基于深度学习的非对齐人脸验证方法
2021-01-27陈易萍樊中奎
朱 梅,陈易萍,姚 毅,樊中奎,李 渤
(1.江西理工大学a.软件工程学院,江西 南昌 330013;b.应用科学学院,江西 赣州 341000;2.南昌市农业科学院,江西 南昌 330200)
近年来,卷积神经网络(CNN)在计算机视觉领域取得了巨大的成功。众多的视觉任务:图像分类、物体检测、人脸验证及识别都受益于CNN模型的分类能力,性能得到了很大的提高。当前使用基于CNN的模型的人脸识别在LFW数据集上的识别精度达到99%[1],并在商业上得到了应用。
目前,多个CNN方法被用于人脸验证,Taigman[2]使用CNN模型提取人脸的特征向量,然后将这些特征向量输入到贝叶斯分类法及高斯分类法进行人脸验证,但这种方法在样本分布不均匀的情况下难以正确的分类。Y.Sun[3]采用人脸对齐及对人脸进行多分片的方法进行人脸特征的提取,提高了人脸验证的鲁棒性,但耗时较长。F.Schroff[4]提出了使用triplet loss来验证两个样本是否为同一实体克服了基于多分类网络只用于分类而不能用于验证的瓶颈,但是对于训练集中不存在的新实体无法进行验证并且需要手工确定分类的阈值。Chen.Jun Cheng[5]使用多任务的深度卷积网络模型进行识别和验证,多任务学习为提高人脸表示的泛化能力提供了一种有效的方法,然而基于多任务的神经网络的收敛性仍然是一个挑战,识别和验证的选择需要手工确定的,并且效果严重依赖训练集。
以往的方法取得了重要的发展,但仍有许多不足之处有待改进。首先,一些方法在CNN测试前需要进行人脸对齐或仿射变换等预处理,这会消耗大量的计算时间。其次,使用复杂的CNN模型和多分片进行人脸验证,生成了大量的中间数据,需要较大的存储空间和计算时间[1,5]。第三,从CNN中提取特征向量,然后在其他平台上进行人脸验证的不能做到从输入端到输出端不间断连续的过程处理,影响验证效率及操作体验。针对目前研究的不足,本文提出了一种基于深度学的非对齐人脸验证框架(如图1所示)。在框架中设计具有较少层数和参数的卷积神经网络,具有良好的人脸验证的准确度同时减少了计算量提高了处理速度;在验证过程中抽象出SIFT描述符进行人脸验证可以有效减小姿态变化的影响,不需要人脸对齐预处理情况下进行验证,让人脸验证过程能够进行端到端处理,提高了验证过程的完整性;采用级联法提高了人脸识别的精度,减少了人脸识别的运行时间。CNN模型在CASIA-Web Face数据集上进行训练,并在著名的LFW和You Tube(YTF)数据集上进行评估,取得了优异的性能。论文主要贡献如下:
(1)设计出一个人脸验证框架。框架分为三个阶段:在第一个阶段,CNN得到了充分的训练得到模型;第二阶段,在CNN中加入triplet loss对第一阶段的模型进行微调适应人脸验证;第三阶段采用级联法进行人脸验证。框架不仅提高了人脸识别的精度,而且减少了人脸识别的运行时间。
(2)在卷积网络的池化过程中提取SIFT描述符,用于人脸验证。由于SIFT描述符具有良好的尺度不变性和旋转不变性,可以在非人脸对齐的情况下获得较好的人脸验证效果。
(3)设计了两个CNN被来适应不同的设备。CNN1层数少、参数少,能较好地满足时间成本和验证精度的要求,适用于智能手机平台。CNN2层数多,参数多,性能优良,适合在服务器上使用。
2 相关工作
人脸验证是计算机视觉领域研究的热点之一。通过许多研究人员的努力,近年来精度得到了显著提高。人脸验证研究主要集中在以下方面。
特征提取:识别人脸特征表示的提取是人脸验证的第一步。它大致可分为两类:手工生成的特性,以及从数据中学习的特性。在第一类中,Ahonen[6]等人在中提出使用局部二值模式(LBP)来表示人脸。Chen[7]等人在中利用高维多尺度LBP特征提取人脸标记周围的特征,对人脸进行了验证,取得了良好的效果。Gabor小波具有良好的方向选择和尺度选择特性,Xie[8]和Zhang[9]使用该方法对人脸图像的多尺度、多方向信息进行编码。在第二类中,Patel[10]和Chen[11-12]采用基于字典的方法,通过从样本中学习对姿态和光照变化具有鲁棒性的代表性特征来进行人脸识别和验证。采用Fisher向量[13](FV)编码生成完备的高维特征表示。Lu等[14]提出了一种字典学习框架来生成高维特征向量。上述方法需要高维特征向量,难以在大型数据集中进行训练和应用。然而,随着深度学习的发展,利用深度卷积神经网络(DCNN)可以从大数据集中学习分类特征。Taigman等[2]从大规模人脸数据集中学习生成人脸特征的深度网络模型,取得了比传统人脸验证方法更好的性能。Sun等[1]在LFW数据集上实现了出色的人脸验证性能。Schroff等[4]将深度结构从对象识别应用到人脸验证,并对其进行三重损失训练,取得了较好的效果。这些工作从本质上证明了DCNN模型对特征学习的有效性。
度量学习:从数据中学习相似性度量是提高人脸验证系统性能的另一个关键部分。在过去的十年中,人们提出了许多度量学习算法,其中一些已经成功地应用于人脸验证。这些方法的共同目标是学习一种良好的距离度量,使正样本对之间的距离尽可能地减小,负样本之间对之间的距离尽可能地增大。例如,Sun等[1]提出了大边际最近邻(LMNN)度量,该度量在所有三组标记训练数据之间强制执行大边际约束。Taigman等[15]使用信息论度量学习(ITML)方法学习马氏距离。Chen等[16]中提出了一种用于人脸验证的联合贝叶斯方法,该方法对一对人脸图像的联合分布而不是它们之间的差异进行建模,用类内概率与类间概率之比作为相似性度量。Hu等[17]研究了深度神经网络框架下的判别度量。Huang等[18]研究了一组保留底层流形结构的标记图像上的投影度量。
3 方法介绍
我们提出的方法设计了两个参数不同的CNN架构。为了使CNN架构适合人脸验证,在CNN架构使用三元组样本,用于对CNN训练得到的模型进行微调。在测试阶段,从池化层中提取SIFT描述符,进行非对齐的级联人脸验证,取得良好的效果。图1给出了方法的流程图。方法详细实现在下面介绍。
3.1 深度卷积神经网络
本文针对不同的应用平台提供了两种CNN架构。CNN1的层数和参数比CNN2少(如表1所示),因此CNN1比CNN2需要更少的训练和测试时间。CNN1包含5个卷积层和4个池化层,FC5a和Conv5b具有相同输入层为池化层4;FC5b1为Conv5b的顶层;FC6为FC5与FC5b1的和,网络输入图像的分辨率是224*224,输出为一个160维向量,CNN1的数据量为22M。CNN2包含10个卷积层和5个池化层,输出为4096维向量,共有2.239亿个参数。在CNN1和CNN2中卷积核由高斯函数初始化,使用ReLU作为激活函数,使用Dropout避免过拟合,使用Softmax-loss进行多分类。
为了使CNN适合人脸验证,使用triplet loss对CNN模型微调(如图1所示),微调仅改变最后一个全连接层的参数,使正样本之间的距离变小,正负之间的距离变大(如图2所示)。在微调阶段,CNN需要输入的三元组包含三个样本,一幅为锚点,一幅为正样本,另一幅为负样本利用triplet loss通过训练求出最小的区间,当两幅图像之间的距离大于最小区间则认为是不同的人,否则图像描述的是同一个人。
从表1和表2可以看出:CNN1(如表1所示)网络层数和参数较少,CNN2(如表2所示)网络层数和参数较多。与CNN2相比,CNN1在训练和测试中消耗的时间更少,适合在手机等小型设备上运行。

表1 CNN1架构
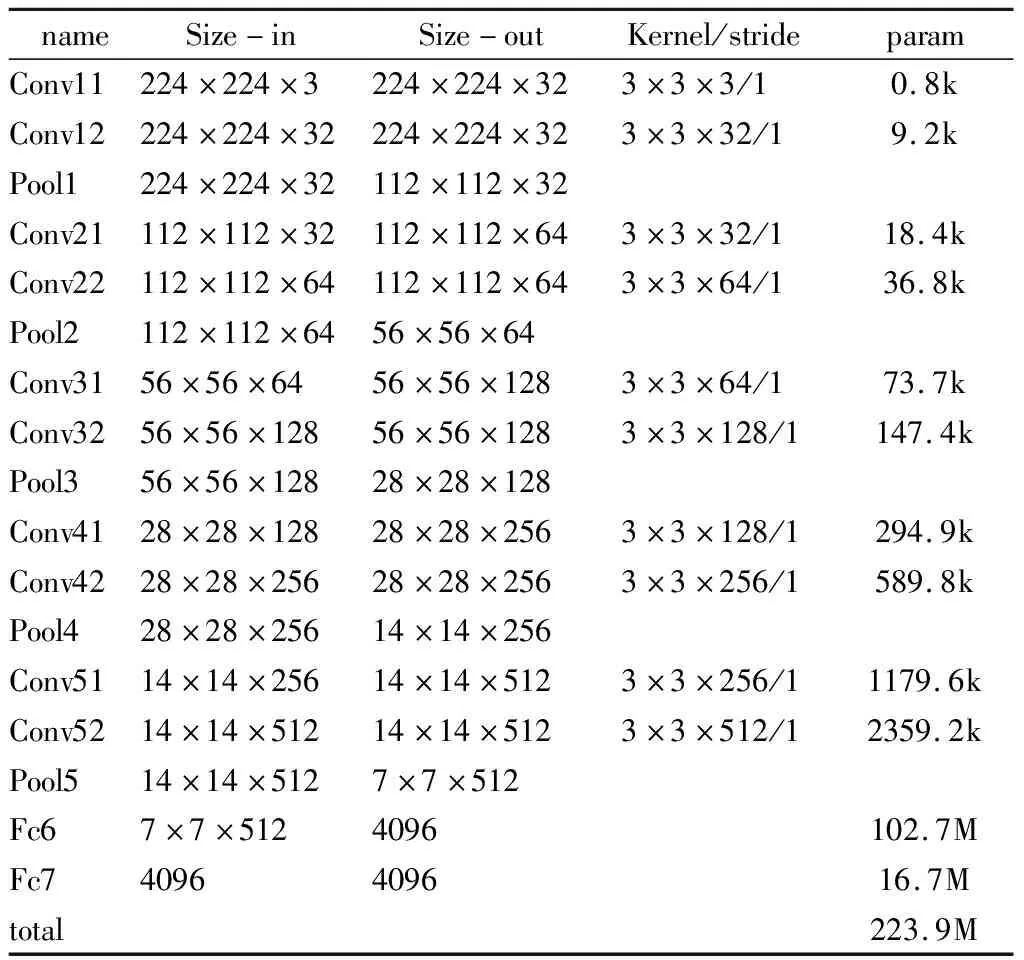
表2 CNN2架构
3.2 使用triplet loss进行模型训练
根据常识同一个人图像有更多的相似性,所以同一个人的人脸图像特征之间的距离应被集中到一个很小的范围之内。triplet loss试图在每对人脸之间建立一个从一个人脸图片到其它人脸图片的间距(如图2所示)。
两张人脸图片是否为相同的人需要通过验证的方式来确定的。但是目前的深度学习网络模型主要应用在图像的分类,不适合人脸图片的验证,因此我们需要设计一种适合人脸验证的深度学习网络。本文在CNN的末端添加triplet loss层使之适合人脸图片的验证(如图3所示)。
经过使用triplet loss进行模型微调训练,得到了一个低维向量,对人脸识别具有较强的识别力。考虑一个三元组{a,p,n},其中a(anchor)和p(positive)来自同一个实体,而n(negative)属于不同的实体。我们的目标是样本特征向量的W映射应满足(1)约束:
(Wa)T·(Wp)>(Wa)T·(Wn)
(1)
在我们的方法中,在CNN1中{a,p,n}∈R160和CNN2{a,p,n}∈R4096,它们通过W被归一化为单位长度。因此,Wa、Wp、Wn是a、p、n在投影W下的相似性特征向量。(1)中的约束条件要求在低维空间中,锚点与正样本的相似性应大于锚点与负样本的相似性。因此,映射矩阵W应能够将锚点与正样本距离缩小,锚点与负样本距离增大,经过验证选择Wa、Wp、Wn的维数为d=128。
根据一个三元组标记的样本的特征向量,我们解决以下优化问题:
(2)
其中T是三元组集,α是根据验证集来选择的边距参数。在实际应用中,采用增大区分度的随机梯度下降法(SGD)解决了上述问题,解决(2)的更新迭代步骤为:
Wt+1=Wt-η*Wt*(a(n-p)T+(n-p)aT)
(3)
Wt为第t次迭代的估值,Wt+1为更新值,{a,p,n}是一个三元组样本,η为学习速率。
3.3 SIFT描述符提取
人脸对齐是人脸验证的难点,需要大量的运行时间,严重影响人脸验证的性能。SIFT描述符具有旋转不变性、尺度缩放、亮度变化以及查看变化、仿射变换和噪声的稳定性等优点。如果我们可以从卷积神经网络得到信息SIFT描述符,它可以在不需要人脸对齐的情况下帮助人脸验证。下采样是卷积神经网络中一个必不可少的过程,在最大池化过程中可以得到图像特征点的方向和梯度信息,能够同步的获取SIFT描述符。
在池化过程中人脸的SIFT描述符由以下过程获得。由式(4)得到最大值和式(5)得到平均值,其中vi为样本块元素,如图6所示。梯度g为最大值m减去平均值a(如式(6)所示)。梯度方向由式(7)得到
m=max(v0,v1,v2,v3)
(4)
a=avg(v0,v1,v2,v3)
(5)
g=m-a
(6)
θ=90×i+90×((m-v(i+3)%4)/((m-v(i+5)%4)+(m-v(i+3)%4)))
(7)
其中i为最大值m索引值,θ取值范围为0~360度,分为8个区域,每个区域有45度,{0°,45°,90°,135°,180°,225°,270°,315°}代表8个方向(如图4所示)。
在从2×2图像区域获得梯度和方向之后(如图4所示),描述单元通过4×4梯度和方向块中的8个方向的梯度统计获得(如图5a所示)。4×4描述单元构成一个SIFT描述符,由128维向量表示(如图5b所示)。由图5b所示一个SIFT描述符需要从32×32图像区域中提取。
3.4 人脸验证
利用两幅人脸图像的距离D(xi,xj)确定相同和不同的分类。同一人的所有人脸对(i,j)用Psame表示,而不同人的所有人脸对用Pdiff表示。
我们把所有真正接受的集合定义为
TA(d)={(i,j)∈Psame|D(xi,xj)≤d}
(8)
这些是在阈值d时正确分类为相同的人脸对(i,j)。
FA(d)={(i,j)∈Pdiff|D(xi,xj)≤d}
(9)
FA(d)是错误分类为相同(错误接受)的所有对的集合。然后将给定人脸距离d的验证率VAL(d)定义为
(10)
相应地,错误接受率FAR(d)是
(11)
从最大池化的结果(如图6所示)可以看出,它保留了更好的人脸特征,我们在最大池过程中提取最大值时,可以快速地获得方向信息,从而方便地获得SIFT描述符。在CNN1和CNN2中,第一池化层可以得到49个描述符,第二池化层可以得到16个描述符。
为了进行快速的人脸验证,我们设计了基于级联的验证方法,该方法包含三个连续验证步骤(如图7所示)。利用池化结果中提取的SIFT描述符进行ver1和ver2验证,保证了不需要人脸对齐情况下的验证准确性。如表1所示,CNN1中pool1和poo2层有20和40个池化层结果,如表2所示CNN2中pool1和poo2层有32和64个池化结果,采用所有中间卷积结果进行验证,能够有效保证验证精度。在验证过程中设置一个阀值,当相似度大于阀值时,表示来自同一个人的两张照片,当相似度小于阀值时,表示来自不同人的两张照片。在验证过程中,只有当前一步验证为同一个人时,才允许它们进入下一步验证,具体验证过程如图7所示。
4 实验
4.1 数据集选择和预处理
神经网络需要使用大数据集进行训练,选择合适的训练数据集非常重要。CASIA-WebFace有足够的实体,并且每个图像都有标签,所以它们更适合CNN的训练和微调。CASIA-WebFace包含493,456张人脸图像,包含10,575个实体。
本文使用LFW和YTF两个常用的数据集进行评估,这两个数据集是在无约束条件下人脸验证的事实标准集。LFW数据集包含13233张来自互联网的5749个实体的人脸图像。YTF包含了从YouTube上收集的1595人的3425个视频,是视频中人脸验证的标准基准。为了便于比较,算法通常给出LFW和YTF中给定6000对人脸的平均人脸验证精度和ROC曲线。利用CASIA-WebFace数据集训练卷积神经网络。在训练之前,所有的人脸图像归一化为224×224。
4.2 训练
CNN训练分为两个阶段(如图1所示),第一个阶段使用大量的样本对网络的分类能力进行训练,使网络的趋于稳定。每二个阶段主要进行人脸验证能力的训练使网络能够进行人脸验证。
第一阶段使用softmax loss对CNN进行训练,得到CNN模型。训练使用开源的深度学习框架pytorch在ImageNet大型数据集上进行。CNN1和CNN2的训练参数进行相应设置。CNN1中动量设为0.9,卷积层和全连接层的权值衰减设为5e-3,为了避免全连接层的过拟合,将dropout设为0.5。在CNN2中,动量设为0.9,卷积层和全连接层的权值衰减设为5e-4。fc6全连接层是用于人脸验证任务的人脸表示。从fc6层到fc7层的参数都非常大,对于学习大的全连通层参数可能会导致过拟合。为了克服它,我们将dropout设置为0.5。Xavier用于卷积层参数初始化,Gaussian用于完全连接层初始化。深度模型在GTX1070上训练了2周。
第二阶段是对网络的人脸验证能力进行训练,主要目标是缩小相同实体之间的距离及增大不同实体之间的距离。输入数据需要一个图像组,每个组包含三个图像(一个锚点样本,一个正样本,一个负样本)。在此阶段,我们只训练triplet loss层,而保持其他层的参数不变。我们从CASIA-Webface数据集中选择5606个实体,其中每个实体包含至少30张用于训练的图片。
4.3 测试
我们在LFW和YTB数据集上使用给定的标准的样本对我们的方法进行评估,该数据集总共定义了3000组正对和3000组负对样本,并将它们进一步划分为10个不相交子集进行交叉验证。每个子集包含300组正对样本和300组负对。在级联人脸验证过程中(如图7所示),在第一次验证(ver1)中将低阀值设置为0.4,当相似性在0.4以上时,认为两幅人脸图片来自同一实体,将进行第二次验证(ver2),否则将显示来自不同实体的两幅图像;ver2中阀值设为0.7,验证过程与ver1相同(如图7所示),ver3中使用深度学习特征进行最终验证。
根据表3,表4中的结果,我们得到以下结果:CNN1和CNN2的模型都在LFW和YouTube数据集上实现了良好的性能。该框架在人脸对齐和无对齐两种情况下均能获得较好的性能。在没有人脸对齐的LFW和YouTube人脸数据集中,CNN1的人脸验证准确率分别为96.53%和93.65%,CNN2在LFW和YouTube人脸数据集中的人脸验证准确率分别为98.37%和94.49%。
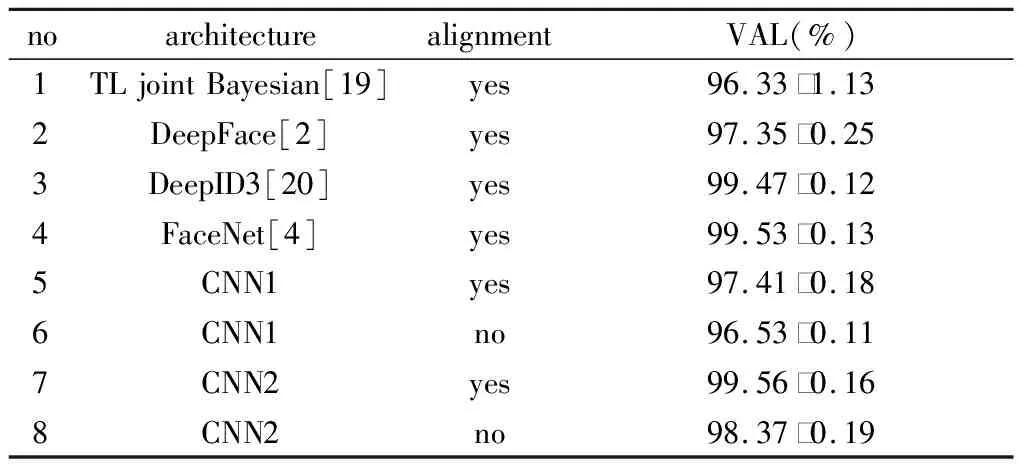
表3 在LFW上进行人脸验证
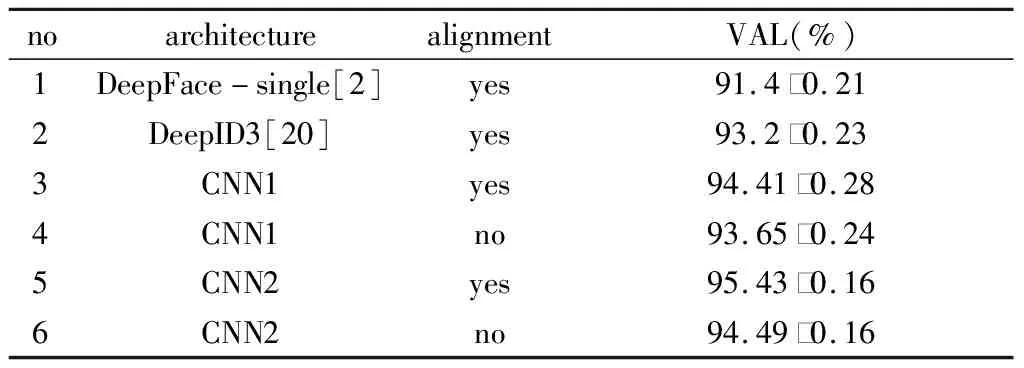
表4 在YouTube上进行人脸验证
4.4 结果分析
在本节中,分析了框架的效果。我们在LFW数据集上对CNN1和CNN2进行测试,表5给出了测试结果。
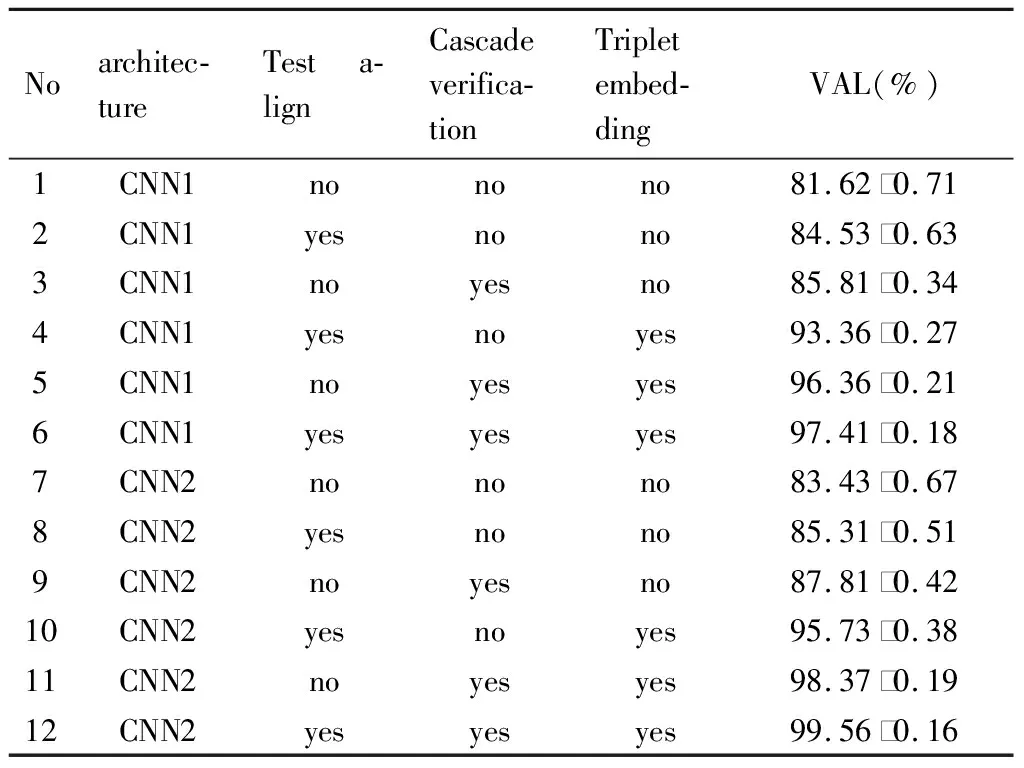
表5 LFW的性能评估
我们从以下几个方面分析测试结果,网络结构:通过表5中第1行与第7行、第2行与第8行、第3行与第9行、第4行与第10行的比较可以看到在同等条件下CNN2比CNN1的性能明显提高。其中原因为:CNN2具有更多的层和参数,可以获得良好的表示向量;从表5第1行对第2行,第7行对第8行可以看出由于使用了级联验证性能明显提高;从表5第6、12行结果可以看出方法能够有效地防止人脸姿态变化的影响;从表5第1行与第3行可以看出,经过级联验证,性能提高了4.2%;从表5第2行与第4行对比可以看出使用trilet loss进行微调具有重要的作用,准确率提高了8.83%。
级联验证分析:在本节中,我们将评估级联验证框架的性能。从表6的结果可以看出,Ver1在没有对人脸对齐的情况下,具有较高的验证精度。这里有以下原因:首先,池化层的结果比原始图像具有更明显的纹理特征,这使得从池化结果中提取的SIFT描述符具有更好的分类能力。其次,pooling1的多个池化结果用于验证,这确保了验证的准确性。从表6第2行与第5比较可以看出ver2明显的提高了准确性,这是由于ver2是基于ver1的第二次验证,它使用了更多的池化结果来验证;Ver3通过人脸的深度特征验证实现了更好的验证结果。验证结果表明,级联的验证在非对齐人脸的验证中能够有效的提高准确率。

表6 LFW的级联人脸验证测试
运行速度分析:从表7中可以看出,我们的方法具有很高的计算速度,原因如下:我们的CNN架构有更少的层和参数;无需人脸对齐且SIFT描述符利用池化过程中同步得到的有效节省了计算时间。
如表7所示,对于一对人脸图像验证,CNN1的CPU时间为70ms;结果表明该模型可能适用于智能手机等小型设备上。使用CNN2模型对一对人脸图片验证需要CPU时间为560ms,但使用GPU时只需要到67ms,表明CNN2适用于使用GPU在设备上运行。
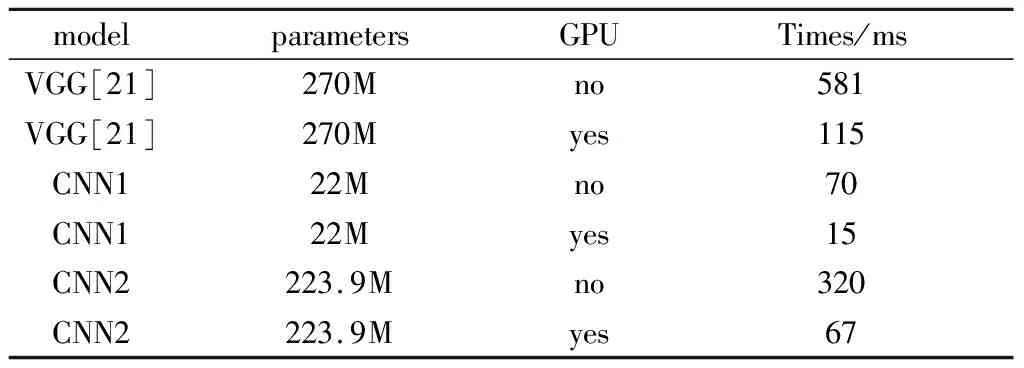
表7 一对图像验证的时间(它在具有GPU GTX1070的单核i7 6700上进行测试)
4.5 与当前方法对比
本文采用LFW和YTF两个著名的人脸识别和验证数据集上评估我们的模型。从图8和图9 ROC比较来看,CNN2模型在两个数据集上均优于当前最好的方法;虽然CNN1所包含的层数和参数较少,但其性能也非常显著。两种方法在人脸图片非对齐的情况下同样能取得较好的准确度。
5 结论
本文设计了一个基于深度学习的非对齐人脸验框架。在该框架中首先使用softmax loss对深度网络进行的充分的分类能力训练;然后加入triplet loss层进行微调使之适合于人脸验证。本文提出了在网络运行过程中间结果中同步提取SIFT描述符进行级联验证,减少了人脸姿态变化对人脸验证的影响,有效提高了人脸验证速度与精确度。为了使框架能够具有更广泛的应用,设计了两个CNN架构:CNN1具有较少的层和参数需要较小的计算量,可用于智能手机等小型计算设备;CNN2模型具有更多的层数和参数需要较大的运算量,适用于具有GPU的大型运算设备。经过在LFW和YTF数据集上测试结果表明,该框架在人脸非对齐的情况下具有优秀的性能。
