汉意意汉文学平行语料库的研制*
2021-01-22北京外国语大学余丹妮
北京外国语大学 余丹妮
提要:北京外国语大学汉意意汉文学平行语料库是首个以意大利语经典文学作品及其汉语译本、汉语经典文学作品及其意大利语译本为语料创建的双语双向平行语料库。语料库研制的主要环节包括语料文本的搜集与选择、语料电子化、语料对齐与语料检索功能的实现。本语料库基于互联网进行部署,向相关领域的学习者、译员及研究人员开放,有助于促进汉语—意大利语文学翻译的教学与研究,以期进一步推动中国文学的对外翻译。
1.引言
双语平行语料库的建设与研究已有近30年的历史。20世纪90年代初,世界上第一个双语库在加拿大建成(王克非、黄立波 2012:3)。平行语料库的开发与研制是语料库翻译学取得新突破的数据和方法基础,其潜力有待激发(王克非、黄立波 2012:8)。
目前,平行语料库涉及的语言主要为英语,比如德英文学文本平行语料库(GEPCOLT)、隆德大学开发的英语—瑞典语双向平行语料库(ESPC)、博洛尼亚大学开发的英语—意大利语双向平行语料库(CEXI)等(王克非、黄立波 2012)。目前仍未发现汉语与意大利语作为句对的双语平行语料库以及相关研究。
自2019年3月,我国与意大利签署《“一带一路”倡议谅解备忘录》以来,中意两国在各领域的合作日益加深,意汉文学翻译领域及翻译教学的需求不断增长。1980—2017年,37年间,在意大利仅以书籍形式出版的中国文学译作就有260部(吴菡、吴志杰 2018)。在这一背景下,汉意意汉文学平行语料库CIICLPC的创建具有紧迫性和必要性,将为两国的文学翻译研究、文学交流与语言教学等提供突破性的数据共享平台,为现有翻译研究提供可靠的数据支撑,更系统地推进意汉翻译研究。
2.汉意意汉文学平行语料库的创建
2.1 语料库架构
汉意意汉文学平行语料库的语料包括两部分:汉语原文对应意语译文;意语原文对应汉语译文。语料库采集的语料为书面语料,遵循以下原则:(1)保证语言的共时性,采集1950年后正式出版的文学作品及译本;(2)保证语料的平衡性,科学抽样,兼顾平衡;(3)保证语料的权威性,选取具有影响力的文学作品。语料库总规模为500万字词。意语原文对应汉语译文和汉语原文对应意语译文的比例为1:1。其中,汉意方向的双语语料包含汉语约150万字,意大利语约100万词;意汉方向的双语语料库包含汉语约150万字,意大利语约100万词。该比例设计符合语料库文本的平衡性原则,构建了如图1所示的汉意意汉文学平行语料库模型。
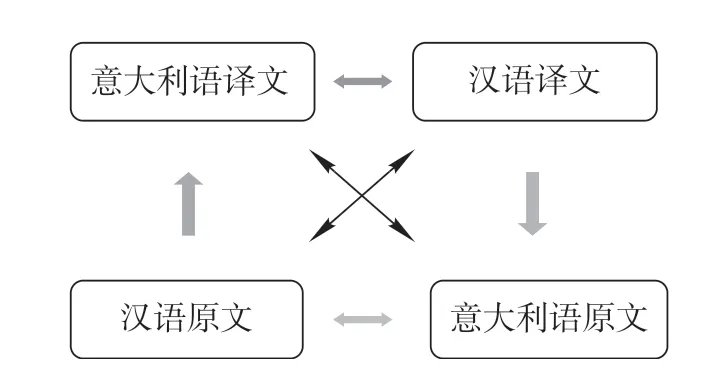
图1 汉意意汉文学平行语料库模型
该语料库模型集平行语料库与可比语料库为一体。其中,除了汉意意汉方向的两个平行语料库之外,还包含由意大利语原文与意大利语译文构成的原生语言与翻译语言可比语料库、由汉语原文与意大利语原文构成的原生语言与翻译语言可比语料库、由汉语原文和意大利语原文构成的原生文学语言可比语料库,以及由汉语译文和意大利语译文构成的文学翻译语言可比语料库。基于该语料库模型,可以展开不同语言对的翻译研究、原生语言与翻译语言的语言特征研究、汉意文学原生语言的对比研究,以及汉语与意大利语文学翻译语言的对比研究。这一研究框架与挪威奥斯陆大学和卑尔根大学研制的英语—挪威语双向平行语料库(ENPC)的分析模型(许家金 2018:6)、北京外国语大学研制的汉日平行语料库对应模式(曹大峰 2006)相似。
该语料库重点收集了中国著名作家莫言、余华的作品及其意大利语译本,以及意大利著名作家卡尔维诺与埃科的作品及其汉语译本,可分为以作家作品为主题的子语料库,即莫言小说平行语料库(8部作品,106万字词)、余华小说平行语料库(5部作品,66万字词)、卡尔维诺小说平行语料库(10部作品,64万字词)和埃科小说平行语料库(9部作品,80万字词)4个子语料库。以作家作品为主题的平行语料库可用于开展特定作家作品译本的翻译与传播研究。
2.2 语料库研制方法
汉意意汉文学平行语料库的研制过程主要包括以下5个阶段,如表1所示。

表1 汉意意汉文学平行语料库的研制
3.汉意意汉文学平行语料库的应用
汉意意汉文学平行语料库可应用于文学翻译研究,对于文学翻译教学、翻译实践及词典编纂也有重要的借鉴意义。目前,在文学翻译研究领域,以汉语和意大利语为句对的翻译研究仍不多见。汉意双向文学翻译语料库的建成可应用于翻译语言特征研究、翻译策略研究、译者风格研究等领域。
3.1 翻译语言特征研究
翻译语言特征研究揭示翻译语言的特性,对促进翻译语言本土化有一定启示。王克非、胡显耀(2010)基于汉语翻译文学语料库与汉语原创文学语料库的对比分析,探讨汉语翻译文学作品中人称代词使用的特征,反映了英语等形态比较丰富的语言对翻译汉语的干扰作用,体现了现代汉语翻译文学作品的陌生化操作规范。翻译语言特征及其普遍性是语料库翻译研究的核心话题,但目前在不同语种组合中的验证尚无一致结论,甚至出现了相互矛盾的数据。不同源语独有的表述习惯对翻译语言的干扰也各有不同。刘淼(2018)探讨了俄语文学汉译本中俄语副动词的翻译。副动词是俄语文学语篇的典型语言现象,是俄汉互译过程中的“语言真空项”。该研究表明,译文中助动词与副动词的语义关系呈现了模糊化。意大利语具有自身的语言特征,如大量的无人称形式表达,其翻译处理方式是值得研究的对象。利用汉意双向文学翻译语料库对翻译普遍性进行更多语种组合的研究,验证已有结论,有助于推动语料库翻译研究的发展。
3.2 翻译策略研究
文学翻译与文化传播的质量息息相关。源语文本特有的语法或语义表达在译入语中往往难以找到对应的翻译方式,基于语料库的翻译策略研究对文学翻译实践能提供一定启示。比如,刘彬等(2015)基于《丰乳肥臀》汉英平行语料库的研究发现,汉语中不同类别的本源概念翻译模式呈现出“直译 > 意译 > 换译 >省略”的分布倾向,提出译者应根据本源概念类别采用相应的翻译模式。直译翻译模式占比较高的倾向,在意大利语文学译本中也有体现。近些年来,很多译者都试图从过度意大利化的翻译思维转变为尽量直译,避免因译者按照普遍标准和自身认知范畴对原文本进行归化。比如,余华《兄弟》中“林子大了什么鸟都有”不再译为意大利语中的相似谚语“世界的多元化就是世界的好处”,而是通过直译引导读者接受这一不难理解的谚语含义(傅雪莲 2014)。基于汉外平行语料库的翻译策略探讨有助于促进中国文学的海外传播,但值得注意的是,基于汉英平行语料库的翻译策略研究对于其他译入语虽有一定的指导作用,但由于译入语具有特定的特征,其翻译策略也应有所调整。这为促进汉语文学作品的意大利语译本传播,基于汉意平行语料库的翻译策略研究有其重要意义。
3.3 译者风格研究
Baker(2000)提出“译者风格”研究的概念,呼吁学界关注特定文学译者特有的语言特征。候羽等(2014)基于莫言小说汉英平行语料库,分析葛浩文的翻译风格,发现葛氏所译莫言小说英译本具有明显的美国英语原创文本特征,并强调了译者对作家作品的长期关注与连续翻译对中国文学“走出去”的重要作用。相比英语翻译家,长期从事中国文学作品意大利语翻译的意大利翻译家则较少受到关注。比如,意大利汉学家李莎(Patrizia Liberati)是多部莫言小说的译者。在北京工作期间,她读了刚出版的《檀香刑》,非常感兴趣,并主动将该小说的简介寄给了一家意大利出版社,而后开始了文学翻译生涯。除《檀香刑》,其翻译的莫言小说还包括《生死疲劳》《变》《蛙》《四十一炮》和《战友重逢》(待出版)。其中,《生死疲劳》意文版获得意大利普罗契达—艾尔莎·莫兰黛翻译奖;《蛙》意文版获得意大利国家翻译奖。李莎翻译风格对于莫言小说在意大利的传播作用是值得研究的课题。汉意意汉文学平行语料库中收录了《檀香刑》《生死疲劳》《蛙》《四十一炮》等李莎所译的莫言小说,为相关的译者风格研究提供了有力的语料支撑。
4.存在的问题与发展方向
国内外汉意意汉文学平行语料库的创建与研究仍未起步,课题组处于探索阶段,其建库模式仍有许多需要改进之处:(1)目前,汉意双向文学翻译语料库已有500万字词,具有一定规模,但其收纳的作家作品数量仍相对来说比较有限,这受到了非通用语种翻译作品数量的局限性影响。在接下去的语料库扩建过程中,可继续扩大作家作品范围以及拓宽作品发布年份要求,纳入1950年以前出版的经典作品,比如但丁的《神曲》、薄伽丘的《十日谈》、彼特拉克的《歌集》等作品及其汉语译本、中国四大名著等经典文学作品及其意大利语译本。(2)文学翻译语料库具有广泛应用价值,但在促进机器翻译发展方面,其作用则比较局限。文学翻译由于较多出现意译的现象,不适合作为提高机器翻译精确度的原始语料。相比之下,应用型翻译文本主要为直译,词汇对应率高,便于机器神经网络识别,作为原始数据对于提高机器翻译精确度来说作用更显著。我们将在文学翻译语料库建库经验的基础上,继续进行应用型体裁文本的收集,进一步建成汉意非文学翻译语料库,以服务于汉意机器翻译领域的发展。
5.结语
北京外国语大学汉意意汉文学平行语料库基于互联网进行部署,可供相关领域的学习者、译员及研究人员使用。在实践应用层面,汉意意汉文学平行语料库对提高汉意翻译教学效率、提高翻译实践质量与完善词典编纂等领域具有重要意义,符合国家培养高层次非通用语翻译人才与加强国际交流合作的需求。在研究层面,汉意意汉文学平行语料库是文学翻译研究的重要支撑语料,有助于推动汉意文学翻译研究,符合推动中国文学走出去的需求。
