移动应用评论挖掘研究综述
2021-01-23张季康乐乐李博
张季 康乐乐 李博

摘要:[目的/意义]用户评论有助于开发者实现移动应用创新,通过对移动应用评论挖掘相关文献进行归纳总结,为移动应用开发和评论挖掘提供借鉴。[方法/过程]利用文本分析方法,将移动应用评论挖掘相关研究归纳为评论分类、评论聚类和评论特征抽取3个关键主题,并基于此框架阐述该领域的发展状况。[结果/结论]研究得出:评论分类方法已开始从机器学习向深度学习演变;评论聚类主要使用K-Means和DBSCAN;特征抽取仍以评论的显式特征为主。未来,移动应用评论挖掘仍有3个问题值得探究,分别是领域依赖性、多源信息融合以及评论价值评估。
关键词:移动应用 评论挖掘 评论分类 评论聚类 特征抽取
分类号:TP391.1
引用格式:张季, 康乐乐, 李博. 移动应用评论挖掘研究综述[J/OL]. 知识管理论坛, 2021, 6(6): 339-350[引用日期]. http://www.kmf.ac.cn/p/266/.
1 引言
随着移动互联网的发展和移动设备的普及,移动应用(简称APP)已经成为日常生活中不可或缺的一部分。自苹果公司2008年7月份发布App Store、谷歌公司2008年10月份推出Android Market(2012年更名為Google Play Store)之后,移动应用如雨后春笋般涌现出来。经过10多年的发展,Google Play Store已有超过345万款应用,Apple App Store也有近220万款应用[1],这些应用从社交媒体到新闻资讯、从商务办公到娱乐消遣、从医疗健康到学习教育、从在线购物到金融理财,涵盖了人们生活中的众多场景。2020年,受新冠肺炎疫情的影响,人们使用移动设备的习惯向前推进了2-3年,移动应用下载量达到了2 180亿次,每个用户日均使用移动设备的时长超过了4小时[2]。
移动应用的巨大需求量给APP开发者带来无限机遇的同时,也给开发者带来了巨大的挑战。第一,移动应用商店具有明显的开放性特征[3]。在商店中,关于某一应用的功能描述、用户评论、更新文档等都是公开可见的。这意味着应用一旦发布,就面临着被模仿甚至被抄袭的风险。第二,需求分析具有典型的阶段性特征。应用程序都是针对当时的需求开发的,但在与移动应用交互的过程中,用户会不断产生新的需求。第三,市场竞争异常激烈。在特定的细分市场上,功能高度相似的应用少则数款、多则数十款,用户可以轻易地从一款APP转移到另一款APP[4]。
对于移动应用而言,创新一直以来都被认为是获得竞争优势的关键来源[5-6]。根据新颖程度,创新可分为突破式创新和渐进式创新[7]。突破式创新是设计一个全新的产品或提出产品设计的新方法,是从0到1的过程;渐进式创新是对现有产品进行持续不断的迭代优化,是从1到N的过程。移动应用创新更多的是从1到N的过程,即对APP进行长期的维护和改进。不同于实体产品的创新,移动应用创新迭代非常快,如Google Play中的应用平均13天更新一次[8]。要在如此频繁更新的情况下获得不错的市场绩效,开发者需要及时地从用户那里收集反馈。用户创新理论最先由希普尔发现并提出,该理论认为在某些行业或领域往往是用户而不是生产商提出具有创意的产品或服务[9]。所以,这些生产商要从传统的以自己为中心的创新转向以用户为中心的创新,要为用户提供平台以激发他们的创造力[10]。
移动应用商店的出现不仅为用户打造了一个绝佳的反馈平台,而且为开发者提供一个汲取知识的创新平台。应用商店允许用户以数字星级(从1星到5星)和开放式文本的形式发表评论[11],其中文本通常由标题和正文组成。在开发应用新版本时,开发者平均会使用50%的信息性评论[12]。所谓信息性评论,是对提高APP质量或用户体验有潜在帮助的评论。然而,对开发者来说,从评论中快速筛选出信息性评论并不容易,主要原因有:①评论数量大,增长速度快。评论数量随着时间的推移会越积越多,Google Play Store中一些热门应用每天会收到500多条评论[13],人工审阅耗时耗力。②信息性评论大约只占总评论数的三分之一[14]。也就是说,评论中包含大量的虚假评论、不相关的评论以及非评论等垃圾评论[15]。③评论文本是有噪声的。用户撰写的文本常常不符合语法,存在拼写错误、缩写、表情包,缺少或乱加标点符号[16]。④不同于其他评论(如新闻评论、图书评论、影视评论),移动应用评论具有强时效性和高价值性,用户针对某一版本发表的功能错误、程序崩溃等评论,若开发者及时响应,将极大地增强用户的身份认同和使用体验。因此,诸多学者致力于探索如何自动从海量的、非结构化的、非正式的评论文本中挖掘有价值的信息,然后将其纳入软件开发环节,以促进移动应用的迭代创新。
学界围绕移动应用评论挖掘取得了众多的研究成果,已有学者对此进行了系统性综述。N. Genc-Nayebi和A. Abran[17]从评论挖掘技术、领域依赖、评论有用性、垃圾评论识别和软件特征提取5个方面展开叙述,揭示了评论挖掘的主要研究问题。但是,该综述的分类体系较为分散,并且由于文献量不足难以对评论有用性和垃圾评论识别进行全面客观的述评。M. Tavakoli等[18]针对评论挖掘技术和工具进行综述,将评论挖掘技术分为有监督的机器学习技术、自然语言处理技术和特征提取技术,并罗列了当时的评论挖掘工具。然而,其缺乏对评论挖掘技术更有深度和广度的分析和归纳。鉴于评论挖掘在移动应用创新领域具有重要的意义,且近几年APP评论挖掘方法已经有了新的进展,所以有必要重新梳理相关文献。
本文主要贡献如下:①筛选出利用用户评论驱动APP创新的相关文献;②利用文本分析方法,将相关研究归纳为评论分类、评论聚类和特征抽取三大类,以期明确该领域的发展现状;③从领域依赖性、多源信息融合以及评论价值评估3个方面进行展望,为未来的研究提供参考。
2 数据来源和研究框架
2.1 数据来源
本研究英文论文选取Web of Science核心数据集中的SCI-E、SSCI、CPCI作为数据来源。在增加每个术语可能的同义词以及对检索结果分析的基础上,确定的检索式为(TS=(“user reviews$” or “consumer review$” or “user feedback” or “user comment$”) and TS= (“mobile app$” or “mobile application$” or “app store$” or “app market$”)) or (TS = (“app review$” or “application review$”)),语言类型为English,时间跨度为2009-2020年,文献类型选择article、review和proceedings paper。然后,筛选出与移动应用创新相关的评论挖掘文章共54篇文献作为研究样本。中文论文选择中国知网全文数据库中的核心期刊作为数据来源,检索式为(su=(‘用户评论 + ‘用户反馈+用户评价) and (‘移动应用+应用程序+应用商店+应用市场+app)) or (su=app评论 + ‘应用评论),时间跨度为2009-2020年。同样,筛选出与移动应用创新相关的评论挖掘文章,整理得到13篇文献。综合67篇中英文文献,对用户评论驱动APP创新的研究进行系统总结。
2.2 研究框架
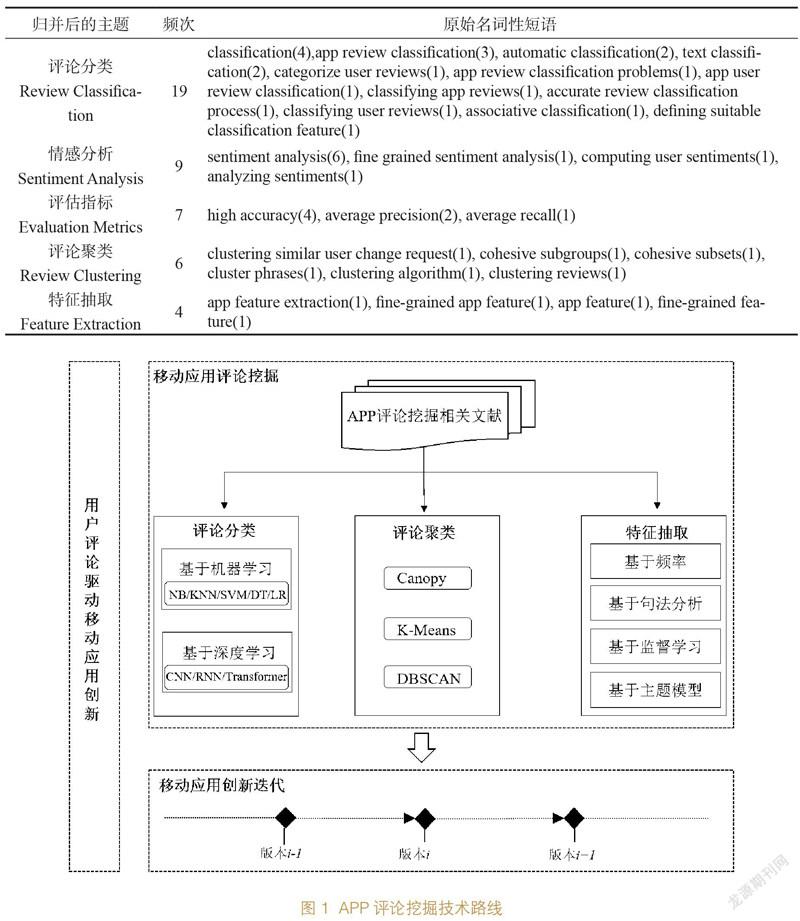
能够表达论文核心内容的关键词或主题词的词频分布可用来研究某一领域的发展现状[19]。笔者利用CiteSpace V[20]从54篇英文文献的标题、摘要、关键词、补充关键词中提取名词性短语,一共抽取了226个名词性短语。作者对统计结果作进一步处理:①删除检索词以及与检索词表达相同含义的短语(如mobile app reviews);②把表达相同主题的短语进行归并;③保留频次大于3的主题,并将主题按频次由大到小排列,如表1所示:
3 评论挖掘
3.1 评论分类
评论分类的目的不仅是要识别出有價值的评论,而且要对评论类型进行更细致的划分。通过对Apple应用商店中528条评论的人工分析,D. Pagano和W. Maalej将其分为17个类别[22],其中大约一半的类别被认为与移动应用创新相关[23-24],如错误报告、功能请求和功能缺陷等。H. Khalid更加关注负面评论,从20个iOS应用的6 390条一星或两星的评论中人工区分出12种类型的用户抱怨,其中功能错误、附加功能请求和程序崩溃等类型对开发者优化APP至关重要[25]。基于机器学习和深度学习的评论分类能够从评论中迅速识别出对开发者有用的评论类型,克服了人工分类耗时长、主观性强等缺陷。
3.1.1 基于机器学习的评论分类
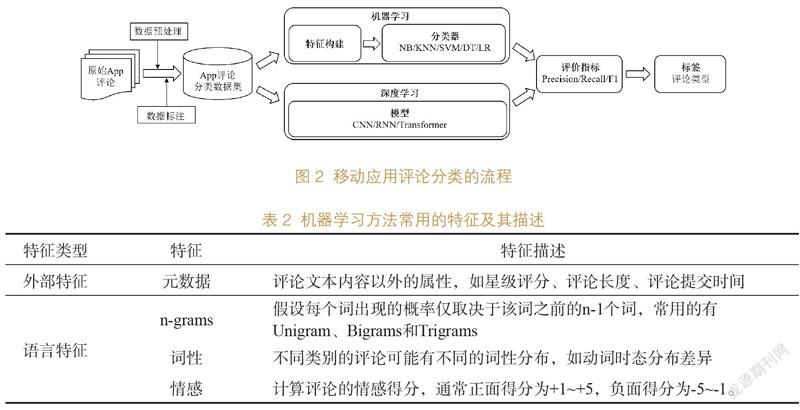
移动应用评论分类的关键流程如图2所示。从图中可以看出,机器学习需要人为构建特征,有意义的特征会显著提高分类算法的性能。移动应用评论的特征可以分为语言特征和外部特征(见表2)。外部特征是指评论文本内容以外的属性,而语言特征主要包括n-grams、词性、情感。在进行评论分类时,主要利用语言特征,辅以评论元数据。常用的评论分类算法包括朴素贝叶斯(Na?ve Bayes,NB)、K-近邻(K-Nearest Neighbor,KNN)、支持向量机(Support Vector Machine,SVM)、决策树(Decision Tree,DT)、逻辑回归(Logistic Regression,LR)。
与单独使用文本分析、自然语言处理、情感分析和评论元数据相比,结合它们会取得更好的结果[24, 26]。W. Maalej和H. Nabil[27]进行了一系列实验来比较简单字符串匹配、词袋模型、自然语言处理(去除停用词和词形还原)、评论元数据和情感分析技术的准确率。研究发现,仅靠元数据会导致分类准确率很低,当与自然语言处理技术相结合时,分类准确率在70%-95%之间,召回率在80%-90%之间。在所有的实验中,多个二类分类器比多类分类器更准确地预测评论类型。次年,W. Maalej等[28]进一步探索,将元数据与词袋模型、自然语言处理(尤其是二元语法和词形还原)结合时,所有评论分类的准确率可达88%-92%,召回率高达90-99%。
由于有监督的方法需要人工标注训练数据,这个过程会花费大量的时间。所以在不影响准确性的情况下,主动学习和半监督学习也受到相关学者的关注。虽然主动学习和半监督学习都用到了未标注的数据,但二者的学习方式不同。主动学习是从未标注的数据中选择最易判断错误的样本交由专家标注,从而最小化训练评论分类器所需的人力,与随机选择的训练数据集相比,主动学习在多个场景下显著提高了预测的准确率[29]。然而,半监督学习是选择最不易判断错误的样本加入已标注数据。胡天媛等[30]综合分析用户评论的内容和句式结构的特点,采用半监督自学习的方式,基于有限数量和类型的评论种子,通过循环的方式自动挖掘出体现使用反馈的APP软件用户评论。为了有效控制用于贬低目标应用或操纵应用排名的虚假评论,D. J. He等[31]提出了一种基于PU学习(Positive-unlabeled learning)和行为密度(behavior density)的方法来检测虚假评论。
还有学者采用集成学习方法,以期通过聚合多个弱监督模型得到一个强监督模型。集成学习算法主要有两种:Bagging和Boosting。通过将朴素贝叶斯、决策树、支持向量机、逻辑回归、神经网络等不同的算法以不同的集成学习算法集成起来,大多数情况下,集成学习的性能优于单个模型[23, 32]。
上述研究依赖于评论的文本属性,这通常会产生高维模型,并可能导致过拟合问题。因此,N. Jha和A. Mahmoud[33]使用语义框架将用户评论分类为用户需求、错误报告和其他,结果表明,语义框架有助于生成更低维、更准确的模型。但是,在评论摘要任务中,基于文本生成的摘要比基于框架生成的摘要更全面[34]。
3.1.2 基于深度学习的评论分类
深度学习相较于机器学习没有显式的特征构建过程,目前已经被广泛应用于自然语言处理问题,并在文本分类任务中取得了很好的效果。王莹等[35]从功能性需求与非功能性需求两个维度出发,对用户评论进行软件需求挖掘,采用TextCNN、TextRNN和Transformer3种深度学习方法,实验结果显著优于传统的机器学习方法。同样,A. Li等[36]提出一种基于图卷积网络的大规模反垃圾评论模型,该模型集成了同构图和异构图来描述局部上下文和全局上下文,线上评估和线下性能都验证了该方法优于利用评论信息、用户特征和商品特征的基线模型。通常来说,深度学习在大量训练数据的情况下会有更好的表现,但在小规模的训练数据上可能并不能取得预期的效果。例如,C. Stanik等[37]使用传统的机器学习方法就获得了与卷积神经网络相当的结果。当然,更复杂的模型也意味着更高的时间成本。
最后,移动应用评论分类往往牵涉训练数据类别分布不平衡的问题,这会造成分类器决策边界偏移,从而在实际应用中效果不佳。现有文献主要采用两种方式:①用代价敏感的学习方法来缓解不平衡数据的影响[38-39],即对不同类型的误分类设置不同的代价;②使用重采样技术来处理不平衡的类[40-41],即对数量多的类进行欠采样(也称为“下采样”)、数量少的类进行过采样(也称为“上采样”)。
3.2 评论聚类
评论分类是根据预定义的类别给评论分配标签,而评论聚类是将相似且没有预先划定类别的评论聚在一起。典型的聚类算法有K-Means和DBSCAN,其中K-Means是基于形心的聚类,而DBSCAN是基于密度的聚类。张莉曼等[42]在Word2vec词向量模型的基础上,结合Canopy和K-Means对评论聚类,即通过Canopy得到聚类簇数,再运用K-Means得到聚类結果,该方法有效识别并聚合了用户需求。不同于广泛使用的K-Means,DBSCAN可以自动确定聚类簇的个数,而不需要预先指定。因此,这种方法也受到了学者的关注。L. Villarroel等[4]采用DBSCAN算法对错误报告、新功能建议两种类型的评论进行聚类,并分别针对这两种类型的聚类簇执行优先级排序。在此基础上,S. Scalabrino等[43]对评论进行了更细粒度的分类,增加了4类非功能性需求:安全问题报告、性能问题报告、过度能耗报告和可用性改进请求。不过,K-Means和DBSCAN在移动应用评论数据集上的优劣有待进一步研究。
3.3 特征抽取
虽然评论分类或评论聚类可以从大量的评论文本中挖掘高价值的评论,但后续仍需开发者人工分析才能知道用户喜欢或讨厌的具体是哪些特征。为了解决这个问题,学者们提出了多种方法以高效地抽取APP特征,进而可以分析用户对这些APP特征的情感。笔者结合APP评论中特征抽取的研究现状,参照B. Liu对属性抽取方法的分类[44],将相关文献划分为4类:基于频率、基于句法分析、基于监督学习和基于主题模型的特征抽取。
3.3.1 基于频率的特征抽取
基于频率的特征抽取通常先利用ICTCLAS、jieba、Standford Parser等自然语言处理工具进行词性标注,然后从标注好的语料中提取出名词、动词等,最后保留大于设定阈值的词作为候选特征[44]。P. M. Vu等[45]从原始评论中提取所有的名词和动词作为关键词,根据评论星级和出现频率对关键词进行排序,以便开发者查找与所需关键词最相关的评论。不过,单个词语只能浅显、零散地表达用户观点,而短语可以提供更完整的信息。于是,P. M. Vu等[46]使用词性组合来提取用户评论中的短语,根据短语之间的相似性度量对短语进行分组,排序并监测这些分组的动态变化,从而帮助开发者获取主要的用户观点。
为了从评论中挖掘出用户高频反馈的特征,不少学者使用关联分析。这一方法的基本假设是:用户在评价APP特征时,用词是比较一致的[47]。因此,那些频繁出现的名词或动词很可能就是APP特征。为了提高特征挖掘的效果,吕宏玉等[48]先利用基于句式匹配和情感倾向识别出特征请求评论,然后通过Apriori关联规则挖掘算法提取软件特征。与之不同,文涛等[49]利用Apriori算法提取特征后,针对每一条评论语句需要进一步识别出其中包含的<特征词, 观点词>对。鉴于传统的频繁项集挖掘算法(如Apriori)计算量大且难以扩展,C. Gao等[50]采用Eclat算法快速获得所有频率大于支持度阈值的候选短语。
3.3.2 基于句法分析的特征抽取
观点词和观点评价对象之间的评价或修饰关系往往能够通过句法关系来表征,而句法分析可以识别这些关系[44],从而实现特征的抽取。句法分析从语法的角度分析词语之间的关系,包括句法结构分析和依存关系分析。Z. Peng等[51]使用Stanford Parser从评论的依存关系分析中提取动名词短语(动词—名词)和名词短语(名词—名词或形容词—名词),然后基于短语与主题之间的相关性,确定作为功能请求的短语。考虑到APP评论描述的内容总是与场景相关,D. Sun等[52]利用评论的短语结构树和依存关系提取核心关注(kernel concern),并为每个核心关注构建聚合场景模型,帮助需求分析人员更完整、更准确地理解用户的真实意图。
3.3.3 基于监督学习的特征抽取
特征抽取任务可以转化为序列标注任务,当前主要的序列标注算法有隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional random field,CRF)。CRF對HMM进行了改进,打破了HMM与实际问题不符的两个基本假设——齐次马尔可夫性假设和观测独立性假设。因此,CRF在特征抽取任务中的表现更为出色,也更为常用[53]。崔建苓等[54]提出基于本体和CRF融合的特征提取方法,并将深度学习Recursive Autoencoder应用于情感分析,最后形成<特征,话题,情感词,句子,极性>的五元组,结果表明RERM(Requirement Elicitation method based on Review Mining)对潜在软件需求类型分类的效果良好,比ASUM(Aspect and Sentiment Unification Model) [55]提供了更多有价值的信息。
3.3.4 基于主题模型的特征抽取
主题模型是一种生成概率模型,其目标是从文档集合中挖掘出其潜藏的主题[56]。当前APP评论挖掘中应用最广泛的主题模型是由D. M. Blei提出的潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)。LDA主题模型利用不同文档中观测到的词来推断文档的主题分布及主题中词的分布[57]。王欣研等[58]通过LDA获取用户评论主题词并运用Glove词向量相似性得到主题语义关联,然后构建出语义关联主题图谱,从而为开发者高效获取用户需求提供了新的思路和方法。近年来,学者们也提出了许多LDA的变体模型用于评论挖掘,如动态LDA[59]、自适应在线LDA[60]、E-LDA[61]等。
除了普遍使用的LDA及其变体模型外,ASUM[55]、非负矩阵分解[62]等主题模型也会被采用。另外,还有部分学者对比了不同主题模型的效果。E. Suprayogi等[63]比较了LDA和非负矩阵分解,从主题连贯性来看,非负矩阵分解的表现更好。C. Gao等[64]比较了潜在语义索引、LDA、随机投影、非负矩阵分解和基于吉布斯抽样的LDA模型,最终基于吉布斯抽样的LDA模型取得了与AR-Miner(App Review Miner)[14]相当的命中率,并实现了动态跟踪排名靠前的评论所反映的主要主题。
现有的主题模型大多基于LDA和概率潜在语义分析,但是这些主题模型对短文本的表现不佳,因为短文本会造成数据稀疏、难以识别歧义词含义等问题[65]。为此,M. A. Hadi和F. H. Frad[66]提出了自适应在线Biterm主题模型,有效缓解了词语共现模式稀疏的问题,可以从APP评论中抽取出更连贯、更高区分度的主题。
4 总结与展望
移动应用商店汇集了大量用户对APP的使用体验和建议,而这些反馈是开发者取得竞争优势的重要抓手,因为用户评论中包含功能缺陷、功能请求等有利于开发者优化APP、提升用户体验的信息。笔者从评论分类、评论挖掘、特征抽取3个方面对相关的文献进行系统性梳理。首先,基于监督学习的评论分类仍是主流,但评论分类方法已经开始从机器学习向深度学习演变,深度学习方法在评论分类任务中的效果往往优于机器学习方法。其次,评论聚类通常作为评论分类的后续步骤,因为特定类别中的评论数量可能有数百条,通过聚类可以进一步降低开发者获取信息所付出的时间和精力。聚类算法有很多,但现有研究还没有比较不同聚类算法或算法的不同设置在移动应用评论数据集上的性能优劣。最后,有关特征抽取的文献主要集中在移动应用评论显式特征的挖掘,主题模型能够在一定程度上解决隐式特征抽取问题,但还需要专门针对APP评论隐式特征抽取进行研究。
未来,移动应用评论挖掘还需要深入研究的问题主要有:
(1)领域依赖性。在不同类别的应用中,词语会呈现出不同的含义,语言模式也有所不同,这使得大多数研究仅适用于特定的实验环境。例如,T. Johann等[67]提出的特征提取方法SAFE(a Simple Approach for Feature Extraction),通过人工分析应用页面和评论,确定了18个词性模式和5种句子模式,并用这些模式来提取应用页面和评论的特征。该方法对于页面维护良好的Google Drive,精度为87%;对于评估的10个应用程序,平均精度为56%。然而,F. A. Shah等[68]将SAFE用于8个不同的数据集(6个APP评论数据集、1个笔记本电脑评论数据集和1个餐厅评论数据集)获得的平均精度远低于论文中报告的性能。因而,APP评论挖掘中如何实现领域迁移是一个具有挑战的研究方向。
(2)多源信息融合。一方面,不同应用商店的管理策略和用户群体存在显著的差异,使得即使是同一APP在不同应用商店中的用户反馈也会有所不同[69];另一方面,开发者不仅需要了解自身应用的优点和缺点,还要时刻关注竞争应用的长处和不足。因此,需要整合不同应用商店的用户反馈以及竞争应用的评论、产品描述和更新文档。除了从应用商店挖掘信息外,还可以收集APP运行时的数据。将应用商店数据和APP运行数据融合在一起,可以更全面地反映移动应用的状态,更准确地把握用户的需求。
(3)评论价值评估。移动应用评论的质量参差不齐,有用评论少、低价值评论多。因此,高效的评论价值评估对于APP开发具有积极的现实意义。当前大多数研究尚未考虑到,APP评论价值的评估不仅仅是一个技术性问题,更是一个理论性问题。需要构建合适的价值评估体系,从多个角度对移动应用评论进行分析。具体而言,可以从评论的信息价值、时间价值、创新价值等多个维度,对移动应用评论进行恰当的评估,以最大限度地挖掘评论的价值,更好地推动APP评论挖掘的演化。
参考文献:
