针对商品推荐系统的混淆托攻击半监督检测研究*
2021-01-22卫星君李海霞
■ 卫星君 李海霞
1.陕西能源职业技术学院机电与信息工程学院 咸阳 712000
2.陕西能源职业技术学院经济管理学院 咸阳 712000
0 引言
互联网推动社会经济快速发展的过程中,产生海量商品数据的同时,其背后的信息系统为“信息过载”问题作出了巨大贡献。以电子商务平台中使用的推荐系统[1]最为普遍。它能使客户从海量商品信息中,找到相关或喜好的商品,为买家提供合适商品,为卖家提高销售业绩,促进商品经济的发展。电子商务平台在陕西省农业农村信息化背景下,所具有的特点和优势使其在农业及农村中的发展势不可挡。同时,商品服务和消费者重复购买意愿之间的信任关系极为重要,使得对推荐商品的准确性和可靠性有了更高的要求。然而,推荐系统的开放性及算法特点,系统易受到恶意攻击[2-3]。攻击者在推荐系统中伪造虚假用户的购买信息,促销或者打压某类商品而获利,称为托攻击(shilling attack)[4-5]。为解决商品推荐的可靠性和安全性,促进农村消费者对商品服务和品质的信任,申请陕西省教育厅专项科研计划项目——陕西农村电子商务发展模式研究,本文作为项目成果的一部分,为项目实施提供必要技术支撑。
常见的基本托攻击有随机、均值和流行攻击等[6-7]。目前的托攻击检测方法主要是针对基本托攻击。例如:方楷强等[8]利用托攻击防御算法框架,通过降低检测托用户的信任度,从而减少托攻击用户的影响,对托攻击进行检测。于洪涛等[9]提出了7 个不依赖于项目具体评分值大小的托攻击检测特征,对基本托攻击检测效果明显。吕成戍等[10]用非对称半监督集成支持向量机(Sup‐port Vector Machine,SVM)的攻击检测方法,解决系统小样本问题和数据不均衡分布问题,取得较好的检测效果。Alostad 等[11]提出SVM 高斯混合模型对托攻击进行检查,检查准确率较高。Wei 等[12]通过构建时间序列来确定可疑评分时段,并检测可疑评分段,进而发现攻击。Yang 等[13]充分利用标记用户,包括用户与用户、项与用户相互关系,通过贝叶斯模型对托攻击进行检测,在低攻击强度下取得了较好的检测效果。而在实际中,基本攻击模型构成的托攻击往往易于检测。为了躲避攻击检测,提高攻击效果,攻击者会使用评分偏移和噪音注入两种混淆策略[14]与基本托攻击混合使用,构造更复杂的混淆托攻击,降低攻击概貌和用户概貌之间的区别,使得伪造的攻击用户更加接近真实用户而逃避托攻击检测。伍之昂[6]等分析基本攻击模型和混淆策略,给出了构建混淆托攻击的思路。Hurley 等[15]提出混淆AoP(平均流行,Average over Popular)攻击,在均值攻击中加入流行项,攻击效果明显。卫星君等[16]提出混淆BoP(混淆流行,Obfuscation over Popular)攻击,对流行交叉项评分偏移,表明该攻击相比流行攻击,对推荐系统的影响更大。因此,混淆托攻击难检测,危害大。

表1 混淆托攻击一般形式
目前,大部分的托攻击检测方法未能充分利用标记用户,且对使用混淆策略的托攻击检测“力所不及”。因此,本文从混淆策略特点入手,充分利用标记用户,改进K-Means算法,提出标记用户共同关注;对标记用户的特征指标进行二次提取,进而压缩特征指标向量,给出混淆托攻击半监督检测方法,在无需确定攻击目标的情况下,对托攻击进行有效检测。
1 相关工作
为了识别混淆托攻击,分析基本托攻击的组成及评分方式,混淆策略的具体使用方法,给出混淆托攻击的一般形式;收集系统数据库中的标记用户,为计算特征向量提供样本数据。
1.1 混淆托攻击一般形式
基本托攻击模型由选择项、填充项、未评分项及目标项组成。选择项是为了成为更多正常用户的近邻;填充项使其更像正常用户;目标项是推举或者打压的商品。目标项设定系统评分最大值称为推攻击,设定系统评分最小值为核攻击[17]。攻击者会尽可能了解数据库评分分布情况、数据库的数值或密度分布,选择热门商品,实现自动化填充项和选择项。但这样构成的攻击概貌具有相似性,且易检测。因此,为了设计更加有效的攻击,攻击者利用混淆策略对填充项和选择项的评分进行修改,使得攻击概貌更加接近真实用户评分而躲避检测,实现攻击目的。
混淆策略具体如下:
(1)评分偏移策略修改选择项评分
攻击者最常用且有效的方式为选择热门商品插入攻击概貌中,不但能够成为更多用户的近邻,而且获取热门商品所需知识成本较低,但插入过多的热门商品易被检测。使用偏移函数,修改热门商品评分,降低攻击概貌“关注度”,使得更加接近普通用户概貌评分。评分表示成:

式中:smax为系统评分最大值;Fshift(i)为第i 个热门商品的评分偏移函数,依赖于热门项在数据库中的评分分布。
(2)噪音注入策略修改填充项评分
攻击者很容易根据经验确定数据库中的评分分布,构造评分函数[18],实现自动化填充评分。同时加入常数因子α,降低攻击概貌自动化评分的“机械性”,使得更加接近普通概貌评分。评分表示成:

式中:α∈(0,1];θ 为评分函数Fselc 参数,依赖于数据库中评分分布。
依据基本托攻击模型的构成及混淆策略,混淆托攻击的一般形式如表1所示。其中bssq为使用公式1 修改第q 项选择项评分,bsfp为使用公式2 修改第p 项填充项评分。
1.2 数据定义
定义1标记用户数据集。系统中用户对商品评分真实可信,不存在虚假且评分项较多。因为评分项越多更有资格成为最近邻。用一个三元组表示:
UT=(DT,IT,ST)
式中:DT表示标记用户身份;IT为评分项;ST为IT的评分。
定义2特征指标向量。特征指标用来区分攻击概貌和普通概貌之间的差异。不同攻击类型选取的特征指标不同。表示成:
R=[r1,r2,。。。,rm]
式中:rm表示不同攻击类型确定的特征指标。
1.3 特征指标
攻击概貌评分的“关注度”和“机械性”,使得与普通概貌评分之间存在差异。如项目的评分高低,用户评分向量长度变化,用户对于流行项的关注程度等。特征指标可以量化托攻击者与正常用户在评分方式上的差异。文献[4,19-20]为识别基本托攻击,提出了不同的特征指标。RDMA 反映了输入用户与系统中其他用户的评分差别;WDA、WDMA是对RDMA的改变;LengthVar表示用户评分向量的长度变化;MUS反映出用户概貌同聚类中心相似度。WDA、WDMA、RDMA、LengthVar、MUS等特征指标从不同方面反映出普通概貌和攻击概貌的差异性。
2 标记用户共同关注项
由1.1 可知,攻击者选择用户共同关注的热门流行商品,插入攻击概貌。同时使用评分偏移策略修改热门商品的评分,降低攻击概貌的“关注度”,进而躲避攻击检测。不同商品的受众群体不同,共同关注的热门流行商品不同。因此,采用K-Means 算法[21],对标记用户数据集UT进行聚类分析,把评分近似的用户划分到一个簇集中,进而得到不同簇集的共同评分项。
推荐系统中,相似用户用Pearson 相关系数描述。相关系数越大,两个评分用户相关性就越强,评分越近似。相关系数表示成:
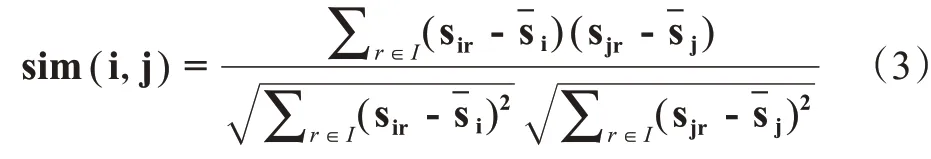
式中:sir用户i对项r的评分;sjr用户j对项r的评分;i用户i的平均评分;j用户j的平均评分。
2.1 改进K-Means算法
K-Means算法的聚类效果受初始聚类中心个数和聚类中心位置的影响。为了确定聚类中心个数,计算标记用户的Pearson 相关系数,得相似矩阵simn×n。该矩阵对称,且负数表明两个用户评分差异大,所以只考虑标记用户相关系数simij>0的上三角数据。simn×n表示如下:
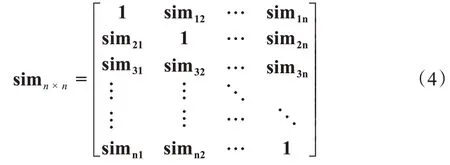
2.1.1 确定聚类中心个数K
(1)使用公式4计算标记用户的simn×n,把simn×n上三角数据投影到X 轴坐标。为保证sim 值划分的精度,投影值保留4位有效数字。
(2)依次计算投影在X 轴的相邻sim 差的绝对值。若|simf-simb|≥б,则为一个划分,并记录这一划分sim 的个数tk。б 取值依赖于sim 的精度和相邻sim 差值大小。б取值随着sim的移动而增大,但在段内|simf-simb|<б。
(3)计算K个划分平均用户个数,即tagv=标记用户个数/K。tk<<tagv,即对于个别划分仅有少数标记用户,则该划分可以不用考虑,K减1。
(4)K为聚类中心个数。
2.1.2 选择K个初始聚类中心
标记用户中,选择评分项最多的utk个用户为聚类中心。因为评分项越多,更能成为其他用户的近邻。utk表示标记用户中评分最多的第k个用户。
2.1.3 标记用户聚类分析
(1)计算标记用户同K 个初始聚类中心的相关系数sim(ut, ck),把用户划分到相关系数最大簇集中,ck为初始聚类中心。
(2)计算K 个簇集中用户对项的评分均值,作为新的聚类中心ck’。
(3)如果sim(ck,ck’)<θ,则ck=ck’,重 复step1 和step2,否则聚类结束。θ的取值通过实验确定。
(4)输出K个聚类中心,K个簇集的标记用户ukt。uk‐ti∈ukt,ukti表示第k个簇集中第i个标记用户。
2.2 共同关注项
不同的簇集中,共同关注项可能不同,但每个关注项都是近邻用户可能选择的物品。推荐系统中,近邻个数越多,共同关注项的评分次数越多。推荐系统通过用户近邻来计算预测值,近邻个数太多,计算效率低;近邻个数太少,很多商品无法预测。因此,需要对数据集进行分析,找到合适的近邻个数。
在同一个簇集中,统计不同用户的评分次数,被评分次数大于等于用户近邻个数的商品集合为簇集k中的共同关注项。表示为:
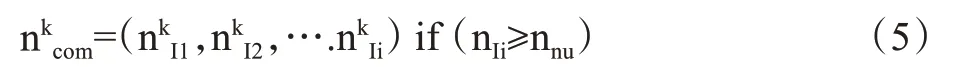
式中:nkIi为第i个物品在簇集k 中被评分次数;nnu为推荐系统中预测评分时,用户的近邻个数。
3 特征指标二次提取与压缩
由1.1 可知,攻击者会尽可能了解数据库的评分分布。如热门物品评分均值,进而使用噪音注入策略自动化生成攻击概貌,避免评分的“机械性”,躲避攻击检测。因此,采用类内散布矩阵的单类模式特征提取方法[22],二次提取标记用户特征指标的特征向量。在保留类间鉴别信息的同时,突出可分性,为区分混淆托攻击提供先验知识,把攻击用户和普通用户富集于两端,实现攻击概貌和普通概貌的分类。
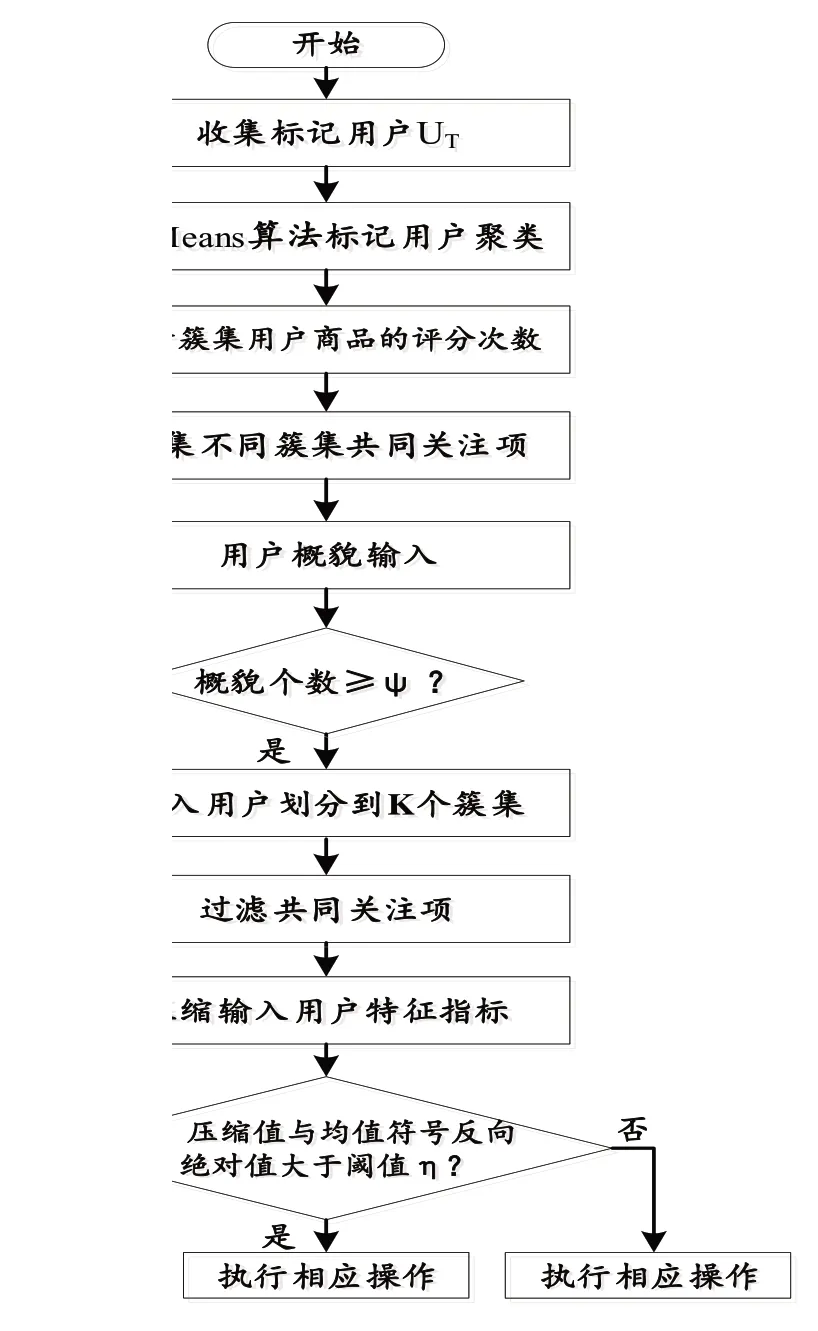
图1 混淆托攻击检测算法流程
3.1 特征指标二次提取
类内散布矩阵的单类模式特征提取的目的是压缩维度,保留类别间的鉴别信息,突出类间可分性。具体计算方法如下:
(1)依据定义2,计算标记用户特征指标矩阵,行为特征指标,列为标记用户,表示为:
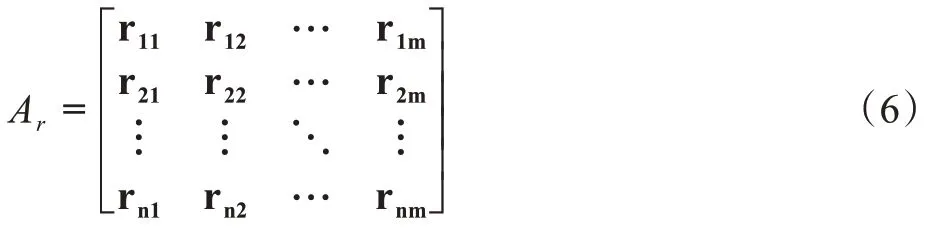
(2)特征指标值的均值向量表示为:

(3)特征指标协方差矩阵表示为:

式中:r 为n 个特征值的n 维向量;Acr为n×n 的实对称矩阵。
(4)计算特征指标协方差矩阵Acr的特征向量。假设Acr的n个特征值λk对应n个特征向量,归一化n个特征向量后的正交矩阵为Ccr,表示为:

式中:wk为归一化的特征向量;k=1,2,…,n。
3.2 特征指标压缩
使用Ccr对标记用户特征指标样本进行变换,计算变换后的类内距离:
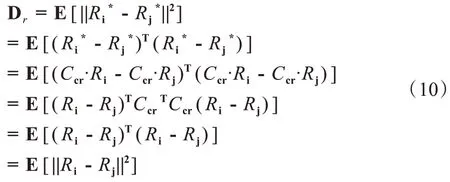
式中:R*=CcrR;Ccr为正交矩阵,CcrTCcr=E。
从上式可以看到,变换的标记用户特征指标向量R*,类内距离保持不变。对Acr的n个特征值λk升序排序,选取前m 个特征值对应的特征向量作为的行,组成压缩变换矩阵Ctr(m×n),则特征指标向量压缩表示为:

式中:R为特征指标向量,R*为被压缩后的特征指标向量。
4 混淆托攻击半监督检测模型实现
4.1 混淆托攻击半监督检测算法流程
混淆托攻击半监督检测算法(SeD-CSAD)的流程如图1所示。
具体实现步骤如下:
(1)依据定义1,收集标记用户。
(2)依据上文2.1,对标记用户进行聚类,输出K个聚类中心ck,K个簇集的标记用户utk。
(3)使用公式5,统计K 个簇集中用户的商品评分次数nkcom。
(4)输入用户进入推荐系统,判断当前进入系统的用户个数,直到输入用户个数大于等于阈值ψ,转入下一步。
(5)过滤输入用户共同关注项。
(6)使用公式11,对输入用户特征指标进行压缩。
(7)对输入用户特征指标压缩值进行排序,并计算压缩值的均值差,差值为负且绝对值大于阈值η,为普通概貌,否则为攻击概貌。
4.2 过滤输入用户共同关注项
输入用户,进入推荐系统后,它们的最邻近不同。因此,输入用户过滤的共同关注项也不同,这就要求把每一个进入推荐系统的用户划分到不同的簇集中,再过滤同关注项。输入用户共同关注项过滤流程如图2所示。
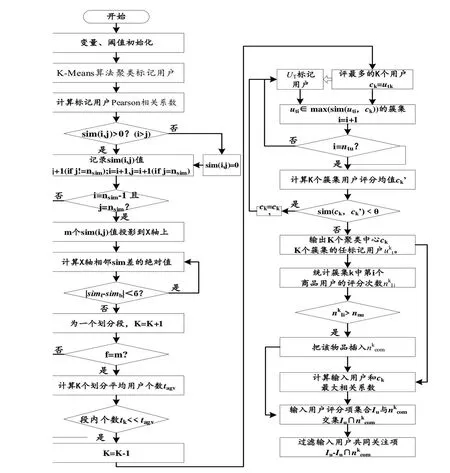
图2 输入用户共同关注项过滤流程
4.3 压缩输入用户特征指标
过滤输入用户共同关注项,利用标记用户特征指标的特征向量,压缩输入用户特征指标,进而识别攻击概貌和普通概貌。特征指标向量压缩流程如图3所示。
5 实验设计与分析
5.1 实验设计
实验数据为MovieLens100K 数据集[23]。该数据集包含了943 位用户,每位用户至少对20 部电影进行了打分,并对1682 部电影进行了1 到5 的评分。实验参数设定:推荐系统的攻击强度太低不能影响推荐评分,太高易被检测。因此,实验中输入用户为ψ≥3%[11];用户的近邻个数nnu=30[16];特征指标向量压缩维度m=1;概貌识别阈值η=0.02;确定聚类中心个数K=8。构建混淆托攻击概貌中α=0.8。
5.2 实验结果分析
5.2.1 信息增益比较
信息增益表明特征指标对样本的区分能力,区分能力越强,说明特征越重要。因此,过滤共同关注项,计算K 个簇集平均信息增益,进而为不同混淆托攻击选取特征指标。表2和表3分别为混淆随机攻击和混淆均值攻击进行50 次实验,当填充率为3%、5%、10%和20%的K个簇集平均信息增益大小。
从表2和表3可以看出,不同特征指标在同一填充率下,K个簇集平均信息增益大小不同,表明特征指标对输入用户的区分能力不同。MUS 为富集攻击到一端提供了有效的分类信息。RDMA和WDA能有效反映用户概貌评分差异。LengthVar表明用户评分概貌长度变化。
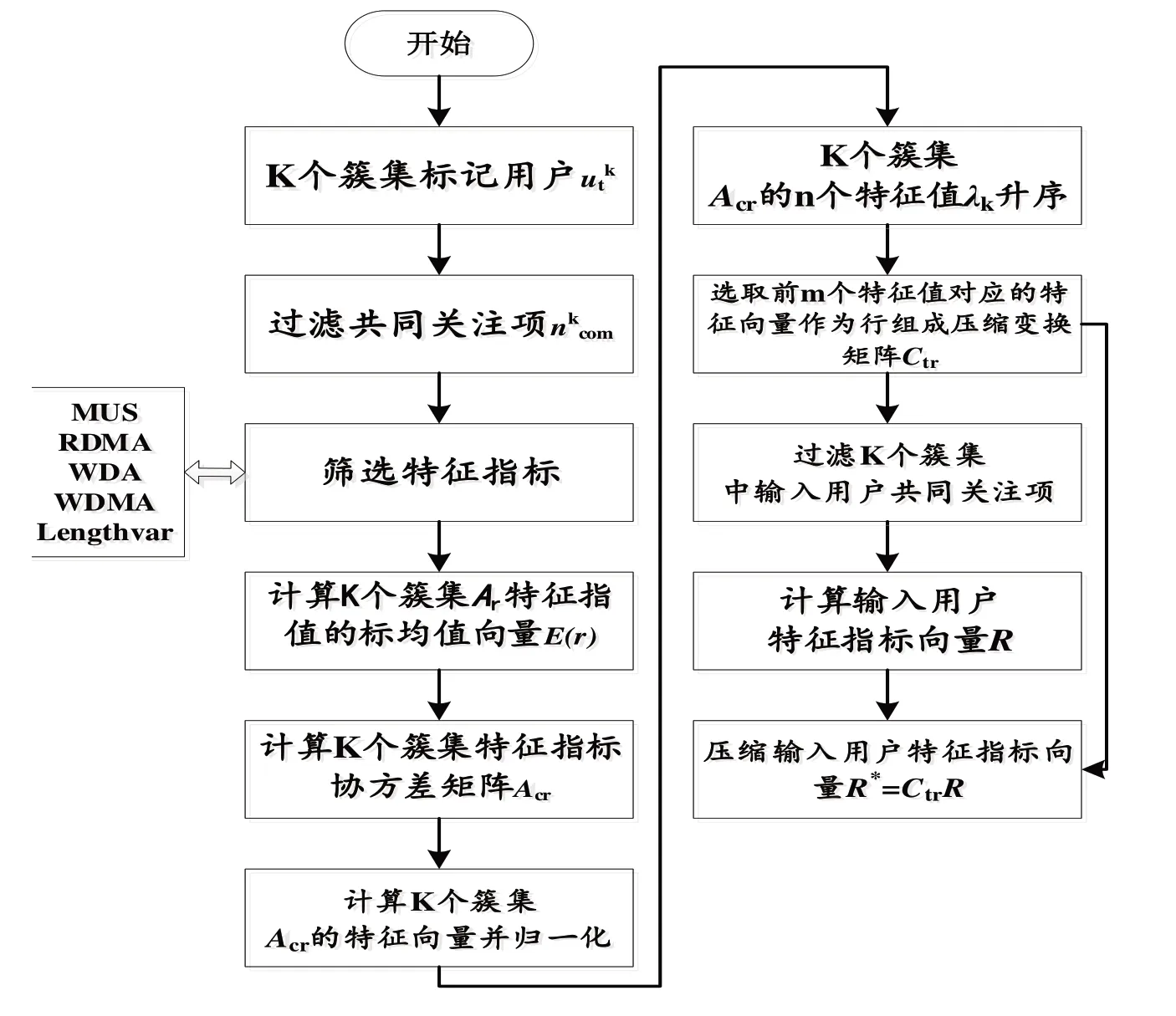
图3 特征指标向量压缩流程
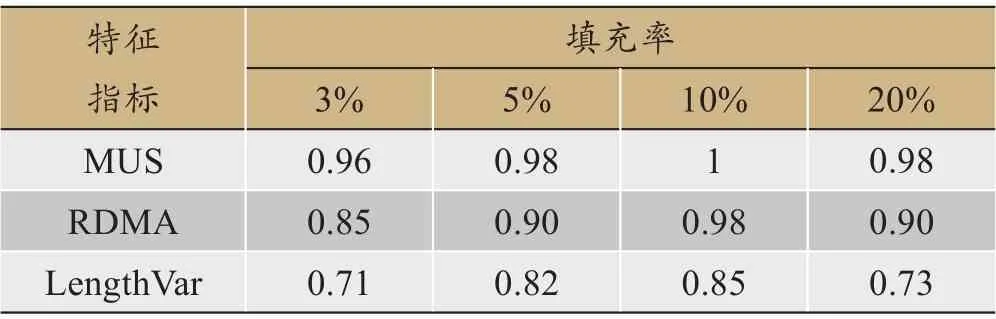
表2 混淆随机攻击K个簇集平均信息增益
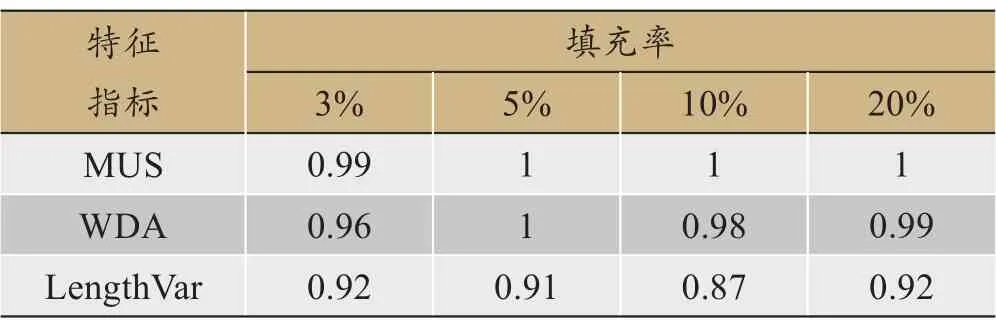
表3 混淆均值攻击K个簇集平均信息增益
6.2.2 SeD-CSAD算法检测效果比较
混淆托攻击算法的检测效果用准确率(P)和召回率(R)表示,计算方法为:
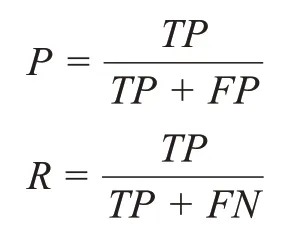
式中:TP 正例检测为正例;FP 反例检测为正例;FN 正例检测为反例。
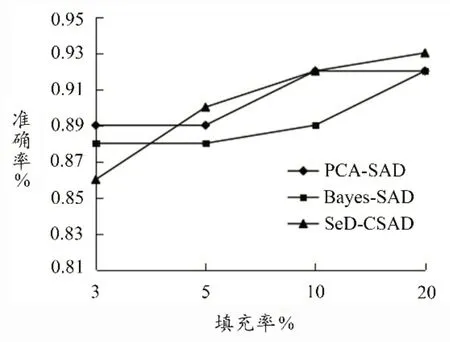
图4 混淆随机攻击准确率比较
低填充率下,检测效果可以用斜率绝对值,即检测敏感性表示:
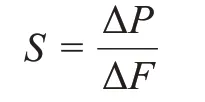
式中:ΔP 表示准确率的变化量,ΔF 表示填充率的变化量。
比较混淆托攻击半监督检测算法(SeD-CSAD)、主成分分析算法(PCA-SAD)和贝叶斯算法(Bayes-SAD)对混淆托攻击检测效果。图4-5 给出了实验检测算法SeDCSAD、PCA-SAD 和Bayes-SAD 在攻击强度3%下,填充率为3%、5%、10%、20%混淆随机攻击和混淆均值攻击的检测准确率。

表4 混淆随机攻击和混淆均值攻击的准确率和召回率
从图4-5 可以看出,混淆随机攻击和混淆均值攻击,在较低的填充率下(≤5%),SeD-CSAD 算法检测敏感性更高,即在较低的填充率下,该算法更易检测出混淆托攻击,且SeD-CSAD 算法随着填充率的提高准确率不断提高。
表4为SeD-CSAD 算法对混淆随机攻击和混淆均值攻击的准确率和召回率。随着填充率的增大,召回率和准确逐渐提高,表明该检测算法的有效性。
6 结论
(1)分析基本托攻击模型及混淆策略,给出混淆托攻击模型的一般形式,为研究混淆托攻击提供了攻击模型基础。
(2)改进K-Means 算法,对标记用户聚类,进而得到最近邻用户的共同关注项。过滤输入用户共同关注项,计算标记用户特征指标的特征向量,为区分攻击概貌提供先验知识;为消除混淆策略对托攻击检测的影响提供计算方法。
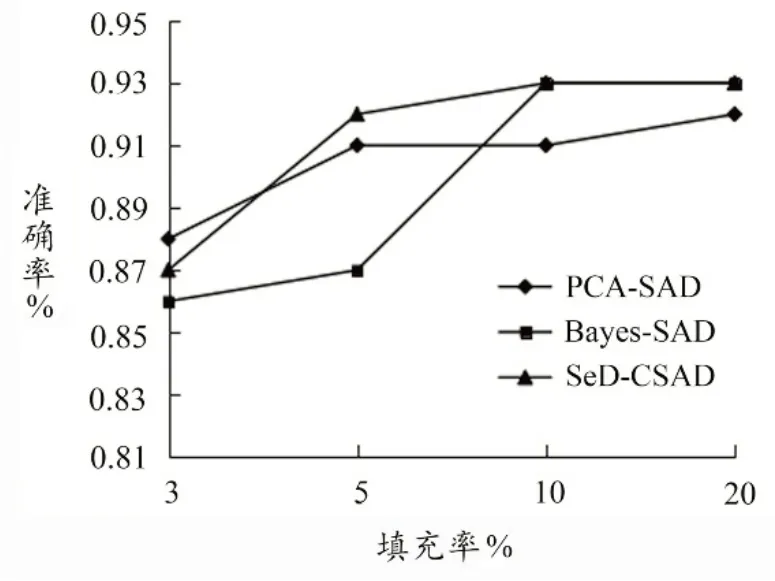
图5 混淆均值攻击准确率比较
(3)比较半监督算法(SeD-CSAD)、主成分分析算法(PCA-SAD)和贝叶斯算法(Bayes-SAD),在较低的填充率下,SeD-CSAD算法有着较高的检测准确率。
本文充分利用标记用户,降低混淆策略对托攻击检测的影响,进而对混淆托攻击进行检测。下一步的重点工作是研究混淆托攻击的特征指标,进一步提高混淆托攻击检测效率和准确率。
