面向主题社团的意见领袖挖掘方法
2021-01-22陈淑娟徐雅斌
陈淑娟,徐雅斌
1.网络文化与数字传播北京市重点实验室,北京100101
2.北京信息科技大学 计算机学院,北京100101
近年来,Facebook、Twitter、微博等社交网络已经成为人们沟通交流的重要渠道。每个社交网络都存在着意见领袖,意见领袖在敏感信息、舆情、热点话题的传播过程中扮演着关键作用,具有较大的社会影响力。
分析发现,在每个社交网络中,围绕着意见领袖自然形成若干个不同的社团,而每个社团往往具有一个或多个交流和讨论的主题。因此,意见领袖的挖掘与主题社团是密切相关的。研究如何面向主题社团挖掘意见领袖对热点事件传播,舆情管控具有重要的意义和研究价值。
针对上述分析,本文提出了一种基于主题相似度的多标签均衡社团划分算法和快速意见领袖挖掘算法QMOLA。首先采用I-LDA 计算主题分布,并籍此计算出主题相似度。并利用主题相似度排序,确定节点标签传播更新的顺序,再结合邻居节点间的相似度和社团标签信息更新自身的社团标签信息,由此划分出高稳定性的主题社团;然后针对某一主题社团,根据结构特征排除粉丝数、关注数和VIP 等级较低的用户,确定候选人集合;最后,根据候选人的传播特征和情感特征计算用户影响力,挖掘TOP- K 个意见领袖。整体算法的框架流程图如图1所示。
(1)提出了一个I-LDA 模型,将粉丝类别属性作用于LDA 模型,由此可抽取出主题表达能力更强的主题词,使得主题识别效果更好。
(2)针对同一社团的用户经常发布相同或相似主题文本内容的特点,采用基于主题相似度的多标签均衡社团划分算法划分主题社团,相对已有的社团划分方法,有效提高了社团划分的准确性。
(3)提出了意见领袖快速挖掘算法QMOLA,不仅可以减少计算全部用户影响力的时间,提高效率,而且还可提高社团中意见领袖挖掘的准确性。
1 相关工作
对于社团划分的研究,姜昊等[1]提出了Fast-Newman算法,不同于传统的分裂式社团划分算法GN[2],该算法先将每个用户初始化一个单独的社团,再采用贪婪算法合并社团,实现复杂网络的快速社团划分。Liu等[3]提出了一种基于局部最优扩展内聚思想的社区发现算法,先使用最重要的节点及其邻接节点初始化核心社团,再通过节点隶属度对核心社团进行扩展。文献[4-6]提出基于节点重要性的多标签传播重叠社团发现算法,先采用LeaderRank 或PageRank 计算出节点的影响力,再使用多标签传播算法划分社团。赵雨露等[7]在采用标签传播算法划分社团的基础上,采用最大社区节点数控制社团规模。欧阳骥等[8]提出采用主题划分与链接划分的社团发现算法,先采用隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型对社团进行主题划分,再应用模块度社团发现算法对社团进行链接划分。翟菊叶等[9]提出一种主题社团混合模型(On-line Topic and User Combine Model,OTUCM)模型的网络社团演化识别方法,把社团识别转换成主题识别,并引入时间因素,实现动态社团划分。
对于意见领袖挖掘的研究,文献[10-12]主要根据核数、粉丝数、接近中心性、转发数等节点的结构特征挖掘意见领袖。郭博等[13]采用层次分析法确定用户的粉丝数、关注数、活跃度和可信度各个指标的权重,并基于PageRank算法挖掘意见领袖。Qiu等[14]根据用户评论进行文本挖掘,并通过引入时间特征改进PageRank 算法来挖掘意见领袖。陈振春等[15]通过研究用户的粉丝数、跨社团数等结构特征和用户行为特征计算节点影响力,并挖掘意见领袖。肖宇等[16]通过分析用户回帖的情感倾向,采用LeaderRank算法计算意见领袖排名。徐郡明等[17]根据用户的情感倾向和活跃程度改进LeaderRank 算法挖掘意见领袖。Duan等[18]先采用聚类算法将用户聚类,再对用户进行情感分析,由此挖掘意见领袖。
综上可以发现,现有的方法采用LDA 主题模型对文本提取主题并计算主题相似度,但是提取出的主题词倾向于选择高频词,而主题表达能力强的低频词被分配到各主题的概率比较低。现有的方法划分社团常采用分裂或聚合的方式将关系密切的用户划分在一个社团内,将关系不密切的用户分离,但是忽略了用户间的主题相似影响,不能准确地划分主题社团。现有的意见领袖挖掘方法计算结构特征、行为特征或情感特征对PageRank算法进行改进计算影响力,但是并未考虑到用户在每个主题社团下的影响力是不同的。并且计算全部用户的影响力值,并对其进行排序,导致耗时较长,计算效率需进一步提高。
2 主题社团划分
2.1 主题提取

图1 整体算法的框架流程图
LDA 主题模型的基本思想是将多个不同的主题按照一定的概率分布生成文档,其中多个不同的词按照一定的概率分布生成主题,从而挖掘文档中隐藏的主题信息。标准的LDA 模型是一种基于文档-主题-词语的三层贝叶斯模型,可以得到“文档-主题”和“主题-词项”两个概率分布。
LDA 模型以离散的词频作为输入,并且语料库中单词的重要程度只有词频相关。由于文档中公用词和停用词几乎出现在所有主题下,而LDA 模型会赋予在部分文档中出现频率低而在语料库的其他文档中出现频率高的单词一个较高的值,而赋予在整个语料库所有文档中出现频率很低的单词一个较低的值。因此,当使用LDA 模型提取文本中的主题词时,容易出现向高频词倾斜的现象,因而主题表达能力强的低频词分配到各主题中的概率就会比较低,主题表达能力弱的高频词分配到各主题中的概率往往会比较高,由此降低了模型的主题识别效果。为了能抽取到主题表达能力强的主题词,使主题识别效果更好,本文提出了一个I-LDA模型,如图2所示。
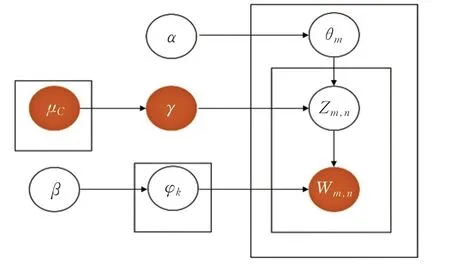
图2 I-LDA模型
基于I-LDA 模型的主题挖掘方法的过程:(1)根据用户的粉丝博主分布比例作为用户的兴趣属性矩阵,将其作为I-LDA 模型的输入文档之一;(2)对微博文本进行预处理,包括去短文,分词,以及去停用词,形成规范的文本语料库,得到词汇表和文档-词汇矩阵,作为ILDA 模型的输入文档之一;(3)采用I-LDA 模型对文本语料进行文本表示,在利用Gibbs抽样过程中,使用兴趣属性矩阵对文章-主题矩阵以及主题-词矩阵进行加权迭代,由此得到文章-主题分布矩阵和主题-词分布矩阵。
在主题数为K 的情况下,语料库中包含M 篇文档,每篇文档中包含词汇Wm,n,每个用户包含C 个兴趣属性。首先,对于任意一篇文档m,使用Dirichlet 分布作为主题分布θm的先验分布,其中α 是分布的超参数,θm表示文档m 属于K 个主题的概率。对于任意一个主题k,使用Dirichlet分布作为词分布φk的先验分布,其中β 是分布的超参数,φk表示主题k 对于N 的词的概率。
然后,对于文档m 中的每个词w 进行如下操作:根据每一篇文档中主题的多项式分布和兴趣参数对主题词的加权处理,不断调整主题分布,最终得到这篇文章的主题分布Zm,n。根据每一个主题中词的多项式分布和兴趣参数对词项的加权处理,不断调整词分布,最终得到K 个主题下的词分布Wm,n。重复此过程,遍历文档中所有的词汇,直到生成所有文档的主题。最后采用快速Gibbs 抽样对超参数α 和β 进行迭代估计,得到ILDA的联合概率分布如式(1)所示:

迭代循环最终得到文档m 的主题分布和主题k 的词分布的期望公式:
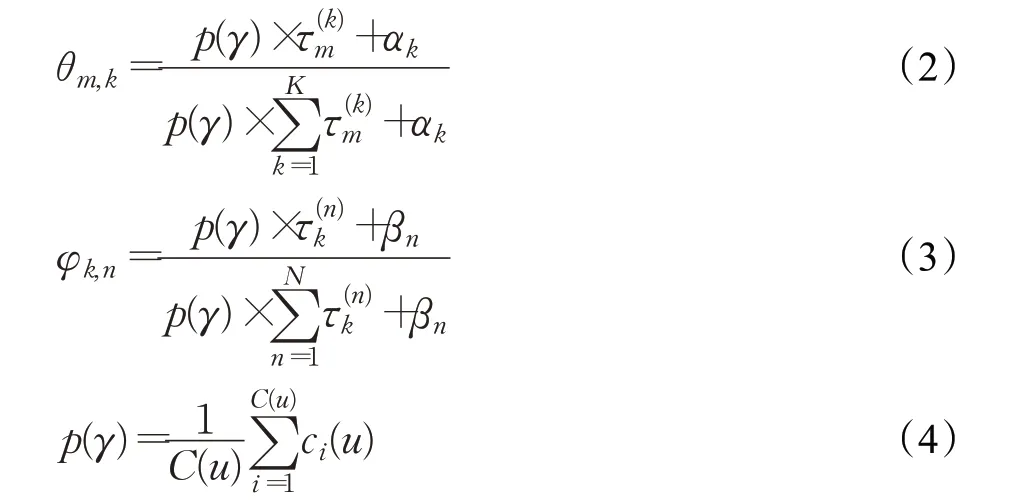
一般可以根据用户的标签信息判断用户的兴趣。但是用户往往并不及时更新自己的信息资料,所以以标签信息表示用户的兴趣缺乏时效性。以微博为例,大V用户经过微博认证分类,并且关注自己感兴趣的用户,所以可根据粉丝的认证博主分类推测用户的兴趣。博主分类为44种类型,如表1所示。

表1 粉丝博主分类类型
由此,用户u 的兴趣属性可由interest(u)=[c1(u),c2(u),…,c44(u)]表示。ci(u)表示用户u 的第i 类粉丝博主的比例,计算公式如式(5)所示:
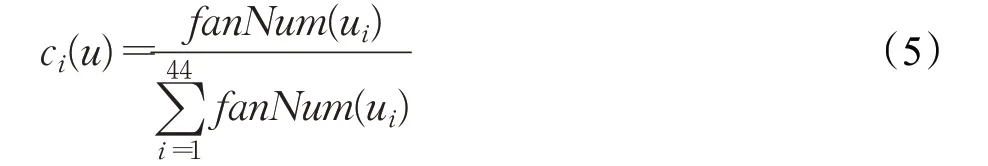
其中,fanNum(ui)表示用户u 的第i 类粉丝博主数量。
2.2 主题相似度计算
通过I-LDA模型进行主题识别后,得到所有用户及其主题构成的用户-主题矩阵(User-Topic Matrix,UTM)如式(6)所示:

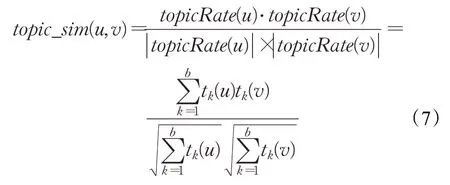
其中,a 表示用户的个数,b 表示主题的个数。用户(u,v)的主题分布可使用VSM表示:topic_rate(u)={t1(u),t2(u),…,tb(u)},topic_rate(v)={t1(v),t2(v),…,tb(v)}。两用户(u,v)的主题相似度可采用公式(7)所示:
2.3 基于主题相似度的多标签均衡社团划分算法
多标签均衡传播算法是一种快速划分社团的半监督学习算法。标签的格式为(c,r),其中c 表示节点属于c 社团,r 表示节点属于c 社团的从属系数,每个节点可以拥有多个标签,并且多个标签的从属系数之和为1。均衡传播指在网络中,若存在一些已标记节点和未标记节点,将已标记节点的标签信息传递给相邻的未标记节点,引入阈值p 判断未标记节点是否保留传递得到的标签,以此更新自身标签信息并转换成已标记节点。但是也存在一些问题:
(1)节点更新标签的顺序是随机的,可能会出现未标记节点预测已标记节点的标签信息的现象。
(2)更新节点标签时,认为节点接收每个邻居节点标签的概率是相同的,忽略了节点与不同邻居节点之间的相似度对标签传播的影响。
(3)当邻居节点拥有多个从属系数最大的标签时,算法采用随机的方式保留标签,使得社团划分存在一定的随机性,导致划分的社团结构不稳定。
为了解决上述三个问题,提高社团划分的准确性和保证社团结构的稳定性,本文对已有的多标签传播算法进行改进,提出了一种基于主题相似度的多标签均衡社团划分算法如算法1所示。
算法1 基于主题相似度的多标签均衡社团划分
输入:用户节点集合U ,用户的主题相似度。
输出:主题社团集合S。
(1)每个节点ui设置一个各不相同的标签(c,r)。
(2)将主题相似度从大到小排序,确定标签更新的顺序,并设定阈值参数p。
(3)更新节点ui的标签时,接收邻居节点传递的标签。计算每种标签的社团从属系数与相似度乘积之和,确定最大值bmax。
(4)节点ui计算每种标签的乘积之和与bmax的比值,将比值与阈值p 进行比较,保留大于p 的标签。
(5)节点ui对标签的社团从属系数进行标准化,使得所有标签从属系数之和为1。
(6)如果社团中的最少节点数不再变化,则算法停止,否则继续重复步骤(3)~(5),对其余节点进行标签更新操作。
(7)将拥有相同标签的节点划分到一个社团中,从而实现主题社团划分。
通过上述算法即可得到主题社团集合S。在算法中,步骤(1)、(2)为准备阶段,完成节点的标签初始化、确定节点的标签更新顺序和设置阈值p 三部分。步骤(3)~(6)为标签更新阶段,每个节点按照更新的规则迭代更新自己的标签。步骤(7)为收尾阶段,统计和整理节点的标签,划分主题社团。
3 快速意见领袖挖掘
主题社团形成之后,挖掘主题社团中的意见领袖的关键在于综合分析各个维度的特征对用户影响力的作用结果。基于对意见领袖的特征进行深层次分析,本文从结构特征、传播特征和情感特征三个角度挖掘意见领袖。
3.1 结构特征分析
结构特征不仅指用户个人因素,还指其所处的网络拓扑结构因素,在微博中可由粉丝数、关注数、VIP 等级,接近中心性等属性表示。但是,由于采集的数据集不能准确再现用户在微博中的网络拓扑结构,对接近中心性的计算存在差异。为此,本文主要从粉丝数、关注数和VIP等级三个因素计算用户的结构特征值INF_S。
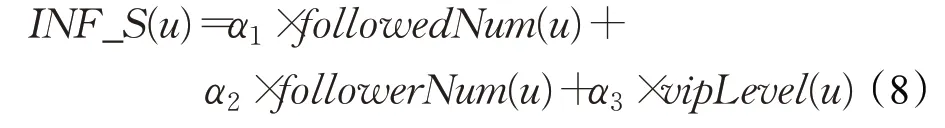
其中,followedNum(u) 表示用户u 的粉丝数,followerNum(u)表示用户u 的关注数,vipLevel(u)表示用户u 的VIP等级,α1~α3表示对应属性的权重。
每种属性数据具有不同的量纲,数据间差异较大,不能直接参与计算,因此需要对数据进行标准化处理,使得数据指标之间具有可比性。本文采用min-max 标准化对数据进行线性转换,将结果映射到[0-1]之间,转换函数如下所示:

通过AHP层次分析法确定每个属性的权重参数值。
首先,通过对1 043个用户进行结构特征分析,可以发现,用户可以选择不关注其他用户,但不能阻止其他用户关注自己,因此粉丝数相对于关注数稍微重要,另外,VIP 等级越高,影响力越强,因此VIP 等级相对于粉丝数和关注数较强重要。然后,根据两两属性之间的重要程度,得出层次判别矩阵如表2 所示。最后,通过一次性检验得到各个属性权重如表3 所示。从表中可以看出,VIP 等级、粉丝数和关注数的比例约为6∶2∶1,符合用户的结构特征分布。

表2 结构属性权重的层次判别矩阵

表3 结构属性权重设置
3.2 传播特征分析
传播特征指用户在一段时间内发布的微博数和微博被点赞、被转发和被评论的数量。为了表示时间对传播特征的影响,本文选取用户在24小时内的发博数、被点赞数、被转发数和被评论数计算用户的传播特征值INF_P。
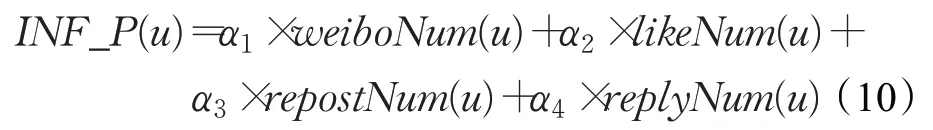
其中,weiboNum(u)表示用户u 发布的微博数,likeNum(u)表示用户u 的被点赞数,repostNum(u)表示用户u 的被转发数,replyNum(u)表示用户u 的被评论数,α1~α4分别表示对应属性的权重。
首先,通过式(9)的转换函数对数据进行min-max标准化转换;然后,对用户进行传播特征分析,发布微博越多,其微博有更大概率被转发,因此微博数相对于其他三者较强重要,转发数越高,则微博更能广泛传播,因此转发数相对于点赞数稍微重要,对微博进行评论,更能体现对该条微博的认同,因此评论数相对于点赞数较强重要,相对于转发数稍微重要。其次,通过层次分析法确定每个属性的权重参数值,得到层次判别矩阵如表4 所示;最后,通过一致性检验得到各个属性的权重如表5所示。从表中可以看出,微博数、评论数、转发数和点赞数的比例约为7∶4∶2∶1,符合用户的传播特征分布。
3.3 情感特征分析
用户发布的微博往往受到粉丝或者路人的评论,对用户发布微博的正向评论越多,越能体现其受尊重和受欢迎的程度,越能增加作为意见领袖的概率。反之,反向评论越多,则说明其不受尊重和不受欢迎的程度,越能降低作为意见领袖的概率。为此,本文以微博评论的情感极性作为用户的情感特征,极性判别步骤如下:
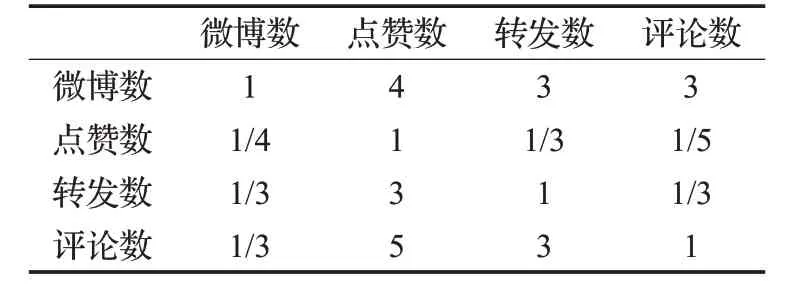
表4 传播属性权重的层次判别矩阵

表5 传播属性权重设置
(1)用SVM模型训练已标注好的语料,对参数进行调优。
(2)预处理,剔除微博评论中的特殊字段。例如,“http://www.qzjcj.com”“#话题#”“回复@用户名:”“//@用户名:”“@用户名”等。
(3)采用jieba 分词器对预处理过的评论进行分词和加载停用词表,去除评论中的停用词。
(4)用word2vec 模型训练每条评论,得到每个词的高维向量,然后根据情感词典选取每条评论中的特征词,将特征词的向量相加后求平均,得到每条评论的句子向量。
(5)使用训练好的SVM 模型对句子向量进行极性分类。
情感极性分析结束后,统计每个用户正、负向评论的条数,采用公式(11)计算用户的情感特征值INF_E。参数分别取1、-2,能够明显区分用户正向评论数与负向评论数。

3.4 快速意见领袖挖掘算法
通过研究发现,意见领袖一般具有明显的结构特征,然而具有明显结构特征的用户不一定是意见领袖。此外,意见领袖的影响力不仅表现在微博被转发或评论的次数,还表现在粉丝对其微博的支持态度。为了快速和准确地挖掘主题社团中的意见领袖,本文提出了快速意见领袖挖掘算法QMOLA,先根据结构特征筛选出候选人,后根据传播特征和情感特征计算影响力,从候选人中选取意见领袖。
本文在网页排名算法PageRank 的基础上,添加用户的传播特征和情感特征,提出了如式(12)所示的用户影响力(User Influence,UI)计算公式。
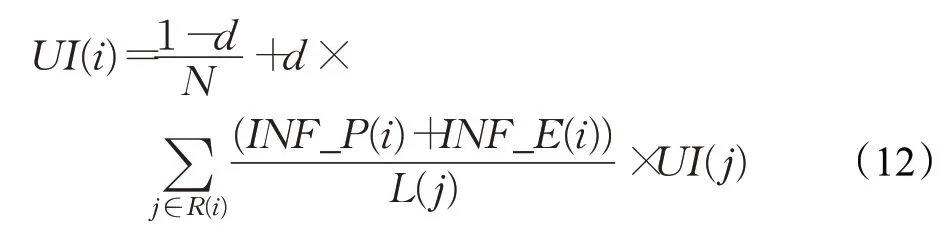
其中,d 为阻尼系数,取值为0.85;N 表示全部节点的数量,表示用户i 被选为候选人的粉丝集合;L(j)表示用户j 关注的且被选为候选人的用户集合;INF_P(i)表示用户i 的传播特征值;INF_E(i)表示用户i 的情感特征值。
UI 计算公式的提出借鉴了PageRank 算法的思想,认为一个用户的影响力不仅与其传播特征和情感特征有关,而且还与其粉丝的影响力有关。由PageRank 算法的质量假设可知,越是质量高的页面指向页面A,页面A 越重要。所以,若粉丝的影响力普遍很高,且对该用户的意见普遍赞成,则表明对此用户的影响力贡献越大。因此,UI计算公式不仅分析深层次的影响因素,同时还保持了PageRank 算法的优势。算法步骤如算法2所示。
输入:节点集合U ,关系集合E,主题社团集合S。
输出:节点影响力排名。
(1)根据用户的粉丝数、关注数和VIP 等级计算结构特征值INF_S。
(2)将社团中每个用户的INF_S 从大到小排序,选取h 个用户组成候选人集合H 。
(3)计算候选人集合H 中的每个用户的传播特征值INF_P 和情感特征值INF_E。
(4)根据UI公式计算出用户的影响力值UI 。
(5)将候选人的UI 按照从大到小的顺序进行排序,选择前K 个用户作为意见领袖TOP-K 。
4 实验
4.1 实验数据与实验环境
本文从新浪微博平台上采集实验数据,按照广度优先的策略,从微博昵称为“人民日报”“央视体育”“新浪财经”“圈内星探”“新浪军事”“央视新闻”“新浪娱乐”七个用户开始爬取数据,爬取用户的个人信息和2019-03-18—2019-03-20三天内发布的微博。针对每条微博,先爬取评论内容、点赞数和转发数等数据,再爬取其粉丝用户,将这些用户继续添加至待爬取队列。对一个用户的数据爬取结束之后,继续对下一个用户进行同样的操作,重复此过程,直至爬取1 043 个用户的信息,则爬虫停止。
叶总接过话茬:“这么看来,我猜的就八九不离十了。老贾成功骗过我们之后,就剩下钓你教授上勾了。那天我提前离开酒席之后,他怕夜长梦多,便用钱盒子为饵,促成交易。仔细想想,看来老贾真的是以为这个盒子不太值钱,所以才把它当陪衬送给了陆教授。”
该数据集中包含1 043个用户的个人信息、1 124条用户关系、95 447条微博信息以及296 881条评论信息。另外,进行情感分析时,需要借助情感词典,本文的情感词典包含7 339个正向情感词和12 956个负向情感词。
本文的实验环境如表6所示。

表6 实验相关环境
4.2 主题划分实验
4.2.1 评价指标
困惑度指所训练出的模型将一篇文章归属于哪个主题的不确定性。困惑度越小,说明聚类的效果越好。
4.2.2 对比实验
为了验证本文提出的I-LDA 模型对于主题聚类的能力,与I-LDA模型在困惑度上进行对比实验。在相同的实验环境下,对比结果如图3所示。
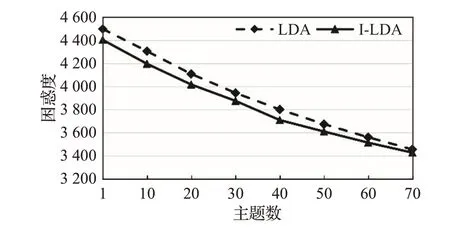
图3 困惑度对比实验结果
从图3中可以看出,本文提出的I-LDA模型困惑度的值明显低于LDA 模型的困惑度值,进一步说明了I-LDA模型的性能优于LDA模型,将用户的兴趣属性融入LDA模型中在一定程度上提升了主题聚类的精确度。
4.3 快速意见领袖挖掘实验
4.3.1 评价指标
(1)时间指挖掘社团中意见领袖消耗的时间,采用计算用户结构特征、传播特征和情感特征的总时间表示。
(2)覆盖率指从信息扩散角度衡量意见领袖的影响力,采用社团内转发意见领袖微博的用户数与用户总数的比值来表示。
(3)支持率指从情感角度衡量意见领袖的受支持程度,采用社团内正向评论的用户数与用户总数的比值来表示。
4.3.2 对比实验
将本文提出的QMOLA与文献[19]提出的多维特征的意见领袖挖掘方法在挖掘时间上进行比较。在相同的实验环境下,两种方法的对比结果如图4所示。
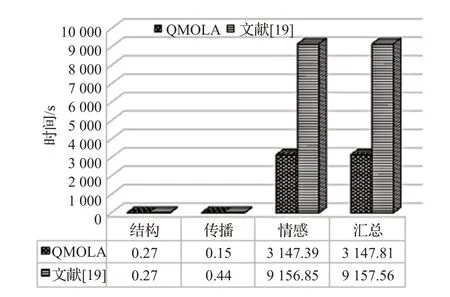
图4 挖掘时间对比实验结果
从图4中可以看出,两种方法都计算全部用户的结构特征,耗时相同。之后,本文提出的QMOLA 只需计算候选人的传播特征,与文献[19]计算全部用户的传播特征耗时相差0.29 s。但是,两种方法计算情感特征时,耗时相差明显。并且从时间复杂度上分析可知,文献[19]的时间复杂度为O(n3) ,而QMOLA 的时间复杂度为O(n+n2)。所以,在保证挖掘意见领袖准确率的前提下,本文提出QMOLA 比文献[19]挖掘意见领袖的效率更高。
为了验证本文方法的有效性,与PageRank和SRank方法在覆盖率上进行对比实验。在相同的实验环境下,对比结果如图5所示。
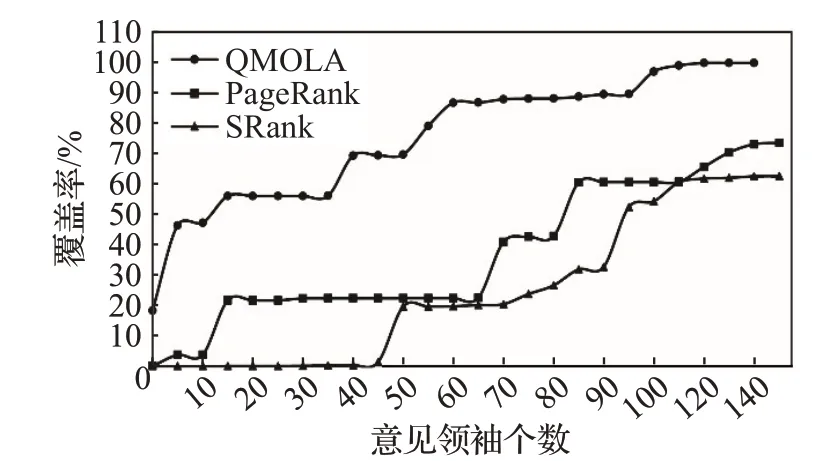
图5 覆盖率对比实验结果
从图5中可以看出,SRank只考虑了情感特征,忽略了好友的影响,导致挖掘出的意见领袖覆盖率最低。PageRank方法体现了用户之间的相互影响,比SRank具有稍好的优势。而本文提出的QMOLA 是在PageRank的基础上,不仅考虑用户之间的相互影响,而且还结合了用户的传播特征和情感特征,因此,效果明显优于PageRank和SRank方法。当选取的TOP-K 较小时,采用QMOLA挖掘出的意见领袖具有更高的覆盖率和影响力。
为了进一步验证结构特征、传播特征和情感特征对节点影响力的影响,本文将QMOLA与根据结构特征和传播特征计算影响力的方案1 以及根据结构特征和情感特征计算影响力的方案2进行对比,选择支持率作为评价指标。在相同的实验环境下,对比结果如图6所示。
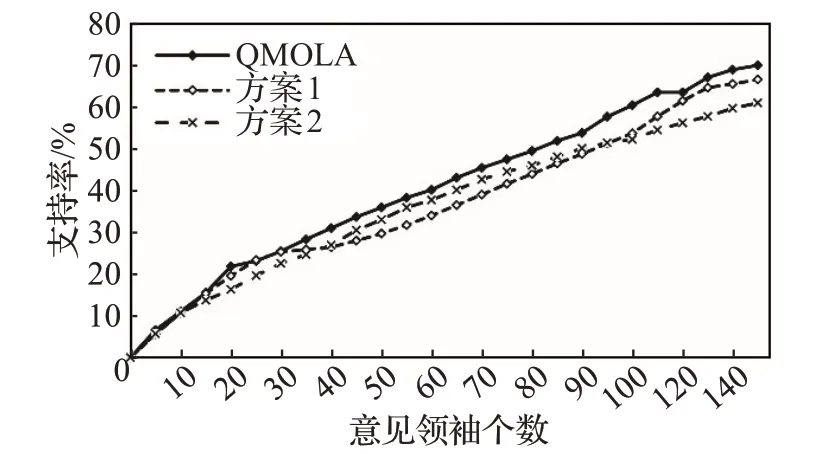
图6 支持率对比实验结果
从图6 中可以看出,当选取意见领袖的TOP- K 个数较小时,本文提出的QMOLA 与方案1 和方案2 挖掘的意见领袖的支持率比较接近,但QMOLA 的效果最好。当TOP- K 选取个数较大时,QMOLA 综合分析意见领袖的传播特征和情感特征,挖掘的TOP- K 个意见领袖的支持率优于方案1 和方案2。因此,本文提出的QMOLA能够挖掘出高支持率的意见领袖。
4.3.3 主题社团的意见领袖挖掘结果展示
表7 展示的是在“娱乐”主题社团中挖掘出的前10个意见领袖的影响力排名。从表中可以看出,“杨幂”“陈坤”等用户结构特征值比较大,但是在近一段时间内,其微博被转发和被评论的数量偏少,传播特征值相对不高,导致用户影响力偏低。再如“王思聪”的微博被转发和被评论的数量很多,传播特征值很高,但由于评论中出现太多贬义评论,导致情感特征值出现负值。综合传播特征值和情感特征值来看,其用户影响力是比较低的。
5 结束语
为了更加准确、高效地挖掘不同主题社团下的意见领袖,本文针对现有方法主题抽取准确率低的问题,提出了一种I-LDA模型,通过添加兴趣属性对传统的LDA模型进行改进,由此能够抽取主题表达能力更强的主题词。在以关注关系建立的社交关系图中,增加主题相似度权重,并提出基于主题相似度的多标签均衡社团划分算法进行主题社团划分,提高了主题社团划分的准确性。本文进一步提出了一种快速意见领袖挖掘算法(QMOLA),该方法先在主题社团中筛选出结构特征值比较大的用户作为候选人,再采用本文提出的用户影响力(UI)计算公式,根据候选人的传播特征和情感特征计算用户影响力,据此,进行主题社团中的意见领袖挖掘。
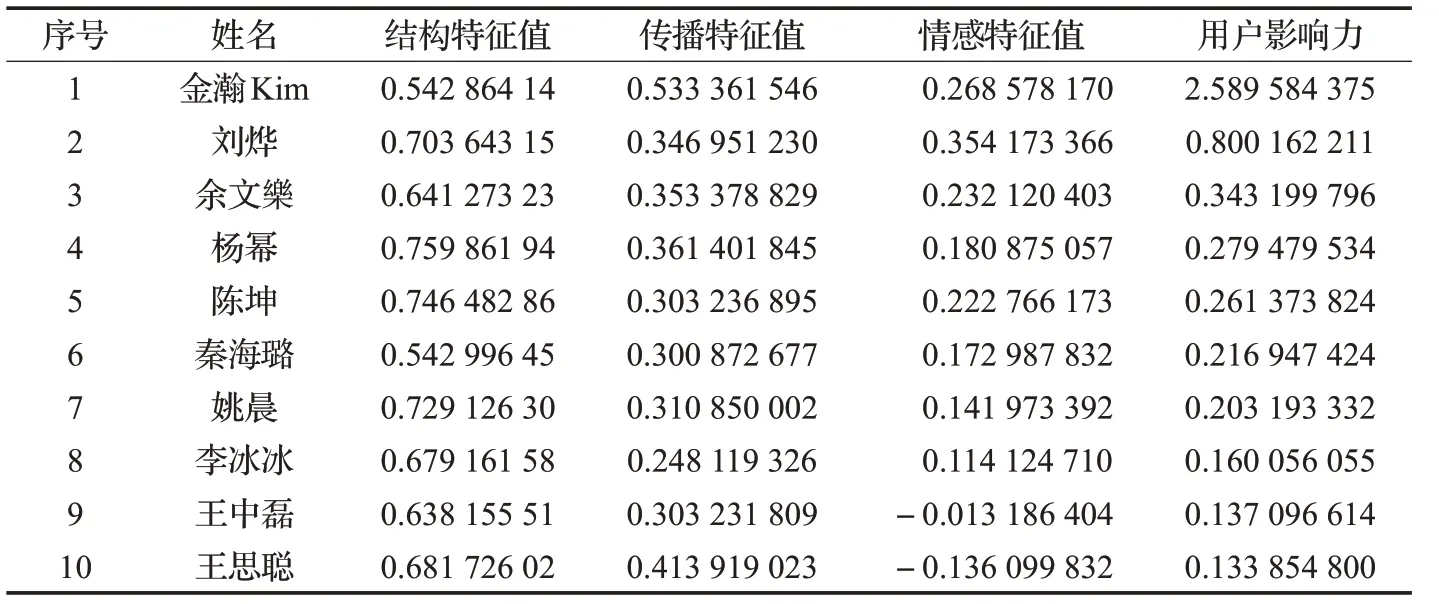
表7 节点影响力排名
实验及分析结果表明,本文方法不仅能够准确划分出主题社团,而且挖掘意见领袖的效率更高,挖掘出的意见领袖具有较高的覆盖率和支持率。
