公司财务舞弊的智能识别与模型优化策略
2021-01-26曾小青唐湘勇
曾小青,唐湘勇
(长沙理工大学 经济与管理学院,湖南 长沙 410114)
一、引言
截至2020年6月30日,我国深沪两市A股上市公司数量已达3 936家。然而,在资本市场不断发展壮大过程中,上市公司财务舞弊现象也屡见不鲜。公司内部人员失信、外部审计机构失责以及国家监管体系不完善是发生财务舞弊的主要原因[1]。近年来,瑞幸咖啡、康得新、康美药业、獐子岛等重大财务舞弊事件引起了国家和社会各界人士的广泛关注。财务舞弊行为导致财务信息失真,投资者因无法了解公司的实际情况而作出不合理的投资决策,严重损害了投资者的切身利益,同时财务舞弊行为导致资本市场资源无法得到合理配置,严重影响了资本市场的健康稳定发展。
国家证监会为加大对市场监管的力度,在2020年3月新施行的《证券法》中强调,将大幅提高财务舞弊的处罚力度,增加公司财务舞弊的成本。但财务舞弊行为隐蔽、手法多样、识别困难,使得不少上市公司为获取财务舞弊带来的巨大预期收益,铤而走险。因此,在国家出台相关政策严惩财务舞弊行为的同时,应改善财务舞弊识别手段,提高识别效果,增加舞弊成本,杜绝财务舞弊现象[2]。
二、文献综述
随着数据挖掘技术的不断发展,越来越多的学者开始研究如何利用数据挖掘技术识别财务舞弊行为。数据挖掘分类技术主要包括逻辑回归、决策树、支持向量机、贝叶斯等。逻辑回归在二分类问题中运用最广,洪文洲等人选取2003-2013年受到证监会公开处罚的44家舞弊公司和与之匹配的44家非舞弊公司作为研究样本,分别建立了采用进入法、向前逐步法和向后逐步法的Logistic回归模型,研究发现,采用进入法和向后逐步法建立的模型识别效果明显优于向前逐步法建立的模型,但受变量间多重共线性影响采用进入法的逻辑回归模型,其结果表明单个变量显著性不高[3]。考虑到模型应具备分类兼评分两个功能,学者们基于支持向量机构建财务舞弊识别模型。刘志洋等以2007-2015年首次处罚的152家制造业上市公司和152家非舞弊公司作为研究对象,研究发现,直接剔除相关性大于0.5的指标,损失了大量信息,导致Logistic回归模型识别效果不佳;采用主成分分析法降维后建立Logistic回归模型识别效果明显提高,建立具有分类和评分功能的支持向量机模型的财务舞弊识别效果最佳[4]。随着计算能力的提升和深度学习方法的改进,神经网络方法备受关注。冯炳纯将Logistic回归模型、人工神经网络、支持向量机、随机森林四种分类技术进行了对比分析[5];夏明等对数据进行主成分分析后将RBF神经网络和BP神经网络进行组合建立双隐藏层模型,与RBF神经网络和BP神经网络相比,组合模型的识别效果更佳[6]。
本文以舞弊公司所有舞弊年份中的数据作为舞弊样本,按照尽可能保留样本的完整性原则,建立了基于逻辑回归、决策树、神经网络、支持向量机的四类财务舞弊识别模型,并通过调参进行模型优化和模型比较,实现对财务舞弊现象的智能识别。
三、指标体系构建与样本选取
(一)指标体系构建
指标体系包括财务指标和非财务指标。关于财务指标选取,Persons研究发现,财务舞弊公司通常具有较高的财务杠杆率和流动资产比率、较低的资本周转率和较小的公司规模[7]。Ravisankar等对比分析了营运能力指标在舞弊样本和非舞弊样本间的差异,研究发现总资产周转率、应收账款与销售收入比有显著差异[8]。杨贵军等发现衡量偿债能力、盈利能力、现金流量、运营能力等9个财务指标对模型有较好的解释力[9]。熊方军等选取总资产周转率、资产负债率、流动负债与总负债之比等12个重要财务指标进行研究,发现通过分析财务数据波动性能有效识别上市公司的财务舞弊行为[10]。关于非财务指标选取,Rezaee研究发现公司的治理结构与财务舞弊之间存在很大的关系[11]。Gao Y等人研究发现董事会规模越大、董事会会议次数越多,则公司进行财务舞弊的可能性越小[12]。钱苹等研究发现,将审计意见、事务所规模大小等审计信息作为非财务指标加入财务舞弊预测模型可以提高识别效果[13]。
上市公司通常采用如下手段进行财务数据造假:虚构关联方交易增加公司收入;少计费用或调整折旧少计成本;虚增银行存款、货币资本、存货等资产类科目数据;虚增利润。虚构交易时无法收到货款将导致应收账款异常增加,销售收入增长速度比成本增长速度快,因此,本文选取了应收账款与收入比、应收账款周转率、营业收入现金净含量、营业收入增长率、营业总成本增长率、营业成本率等与之相关的财务指标。少计费用和成本时,管理费用率异常故加入初始指标体系。虚增银行存款、货币资本、存货往往导致流动比率、速动比率、资产负债率、资产报酬率、总资产净利润率、流动资产周转率、流动资产净利润率、净资产收益率、存货周转率等与资产类科目相关的财务指标异常,因此,将以上财务指标加入初始指标体系。虚增利润时,资产报酬率、总资产净利润率、现金与利润总额比等反映企业盈利能力的财务指标可能存在异常,因此将其加入初始指标体系。非财务指标中,审计意见对舞弊识别作用明显,董事会会议次数及股东大会会议次数、前十大股东持股比例、董事长与总经理兼任情况等反映了公司内部治理状况。最终,本文在CSMAR财务指标分析中选取包括风险水平、经营能力、现金流分析、偿债能力、发展能力、盈利能力在内的25个财务指标,以及在外部审计、治理结构中选取5个非财务指标构成初始指标体系。初始特征体系具体指标如表1所示。

表1 初始指标体系
(二)样本选取
本文在国泰安数据库中选取了2010-2019年违规样本数据,筛选出违规类型为虚构利润、虚列资产、虚假记载、推迟披露、重大遗漏、披露不实等违规记录。如表2所示,虚假记载、推迟披露、重大遗漏等违规行为较多。在每条违规记录中按违规年度进行展开并剔除相同记录后共得到2 668个舞弊样本。公司若存在连续舞弊,以往学者通常选择首次舞弊年度作为违规年度,本文将公司所有舞弊年度纳入样本中,扩充了样本数据且保证了样本数据的完整性。

表2 六大违规类型数量统计
利用国泰安数据库中公司研究系列中的数据收集初始指标体系中的5个非财务指标和25个财务指标数据,按图1所示的方法对数据进行整合,剔除空值后共得到2 338个舞弊样本数据。按照行业相同、会计年度相同、从未被公开处罚的原则1∶2选择配对样本,最终得到非舞弊样本4 676个。

图1 数据整合
(三)特征选择
在SPSS中,通过独立样本曼-惠特尼U检验判断30个变量在舞弊样本和非舞弊样本中是否存在显著差异。检验结果表明:X6(存货周转率)、X16(营业收入增长率)、X29(董事长与总经理兼任情况)3个变量不存在显著差异性,故将其剔除。
由于各指标之间具有不同的量纲,数据间差异较大。为了消除数据取值范围差异对模型效果的影响,需要对数据进行归一化处理。本文采用较为常见的“最小-最大归一化”方法。在SPSS中,对初始特征指标体系中样本数据进行归一化处理,处理原则如下:
归一化处理后对23个财务指标进行KMO和巴特利特检验,结果如表3所示,KMO值大于0.5且巴特利特球型度检验的P值小于0.05,因此适合主成分分析法对数据进行降维。

表3 KMO和巴特利特检验
在SPSS Modeler中按图2流程进行主成分分析,根据特征值大于1.0提取主成分,最终提取了11个因子,累计方差百分比为79.110%。

图2 主成分分析
将11个因子分别命名为Y1,Y2,Y3,Y4,Y5,Y6,Y7,Y8,Y9,Y10,Y11,如表4所示。其中,Y1主要表示盈利能力指标X19,X20,X21,X22;Y2主要表示偿债能力指标X12,X13,X14;Y3主要表示发展能力指标X17和X18;Y4主要表示风险水平指标X1和X3、发展能力指标X17和X18以及盈利能力指标X25;Y5主要表示经营能力指标X7和X8、偿债能力指标X12和X13以及盈利能力指标X24;Y6主要表示经营能力指标X4、盈利能力指标X23和X24;Y7主要表示经营能力指标X5、现金流分析指标X9;Y8主要表示风险水平指标X2、经营能力指标X5、现金流分析指标X11;Y9主要表示现金流分析指标X10和X11、发展能力指标X15;Y10主要表示现金流分析指标X10、发展能力指标X15;Y11主要表示风险水平指标X2和发展能力指标X15。最终指标体系中含有4个非财务指标和11个因子。

表4 主成分构成
四、模型构建
在SPSS Modeler中对样本数据类型进行定义,按照训练集和测试集之比为7∶3的分配标准对样本进行分区后,分别建立基于逻辑回归、决策树、神经网络、支持向量机的财务舞弊识别模型。训练集中样本数为4 890,测试集样本数为2 124。建模流程如图3所示。

图3 建模流程图
(一)逻辑回归
逻辑回归是二分类问题中运用最为广泛的模型。有一组自变量X1,X2,…,Xn,因变量为Y。本文中,当Y表示舞弊样本时,记Y=1;当Y表示非舞弊样本时,记Y=0。逻辑回归模型中,用因变量Y取0或1的概率P来表示模型预测结果,若概率P(Y=1│X)大于0.5则预测结果取1,小于0.5则取0。逻辑回归模型表达式为:
等价于
在SPSS Modeler中,建立逻辑回归模型时,可以选择过程为多项式或二项式,本文选择多项式过程。多项式过程方法共有五种,分别为进入法、逐步法、前进法、后退法、后退逐步法。测试后发现,采用进入法构建的模型识别效果最优,因此本文选择使用进入法。基于4个非财务指标以及主成分分析法提取的11个主成分建立模型后,逻辑回归模型为:
RESULT=1/[1+exp-(-0.198 1*Y1+0.514 9*Y2-2.175*Y3+1.806*Y4-0.076 52*Y5+0.196*Y6-0.412 2*Y7+0.457 3*Y8-0.595 8*Y9-0.442 5*Y10+0.524 5*Y11-0.018 28*X26+0.093 11*X27-0.021 09*X28+1.821*[X30=0]+0.349 6)]
由表5所示的参数估计结果可知,以Sig.值小于0.05为标准,与因变量RESULT显著相关的自变量有Y1,Y2,Y3,Y4,Y6,Y7,Y8,Y9,Y10,Y11,X27,X28,X30。逻辑回归模型的识别效果如表6所示,在逻辑回归模型训练集中有3 695个样本被准确识别是否进行财务舞弊,占训练集总数的75.56%,测试集中有1 574个样本被准确识别,占测试集总数的74.11%。

表5 参数估计

表6 逻辑回归模型识别效果
(二)决策树
决策树是树形结构,由决策节点、分支和叶节点组成。决策节点表示样本属性划分;分支是对决策节点属性划分进行判断后的输出;叶节点表示经过分支判断后到达的类。决策树从顶端根节点出发,从上往下移动,每一个决策节点按照尽可能使划分后各区域样本点纯度高的原则划分属性,然后判断样本属性,最后对样本分类到达叶节点。这个自上而下进行判断输出的过程就是利用决策树进行分类的过程。
在SPSS Modeler中,可供选择的决策树节点有C&R 树(R)、Quest(Q)、CHAID(C)和C5.0四种。C5.0算法适合用于处理大数据,因此本文选取C5.0算法建立财务舞弊识别模型。数据采用主成分分析法降维后,C5.0模型中树状图深度为17,图4为部分树状图结构。

图4 决策树树状图
决策树模型识别效果如表7所示,训练集中模型中有4 410个样本被准确识别,识别正确率为90.18%;测试集中有1 698个样本被准确识别,识别正确率为79.94%,测试集中模型识别率比训练集中的识别率降低了10.24个百分点。总体来说,决策树模型识别效果优于逻辑回归模型的识别效果。

表7 决策树模型识别效果
决策树模型中,预测变量重要性结果如图5所示,排名前五的变量依次为:Y3(0.30),X30(0.16),Y1(0.15),Y2(0.15),Y6(0.06)。由Y3表示的指标X1,X3,X17,X18以及非财务指标X30在决策树模型中最重要。在决策树模型中,财务杠杆X1、综合杠杆X3、营业总成本增长率X17、管理费用增长率X18和审计意见X30等5个指标对财务舞弊识别模型有较好的解释力。

图5 决策树模型预测变量重要性
(三)支持向量机
1.基础建模
支持向量机(SVM)将每个样本数据通过某种变换投射到空间中成为一个具体的点,使不同类别的样本点尽可能明显地区分开。支持向量机主要应用于数据样本集较小,样本维度较高的分类问题。支持向量机通过将样本的向量映射到高维空间中,寻找区分两类数据的最优超平面,使这两类数据与平面最近的点到超平面的距离最大化,与超平面的距离越大表示 SVM的分类效果越好。支持向量机为了更好地分类,通过某种变换ψ(x),将X映射到高维空间H中,如果低维空间存在K(x,y)使得:
K(x,y)=ψ(x)·ψ(y)
则称K(x,y)为核函数,其中ψ(x)·ψ(y)为x,y映射到空间H上的内积,ψ(x)为X→H的映射函数。核函数主要有四种:高斯核、线性核、多项式核、Sigmoid核。本文选择多项式核支持向量机模型,调整参数进行模型优化。SPSS Modeler中,默认为一阶多项式,识别效果如表8所示。

表8 支持向量机模型识别效果
2.模型优化
核函数为多项式时支持向量机模型识别效果比较如表9所示。多项式核函数可调节的参数主要为伽马值,随着伽马值增加,模型的识别效果逐渐提高。伽马值即多项式阶数,在支持向量机模型中,随着二项式阶数增加,模型分类边界的弯曲程度会逐渐增大,分类效果越好,但是会出现模型过拟合现象,因此将导致模型在测试集中的识别效果远不及在训练集中的识别效果。且随着阶数增加,模型的运行时间也会逐渐增加,五阶多项式时运行时间为30分15秒,模型的时间成本较高。

表9 多项式核支持向量机模型识别效果比较
(四)神经网络
1.基础建模
神经网络由输入层、隐藏层、输出层组成。从输入层输入变量经过神经元时会运行激活函数,对每一个输入值(x)赋予权重(w)并加上偏置(b),然后将输出结果传递给下一层的神经元。神经网络的训练过程主要包括前向传播和反向传播,前向传播是指输入变量后逐层向前传递最后得到结果,并对比实际结果从后往前逐层逆向反馈误差,权重(w)和偏置(b)在训练过程中通过梯度下降法不断修正,然后重新进行从前往后传输,依此反复迭代直到最终预测结果与实际结果一致或者在一定的误差范围内结束训练。
在神经网络建模过程中,SPSS Modeler中可选择的模型有径向基函数(RBF)和多层感知器(MLP)。由模型自动计算神经元数时,神经网络模型识别效果如表10所示。选择径向基函数时,测试集中模型识别正确率为67.61%,识别效果不佳;选择多层感知器时,正确率为84.09%,识别效果较好,隐藏层数和神经元数分别为1和6,因此,在下文基于多层感知器调整参数进行模型优化。

表10 基于RBF和MLP模型的神经网络模型识别效果比较
2.模型优化
与逻辑回归、决策树、支持向量机以及采用径向基函数的神经网络模型相比,采用多层感知器的神经网络模型在测试集中的正确率最高,因此调节采用多层感知器的神经网络模型的参数对模型进行优化,以探求最佳的财务舞弊识别模型。神经网络模型可调节的参数主要有隐藏层数、隐藏层神经元数、激活函数以及梯度下降法循环次数。在SPSS Modeler中,神经网络模型可以调节的参数主要有隐藏层数和各隐藏层神经元数,隐藏层数最多为2,因此在构建多层神经网络模型时存在一定局限性。构建多层神经网络时,按n2小于n1的原则调整神经元数,在测试集中的正确率最高的9个模型(神经网络1-9)如表11所示。与自动计算神经元数得到的单层神经网络模型相比,多层神经网络模型的识别效果更佳。当n1=13,n2=10时,神经网络7的正确率为86.86%,是所有神经网络模型中正确率最高的模型。
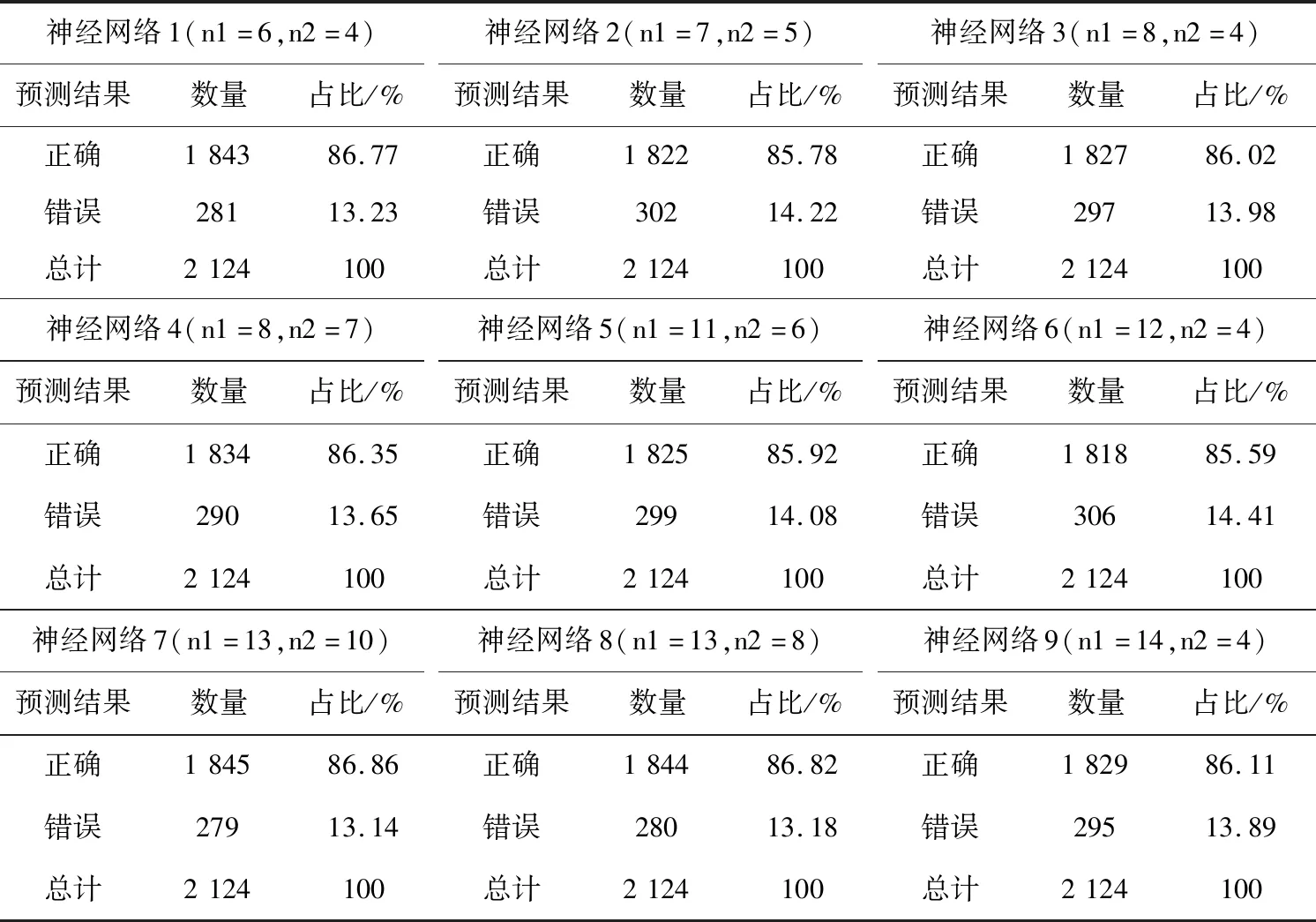
表11 各神经网络模型测试集识别效果比较
神经网络7如图6所示,神经网络包括输入层、两个隐藏层以及一个输出层。输入层有Y1-Y11,X26,X27,X28,X30共15个变量,隐藏层1有13个神经元,隐藏层2有10个神经元,输出层为RESULT判断结果。Y3是最重要的变量,其次是Y9,Y5,Y6,Y10。

图6 神经网络模型
神经网络7识别效果如表12所示。训练集中,RESULT分类正确的样本有4 287个,占训练集总数的87.68%;测试集中,判断正确的样本数为1 845,占测试集总数的86.86%。神经网络模型的识别效果由于逻辑回归和决策树,识别效果较好。

表12 神经网络7识别效果
五、模型评价与比较
(一)混淆矩阵
混淆矩阵是最常用的评价二分类模型准确程度的工具,如表13所示。

表13 混淆矩阵
准确率(Accuracy),表示模型的测试组中类别判断正确的样本数占总样本数的多少。
精确度(Precision),表示模型测试组预测为舞弊公司中实际舞弊公司的占比。
召回度(Recall),也称灵敏度(Sensitivity),表示测试组中判断正确的舞弊公司数与实际舞弊公司数之比。
F1Score综合了精确度(Precision)与召回度(Recall)。F1Score的取值范围为[0,1],F1Score越接近1代表模型的识别效果越好,越接近0代表模型的识别效果越差。
(二)模型识别效果比较
基于逻辑回归、决策树、支持向量机、神经网络构建的财务舞弊识别模型效果的评价指标计算结果如表14所示。逻辑回归模型的召回度较低为35.89%,决策树模型的准确率较高为79.94%,支持向量机(五阶多项式)的召回度较高为87.23%,多层神经网络模型1-9的准确率、精准度、召回度和F1Score都较高。

表14 模型评价指标计算结果
将以上15种模型的准确率、精准度、召回度、F1Score进行比较可知,神经网络7的准确率最高为86.86%;精准度最高的是支持向量机(三阶多项式)为81.38%;召回度最高的是支持向量机(五阶多项式)为87.23%,远高于其他模型;F1Score最高的是神经网络1为0.814 5。由此认为,基于多层神经网络模型(n1=6,n2=4)构建的财务舞弊识别模型有更好的识别效果。
六、结论与建议
通过以上研究发现支持向量机模型和多层神经网络模型的识别效果较好。本文通过调整支持向量机多项式核函数的伽马值发现,伽马值越大,模型在训练集中识别效果越好,运行时间成本越高,模型会出现过拟合现象。通过调整隐藏层神经元数对神经网络模型进行优化得到了9个识别效果较好的神经网络模型。隐藏层1神经元数为13,隐藏层2神经元数为10时,模型在测试集中正确率最高;隐藏层1的神经元数为6,隐藏层2的神经元数为4时,模型的F1Score值最接近1,模型整体识别效果最佳。对比支持向量机模型和神经网络模型后得出研究结论:基于多层神经网络模型建立财务舞弊识别模型的识别效果更佳。
对财务信息使用者而言,识别一个公司是否存在财务舞弊行为时,应当重点关注以下财务指标和非财务指标:财务杠杆、综合杠杆、流动资产周转率、股东权益周转率、流动比率、速动比率、资产负债率、营业总成本增长率、管理费用增长率、营业成本率、十大股东持股比例、审计意见等。上市公司主要是通过提前确认收入和虚构关联方交易来虚增收入、跨期调节费用或将费用往长期资产类科目挂账来减少负债、调减产品成本、虚增利润等方式进行财务舞弊。公司应当加强内部控制,合理增加董事会会议次数,提高公司治理效率。审计人员在对上市公司进行审计工作时,应当重点关注以上财务指标和非财务指标,并出具合理的审计意见。政府部门应当加大监管力度,同时加重对财务舞弊公司的处罚力度。
