改进的K-means算法在校车站点布局中的应用
2021-01-26赵天天
赵天天
(1.天津市自然资源调查与登记中心,天津 300048)
校车站点布局问题是一种服务于学生的设施选址问题,主要用以确定校车车站的位置,并将学生分配到站点上。校车站点的分布直接决定了学生到车站的步行距离;而作为校车路径规划问题中的一部分[1],校车站点布局问题很少被单独讨论。大多设施选址研究均以最大人口覆盖面积或最小运行成本为目标[2-3];而校车站点布局往往追求学生总步行距离最短或以最少的站点数覆盖所有的学生。针对该问题,国内外学者做了诸多研究,Hassan Z[4]等为达到总旅行时间最小化的目的提出了优化公交站点的数学模型;Johan S[5]以已有的公交站点为潜在校车站点,在其中进行选择,直接将学生分配到站点上;在研究方法上,任丽[6]利用基于时空聚类的遗传算法对顾客点进行聚类,并将他们分配到不同的配送区域中;张富[7]等提出以最少包含所有数据点的圆的中心作为校车站点的方法。然而,大多数方法除了从已有公交站点中选取外,均较少考虑站点位置应在路网上的问题。
本文以学生到站点步行距离最短为目标,提出了聚类算法的目标函数,以一定范围内密度最大点为初始类中心对K-means 算法进行改进,并在每次迭代中将类中心投影到路网上,以保证站点位置位于路网中,最后计算站点位置。
1 改进的聚类算法
1.1 聚类算法在校车布局问题中的应用
聚类算法主要包括分割法、层次法、基于密度法、基于网格的方法和基于模型的方法[8]。学生点聚类更适合一种以曼哈顿距离为相似度的圆形簇(类球形)聚类[9],对聚类算法的要求相对简单。根据聚类算法的不同特征,本文选用分割法中最经典的K-means 算法进行聚类。该算法自1955 年被提出后,至今仍被广泛应用[10]。
K-means 算法的思想为:给定n个数据点{x1,x2,…,xn},找到K个聚类中心{a1,a2,…,ak},使得每个数据点与它最近的聚类中心的距离平方和最小,并将该距离平方和称为目标函数,记为Wn,数学表达式为[11]:
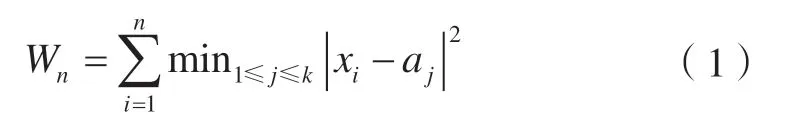
在校车站点布局问题中,聚类的数据点为学生坐标,聚类中心为校车站点,聚类的目标函数为每个学生到站点的步行距离和最小,数学表达式为:
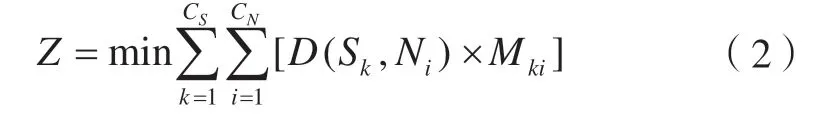
式中,CS为总学生数;Sk为第k个学生(k=1,2,…,CS);CN为学生站点数;Ni为第i个学生站点(i=1,2,…,CN);D(Sk,Ni)为该学生到第i个车站的步行距离;Mki=0或1,第k个学生被分配到第i个站点上则为1,否则为0。
通常聚类算法采用距离函数(多为欧氏距离)来判断数据之间的相似度,基于距离度量的算法在用于发现分布均匀的球形簇上很有效;但该算法也有很多缺点,主要包括需要预先确定K值、严重依赖于初始簇中心点的选取、聚类结果易受噪音点数据的影响、聚类算法无法发现任意形状的簇以及易收敛于局部最优解等[12],因此需对K-means 算法进行改进。
1.2 改进的聚类算法
K-means 算法的主要参数包括K值、初始中心和距离矩阵[10]。根据K-means 算法的主要参数和缺点,本文主要在相似度的计算方法、K值的确定以及初始中心点的选取上进行改进。
首先,考虑到北京市城区的路网结构以矩形环状为主,道路多以此为依托,与经纬线平行网状分布,因此采用曼哈顿距离替代欧氏距离量算点与点之间的距离,作为近似路网距离。学生步行到车站必须经过两个部分:学生先由居住地走到最近的路网上(图1中虚线部分),再沿路网走到车站(图1 中实线部分)。
当路网与经纬线基本平行时,学生的步行距离如图1a 所示;当路网与经纬线不平行时,学生的步行距离如图1b 所示,学生到站点的距离会略大于实际步行最短距离。

图1 学生到站点距离示意图

其次,在K值的确定和初始中心点选取方面,经典的K-means 算法是随机选取K个的中心点,改进方法以最大最小距离法最为常见,其原则是使各初始类别之间尽可能的保持最大距离[13],这样将使站点的分布过于均匀,并不能保证站点位于学生密度最大区域的中心,区域内学生距离尽可能相同。因此,本文按照点的密度大小来划分初始类,在ArcGIS 中计算点的核密度,优先选取密度最大的点为第一个初始类中心,由于密度最大的点附近存在较多密度较大的点,为避免站点之间距离太近,限定在距已知类别点的最近距离大于站点之间的最小距离R的点中选取密度最大的点作为新的类别中心。本文通过限定R值来确定站点个数,并未从成本考虑限制站点的最多个数。
最后,由于站点需建立在道路上,将在每次迭代中形成的聚类中心投影到路网上,对学生进行重分配,重新计算聚类中心,进行下一次迭代,直到目标函数收敛。
基于密度法改进的K-means 算法的具体步骤为:①将学生点放置到最近的路网上,并计算其到最近路网上垂点的距离以及各垂点的核密度;②选取密度最大的点作为第一类中心;③选取其余点中密度最大且到已知类距离大于站间距阈值R的点作为新的类别中心;④循环步骤③,直到不存在到已知类距离大于站间距阈值R的点为止,形成初始站点;⑤将学生点分配到曼哈顿距离最近的站点上;⑥计算每个站点类学生点的重心坐标,并将其坐标改写成路网上最近坐标(即将中心点放置在路网上),计算学生点到新的站点坐标的距离和;⑦重复计算步骤⑤、步骤⑥,直到学生到站点的距离和不变,即模型中的目标方程收敛为止,同时检验学生分配结果是否满足模型中的条件。
1.3 站间距的确定
由于校车车站个数受站点间最小距离R的限制,因此R值的确定也十分重要。从运行成本考虑,站间距越大,车站数和校车辆数越少,车辆运行时间越短,耗油量也越少;但间距越大使得学生到最近站点的步行距离越大[3],将导致愿意乘坐校车的学生越少或满意度降低,从而又使得利益降低。从学生的角度考虑,校车站点距离起点的位置越近越好,由于学生的位置是离散的,这样将导致站间距变小,从而造成校车停车次数过多,增加了学生的出行时间。
Pushkarev B[14]等研究发现大多数人不愿意去步行距离超过800 m 的车站,而北京计划优化调整地面公交线网,使90% 乘客步行到最近车站距离不超过500 m。考虑到北京市主干道与次干道路网平均间距为400~1 000 m,本文以500 m 和800 m 作为站点间最小间距,以检验算法运行结果是否受站间距影响。
2 实例应用
本文以北京市某中学505 个学生点为例,学生点主要分布于北京市东城区和朝阳区;分别利用基于密度法改进初始类中心的K-means 算法和基于最大最小距离法改进的K-means 算法生成校车站点,并在800 m与500 m 两种站间距下进行对比分析。在500 m 站间距下基于密度法改进的聚类算法结果中,每次迭代的学生到站点步行距离总和如表1 所示。

表1 逐次迭代产生的步行距离
每次迭代的学生到站点步行距离总和呈递减趋势,直到两次迭代结果相同,生成最终的校车站点坐标;其他情况中也出现了同样的迭代效果。在500 m 站间距下,利用基于密度法改进的聚类算法生成的结果如图2 所示。
在不同站间距下两种改进方法中,学生到站点的步行距离如表2 所示。在同一站间距下,基于密度法改进初始类中心的K-means 算法使得学生到站点的距离以及距离方差均较小,站点数差别不大,迭代次数约减少50%;800 m 站间距比500 m 站间距生成的站点数少,学生总距离和大,不同站间距下,其结果的变化趋势不受影响。

图2 基于密度法改进初始类中心的K-means 算法生成的站点分布(500 m 站间距)

表2 学生到站点的步行距离
对比各学生步行距离也可发现上述相同结论,如图3 所示,各学生到站点的步行距离从小到大顺序排列。在同一站间距下,基于密度法改进初始类中心的K-means 算法使得绝大多数学生步行距离小于基于最大最小距离法改进的K-means 算法结果。当限定学生到站点距离的满意程度为最小站间距时,绝大多数的学生步行距离使学生满意,且利用密度法生成的站点得到更多学生满意。最小站间距的改变使得学生到站点的步行距离变化较大,但两种算法的比较结果不受其影响。
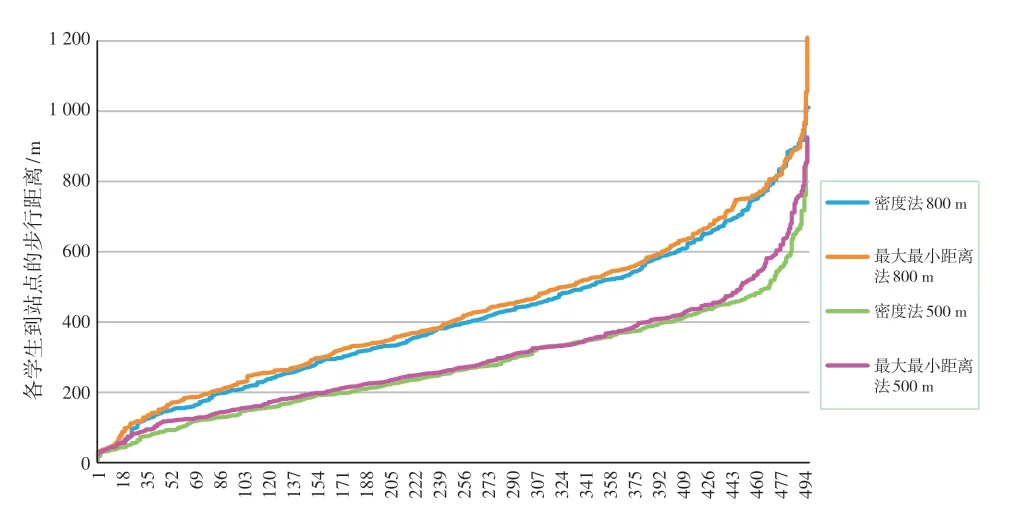
图3 各学生步行距离
3 结 语
本文主要针对校车站点布局问题,利用K-means算法聚类得到车站位置。为保证生成的站点分布在路网上,在聚类算法的迭代中加入了将聚类中心投影到路网上的步骤。本文以学生总步行距离最短为聚类的目标函数,为使得学生到站点的步行距离较小,对K-means 算法选取初始类中心的方法进行了改进,选取密度最大的点作为初始类中心,替代了最大最小距离法中依照距离的方法,并对二者进行了比较。实验结果表明,在相同站间距下,基于密度法改进的聚类算法优于基于最大最小距离法的改进算法,迭代次数明显减少,且不受站点间最小间距限制的影响。该方法还适用于超市班车站点选址、物流配送点选址等问题。
