基于依存关系注意力增强的跨模态检索研究
2021-01-21淦修修彭志颖熊李艳
曾 辉,胡 蓉,淦修修,彭志颖,熊李艳
(华东交通大学信息工程学院,江西 南昌330013)
在信息时代,为了便于人们获取感兴趣的视觉数据,从一个大规模数据库中快速地找到和查询图像内容相关或相似的图像,并按相关的排序返回给用户是很常见的需求。 但是随着多媒体数据,特别是图像视频文字数据,呈爆炸式增长,单纯使用图像来检索图像的单模态检索方式已经难以满足当前用户的需求[1],以互联网上庞大数目的图像视频以及描述性文本等数据为基础的多模态数据研究已经成为当前检索系统领域的研究热点。
目前相关的研究大多利用数据间的共存与互补特征来分析多模态之间的语义理解与关联性表示。 其中典型相关分析(canonical correlation analysis,CCA)[2]是跨模态检索研究中最常用的方法,通过寻找一个线性映射向量能够将映射至相同子空间后的两类模态数据相关系数最大化来实现跨模态检索。Tenenbaum J B 等[3]为跨模态识别提出双线性因子模型(bilinear model,BLM),能够对因子交互进行充分表达,并基于奇异值分解算法来拟合数据。Akaho S[4]就运用了改进的非线性CCA 算法KCCA,即核典型相关分析算法,把核函数的思想引入CCA 中。 Gong Y[5]使用改进的KCCA 算法,但是增加了图像和文本之外的第三类特征—语义关键词。 语义相关匹配[6](semantic correlation matching,SCM)将文本语义抽象化并融合入典型相关分析学习过程中,提高了跨模态检索的准确性。 Jacobs D W 等[7]提出广义多视判别分析方法(generalized multiview analysis,GMA),将特征提取转化为求解广义特征值问题,解决在不同特征空间的联合表示,获得有效的潜在子空间表示,这是CCA 方法的有监督扩展。Kan M[8]在研究中基于神经网络架构而改进典型相关分析CCA 算法,通过多分支的多层神经网络对图像和文本数据进行特征提取, 并将CCA 的优化目标设计成为双分支网络的优化函数。 Wang L[9]设计一个双分支的全连接神经网络(convolutional neural network,CNN)来对图像和文本特征信息分别进行表示学习,进而进行总体的联合嵌入空间表示,作者新颖地使用类间距离和类内距离作为优化目标。 深度学习算法对这类包含位置、色彩、时序性的结构数据拥有很好的特征学习能力,其中卷积神经网络被广泛应用于图像表征的学习。 Diaz-chito K[10]使用CNN 和LSTM 网络对图片和文本进行编码,再嵌入联合空间表示,并通过解码网络来保证各自的信息的重构性。 Karpathy A[11]通过多目标识别算法RCNN对图片样本进行区域切割和文本识别,利用句法依赖树对文本句子样本进行词语切割。 最后比对各片段相似度和整体相似度,通过保证类内差异小,类间差异大来进行模型学习。 然而对于描述图像内容的文本数据来说,真正能够代表图像主要语义内容的只有一个或几个词,即不同的词在语义表达中的重要程度存在差异性。 本文参考注意力机制在机器翻译、图文理解任务中的广泛应用模式,通过对句子依存树结构的片段化处理,添加关于依存关系元组注意力机制,使关键词组片段在文本数据表示时具有更加重要的影响作用,并基于双分支网络结构模型训练,实现跨模态检索任务。
1 模型方法
1.1 模型结构
本文所提的模型框架主要包含3 部分,双分支网络、注意力机制嵌入和联合空间表示。 如图1 所示,双分支网络分别由图像特征输入部分和文本特征表示部分组成,每个分支都存在3 个全连接隐含层,其中使用relu 函数作为全连接层之间对各层输出作非线性映射;注意力机制嵌入部分通过学习基于句子依存关系拆分的不同词组的权重分布,使重要的词组在特征表示中占更多的权重;而联合嵌入表示空间将图像和文本在相同的维度空间内进行表示,从而计算相似性,并通过hinge loss 目标函数来对整个模型进行训练,使对应的图片—句子组合具有更高的相似度。

图1 跨模态检索模型框架Fig.1 Cross-modal retrieval model framework
1.2 注意力机制嵌入
1.2.1 图像表示
现实的图像是通过无数像素点的集合来表示,而单纯的像素点的灰度值无法有效表达图像的高层语义特征,故需要进行图像数据特征向量化。 对于图像数据,本文采用迁移学习的思想,选择当前图像表征效果卓越的卷积神经网络CNN 模型,使用基于CNN 网络架构的VGG 预训练模型[12],从原始图像I 中提取图像特征VI,VGG 模型是由牛津大学计算机视觉组合和Google DeepMind 公司研发的一种16~19 层深度的卷积神经网络,并在2014 年的机器视觉领域顶级学术竞赛(imagenet large scale visual recognition challenge,ILSVRC)中获得分类项目第二名以及图像定位比赛的第一名,目前为止被广泛运用于深度学习中提取图像特征。
如图2 所示,VGG 模型能够有效对图像做特征表示, 而VGG 模型需要输入图像的维度是224×224,本文首先进行图像增强操,用于增加数据量,将图像先统一放缩成256×256 大小,然后分别裁剪左上角、左下角、右上角、右下角和中部5 个位置224×224 大小的图像扩充数据,选择VGG 模型最后一层池化层输出作为图像表示特征向量, 每张图片向量维度为4 096 维。
图像特征提取过程用公式(1)表示,其中I表示原始图像,VI表示提取的图像特征


图2 VGG 预训练模型提取特征Fig.2 VGG pre-training model extraction feature
1.2.2 文本表示与句子依存结构构建
对于文本数据的表示,分为两个方面,一方面需要对句子文本自身作句子向量表示;另一方面需要将句子进行结构拆分,构造出多个子结构区域,用于注意力机制嵌入计算。 文本数据集合用UT表示。
1) 句子向量表示。 对于单个句子文本S(S∈UT),由于句中副词等词语出现的频次较高,会影响句子的语义表达。本文首先对句子进行去停用词处理。句子是由多个词组成,要对句子进行表示首先需要进行词表示,本文使用基于word2vec[13]模型改进的GLOVE 方法训练的词向量来对每个词作词向量表示,经GLOVE训练好的词向量表示维度分别有50 维、100 维、200 维和300 维等,能够根据不同的需求选择不同的向量维度。 本文考虑模型结构和计算的复杂性,选择300 维的GLOVE 词向量来表示每个词vt,然后以整个训练集文本为集合,计算句子中每个词在整个训练集中的TF-IDF 值WTF-IDFt(t∈S),并以每个词的TF-IDF 值作为GLOVE 词向量的权重进行加权求和,如公式(2)所示,最终得到300 维的向量即代表此句子表示向量VS。WTFt表示对应单个句子文本中的某一个词t 在整个训练集中的TF-IDF 值。

2) 基于依存语法拆分句子。 句子结构拆分的目的是将句子拆分成多个元组,每个元组由多个词组成,并且分别代表了某种词组结构关系,这样就能够将句子片段化。因此首先需要对句子作句法结构分析,并确定句子中词汇之间的依赖关系,本文选择当前广泛使用的句法解析工具斯坦福分析器(Stanford Parser)来处理英文文本,获得有效的句子依存结构关系。

图3 短语结构树Fig.3 Phrase tree
句法结构普遍分成两种表现形式,经过分词和词性分析过程后,生成如图3 的树结构,称为短语句法结构树。 短语结构树能够表达句子的句法结构,源自传统的句子图解法,把句子分割成各个组成部分,较大的组成成分能够由较小的组成成分合并得到,由此逐级传递分解。 只有叶子结点代表句子中各个词本身,而其他的中间结点是短语成分的标记,短语结构树能够表示每个词在句子中的所属成分和位置,但是无法直接处理词与词之间的依赖关系。 图4 是简化的图结构。 依存关系树用于表达句子词与词之间的依存关系,依存结构中每个结点都是一个词,通过词之间的连接弧表示词之间的“主谓宾”和“定状补”语法修饰关系,同时由于总体的节点数大大减少,使结构更加简洁清晰。 本文通过Stanford Parser 生成句子依存关系树,获得如图4 中右框中所示的依存关系元组,以TF-IDF 作为词权重加权求和获得句子依存关系元组表示矩阵VQ。
1.2.3 句子依存关系的注意力机制嵌入
不同的词汇依存关系组合对于句子语义表达的重要程度是存在差异的,因此本文在模型中加入注意力机制来学习每个词汇组合表示的权重分布[14],以此反映出句子各片段区域的偏重性,并将其加入句子表征向量中。 如公式(3)所示,首先通过一个单层神经网络对句子表示向量VS和句子依存关系元组表示矩阵VQ进行非线性变换来激活组合,然后通过公式(4)的softmax 函数获得关于各依存关系元组的关注度概率分布。

式中:VQ∈Rd×m,d 代表每个依存关系元组向量的维度,m 是句子元组的数目,即句子经过依存语法拆分后保留的词语组合的个数;VS∈Rd是d 维句子表示向量。 设定映射参数矩阵WQ,A,WS,A∈Rk×d以及WP∈Rl×k,通过softmax 函数计算后得到PI∈Rm的m 维向量,表示此句子每个依存关系组合片段的注意力概率值。 由于WQ,AVQ∈Rk×d是k×m 的矩阵而WS,AVS∈Rk是k 维向量,故将矩阵的每一列分别与该向量进行求和,得到hA∈Rk×m。 WQ,A,WS,A,WP,bA,bP是通过模型学习得到的参数。 PQ表示每个依存关系词组对于句子语义内容的重要性度量。
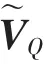

1.3 目标函数
图像、文本数据分别用X,Y 表示,对于给定的训练集图像样本xi,设定文本样本yi和yi-,它们分别表示与图像xi正确匹配的文本和不正确对应的文本,E(xi),E(yi),E(yi-)分别代表各自的嵌入空间的最终输出向量。 跨模态检索的目标是期望E(xi)与正确文本E(yi)之间的相似度比E(xi)和E(yi-)之间的相似度更高,如公式(6)所示

其中m 是阈值参数,表示两者相似度期望的差值,设m=0.3。 Sim(·)表示两者相似性计算函数,本文采用余弦函数作为相似度计算方式,通过计算向量之间的余弦夹角体现相似程度。 如公式(7)所示

同样,对于给定的文本数据yi来检索相关图像,如公式(8)所示

对于图像检索文本过程,三元组{xi,yi,yi-}损失函数L(xi,yi,yi-)定义如下

对于文本检索图像过程,损失函数计算方式定义
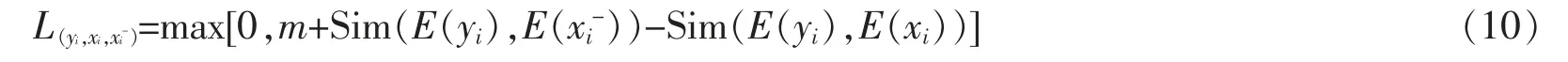
因此,使用hinge loss 函数方法定义图像分支xi与文本分支yi联合损失,如公式(11)所示

故定义模型的总损失LX,Y如下

其中N 是测试集样本数。
2 实验结果与分析
2.1 数据集
本文选择公共数据集Flickr8K 和Flickr30K 用来对所提算法进行实验评估,Flickr8K 和Flickr30K 是图片分享网站Flickr 上筛选出的专门用于图像研究的公共数据集,分别包含8 000 和30 000 幅图像,每幅图像使用标5 个独立的描述句子标注,数据集样本的内容如图5 所示。

图5 数据集表示Fig.5 Dataset representation
2.2 评估方法
本文采用排序问题评价指标P@K 对算法性能进行评估,计算方式如下

P@K 用于判断检索排在前k 位的相关性,N 是测试集样本数, 若在检索结果中排序前k 个中有正确对应的样本,则δ(k)=1 表示检索正确。
2.3 实验设置
在模型训练过程时通过交叉验证方式选取最优实验参数设置,选择随机梯度下降方法(stochastic gradient descent,SGD)优化目标函数,学习率设置为0.01,隐含网络层激活函数选择relu 函数。 嵌入表示空间维度为300, 即将每类模态数据最终使用300 维的向量进行特征表示, 从而计算相似度。 每层隐含层之后的dropout 方法的节点丢弃率设为0.5,以分批度训练的方式训练样本,每个批度数据数目设为100,每个单分支网络的3 层全连接网络层的神经元节点数设置为1 000*1 000*1 000。
2.4 实验结果分析
本文分别使用4 种算法与所提算法VSDA 进行实验对比,其中“CCA”是典型相关分析算法,是一种经典的无监督关联学习方法,通过最大化不同模态间在投影子空间的相关性实现匹配。 “SCM”是语义关联匹配方法,基于CCA 方法学习子空间映射,再基于多标签的逻辑回归方法学习不同模态间的语义匹配。 “KCCA”是一种将核函数思想引入CCA 进行高维映射的方法。 “DCCA”是基于典型相关分析理论的深度网络改进模型。 结果如表1 所示。

表1 各算法实验结果Tab.1 Experimental results of various algorithms
表1 是各类算法在Flicker8K 和Flicker30K 数据集下的P@K 指标的实验结果,分别对给定文本的情况下检索与文本内容匹配的图像,和给定图像的情况下查找与图像内容匹配的相关文本。 整体来说,本文所提的VSDA 算法相较于其他对比方法无论是P@1、P@5 还是P@10 的检索准确率都有一定程度的提高, 尤其是相比于CCA、SCM、KCCA 算法,在P@5 和P@10 指标上效果提升显著,可能是神经网络模型在异构数据之间具有复杂关系情况下对比于传统理论模型拥有更强大的学习能力。 其次,检索准确率普遍非常低,但是对于检索任务来说,其目的类似于推荐系统形式是为用户提供合理的检索结果集合,对于Top1 即正确对应的样本一定要排序在首位的需求并不是必须, 故P@1 的结果偏低是可以接受的。 随着数据量的增加,由Flicker8K 的8 000 张图片到Flicker30K 的30 000 张图片, 本文的VSDA 算法和DCCA 方法的Text 检索Image、Image 检索Text 的检索准确率都有可观的提高,然而其他方法的检索准确率普遍都有相对应的降低,说明VSDA 算法在大数据集情形下同样可以获得好的性能。 对比VSDA 算法和DCCA 方法,Flicker8K 数据集和Flicker30K 数据集的各项指标都高于DCCA 方法,而DCCA 方法同样是使用双分支网络结构,说明本文所提的VSDA 算法针对句子依存关系注意力机制的嵌入改进是具有可行性的。
3 结论
本文针对跨模态多媒体检索领域中图像与文本之间的互检任务,考量句子文本的不同片段对于整体语义表达具有不同的偏重性,通过基于依存关系结构的句子拆解,嵌入注意力机制从而学习各片段元组的权重分布,并设计双分支神经网络模型实现跨模态检索。 实验结果表明该方法的检索准确率相比于其他算法有着显著的提高。 未来的研究工作将从以下两个方面去考虑:①模型学习主要采用的是全连接网络,可以考虑替换成其他更优越的模型架构,可能获得更好的效果;②可以考虑图像和文本之间是否存在其他联系。
