基于长短期记忆网络的城市建筑垃圾产量预测
2021-01-21孙柯华吴晓南刘弘昱
孙柯华,蔡 婷,王 伟,吴晓南,刘弘昱,郑 虢,
(1. 上海交通建设总承包有限公司,上海200136;2. 四川大学商学院,四川 成都610064;3. 河海大学港口海岸与近海工程学院,江苏 南京210098)
随着城市化建设和老旧城区改造的不断深入,建筑垃圾产量不断增长。 据统计,近几年中国建筑垃圾的年排放总量为15.5~24 亿t,约占城市固体垃圾总量的40%,但国内建筑垃圾的处理仍处在相对粗放的填埋及堆放阶段。 研究发现,通过有效规划和技术措施,大部分建筑垃圾是可以作为再生资源而被重新利用的。
因此,建筑垃圾资源化被认为是消化城市垃圾的有效途径,而建筑垃圾量化方法是实现建筑垃圾资源化管理的基础,其中预测建筑垃圾产生的趋势和变化对政府提前估测垃圾填埋场容量和制定相关政策具有重要的指导作用。 2014 年,Wu 等[1]对现有的建筑垃圾管理文献进行了广泛回顾,并指出目前对建筑垃圾产量的预测研究较少,用于预测的支持信息不足,应投入更多的精力研究该课题。 基于此,本文以建筑垃圾产量为切入点进行预测分析。
1 文献综述
建筑垃圾产量的历史数据多呈时间排列,能够展示系统的动态演化过程,在样本量充足的情况下,可以采用多种数据驱动的方法进行预测,比如多元线性回归(multiple linear regression,MLR)、灰色模型(grey model,GM)、支持向量机回归(support vector machines regression,SVR)、人工神经网络(artificial neural network,ANN)等。
2013 年左浩坤等[2]、2014 年张红玉等[3]均采用估算的历史数据分别建立ARIMA、GM 模型,这些模型能很好地拟合和预测持续增长且较规则的曲线。对于复杂且不规则的时间序列,2012 年吴泽洲[4]首先在城市建筑垃圾生成量预测方面引入基因表达式编程技术(gene expression programming,GEP),并结合时间序列模型与因子回归模型的优点。 2013 年Antanasijevic 等[5]建立反向传播神经网络(back propogation neural network,BPNN)和广义回归神经网络(general regression neural network,GRNN)模型用于城市固体垃圾预测,证明GRNN 模型明显优于传统的BP 神经网络模型,而且在长期预测中也保持较高的稳定性。 2016 年Abbasi 等[6]证明了自适应神经模糊推理系统 (adaptive neuro-fuzzy inference system,ANFIS)、K 最近邻 (K nearest neighbours,KNN)回归和SVR 模型可用于建立预测模型,并可提供准确可靠的月度垃圾生成预测,而且ANFIS 模型比KNN 和SVM 模型具有更高的预测精度。
考虑到单一模型的局限性,2009 年李志涛等[7]引入变权重组合的思想,结果表明该模型的预测效果优于一元线性回归法、指数平滑法、GM 模型等各单项模型。 2014 年,袁媛[8]首先提出将主成分分析(principal components analysis)与隐马尔可夫模型(hidden markov model,HMM)结合的预测方法,解决了小样本垃圾量预测问题。 2017 年,Song 等[9]建立PCA-SVR 的组合预测模型,该方法从原始数据中提取特征成分后进行建模和预测,得出了比单一模型更好的实验结果。 但在实际应用中,组合预测方法存在构建过程复杂、人工依赖性强的缺点。
随着我国城市化进程的迅猛发展,我国城市建筑垃圾产量数据呈现出复杂的非线性特征。 另一方面,由于我国城市建筑垃圾产量数据的统计口径和数据保存等方面的原因,我国各主要城市的统计数据中的建筑垃圾产量数据量非常有限,常规的时间序列预测方法往往难以从如此少量的数据中捕捉数据蕴藏的复杂规律。
近年来, 基于深度学习的预测方法逐渐被应用到时序数据的研究中, 尤其是循环神经网络(recur rent neural network,RNN)在时序分析中表现出较强的适应性。 长短期记忆(long short-term memory,LSTM)网络作为典型的RNN 变体,能够比RNN 更好地表达长短时依赖,有效地解决了RNN 梯度消失、梯度爆炸以及长期记忆快速衰弱等问题,且可适用于较少数据量的预测问题。LSTM 模型已成功应用于不同领域的时序数据研究中,包括机器翻译、语音识别、交通流预测[10]等,其有望为历史数据量少的建筑垃圾产量预测问题提供有效的解决方案。而在城市建筑垃圾的时序预测这一问题,LSTM 模型的应用还未见报导。
针对建筑垃圾的时间序列数据, 本实验提出了一种基于3 层网络结构的LSTM 神经网络的预测方法,对网络设计、网络训练和网络预测的实现算法进行详细描述,并通过数值实验与多种时间序列预测模型进行对比。
2 长短期记忆网络
长短期记忆网络是循环神经网络的一种,其本质是对标准RNN 结构的改进, 区别在于标准的RNN 细胞结构中只有一个门限函数,而LSTM在隐藏层的细胞结构中引入了3 个重要的门限函数[11],如图1 所示。
LSTM 在前向传播过程中, 通过隐藏层细胞结构中的3 个门限来控制信息的保存和交互。 其中,遗忘门(forget gate,ft)控制上一时刻的单元状态需要丢弃的信息;输入门(input gate,it)控制当前时刻信息的输入过程;输出门(output gate,ot)控制当前单元状态的过滤输出。
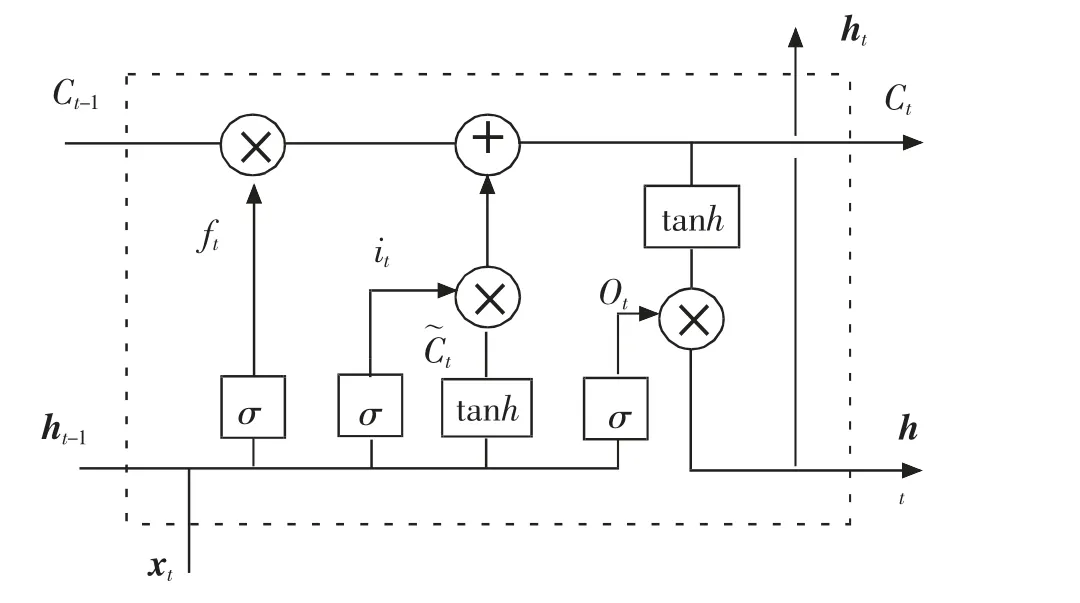
图1 LSTM 隐藏层细胞结构Fig.1 LSTM cell structure in hidden layer
3 个门限的计算公式为[12]

对于当前时刻细胞状态信息的更新公式为

根据遗忘门与输入门的共同作用,当前时刻细胞状态Ct表示为

返回至隐藏层的信息ht为

式中:x 表示输入向量;h 表示输出向量;C 表示细胞状态;σ 为sigmoid 激活函数;tanh 为激活函数;W,b 表示相应的权重和偏差矩阵。
LSTM 模型在训练过程中使用基于时间的反向传播(backpropagationthroughtime,BPTT)算法[13],具体步骤如下:
Step1:利用式(1)~式(4)计算前向传播过程中的输出值;
Step2:反向计算每个LSTM 细胞的误差项,包括层级间的纵向传播和时间上的横向传播;
Step3:根据相应的误差项,求解每个权值的梯度;
Step4:采用基于梯度的优化算法更新权重。
3 基于LSTM 网络的建筑垃圾产量预测模型
基于单变量时间序列有限样本点的数据特征,以及RNN 从简的设计原则,LSTM 模型整体框架如图2所示,包括输入层、LSTM 隐藏层、输出层、网络训练以及网络预测。 输入层对原始时间序列进行预处理以满足网络的输入要求, 经处理后的数据通过LSTM层、全连接层后获得预测结果。 全连接层选择sigmoid 激活函数,以均方误差(mean square error,MSE)作为损失函数,采用Adagrad 优化算法[14],并以递归方式进行逐点预测。
为实现单变量时间序列的预测问题,通过创建滞后观察列和预测列可将时间序列转化为监督学习问题, 即使用步长为k 的序列 (yt-k,yt-k+1,…,yt-1) 作为网络输入来预测当前t 时刻的观测值yt,其预测模型表示为

损失函数Loss 表示为
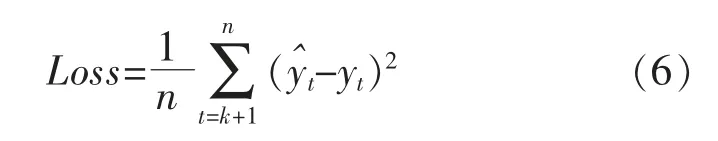
图2 基于LSTM 的时间序列预测框架Fig.2 LSTM framework for time series prediction
4 数值实验
基于上海市建筑垃圾产量的历史数据建立预测模型。 由于上海市统计年鉴从2012 年开始才将工程渣土纳入建筑垃圾范畴,实验数据使用上海市1980—2011 年共32 年的建筑垃圾产量数据。
4.1 实验准备
4.1.1 数据预处理
1) 异常值处理。 异常值指远离正常值范围的数据点,一般采用散点图或是箱形图进行识别。 由于实验数据维度体量较小,且异常值处于数据集末端,将异常值按缺失值插补处理,避免因剔除造成样本量不足。故使用前5 个数据点(包括异常点)的均值进行插补,如图3 所示。
2) 数据分割。 数值实验中使用hold-out 交叉验证,即按照时间顺序切分,设定前27 个数据点作为训练集(2007 年以前的数据),后5 个数据点(2007—2011 年数据)作为训练集。
3) 数据标准化。 数据标准化能够消除输入数据的量纲差异,同时加快模型的运算速度。 故采用Min-Max 标准化将输入数据映射在[0,1]之间,用公式表示:y*=(y-ymax)/(ymax-ymin),其中,y 为输入数据,y*为归一化数据,ymax,ymin为输入数据中的最大值与最小值。 对于预测模型的输出结果也需进行反标准化处理,使预测得到的数据符合实际范围和意义。

图3 异常值处理示意图Fig.3 Schematic diagram of outlier handling
4.1.2 评价指标
为减少单一指标对模型性能评价的局限性,采用3 项指标对预测模型进行综合考量。
1)决定系数(coefficient of determination,R2),表示响应变量的变异部分,可由输入变量的变异解释的百分比。

2) 平均绝对误差(mean absolute error,MAE),评估真实值和预测值之间的接近程度。

3) 平均绝对百分误差(mean sbsolute percentage error,MAPE),衡量相对误差,可用于比较不同范围数据集间的预测效果。

式中:yt,分别为t 时刻真实值与模型输出的预测值;为yt均值。
4.1.3 对比模型
本实验选取以下3 类预测模型用于实验对比分析。
1) 岭回归。 岭回归(ridge regression,RR)是在一般线性回归模型中加入L1 正则化防止过拟合的方法,其时间序列预测模型与MLR 结构类似[15],可以表示为:Yt=a0+a1Yt-1+a2Yt-2+…+akYt-k+e,其中,Yt表示t 时刻的预测值,a1,a2,…,ak分别为不同时刻Yt-1,Yt-2,…,Yt-k的回归系数,a0和e 分别为偏置项和误差项。经试凑,选定输入序列步长k 取4,同时设定岭回归模型的正则化系数为0.5。
2) 支持向量机回归。 SVR 通过非线性核函数将低维数据映射到高维的空间后执行回归运算,从而得到与输出指标的非线性映射关系[16]。SVR 模型选取高斯径向基函数(gaussian radial basis function,RBF)作为非线性核函数,并设定惩罚因子为1,输入序列步长取3。
3) 人工神经网络。 3 层BP 神经网络对于非线性数据具有良好的逼近性能[17],故采用3 层神经网络,预置输入层神经元数为4,即输入序列步长为4,输出层神经元数为1,经试凑确定隐藏层的最优神经元个数为6,层级之间均采用sigmoid 激活函数。 网络训练时采用随机梯度下降算法,学习率为0.08,最大迭代次数为2 000,期望误差为1e-6。
4.2 实验结果
4.2.1 模型参数分析
本实验设计的LSTM 模型为3 层,分别为输入层、LSTM 隐藏层和输出层。 其中输入层和隐藏层的节点规模对网络规模有着极大影响,经试凑确定隐藏层神经元数目n 为64,输入时序的步长k 为2。
由于LSTM 隐藏层神经元数目较多,模型复杂度较高,可能造成过拟合现象,导致模型泛化性能较差,故采用Dropout 方法[18],即在LSTM 隐藏层后添加Dropout 层, 随机使一部分神经元失效,不让它们进行前向和后向传播的更新,可以在一定程度上避免过拟合。 通过设定不同的失效概率p, 比较其在测试集上的损失值来确定其最优概率,如图4 所示。
当模型未添加Dropout 层时,测试集的Loss最大,但当Dropout 层概率设置为0.2 时,测试集数据的Loss 最小,训练效果在测试集上达到最优。
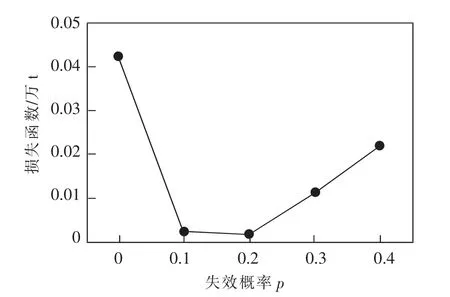
图4 不同失效概率下测试集的损失值Fig.4 Loss of test set under different dropout probability
4.2.2 预测结果及对比分析
根据上文确定的LSTM 网络结构及参数,模型训练后得出训练数据的拟合值,并以递归的方式对测试集进行逐点预测,得到2007—2011 年相应的预测值。 为了定量分析不同模型的拟合和预测性能,采用4.1.2节的评价指标进行对比分析,如表1 所示。
对于训练集而言,LSTM 模型在MAE,MAPE 指标上的得分明显优于其他模型, 指标R2与BPNN 得分相同,RR,SVR 模型总体表现较差。

表1 不同模型的拟合和预测性能对比(上海)Tab.1 Comparison of fitting and prediction performance of different models(Shanghai)
图5 和表1 以直观的方式展示了LSTM 模型与各对比模型的预测值与误差结果。 图5 显示,RR,SVR与BPNN 模型的预测曲线趋于平稳, 无法对2011 年的数据进行准确预测, 从而产生较大的预测误差;而LSTM 模型对2011 年的数据预测效果较好,但对2010 年数据的预测均存在较大误差。从整体的预测曲线来看,LSTM 模型更接近真实数据的变化趋势。
通过表1 数据可以进一步对比LSTM 模型和其他预测模型在测试集上的性能。 以LSTM 为例,其对应的R2指标值均高于其他预测模型,其余指标值均低于其他预测模型。 由此可见,LSTM模型在测试集上很好地跟踪了真实数据,达到了比较理想的预测效果。
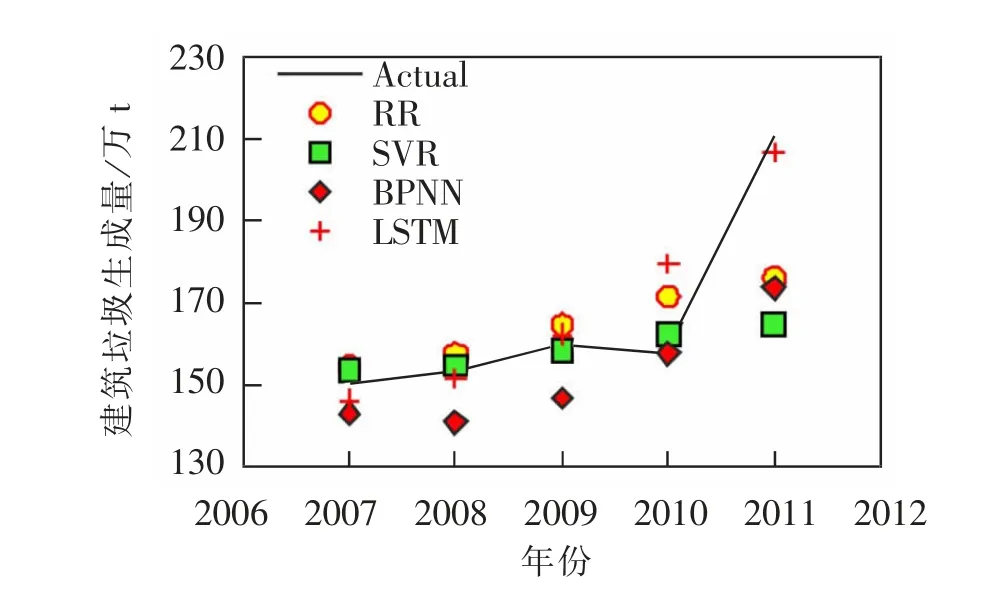
图5 不同模型在测试集的预测结果Fig.5 Prediction results of different models for test sets
由于上海市统计数据的限制,用作训练和预测的建筑垃圾产量数据只到2011 年且不包括工程渣土量。 对2012—2017 年的建筑垃圾产量做进一步预测,利用LSTM 模型的预测结果如表2 所示。 通过折算将2012—2017 年建筑垃圾(含工程渣土)的历史数据转化为建筑垃圾(不含工程渣土)的产量数据,折算系数为1980—2011 年建筑垃圾(不含渣土)产量均值与2012—2016 年建筑垃圾(含工程渣土)产量均值之比,LSTM 模型的预测结果与折算后建筑垃圾(不含渣土)生成量变化趋势类似,两趋势线的相关系数R=0.87,也可从侧面验证预测结果的可靠性。图6 展示LSTM 模型在训练集和测试集上的拟合和预测结果以及2012—2017 年建筑垃圾产量的变化趋势。

表2 2012—2017年预测值Tab.2 Forecast for the next 6 years
为了进一步验证所提出的方法对其他城市建筑垃圾产量预测的适用性,利用香港建筑垃圾产量数据进行实验,数据来源于香港环境保护署的减废统计处,截取1986—2016 年共31 年的建筑垃圾年产量数据。 实验结果如表3 所示,对于训练集和测试集而言,LSTM 模型在R2,MAE,MAPE 指标上的得分均明显优于其他模型,即LSTM 模型能提供优于对比模型的预测精度,进一步表明所提出方法的有效性和准确性。
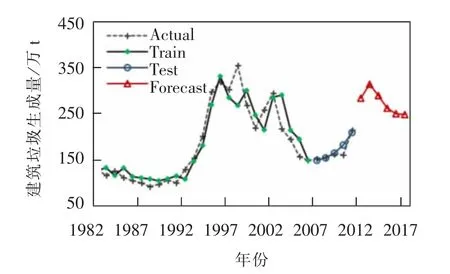
图6 LSTM 模型的拟合和预测结果Fig.6 The fitting and prediction results of LSTM model
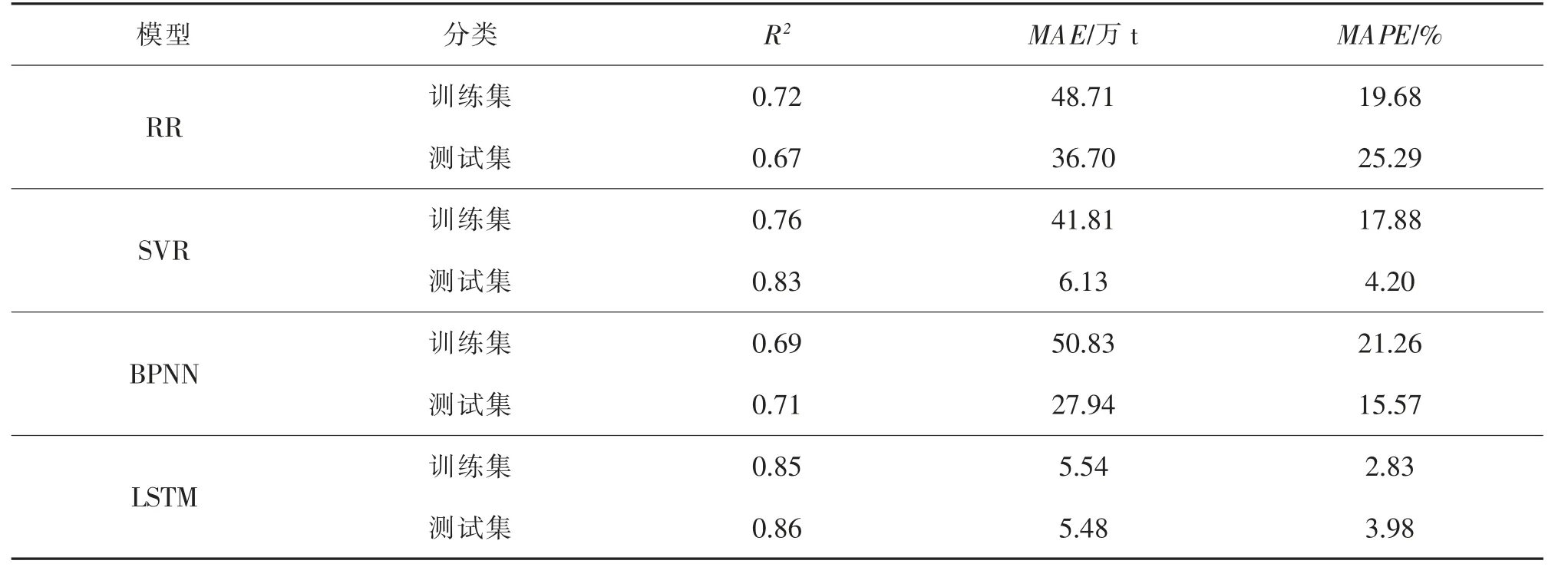
表3 不同模型的拟合和预测性能对比(香港)Tab.3 Comparison of fitting and prediction performance of different models (Hongkong)
5 结论与展望
5.1 结论
1) 预测建筑垃圾产量是地方政府管理建筑垃圾填埋场和制定建筑垃圾管理政策的基础。 目前的文献综述表明,针对这一类预测问题的方法及其准确性仍有待提高。
2) 针对城市建筑垃圾产量可利用的数据量较少且数据非线性程度高等特点, 提出了含Dropout 层的LSTM 网络对有限样本点的单变量时间序列进行预测,与回归模型和神经网络模型进行比较,证明LSTM 对单变量非线性预测问题的建模非常有效。 对于常规LSTM 模型容易产生过拟合的问题, 通过添加Dropout层,有效地解决了此问题,提高模型的泛化性能。
3) 本实验验证了LSTM 模型在建筑垃圾预测领域的适用性,扩展了深度学习技术的应用范畴,对建筑垃圾量化和管理具有重要的理论和实践意义。
5.2 展望
由于我国城市的建筑垃圾数据难以获取,仅通过上海和香港的数据对所提出方法进行了验证。 未来的研究可将所提出的方法应用于其他城市的建筑垃圾产量预测和其他领域的预测问题,也可以比较多种网络训练优化算法的应用效果,如Adam,Rmsprop 算法等。
