洪水预报智能模型在中国半干旱半湿润区的应用对比
2021-01-27牛杰帆晁丽君
张 珂,牛杰帆,李 曦,晁丽君
(1.河海大学水文水资源与水利工程科学国家重点实验室,江苏 南京 210098;2.河海大学水文水资源学院,江苏 南京 210098; 3.长江保护与绿色发展研究院,江苏 南京 210098;4.中国气象局-河海大学水文气象研究联合实验室,江苏 南京 210098)
近年来,受气候变化和人类活动的影响,极端天气频发,山洪、泥石流、城市内涝等自然灾害不断发生。尤其位于山区的中小流域,由于洪水突发性强、汇流快、预见期短,灾害发生迅猛,给防汛工作带来了严峻考验[1-3]。洪水预报主要依赖模型模拟,目前洪水预报模型可分为两大类:基于物理过程的传统水文模型[4-6]和数据驱动的人工智能模型[7-8]。传统水文模型具有明确和相对固定的物理关系基础[9],在实际应用过程中一般对下垫面变化导致的物理关系变化考虑不足。智能模型在模拟中依靠人工智能技术,通过不断获取的数据进行自我学习,不需要流域水文的先验知识,能够从多角度捕捉水文数据中的复杂非线性关系,具有强大的仿真能力,在水文预报中应用越来越广泛[10-15]。
国内外学者在利用人工智能模型进行水文预报方面做过许多研究。霍文博等[16]使用支持向量机模型与新安江模型进行实时洪水预报比较研究,发现支持向量机模型在短预见期实时预报中更具优势,在率定期和测试期中均具有较高精度;徐源浩等[17]使用长短时记忆神经网络建立不同预见期的暴雨洪水模型,对黄河中游洪水过程进行模拟,研究发现6 h预见期内模型预报精度较高;Yaseen等[18]提出了一种改进的极限学习机模型应用于热带地区的流量预测中,发现改进后的模型各项评价指标得到了显著提高,具有广泛的应用前景;Tikhamarine等[19]将灰狼优化算法与智能模型结合建立了更加高效的水文预报系统,在月径流预测中取得了较好的效果;Zhou等[20]提出将基于递归的自适应模糊神经网络模型运用于水文预测,相比于传统自适应神经网络,改进后的模型能够适应非平稳的降雨径流过程,具有更高的模型效率与可靠性。
目前国内外学者针对智能模型的水文预报应用研究较多,并取得了很好的成果,但研究主要集中于单一智能模型的改进和多种智能模型的集成优化,对于多种智能模型实时洪水预测的对比研究较少。本文使用决策树、多层感知器、随机森林和支持向量机4种智能模型对陕西省的3个半干旱半湿润典型流域进行逐时洪水预报,比较4种模型在半干旱和半湿润区的预报结果,探究人工智能模型在洪水预报中的适用性。
1 研究区概况
选取陕西省的志丹流域、板桥流域、马渡王流域3个流域作为研究区域(图1),其中志丹流域为半干旱流域,板桥流域和马渡王流域为半湿润流域。志丹流域集水面积为777 km2,区域气候隶属于中温带半干旱气候,多年平均降水量为510 mm;受地形地貌影响,志丹流域河网密度较大,洪水涨落快,历时较短。马渡王流域面积为1 604 km2,属暖温带半湿润大陆性季风气候,多年平均降水量 631 mm,流域山区地势陡峭,河谷纵横,丘陵区沟谷较为发育,暴雨中心多集中于流域的中上游地区。板桥流域面积502 km2,气候为北亚热带湿润、半湿润气候,多年平均降水量约为729 mm;板桥流域地形西北高东南低,夏季常产生局部暴雨;受地势影响,洪水汇流迅速,多形成峰尖型瘦的洪水。
选取研究区2000—2010年汛期12场洪水数据进行模拟,其中2000—2007年8场洪水用于模型训练,2008—2010年4场洪水用于模型测试,计算时间步长为1 h。
2 研究方法
2.1 模型方法
决策树(decision tree,DT)是一种非参数监督学习方法,从测量特征与训练数据推断决策规则从而进行目标预测。决策树自顶向下逐步生成,在生成模型结构时不断建立分枝规则。目前常用的规则主要有两种:基于信息增益的方法和基于最小基尼系数的方法。本文所采用的决策树为分类回归树,分类回归树以基尼系数作为分枝规则,已在统计领域和数据挖掘技术中得到普遍应用。
随机森林(random forest,RF)是一种基于决策树的集成算法,效率较高,计算成本低,具有一定优势。随机森林的核心思想是构建多个未剪枝的DT集合。在模型训练中,随机森林在基于学习器构建Bagging集成的基础上,引入了随机属性选择,通过从结点的属性集合中选择属性子集和最优特征,进一步增强了模型的泛化能力。
支持向量机(support vector machine,SVM)的主要特点是对原始数据集空间的超平面进行优化,找到具有最大间隔的划分超平面。对于非线性样本,SVM通过核函数进行非线性变换,将原问题映射到高维特征空间转化为线性问题进行求解。
多层感知器(multilayer perceptron,MLP)是一种前馈人工神经网络模型,解决了单层感知网络对于非线性问题的弊端。MLP通过调节神经元间的连接权重和阈值,对神经网络进行训练。每个神经元计算n个输入信号的加权平均后,应用非线性激活产生输出信号。
2.2 评价指标
为了对比模型在不同流域洪水预报的适应性,本文采用相关系数(r)、纳什效率系数(NSE)、均方根误差(RMSE)、平均绝对误差(MAE)、相对误差(RE)几种指标对模型模拟结果进行评价。其中,NSE反映了模型模拟的整体效果;RMSE和MAE两个指标侧重于评价系列总体的误差情况,RMSE用来衡量观测值与真值之间的偏差,MAE表达绝对误差的均值程度,两者都对序列中极大或极小误差反应敏感;RE反映了误差的相对大小,适应于非平稳序列的模拟比较;r是回归模式中反映两个变量相关程度的统计指标,可对模型拟合优度进行综合评价。
2.3 洪水预报方案
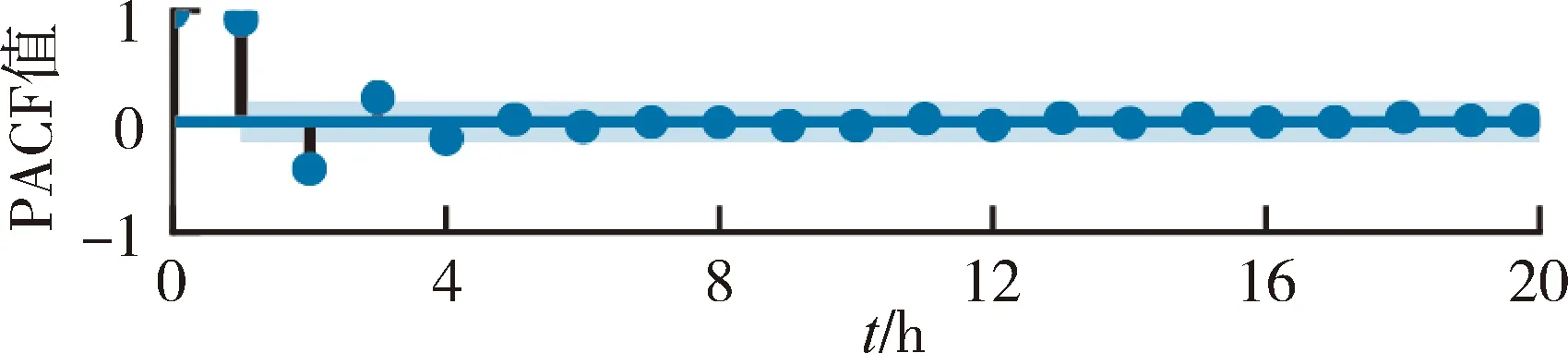
本文根据数据统计相关特性确定模型预报因子,通过流域偏自相关函数PACF构建模型的输入结构。偏自相关函数消除了序列较短滞后条件产生的相关性影响,提供时间序列上两个独立点在不同滞时的相关性信息。图2为3个流域的流量偏自相关曲线,在95%置信区间下选取流量输入,与实时雨量数据共同构成模型的预报因子。模型结构如下:
Qt=f(Qt-Δt,Qt-2Δt,…,Qt-nΔt,R1t,R2t,…,Rmt)
(1)
式中:Q为水文站点流量;R为雨量站降水量;t为当前时刻;Δt为计算时段(本文取1 h);n为流量滞后时段数;m为流域内的雨量站个数。板桥流域、马渡王流域、志丹流域对应的流量最大滞时分别为 3 h、4 h 和3 h。
(a) 板桥流域
利用训练期洪水预报因子分别训练DT模型、MLP模型、RF模型和SVM模型,使用训练好的模型对3个典型流域进行洪水滚动预报,并对模型模拟精度与适应性进行评价,主要步骤如下:
a. 划分数据训练期与测试期。采用2000—2010年汛期场次洪水数据,其中,2000—2007年数据用于模型训练,2008—2010年数据用于模型测试。
b. 数据的归一化处理。对训练集和测试集数据进行标准化处理,消除数据的量级差异对模型模拟的影响,经过归一化处理的数据位于0~1之间:
(2)
式中:xnorm为归一化后的数据;x为原始数据;xmin、xmax为样本每一维的最小值和最大值。
c. 模型训练。选用基于高斯混合模型的TPE算法[21]进行模型参数寻优。使用训练期样本数据进行模型训练,以RMSE作为目标函数,通过交叉验证,计算最小误差参数作为模型的最优参数。
d. 测试期洪水模拟与洪水滚动预报。利用训练后的模型对测试样本集进行预测。将当前时刻预测流量值作为下一时刻的前期流量输入,以此类推,实现流域洪水的滚动预报。
e. 模型评价。使用相关系数、纳什效率系数、均方根误差、平均绝对误差、相对误差等指标对模型结果进行评价。
3 模拟预报结果与分析
3.1 模型模拟结果对比及误差分析
根据模型的训练结果对流域进行洪水模拟,整体来看,板桥流域和马渡王流域4种模型均取得了较好的模拟结果,志丹流域的模拟结果相对较差。图3和表1分别为模型测试期部分场次洪水模拟结果与误差统计。可以看出,板桥流域和马渡王流域洪水历时较长,洪水过程皆呈现陡涨缓落的态势。4种模型在以上2个流域模拟过程线趋势理想,平均洪峰相对误差为5%,平均洪量相对误差为2%,平均峰现时刻误差为2 h;志丹流域洪水过程呈现涨落快、历时短的特点,模型在此流域模拟洪水的起涨点与实测洪水起涨点吻合较差,DT模型、SVM模型模拟洪峰偏小,MLP模型、RF模型洪峰则偏大,其中SVM在4种模型中模拟结果最好,平均洪峰相对误差为7%,平均洪量相对误差为12%,峰现时刻误差维持在许可误差3 h的范围内。志丹流域模拟整体精度较低,这是由于志丹流域气候干旱,产流的时空分布较复杂,同时洪水过程历时较短,模型很难从洪水数据中学习到准确的水文信息,洪水模拟难度较大。

(a) 板桥流域2009082821号洪水
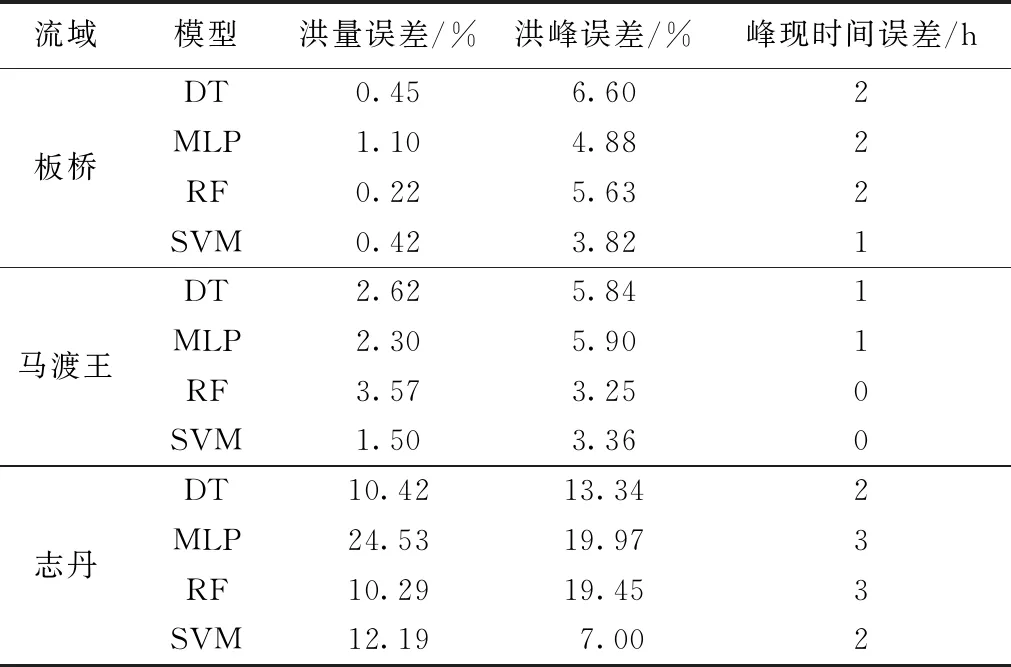
表1 测试期流域特征值模拟误差
为了更加深入研究在半干旱与半湿润区智能模型洪水模拟的适用性,对模型测试期的统计相关性水平与误差分布进行评价。由模型测试期预测流量与实测流量散点图(图4)可以看出,板桥流域和马渡王流域4种模型的拟合程度较好,志丹流域拟合程度较低。板桥流域和马渡王流域模拟确定性系数均超过0.96,其中SVM模型模拟精度最优,确定性系数分别达到1.0和0.98,最接近1∶1线,流量模拟效果最好;志丹流域流量拟合相对较差。模型由优到劣分别为SVM、RF、MLP、DT,其中,SVM模型模拟精度最高,确定性系数达到0.7,DT模型模拟精度最差,确定性系数仅为0.48。
图5为流域测试期模拟流量的相对误差,半湿润地区在模拟相对误差水平上小于半干旱区。在半湿润地区,模型模拟相对误差由小到大分别为SVM、RF、DT、MLP,其中SVM模型整体相对误差最小,平均相对误差为2.98%。由于SVM模型根据样本偏离值进行惩罚函数的调整,没有考虑样本数量的不平衡性,模型经过训练所贮存的信息更多地反映了样本数量较大的中小流量变化规律,因此,SVM模型对中小流量预报精度较高,在高流量时存在一定程度的低估。RF、DT、MLP模型在高流量时存在高估,其中RF、DT模型相对误差水平相似(平均相对误差分别为5.79%和7.50%),MLP模型相对误差较大,平均相对误差值为22.54%;在半干旱区,模型模拟误差较大,精度由高到低为DT、SVM、RF、MLP。4种模型流量模拟都存在高估,这是由于干旱区流量历时短,洪水涨落迅速,模型对于洪水涨落点的捕捉较难,前期的高流量点极易影响后期模拟。
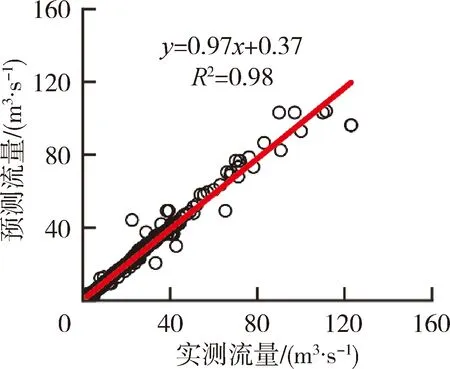
(a) 板桥流域(DT模型)
3.2 不同预见期下的模型稳定性分析
为了深入分析智能模型在洪水预报中的适应性,统计不同预见期(1~4 h)下的模型模拟结果(表2和表3),对智能模型进行稳定性评估。
由表2和表3可见,当预见期为1 h时,在板桥流域,模型训练期和测试期的模拟结果都较好(平均NSE为0.98)。训练期模型模拟精度由大到小分别为DT、RF、MLP、SVM,其中DT模型RMSE为1.02,模拟结果最好,SVM模型误差相对较大;测试期模型模拟精度由大到小分别为SVM、DT、RF、MLP,其中SVM模型在测试期模拟精度最高,MAE(0.28)和RMSE(1.08)均小于其他模型,DT模型和RF模型拟合程度和误差水平相似,MLP则在4种模型中误差最大。在马渡王流域,模型在训练期和测试期的模拟结果较好(NSE分别为0.99和0.97)。训练期DT模型模拟精度最高,MAE(0.02)和RMSE(0.32)均小于其他模型;测试期SVM模型误差最小,在洪水模拟中有较强的适应性。在志丹流域,模型模拟结果整体较差,训练期的模拟结果优于测试期(NSE分别为0.84和0.51)。DT模型和SVM模型分别在模型训练期和测试期取得了最大的精度。DT、RF、MLP模型在训练期和测试期模拟结果差距较大,存在一定的过拟合问题,SVM模型在训练期和测试期的模型模拟精度相近,具有一定的稳定性。

(a) 板桥流域

表2 训练期不同模型不同预见期模拟结果

表3 测试期不同模型不同预见期模拟结果
综合3个流域的预报结果,半湿润区流域模拟结果优于半干旱区。训练期DT模型模拟精度最高,但测试期模型模拟效果较差,这表明DT模型在实际运用中存在过拟合、泛化能力差等问题。SVM模型在训练期的模拟结果相对较好,测试期模拟精度优于其他模型,泛化能力强,在洪水预报应用中有一定适应性。
可以看出,4种模型在短预见期下,均能保持较好的精度。随着预见期的延长,模型的误差累积增加。随着预见期的延长,SVM模型在不同气候区模拟结果均都能够保持一定的稳定性;DT模型和RF模型模拟精度有所下降,但整体能满足模型精度的要求,其中RF模型下降幅度较DT模型小;MLP模型在半湿润区域较短预见期下能够保持较好的模拟精度,随着模型预见期的增长,模型性能出现骤降,模拟结果不稳定。
(a) 板桥流域
泰勒图用于显示不同模型模拟预测的河流流量在相关性、标准差和RMSE方面与实测值的接近程度,可对模型性能进行综合评价。Moriasi等[22]的研究表明水文模型的RMSE小于数据标准差的50%,模型应用良好。图6为在测试阶段流域1~4 h预见期模拟结果的泰勒图。在1~4 h的预见期内,DT、RF、SVM模型模拟精度略有下降,但仍保持了较稳定的模拟性能。MLP模型在1~3 h预见期内能够保持一定稳定性,在4 h预见期模型性能骤降。
对于板桥流域和马渡王流域,不同预见期模型模拟结果都较接近实测值,模型性能较好(除MLP_4 h外),其中SVM模拟结果最接近实测值,模型结果最稳定。DT模型随着预见期延长精度逐渐下降,在4种模型中稳定性最差(除MLP_4 h外);志丹流域模型点在泰勒图上较为分散,仅有SVM模型满足比值小于0.5的界定要求,DT模型模拟结果远离实测值,误差较大。随着预见期的延长,4种模型精度都有所下降,但不同预见期下模型精度的差异性小于不同模型选择下的精度差异。
综合3个流域不同预见期模型模拟结果,SVM模型在半干旱和半湿润地区模拟都能得到较好的精度。随着预见期的延长,模型精度有所下降,但模型整体稳定,在小流域实时洪水预报中具有明显优势。DT模型与RF模型模拟结果相似,能够取得较好的精度,随着预见期延长,模型精度下降,RF模型下降程度小于DT模型。这是由于RF模型是集成模型,在模型训练中能够更加全面地捕捉水文数据的复杂信息,较DT模型更具适应性。MLP模型在短预见期的洪水模拟中,能够保持较好的精度,随着预见期的延长,模型的稳定性骤变,模拟结果差。由于模型对数据精度要求大,对数据误差敏感,在长预见期水文预报中需要及时对MLP模型模拟数据进行修正,从而保持模型的稳定运行。
4 结 论
a. 4种模型在半干旱与半湿润区模拟结果差异较大,半湿润区洪水模拟精度高于半干旱区。在半湿润区,DT、RF、MLP、SVM模型模拟都可以得到较好的结果。在半干旱区,SVM模型的模拟精度较高,在洪水模拟中具有较强的适应性,其他模型模拟精度较差。
b. 随着预见期延长,SVM模型模拟精度略微下降,但模型整体稳定,在小流域实时洪水预报中具有明显优势;DT模型与RF模型模拟精度缓慢下降,RF模型模拟精度下降程度略小于DT模型。MLP模型模拟精度随预见期延长而骤减,模型稳定性差。由于模型对误差敏感,在长预见期滚动预报中需要进行实时误差校正。
c. 智能模型作为一种数据驱动方法可在洪水预报中发挥作用。在未来研究中,将洪水实时校正和模型集成技术与智能模型相结合,同时,针对半干旱地区产汇流条件复杂、洪水预报难的问题,可将下垫面信息引入智能模型输入,进一步扩大模型的示范应用研究。
