针对文本情感转换的SMRFGAN模型
2021-01-22宁浩宇梁文韬
李 浩,宁浩宇,康 雁,梁文韬,霍 雯
云南大学 软件学院,昆明650500
风格转移是许多人工智能领域的重要问题,例如自然语言处理(NLP)和计算机视觉[1-4]。特别地,自然语言文本的样式转换是自然语言生成的重要组成部分。它方便了许多NLP应用程序,例如将纸质标题自动转换为新闻标题,从而减少了学术新闻报道中的人工工作。对于诸如诗歌生成之类的任务[5-7],可以将样式转换应用于生成诗歌的冷漠风格。但是,语言样式转换的进展落后于其他领域,例如计算机视觉,这主要是因为缺乏并行语料库和可靠的评估指标。
大多数现有的文本处理方法遵循两个步骤:首先将内容与原始样式分离,然后将内容与所需样式融合。例如文献[8-10]通过对抗训练学习与风格无关的内容表示向量,然后将其传递给依赖于风格的解码器进行重新编排。另一项研究2018年Xu和Lietal直接删除输入中的特定样式属性词,然后将仅包含内容词的中和序列提供给依赖于样式的生成模型。但是,每一行都有其自身的缺点。
为了能提升生成句子的准确性和生成质量,本文提出基于情感记忆模块和强化学习,利用对抗生成神经网络的文本情感转换方法的自注意力情感记忆模块生成对抗神经网络SMRFGAN(Self-attention Memory Reinforcement learning Generative Adversarial Network)。模型一方面通过文本的Fast text[11]处理,有效地提高文本分类的准确性,再通过对长短期记忆(Long Short Term Memory,LSTM)[12]网络解决了RNN[13]的“梯度消失”的不足,同时能够有选择地记忆序列中的重要信息,其中利用自注意力机制对情感词的特征进行识别,有针对性地将情感词放入记忆模块来提升算法对情感词把握的准确性;另一方面通过强化学习算法解决生成对抗神经网络[14]在离散数据中无法运算的问题。
1 相关工作
对文本风格迁移的研究在近年有了较多的进展,例如Luo 等[15]在2019 年提出的基于强化学习框架的文本风格迁移。作者提出了双重强化学习的框架,通过映射模型直接传递文本风格,而不分离内容和风格。在2017年Hu 等[16]用一组结构化变量来增加非结构化变量,每个结构化变量都针对句子的显著且独立的语义特征,以控制句子情绪。然而,所有这些工作和Luo等的研究相比,都试图隐含地将非情感内容与情感信息与时间表示分开。
随着2006年GAN模型的提出,GAN在计算机视觉相关领域获得很好的效果。相关研究者将GAN的研究领域深入到了NLP中,并取得了一些进展。
Kusner 等[17]2016 年在论文中提出为了解决离散数据在分布采样不可导的问题,采用Gumbel-Softmax[18]函数对多项式分布连续逼近,Gumbel 分布是一种极值型分布。Zhang 等[19]在2017 年提出了Text GAN 模型,作者利用LSTM 模型作为GAN 的生成器,用CNN 作为GAN 的判别器,并且用光滑近似的思想来逼近生成器LSTM的输出,从而解决离散数据导致的梯度不可导问题。在判别器的预训练方面,利用原始的句子和该句子中交换两个词的位置后得到的新句子进行判别训练。LSTM虽然解决了RNN梯度消失的问题,但是输入序列和输出序列要求等长,seq2seq 突破了这一限制,使得RNN 的应用更加广泛,在文本生成中也能生成不定长的文本序列。
本文在不使用平行语料库的基础上,通过对情感词的提取利用强化学习算法对生成的反向情感词文本进行改进,提升准确性和BLEU的评分。
2 SMRFGAN模型
在SMRFGAN 模型中,使用Fast Text 分类模型对文本进行分类后,为了定位情感词,将分类后的文本以句向量的方式作为LSTM的输入向量,并用self-attention[20-21]来预测文本情感词极性,从而区分感情词和非感情词,将情感词向量输入到情感记忆模块经过Generalization后放入存储模块当中,以此对情感记忆模块进行更新,最后解码器通过情感记忆模块中存储的情感词和句子表示提取情感词汇进行解码重新组成文字序列,将重新生成的文本作为真实文本对生成器进行预训练,Next action定义下一个被选择的词向量。同时判别器通过蒙特卡洛搜索树和policy gradient算法对生成器进行更新。
以正向情感文本为例,即使用self-attention 将正向情感词汇存储在情感记忆网络中,并依据原文本进行解码,作为真实文本利用强化学习和生成对抗神经网络生成负向情感的文本。SMRFGAN模型框架如图1所示。
2.1 Data-LSTM
在Data-LSTM 模型中,本文首先使用Fast Text 对源文本针对情感词的不同分为积极和消极两类,再使用self-attention机制找出情感词极性较大的情感词存储到情感词记忆模块当中,并结合源文本的句向量生成语义反转后的文本作为接下来RFGAN(reinforcement learning)模型的“真实”数据对GAN进行训练。

图1 SMRFGAN模型图
2.1.1 Fast Text
大多数情感分类方法使用的是朴素贝叶斯分类算法、支持向量机、卷积神经网络和递归神经网络来解决分类问题,而这些方法在语料类别较多的情况下会使得计算量增大。本文为了能有效将情感词存入记忆网络并且能减轻计算量,使用Fast Text快速对源文本进行情感词分类。分类结果处理成句向量作为LSTM的输入,以此为下一步情感词定位及存储做准备。
本文对源文本进行数据预处理,对每一行的数据进行打标,将正向的情感词标记为正类,将负面情感词标记为负类。在Fast Text分类时,为了能对文本准确分类以及能更好地区别句子,例如区分“I don"t like this type of movies,but I like this one”和“I like this type of movie,but I don"t like this one”,本文在一个句子的词向量中加入了3-gram特征。将n-gram特征以及原文的单词作为词向量作为Softmax输入以达到分类目的。
2.1.2 Multi-head attention
本文使用多头注意力机制(Multi-head attention)赋予情感词极性权重从而提取文本中情感词极性较大的词向量并存储到接下来的情感记忆模块中。
本文将分类后的文本处理为句向量,作为注意力机制中Query、Key、Value 的输入。经过线性变换后,将经过放缩点积注意力的结果进行拼接来作为多头注意力机制的结果。注意力机制模型图如图2 所示。用以下公式表示:


图2 多头注意力机制图
2.1.3 记忆网络
传统的RNN/LSTM等模型的隐藏状态或者Attention机制的记忆存储能力太弱,无法存储太多的信息,很容易丢失一部分语义信息,使用记忆网络(memory networks)[22-23]通过引入外部存储来记忆信息,提高在文本生成后能有较高的文本保存率。Memory network 框架图如图3所示。

图3 记忆网络框架图
使用正向记忆模块和负面记忆模块对相应的情感记忆模块进行更新,最后解码器通过模块中存储的情感词中提取最符合句子表达的情感词汇进行解码,将重新生成的文本作为真实文本利用强化学习和生成对抗神经网络生成另一种极性的文本。具体在2.3节中进行介绍。
2.2 定位情感词模型
在一句文本中,情感词有很多,但每个情感词表示的情感程度不同,首先找到对情感极性拥有最大判别力的情感词。这一工作是通过情感文本分类器和自注意力(self-attention)来完成的。
为了能连接上下文,并体现情感词极性在文本中的重要性,将at和LSTM中的隐藏层做积乘得到句向量,并将句向量c 作为全连接神经网络层的输入从而得出源文本中的情感词极性的预测,其中at表示了第t 个单词的注意力(attention)权重。用以下公式表示:

将句向量交给文本分类器以便于区分正面情感文本和负面情感文本。分类器使用Fast Text来处理。在训练中,情感词相较于非情感词会被赋予更高的权重,这样at可用来区分情感词和非情感词。传统的self-attention机制在有多个情感词时,这些情感词的权重由1分配得到,但是,为了能识别最具极性的情感词,需要每个情感词的权重都由1 来分配,为了实现这一目的,将传统的self-attention中分配权重的函数Softmax改为了sigmoid函数(attention 公式)。虽然sigmoid 函数将每个情感词的权重分配到了0 和1 之间,但是并不能通过这些分配的权重在文本中利用情感词的极性区分情感词和非情感词,所以采用了平均值的方法进行情感词的划分,即将大于平均值的权重分配给1,将小于平均值的权重分配给0。在分配权重后,把定义权重的at重新定义为用ˆ 表示识别的情感词,表示识别的非情感词。
2.3 情感记忆模块
在对文本分出情感词和非情感词之后,情感记忆模块将用来保存情感词性较大的情感词。Encoder 和decoder都使用LSTM网络。
为了把非情感词文本序列输入LSTM的encoder中:如果xi作为文本单词,当接近0 的时候趋近于xi,那么序列就可以当作是非情感词向量的encoder 序列,这样就能满足LSTM 的编码器进行编码。将这一情感词向量作为ht的文本向量输入到LSTM最后一个模块( ht,ct),即作为输入的内容的表示。
为了能使生成的文本情感符合上下文,来自源文本的情感词向量能够使情感词记忆模块进行更新。因为提取出了两个情感词性即正向的情感词性和负向的情感词性,所以用pos ∈Re×∂来表示正向情感词的记忆模块,用neg ∈Re×∂来表示负向情感词的记忆模块,其中e代表的是词向量的大小,∂代表记忆模块的大小参数。
本文以正向情感词为例,用Npos来表示存储正向情感词信息的句向量。将和xi带入公式(3),得到Npos,公式表示为:

随后通过自注意力机制寻找在正向词情感记忆模块矩阵中与相关情感词最贴近的列向量。注意力机制的权重向量用Npos转置矩阵与pos 相乘,并且利用Softmax 函数使乘积散布在0 和1 之间,用w 表示。为了使得正向情感记忆模块pos 进行更新,将存储正向情感词信息的句向量Npos和注意力机制的权重向量w 进行外积得到一个新矩阵,然后和现有的正向情感记忆模块pos 相加,随后得到新的即更新的正向情感记忆模块。公式表示为:

在情感记忆模块的更新中由于关系到和注意力机制的权重向量w 的外积,所以存储正向情感词信息的句向量Npos的更新也显得尤为重要。
气体水合物生成实验体系包括供气系统、温压调节系统、恒温水浴系统和数据采集系统4大部分。图1为水合物生成的实验装置示意图。
2.4 RFGAN模型
为了能有效判断生成数据与真实数据间的损失值,本文使用policy gradient强化学习算法对梯度算法进行优化并用蒙特卡洛搜索树指导GAN生成器每次训练的更新,使GAN 能处理离散型数据以及优化生成器和辨别器。
本文给定一个假定的“真实”数据集,训练一个参数是α 的LSTM 作为生成器模型。用{ x1,…,xt-1,xt} 表示为每一个LSTM长期记忆单元输入的词向量,将这些词向量作为序列输入到LSTM的隐藏层当中,用一个更新函数g 进行递归,并且使用Softmax函数来对隐藏层的输出数据进行概率分配。用以下公式表示:

从而生成序列y1:T=( y1,y2,…,yt,…,yT),并且yt∈Y ,其中Y 表示为存储单词的词典,其中policy模型参数为Gα( yt|Yt-1)。同时也训练一个辨别器(discriminator)用于对生成器进行指导改进。生成器模型通过Policy Gradient和经过辨别器得到的期望值进行更新。
根据Policy Gradient算法,本文生成器的优化目标公式为:
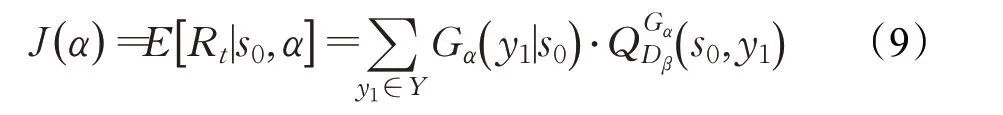
其中,RT表示完整序列的期望值,s0表示初始状态,表示动态取值函数,其函数的定义为:

即对完整序列(Y1:t)进行评估从而得到期望值,Dβ(Y1:t)表示生成的向量序列是“真实”数据的概率并作为期望值。但为了能对任意一个状态的值都有定义,本文使用了蒙特卡洛树搜索办法[24]进行改进,如此便得到了每个阶段的期望值,通过Policy Gradient算法对生成器进行训练。改进后的动态取值函数为:

判别器模型使用的是卷积神经网络(CNN)模型。首先对{x1,…,xt-1,xt}文本的词向量构建矩阵,作为卷积神经网络的最初的输入数据,用公式(12)来表示:

⊕表示对输入的词向量进行矩阵运算,然后通过卷积核对以一个单词为单位的卷积核窗口大小进行特征的提取,公式表示如下所示:

本文使用Dβ判别器作为期望函数的好处在于能动态改进生成模型,一旦生成器生成的序列经判别器判别为接近真实数据的序列,那么判别器的更新公式如下:

即使用对数损失函数进行判别器的训练。
2.5 算法流程
本文算法步骤如下:
步骤1 文本分类
对源文本进行停用词和词性标注,并根据停用词表去除无关词汇。将进行过数据处理后的文本作为CNN的输入层,通过卷积和池化提取文本特征向量,最后通过Softmax函数输出positive和negative两种类别的文本。
步骤2 定位情感词
分别将positive 文本和negative 文本作为LSTM 的输入,在LSTM 的隐藏层中经过公式(1)、(2)输出情感词极性较大的情感词的权重。
步骤3 情感词记忆
通过公式(3)~(6)得到情感词极性权重在平均值以上的句向量并对情感记忆模块进行更新。最后在LSTM的输出层根据上下文解码出极性相反的文本。
步骤4 RFGAN生成文本
将步骤3 生成的文本作为生成器的原始文本并且对生成器和辨别器进行预训练,通过公式(9)对生成器进行优化生成文本。训练时通过公式(10)、(11)对生成的句向量进行评分并通过公式(14)对判别器进行更新。
3 实验
本文使用yelp 评论数据集来进行训练。首先对yelp 数据集用FastText 进行情感词的分类,不同词性的文章用不同的标签来表示。用分类处理后的数据集进行预训练、训练和测试。在用CNN进行情感分类时,准确率达到了93%。
首先定义了预训练过程中生成器的优化器,即通过Adam Optimizer[25]来最小化交叉熵损失,随后通过Data-LSTM网络来产生生成器的训练数据,利用数据读取类来读取每一个batch的数据。同时,每隔一定的步数,会计算生成器与Data-LSTM 的相似性。对于判别器的预训练则是通过生成器预训练完成后得到的负样本和Data-LSTM模型生成的正样本进行结合,来对辨别器进行预训练。
在本文中,将生成器生成的样本即负样本标为0,将通过Data-LSTM模型得到的样本标为1。
3.1 实验设置
为了能使实验收敛,在预训练时迭代次数为120次,在第65 次实验准确度趋于平稳,正式训练迭代150次,在第110 次时实验趋于平稳。在模型Data-LSTM中,bach 的大小为64,学习率设置为0.001,记忆模块的参数∂=60。词向量的维度设置为128。对于不同任务,用不同的卷积层来处理数据,卷积核的大小在1到t之间,每个卷积核的数量在100 到200 之间。本文使用DropOut 和L2 正则化来防止过拟合的发生。在测试阶段,用Gα生成了100 000 个测试数据和预训练时Gα生成的样本进行计算,并取得平均值。
3.2 目标评价函数
用ACC 来表示文本语义转换的准确率,用CON 来表示文本情感转换后文本的保存率,用BLEU[26]来计算输出文本和源文本间的文本保存程度,BLEU 越高,代表模型转换后的文本质量越高,越接近人工翻译水平。目标公式表示如下:

其中,BP 表示惩罚因子,用来解决评分偏向性。BLEU采用加权平均对句子的生成质量进行评估。
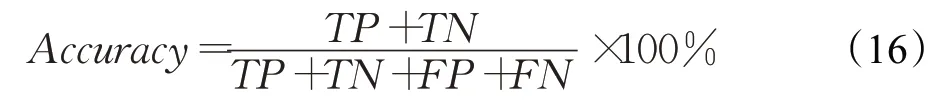
其中,TP 表示实际为正,预测为正的样本数;FN 表示实际为正,预测为负的样本数;TN 表示实际为负,预测为负的样本数;FP 表示实际为负,预测为正的样本数。

doc1和doc2分别表示为源文本和生成文本的共有字符数量,length(doc)表示文本的最长字符数。
3.3 实验结果及分析
本实验与2019年国际人工智能联合会议以及2018年在AAAI 国际人工智能联合会议上发表的文本风格迁移的实验结果进行了对比分析,结果中采用了论文中各个模型的结果与本文结果进行对比。在实验中,SMGAN平均在第15轮的时候准确率开始收敛,而CAE和MAE模型在第25轮左右开始收敛,Retri、BackTrans、Del模型均在15到25轮之间开始收敛,并且SMGAN和其他5个模型对源文本的文本保存率对比也有1%左右的提升。对比结果如表1~3、图4所示。

表1 模型准确率和BLEU对比

表2 对Data-LSTM模型测试
本文对各个模型在三维空间中散点分布进行了对比,从图4可以清晰地看出本文模型在拥有较高的准确率上还保持了高BLEU评分以及高文本保存率。
本文在使用SMGAN 生成文本之前需要利用Data-LSTM模型生成“真实数据”,所以为了测试Data-LSTM模型的有效性对比了加入情感记忆模块和未加入情感记忆模块两种情况下文本生成的精度和BLEU 的性能。如表2所示。

表3 对比模型生成句子示例

图4 各模型散点对比
表3 中显示了由不同模型生成的几个随机选择的示例句子,这些示例能清楚地表明本文提出的模型可以生成与基线相比在输入文本上更具语义相关性的句子。
由表1 和表2 可知两种对比模型的准确率都比较高,但是BLEU 值却比较低,很大的可能是因为在不使用平行语料库的情况下,试图将情感词向量与句向量中的情感词信息进行分离,导致了只是输出具有目标情绪的句子。而Data-LSTM 模型因为使用了self-attention机制,明确地删除了情感词,从而对源文本的内容的保护有了较大的改进。而从加入情感记忆模块和未加入情感记忆模块的对比中可以看出在加入了情感记忆模块后,准确率有62.39个百分点的改进,这体现出了情感记忆模块是保证文本情感转换的重要部分。
对比表3 得到的句子生成示例,相比之下,本文模型使得输入的文本具有更高的语义相关性。CAE 模型通过学习与风格无关的内容来表示成向量,MAE 模型通过删除特定样式属性词进而很好地保留内容。但是当输入的句向量中含有隐式表达样式时,这两个系统可能会不能很好地训练出成功的示例。而本文的模型在保持内容和保持准确率以及提升BLEU 评分的工作上实现了较好的平衡。
4 结束语
本文针对语义反转中不使用平行语料库以及针对生成对抗神经网络生成文本加入了情感记忆模块进行改进。本文先使用FastText 文本分类方法对源文本进行情感分类,然后通过self-attention 方法对分类后的正向情感文本和负向情感文本分别通过权重的大小提取具有最大情感极性的情感词,接着将这些情感词分别放入positive记忆模块和negative记忆模块,再通过解码的方式输出文本作为生成对抗神经网络预处理的数据。生成器通过强化学习中的policy gradient算法反馈一个权重值,通过这个权重来更新生成器的参数,辨别器则通过MC search reward 算法立即评估当前得到的词向量的好坏,从而对判别器进行更新优化。通过对比实验可以看出本文的方法对数据集情感转换的BLEU 和Accuracy 明显的提高,但本文方法还有很大的提升空间,如何使文本内容和风格一起进行转换,从而达到更好的不同模型间的优势互补是下一步工作的重点。
