
空间属性与普通的语义属性表达不同,例如“平原”和“高原”在定义概念时可以添加“owl:disjointWith”不相交约束,说明一个实例不能既是“平原”,又是“高原”,表达两个概念在语义上不相交;在创建空间属性时,也可以将“平原”和“高原”之间的属性定义为“geo:disjoint”不相交,说明某一“平原”和某一“高原”在地理空间上不相交,没有交集。

表6 地理空间属性集
2.4 本体的构建及实例化
在构建本体所有资源时,必须添加国际化资源标识符(IRI),保证本体内每个元素的唯一性,IRI一般由WWW的统一资源定位标志(URL)表示。本文涉及到的自定义IRI如下:http://www.forestdata.cn/animaldata缩写为fd;http://www.forestdata.cn/geodata缩写为geo。其他IRI为OWL本体或其他复用本体默认值,例如“owl”和“foaf”等,本文不作详细解释。
本体中“owl:Thing”表示万事万物,所有的概念和关系都是“owl:Thing”的子类。由上文构建的核心概念集确定了继承“owl:Thing”的5个子类:“fd:Animal”,“fd:AnimalTaxonomy”,“fd:Reference”,“foaf:Person”,“fd:Data”和“geo:GeographicEntity”,为了符合本体方便共享复用原则,本体中概念集和属性集采用了英文命名,然后采用“rdfs:label”属性添加中文标签进行标注。本体的复用可以减少部分工作量,研究中复用了FOAF本体[11],用来表达青藏高原动物资源数据采集人(foaf:Person)及其工作单位(foaf:Organization),复用了QUDT本体[12],用来描述某些数值型数据属性的单位。
按表2和表4概念集上下级层次结构构建青藏高原动物资源空间本体框架,添加本体子类属性(owl:subClassOf)将子类和父类建立语义联系,然后根据实际需求,对本体中的概念进行实例化。青藏高原动物资源空间本体的实例化以原始数据中每一动物种为基础,逐一进行实例化,同时按表5和表6属性集添加相关属性,建立实例之间的联系。为了保证构建的本体语义与原始词条数据(数据共享网址:http://www.forestdata.cn/search-data.html?id=1004)相对应,以便更好地共享数据,在“数据”下创建了“青藏高原动物资源数据”子类,然后以每种动物的“编号”(ID)+字符“数据”创建实例,使用“fd:isDataOf”属性使“种”与“数据”建立联系,例如“Animal092数据”是描述“中国林蛙”的数据。为保证本体的客观性,其中自然地理空间实体中“河流”、“湖泊”和“山峰”分布参考水利标准《SL 249-2012中国河流代码》[13]、《SL 261-2017 湖泊代码》[14]和国家标准《GB/T 22483-2008中国山脉山峰名称代码》[15],人文地理空间中行政区划参考国家统计局[16]和民政部[17]相关数据。进行实例化后本体结构如图1所示。
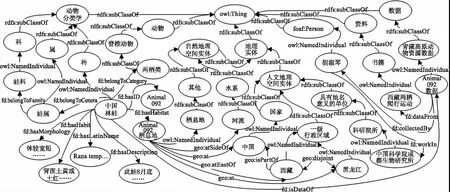
图1 青藏高原动物资源空间本体片段结构图
利用W3C推荐的OWL2本体语言对青藏高原动物资源空间本体进行形式化、序列化编码,将构建的本体处理机器可读可用的表达形式。为了便于后期阅读和维护构建的本体,构建的本体采用了OWL2函数语法表达方式。
3 本体的评价
本体需要在构建和应用过程中不断迭代完善和进化,所以本体的评价十分重要。本体评价包含本体的正确性、一致性、可扩展性和有效性等方面的评价。青藏高原动物资源空间本体是基于国家林业和草原科学数据中心共享数据构建的,抽取的概念集和属性集参考了国家及行业相关标准,保证了本体语义表达的正确性;属性约束的正确与否决定了本体的语义一致性,本文本体属性集构建章节中叙述了构建本体的属性约束,根据多年本体建模经验,结合领域专家指导,保证了本体的一致性;青藏高原动物资源空间本体中“动物分类学”和“地理实体”的子类概念及其实例已经达到最小粒度,具有较大的可扩展性和复用性,但仍然有像“资料”、“书籍”等领域外的概念无法专业的确定本体结构,且未找到可复用的本体,这些概念仅在该本体或作者其他研究使用,可扩展性较小;研究并构建该本体的目的是建立原有数据中概念或元素之间的语义联系,与传统关键词匹配检索方式相比,语义检索在数据共享中可以实现更高效的数据发现,例如利用本体的语义支持,给定某一省份或某一河流,即可准确地检索出哪些动物分布在该地区,这些动物的其他属性或关联信息也都可清晰地展示出来,体现出本体具有一定的有效性,但本体有效性的量化一般采用检索的查全率和查准率表示,由于语义检索系统正在开发过程中,具体有效性的数据无法给出。
4 结论和展望
基于国家林业和草原科学数据中心,用户以关键词检索数据时,常会出现关键词与检索结果不匹配的情况,无法提供高效的检索服务。针对数据共享中信息检索不全面的问题,本文以青藏高原动物资源数据为基础,对领域术语词汇进行归纳分类,抽取概念集和属性集,并分析了地理空间相关数据的概念和属性特征,阐述了本体的构建流程,最终构建了青藏高原动物资源空间本体,为数据共享提供一定的语义支持。随着林业和草原科学数据的逐年增加,涉及到的领域本体越来越复杂,目前大部分本体一般采用手工方式构建,距离全面实现林业和草原科学数据语义共享还需要一段时间,所以自动或半自动本体构建技术是下一步的重点研究内容。此外,国内外本体研究较多,如何实现领域内本体的共享与复用也是有意义的一项工作。
