面向服务的一站式机器学习算法系统的设计与实现
2021-01-22徐亚军
徐亚军
( 苏州百智通信息技术有限公司,江苏 苏州215000)
智能化机器学习技术成为现代公司追求的发展方向,普遍应用于丰富的业务开发以及业务场景中,满足一项业务需求,需要涉及整个数据收集以及机器学习模型线一体化算法流程,不同业务场景需要耗费大量的成本做重复性开发工作,同时还需要融合原有软件开发体系与模型开发流程,在这过程中容易造成代码入侵问题。
本文当中所设计的一站式服务机器学习算法系统,可以完成从最初的数据采集存储,到最后的模型线上化的计算过程。初级学习者也可以根据业务需求制作简单的机器学习模型,同时专业的工程师也可以借助该机器学习算法系统,开发更加复杂的模型平台,减免了修改原有业务系统代码过程。融合机器学习算法模型以及原有的业务生态系统,提升可扩展性,同时降低维护和开发成本。
1 系统总体架构设计
该机器学习算法系统,主要是面向实体用户和虚拟用户开放业务系统。系统对外接口不仅可以获取用户输入信息,同时也可以将结果反馈给用户。一般来说实体用户主要有图形化以及终端命令输入两种输入方式,而虚拟用户主要运用的是RPC 传输方式。
1.1 数据服务部分
数据采集服务位于整个服务层的外侧,所有数据的存储和交互都需要经过数据服务层入口。资源的获取以及读取方式、上层数据的来源均需要依靠数据采集服务[1]。
1.2 数据清洗和数据标准化服务
清理脏乱数据、加工源数据以及赋予文字值数据化属性,都需要在这两个服务当中进行。特征工程服务位于服务最底端,其主要作用是提取精细化和标准化的数据特征,进行特征降维操作等(图1)。
1.3 算法模型层
1.3.1 模型解析
模型解析的主要工作是解析,有关计算图的描述信息。然后将模型放在内存当中,依靠算法库中的通用算法库、自定义复杂算法库以及通用场景库做训练、评估和上线。
1.3.2 计算层
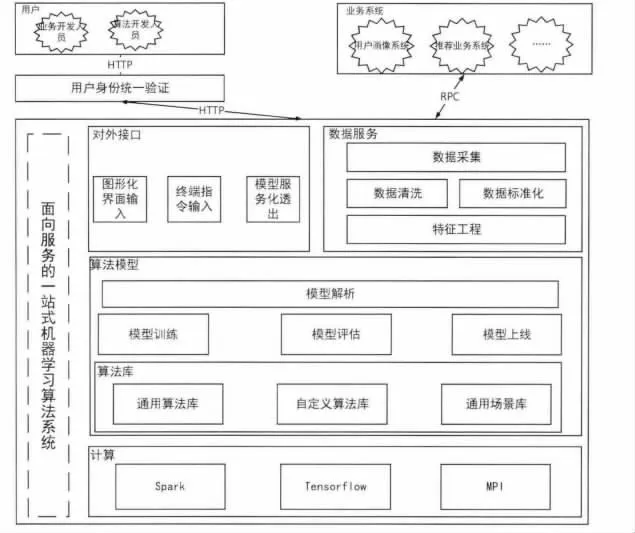
图1 面向服务的一站式机器学习算法系统整体架构图
计算层不仅能够支撑算法模型层,同时也能够实现算法的多样化计算。计算层主要分为三类,分别为spark 大规模数据批处理和流处理框架、Tensorflow为代表的分布式深度学习框架以及MPI 并行计算技术。
2 面向服务的一站式机器学习算法系统的详细设计与实现
2.1 数据采集存储模块
系统数据层的出入口,存在于数据采集存储模块中。该模块可以将不同的数据源交互方式,转变成单一的黑盒模式,借助API,使上层模块,能够操作不同数据源。与此同时,该模块借助多线程并行方式,解决了数据存储介质交互过程中磁盘l/0 以及网络l/O 所造成的等待时间过长问题,从而提升模块的存储性和读取性能[2]。
选择1#样品韵达公司快递包裹袋,剪取面积为0.5 cm×0.5 cm,利用反射法,在相同检测条件下重复测定5次。
2.1.1 数据采集存储模块的详细设计
关于数据采集存储模块的设计,不同的属性对应不同的数据源信息。数据源的IP 地址source IP 端口地址对应sourceport,数据源类型对应sourceType,数据源扩展字段的json 格式对应featureStr,例如mysql 的库名等。为提升读取便利性,feature 所对应的map 形式,是由数据源拓展字段演变而来。
AbstractDataSource 是不同数据源交互方式的抽象父类,shardPolicy 类型是其重要成员。该种类型可以从DataSourceBean的feature 中获得用户分片信息,并根据行列或者文件名进行读取。其中,DataSourcePool 类型主要负责连接数据源,充当有限大小连接池,定义其核心的为po olsize 定义。resize 方法,可以扩充连接池容量,Free 方法,可以销毁并且回收连接池资源。
该模块主要采取的设计思想为Pro actro 模式,从而提升数据读取和存储效率,所使用方法为startTask 方法以及checkDoneQueue 方法,前者主要是用来创建和分发任务;后者主要负责嗅探工作,TaskEventQueue 是任务队列的集合类,一旦发现队列中存在任务,便可完成自动读取任务获取信息。其中,DataSourceTask 是任务载体类别,taskType, taskStatus 以及taskResult 分别对应的是任务类型、状态和结果[3]。
2.1.2 数据采集存储模块的实现
数据任务的执行、调度以及数据源连接资源的分配,是数据采集模块当中较为重要的部分、为实现数据任务的调度控制,需 要 借 助 DataSourceController DataSource' Task 以 及TaskEventQueue 三大类来实现。
第二类,可以有效封装,所有数据任务操作控制数据任务状态变化,同时运用call,wait,wake 三种方法,执行task 的任务,可转化系统状态。其中call 方法主要作用是获取数据源链接,如果获取失败,则可以运用task 以及wake 方法,唤醒沉睡的线程。
第三类,作为任务队列数据结构,包括任务结果队列、等待资源任务队列以及空闲任务队列、正在运行任务队列。第三类是单例,一般不会用在多个线程中,如果是4 个数据结构需要运用线程.ConcurrentHashMap 类和LinkedBlockingQueue 类[4]。
2.2 算法服务模块
2.2.1 算法服务模块的详细设计
Pro cess 方法是ServiceBroker 类用来接收消息,开启算法服务模块流程的关键。ServiceBuilder 类用于创建服务的任务类,其中jobld 指的是模型编号,fileur,指的是模型持久化文件储存位置。
ModelService 类是存在大量实体的外供系统模型服务,主要运用的方法为predict 在线预测服务方法,通过byte 数组以及models 关于jobld 的PredictModel 对象,完成模型预测。其中包含存储模型mpa,即models;检测存储器正确性的mpa,即monitors(图2)。
关于算法服务模块建立算法服务的关键流程节点具体如下:
首先,可靠消息队列会收到来自算法引擎模块的文件储存位置、模型文件大小等模型信息;然后,通过cosumer 位置,借助Process 方法,传送至ServiceBroker 服务器;内存放模型建立单线程ServiceBuilder 任务,将执行模型重放至predictModel 载体类中,在model service 节点机器上添置模型。

图2 算法引擎模块类关键类类型
2.2.2 算法服务模块的实现
算法服务模块的方法包含: ServiceBroker 的process 方法、ServiceBuilder 的run 方法以及ModelService 的addModel 方法。其中,第1 种方法,主要作用是接收消息并判断类型,该方法处理心跳类型的消息便是直接回应消息给对方。而第2 种方法,具有较强的处理逻辑。根据所对应的HDFS 存储位置寻找适宜的HDFS 服务器,读取形式为byte 数组的数据流文件,将其转化为PredictModel 对象,并与manager 节点建立关联,获取modelService 的节点信息,从而选择模型服务节点与业务节点之间的距离作为最合适的节点,部署系统模型,于两个节点之上,用来提供服务和服务备份工作[5]。
3 结论
综上所述,面向服务的一站式机器学习算法系统,可以融合机器学习模型以及传统软件系统,拓展了系统的可修改性,精细优化线程模型。通过设计和实现可算法模型以及数据采集模型,解决代码入侵问题,从而借助伪代码和原生代码,使系统的设计得以实现。
