基于谱系聚类分析的饲料混合加工的研究
2021-01-22郁智轩王林渠韩金诺
郁智轩 王林渠 韩金诺 杨 洋
( 成都信息工程大学光电工程学院,四川 成都610000)
1 概述
饲料加工厂需要加工一批动物能量饲料,加工厂从不同的产区收购了原料,原料在收购的过程中由于运输、保鲜以及产品本身属性等原因,存在着效能率的问题(如1 吨玉米可加工成0.7 吨左右的玉米面)。这个数据在原料进厂之后可以通过随机抽样进行检测得到。工厂技术人员对每种加工原料进行了基因检测,得到了10 个关键位点的基因序列,并规定,两个加工原料如果有N 个相同位点的基因序列标记相同,就认为这两个加工原料的亲缘值为N(如果N 大于0,则说明这两种加工原料之间具有亲缘关系),一个加工包中所有原料两两之间亲缘值的平均值称为亲缘度。例如品种代码1、2、5 的加工原料混合成为一个加工包,假设品种代码1和品种代码2 的亲缘值为5,品种代码1和品种代码5 的亲缘值为3,品种代码2和品种代码5 的亲缘值为5,那么它们的亲缘度就是(5+3+5)/3。如果一个加工包中只含有一种加工原料,则该加工包的亲缘度为10。本文仅从亲缘度角度考虑混合加工饲料的质量,亲缘度越高,饲料质量就越高。
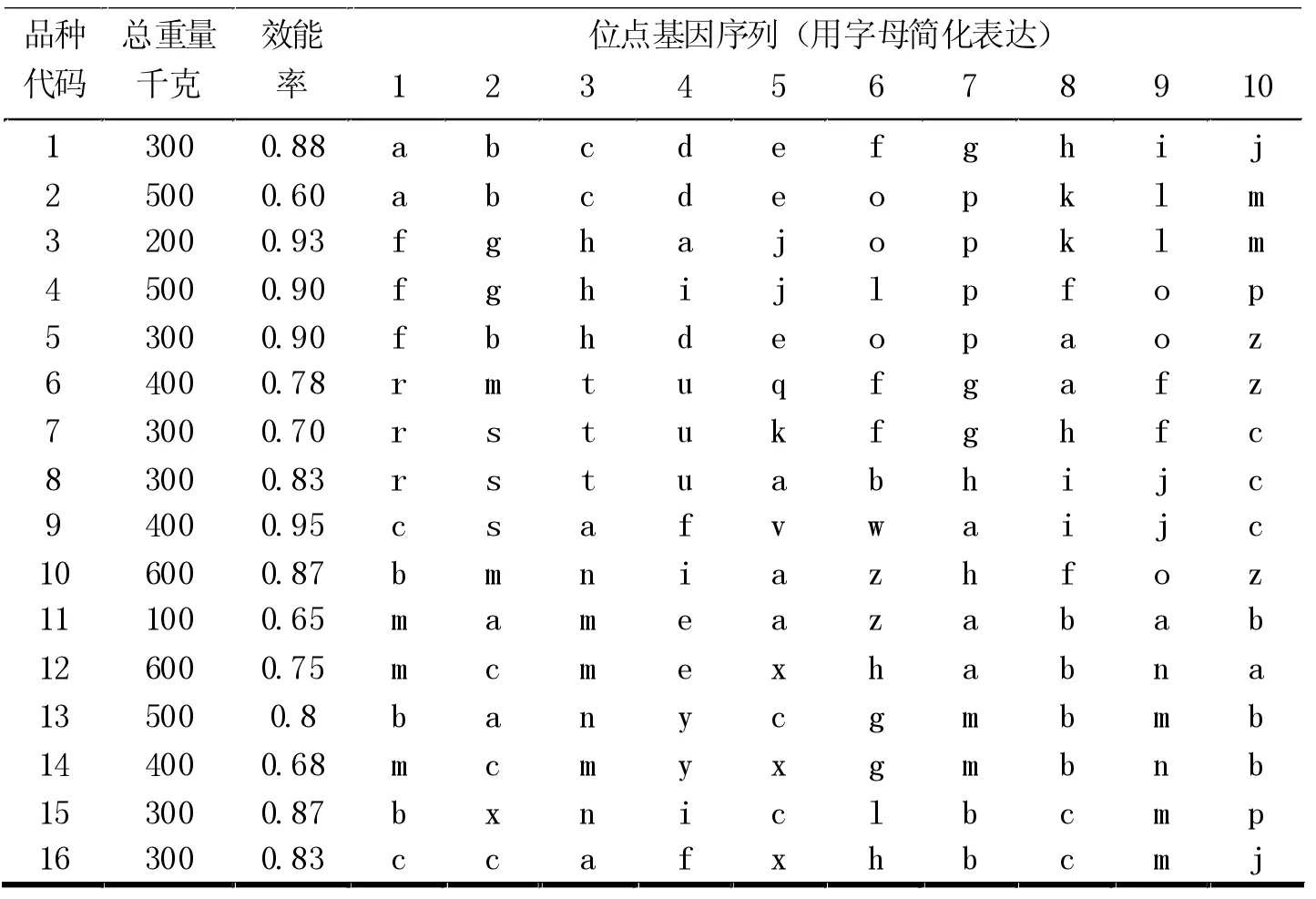
表1 各加工原料的品种代码、总重量、效能率和基因序列标记
2 模型的建立与求解
2.1 谱系聚类分析概述
谱系聚类分析的基本思路是从一批样品的多个样本中, 系统聚类首先定义能度量样品间的亲疏关系的统计值; 然后求出各样品间的亲疏程度度量值; 再接下来按照亲疏程度的大小,把样品挨个归类, 关系密切的聚合到一个小的单元, 关系疏远的聚合到一个大的分类单元, 直至所有的样品都聚合完成;就这样,将不同的类型挨个划分, 最后处理绘出相应的谱系图,以更加直观地表现出分类样品的相关联系及差异。
谱聚类算法将各项数据中的各个对象看作图的顶点D,将顶点间相似性度量化为相应顶点连接边的权值Q,我们就能得到一个基于相似度的无向加权图G(D, Q),我们就把聚类问题转化为图的划分问题。而基于图论的最优划分原则就是使划分成的子图内部相似度最大,子图之间的相似度最小。建立在谱图基础上的谱聚类算法与传统的聚类算法相比,它具有能在任意形状的样本空间上聚类且收敛于全局最优解的优点。
其基本思想便是利用所得样本数据的相似矩阵,即拉普拉斯矩阵,进行特征分解( Laplacian Eigenmap 方式降维处理),再将得到的特征向量进行K-means 聚类。
我们考虑一种最优化图像分割方法,将其为S 和T 两部分,等价于如下损失函数cut(S, T),如公式(1)所示,即最小(砍掉的边的加权和)。
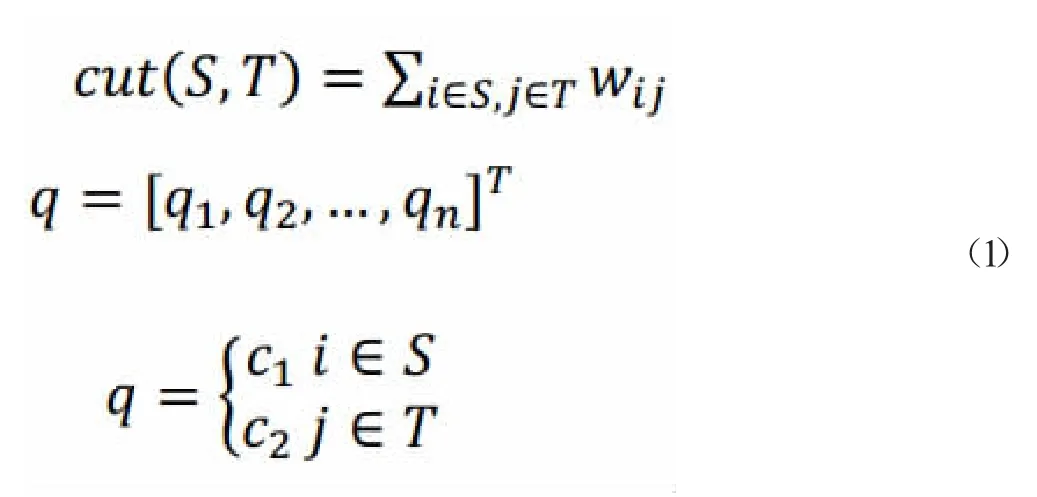
2.2 16 种加工原料参数
给定所测16 种原料的品种代码、总重量、效能率和基因序列标记值如表1。
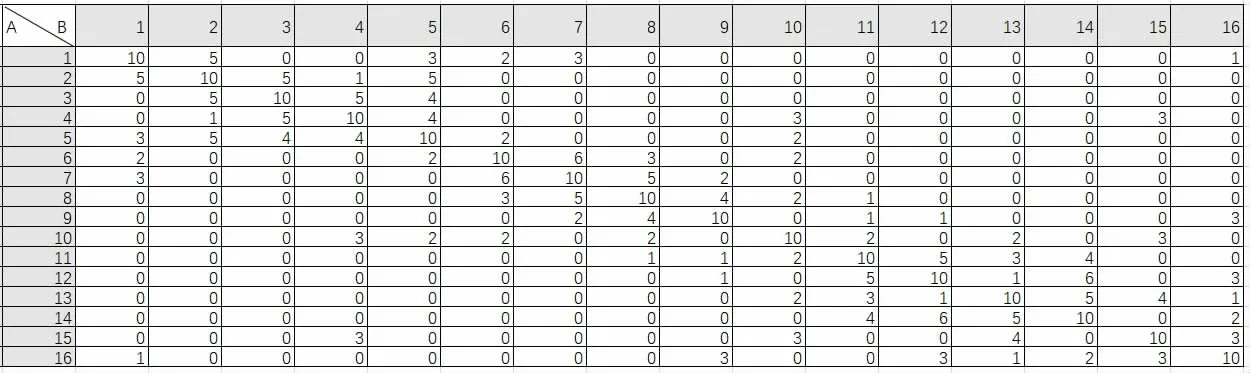
图2 16 个品种的亲缘值邻接矩阵
2.3 分析与求解
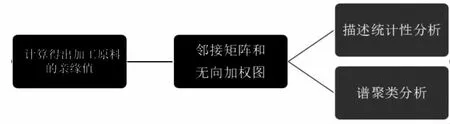
图1 分析流程图
要求出16 种加工原料两两之间的亲缘值,并对其进行统计性分析,依据亲缘值N 的计算方法得出一个16*16 方阵,列出相似性矩阵,将基因序列a-z 用数字1-26 代替,将其带入邻接矩阵(见图2)中,得出16 个加工原料两两之间的亲缘值。建立一种描述性统计分析和谱聚类分析相结合的统计性分析模型来分析得到的亲缘值数据(矩阵与图)。
具体步骤如下:
(1)根据所得出的亲缘值数据,构造一个Graph,Graph 的中每个节点对应一个数据点,将各点连接起来,我们使用边的权重来代表数据之间的相似度。然后将这个Graph 用邻接矩阵的形式进行表示,记为W。
谱聚类中的矩阵:
邻接矩阵:

Min cut 和ratiocut 中的Laplacian 矩阵:
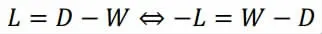
Normalizedcut 中的L:

可见不管是L、L'都与W 联系特别大。如果将W 看作一个高维向量空间,同样能够反映出item 之间的关系。若把W 直接kmeans 聚类,得到的结果也能反映V 的聚类特性,而谱聚类的引入L 和L'是使得Graph 的分割颇具物理意义。
(2)把W 上每一列元素加起来共得到16 个数,把它们放在对角线上(其余均为零),组成一个16x16 的对角矩阵,记为度矩阵M,并把的结果记为拉普拉斯矩阵。
L=M-W
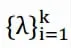
(4)将k 个特征向量排列在一起组成一个16xk 的矩阵,将其中每一行看成k 维空间中的一个向量,用K-means 算法进行聚类处理。得到的结果中每一行所属的类别即是原来Graph中的节点,亦即是最初的16 个数据点分别所属的类别。用matlab 即可快速得出邻接矩阵W 的拉普拉斯矩阵,及其特征向量,进而规定想要把16 个原料分成几类,就将k 设为多少,便可迅速得到一种分类,即是综合亲缘度较高的组合。
图论是指对某些客观的事物进行抽象处理,利用图的形式来描述事物的内在联系。它是研究一类或几类事物之间相关关系的一种理想的数学方法,原理是通过把某一类事物抽象成点,使用两点之间的连线进而表示两个事物之间存在着相关关系,进而将整个复杂的分析转化成一个仅由点线构成的二维图,再应用数学方法展开研究。该方法适用描述各加工原料的亲缘值。两两加工原料的亲缘值与他们相同的基因序列相关,根据基因序列的相同个数得出亲缘值,基于邻接矩阵建立出图论模型。如图3(除去孤点共70 种组合):
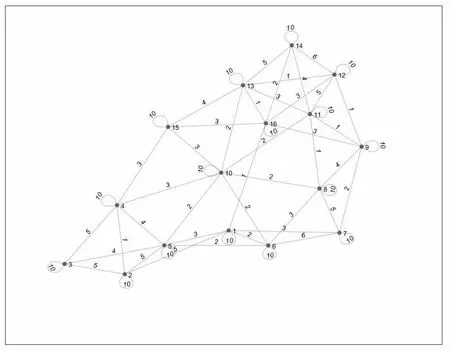
图3 16 个品种亲缘值的无向加权
2.4 计算结果(见表2)。
3 结论
由上述结果可知,在16 个加工原料中,品种5 的综合亲缘关系最强,品种14 次之。品种10 的亲缘关系最广,品种5、11、13、16 次之。为加工出更高质量的饲料提供了参考。
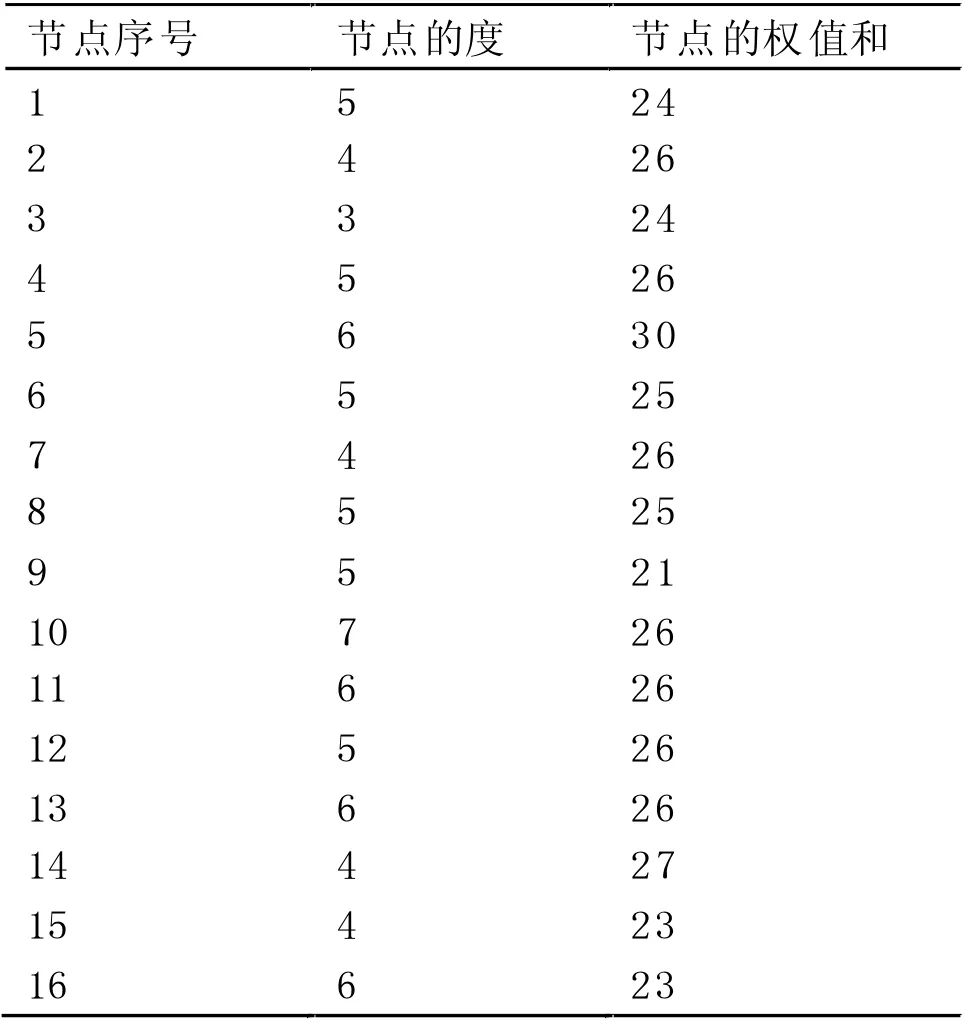
表2
本方法依据邻接矩阵和无向加权图准确的得到了亲缘值,并对数据进行描述统计性分析和谱聚类分析,有着严密的数学逻辑思想,具有较高的可信度。
