基于智能手表的疲劳驾驶监测方法研究
2021-01-21杨萍茹廖龙涛孙棣华王正江
杨萍茹,黄 勇,廖龙涛,孙棣华,陈 希,王正江
(1.重庆城市综合交通枢纽开发投资有限公司,重庆 401121;2.重庆大学 自动化学院,重庆 400044;3.重庆市公共交通控股(集团)有限公司,重庆 401121)
目前我国机动车保有量已经突破2亿,车辆的增多及交通设施的完善给人们的出行带来了巨大的便利,但是也引发了一系列的交通事故。据有关统计数据,在各类事故死亡人数中,交通事故死亡人数所占比例为78.5%。其中,驾驶员疲劳造成交通事故的占总数的20%左右,占特大交通事故的40%以上[1]。
如果驾驶员在疲劳状态下驾驶车辆,不仅自己的人身财产安全存在隐患,而且容易对其他行人及车辆造成安全影响。因为疲劳驾驶所引发的交通事故并不是在驾驶员刚刚产生疲劳时就发生,所以可以通过一种疲劳驾驶监测手段在驾驶员产生疲劳时进行预警提示,从而使得驾驶员可以采取一定的预防措施,以避免事故发生。
现有研究中有多种方式能够实现疲劳驾驶监测,总结起来主要包括3种:①基于驾驶员面部特征的检测(如眼睛的闭合状态、面部表情、眨眼速度等);②基于驾驶员生理特征的检测(如心电信号、脑电信号以及肌电信号等);③ 基于驾驶行为的检测(如方向盘转角、车辆位置、车辆加减速等)。WierwiIIe[2]最早基于模拟实验提出PERCLOS(一定时间内眼睛闭合时间所占的比值)指标用于驾驶疲劳识别,后来研究表明该指标是疲劳识别最有效的指标之一。Mbouna等[3]从驾驶员脸部视频各片段中提取了EI(眼睛闭合度)、PA(瞳孔偏离率)和HP(头部姿态偏差)等3类眼睛和头部特征,并基于SVM建立疲劳识别模型后验证其平均错误识别率为5.16%。王琳等[4]从肌电信号和心电信号中提取出肌电信号复杂度、心电信号复杂度和心电信号样本熵等3个特征参数,并基于多元回归理论建立了判定驾驶疲劳的数学模型,该模型准确率达90%以上。万蔚等[5]对车辆速度、方向盘转角和车辆横向位置的样本熵进行了分析,从中提取了该3类参数的样本熵特征,并构建了基于BP神经网络的驾驶员疲劳驾驶判别算法。
基于驾驶员面部特征的方式可以有效监测疲劳驾驶,且对驾驶员操作不具有入侵性,但是驾驶员由于受到监视而会对此类识别方式产生抵触,且该方式会受到驾驶员肤色、外界光照以及佩戴眼镜等因素的影响。生理信号能够直接反应人体的生理状态,基于驾驶员生理特征的疲劳检测被认为是最直观、最准确的检测方法[6]。但是在采集驾驶员的生理信号时,设备会与驾驶员有接触,从而给驾驶员的操作带来影响,不利于安全驾驶,且信号采集设备也十分昂贵。基于驾驶行为的检测方法则能够有效避免前2种方式的不足,受到了众多研究者的重视,但是该方式目前大多是基于仿真研究的,部分数据在实际中不易获得,而基于实车的研究又需要在车辆上安装多种传感器,存在一定实用局限性。
针对基于驾驶行为检测方法的缺点,考虑到智能手表日益普及,其附带的传感器能够有效监测人体手部运动,因此,本文考虑使用智能手表感知驾驶员的转向行为信息,从中提取出有效疲劳特征指标并基于分类模型实现疲劳识别。该方式不需要依赖车载传感器,且研究成果可以以APP的形式安装在智能手表中供驾驶员使用,成本更低、实用性更强、智能化水平更高。本文采用KSS量表,综合多人主观评价,给采集到的驾驶数据打上“正常驾驶”或“疲劳驾驶”的标签,并将这些数据作为训练集,利用随机森林方法训练本文提出的基于智能手表的疲劳驾驶监测方法。实验结果表明本文提出的方法能够准确感知转向差异并判断驾驶员的驾驶状态。
1 实验
实验以重庆大学车车协同仿真平台为实验平台,将智能手表佩戴在驾驶员左手手腕处,采集10名驾驶员在正常和疲劳状态下手腕运动的加速度和角速度数据。
1.1 平台搭建
模拟驾驶平台是利用虚拟现实仿真技术营造虚拟的驾驶训练环境,人们通过模拟器的操作部件与虚拟的环境进行交互。本文所进行疲劳驾驶实验是基于重庆大学教育部重点实验室T-CPS车车/车路协同仿真平台,该平台由3台驾驶模拟器和1台仿真工作站服务器组成,如图1所示。每台驾驶模拟器均具有可变转向力反馈方向盘、虚拟仪表显示、油门踏板、刹车踏板、自动档换档杆、电动座椅和转向灯开关等,同时驾驶模拟器利用3块显示屏拼接而成,进行实时交通场景交互。该平台采用的是PreScan虚拟交通场景设计与仿真软件,通过与Matlab中Simulink等软件联合实现在环驾驶仿真。
1.2 场景设置
本文招募了10名志愿者(编号1~10)进行疲劳驾驶实验,包括8名男性和2名女性,年龄分布在22~35岁(均值26.5岁),驾龄分布在2~8 a。实验选用容易产生疲劳的高速公路这种单调场景,道路长63 km,双向4车道,车速保持在80±10 km/h,在驾驶过程中需要减少变道和超车行为。仿真场景如图2所示。
1.3 实验步骤
实验需要进行正常驾驶和疲劳驾驶2个阶段,每名志愿者均需要进行这2个阶段的实验。为了避免正常和疲劳驾驶实验之间造成干扰,2个阶段的实验需要间隔一定的时间进行,具体实验顺序如表1所示。

表1 实验顺序
第一阶段为正常驾驶实验,要求志愿者保持充足的睡眠,并且在大脑比较清醒的上午9点开始进行。第二阶段实验为疲劳驾驶实验,要求志愿者在实验前睡眠较晚且不充足,并且在大脑较为疲劳的下午1点开始进行。2个阶段的实验均需要进行1 h。实验前需要每名志愿者充分熟悉驾驶环境,并且在实验过程中需要将智能手表佩戴在左手手腕处,且手握方向盘的位置如图3所示。实验过程中除了采集智能手表加速度和角速度数据以外,还需定期填写KSS疲劳评测问卷[7]以及实时记录驾驶员的面部视频,以便后期对驾驶员的驾驶状态进行标定。
1.4 评价标准
文献[8-9]的研究表明,驾驶员的主观自评与基于面部视频的主观他评具有较高的一致性,通过综合驾驶员本人及他人的主观评价,可以达到相对客观的疲劳判定。另外,驾驶员在疲劳驾驶和正常驾驶时,对车辆的操控能力会有所不同,这一差别可用作客观评价指标。为了提高对驾驶员状态评定的准确性,本文通过采用调查量表,结合驾驶员的主观自评和基于面部视频的主观他评进行疲劳驾驶评定。首先将某段样本数据对应的根据KSS量表(如表2所示)自主评定的状态等级(记为KRATE)作为参考值,当KRATE≤3时则表示处于正常状态,当KRATE≥7时则表示处于疲劳状态,然后与文献[10]基于面部视频的评价方式所得结果进行对比,当2种方式所得结果不一致时则舍弃该样本,否则保留该样本。
2 数据分析及特征提取
2.1 数据分析
已有研究发现,随着疲劳程度的加深,驾驶员对车辆的操控能力会降低,表现为对方向盘的修正频度降低,修正的幅度增大。下面以不同驾驶状态下所采集的加速度数据进行对比分析。图4为正常驾驶和疲劳驾驶状态下的加速度数据变化图,可以发现,正常驾驶情况下,X轴、Y轴和Z轴加速度值会不断变化,且变化的幅值较小;而在疲劳驾驶情况下,X轴、Y轴和Z轴加速度值的波动变小,甚至长时间几乎不变,而会伴有较大幅度的变化。因此,可以通过一些量化的特征参数来表征这种数据变化差异,进而实现区分不同的驾驶员状态。
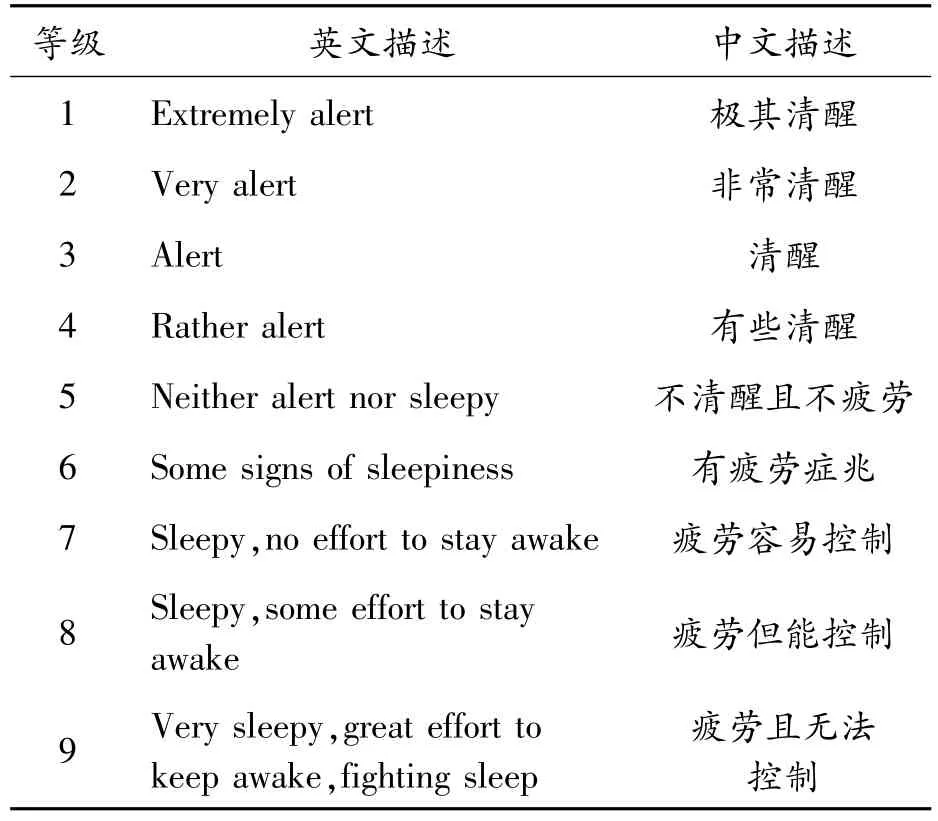
表2 KSS量表等级描述
2.2 特征提取
从前面的分析中可以看出数据波动具有差异,可以利用统计特征来描述这种差异,常用的统计特征包括均值(Mean)、方差(Variance)和均方根(Root Mean Square)。
均值是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。它是反映数据集中趋势的一项指标,其数学定义为:
方差是衡量随机变量或一组数据离散程度的度量,其数学定义为:
均方根能够描述数据相对于零值的波动情况,其数学定义为:
此外,样本熵(sample entropy,SampEn)是由Richman和Moornan提出的一种新的时间序列复杂性度量算法[11],比近似熵更具有相对一致性。样本熵有较好的抗噪抗干扰能力,只需较短的数据就能达到有效分析的目的,运算时间短,对确定性信号和随机信号都适用,是非线性动力学时间序列研究的有力工具。本文中通过计算驾驶员驾驶过程中各个指定时刻所有被试者心电信号的样本熵,以此作为表征驾驶员疲劳的特征参数,可用SampEn(m,r,N)来表示,其中m为维数,r为相似容限,N为长度。相关研究指出[12],当m=2,r=(0.1~0.2)SD时,样本熵的结果较为合理,SD为原始数据的标准差。样本熵算法如下。
步骤1设N点原始时间序列为:x(1),x(2),…,x(N),按顺序组成一组m维矢量为:
步骤2定义Xm(i)和Xm(j)间的距离d[Xm(i),Xm(j)]为 对 应 元 素 差 值 最 大 的 一个,即:
步骤3给定阈值r,对每一个i≤N-m值,统计d[Xm(i),Xm(j)]<r的数目(模板匹配数),然后计算此数目与距离总数的比值,用表示,即:
步骤4求对于所有i的平均值,即:
步骤5将矢量维度m改为(m+1),重复步骤1~步骤4,得B(m+1)(r),则此序列样本熵为:
当N为有限值时,样本熵可表示为:
根据以上特征提取理论知识,本文提取了智能手表XYZ轴绝对加速度的均值(3个轴分别记为MAAX、MAAY和MAAZ)、绝对加速度的方差(3个轴分别记为VAAX、VAAY和VAAZ)、合成加速度均方根值(记为RMSA)、绝对角速度的均值(3个轴分别记为MAPX、MAPY和MAPZ)、绝对角速度的方差(3个轴分别记为VAPX、VAPY和VAPZ)、合成角速度均方根值(记为RMSP)、绝对加速度样本熵(3个轴分别记为SEAAX、SEAAY和SEAAZ)、合成加速度样本熵(记为SEA)、绝对角速度样本熵(3个轴分别记为SEAPX、SEAPY和SEAPZ)和合成角速度样本熵(记为SEP)。
3 疲劳监测模型
随机森林属于非线性拟合模型,训练速度快,可以用于大规模数据集,且不易陷入过拟合状态,具有一定的抗噪声能力。由于驾驶员与驾驶无关的手部动作(如抓痒等)较多,提取的智能手环数据存在噪声。并且,疲劳与转向行为特征之间存在复杂的非线性关系。因此,本文采用随机森林(random forest,RF)理论对疲劳检测进行模型建立。
3.1 RF理论
随机森林算法是Breiman于2001年提出的一种集成学习算法,具有处理高维小样本数据时不容易过分拟合、分类性能优良等特点。随机森林以分类回归树CART为基本分类器,并且包含多个由Bagging集成学习技术训练得到的决策树,当输入待分类的样本时,最终的分类结果由单棵决策树的输出结果投票决定[13,14]。随机森林算法的基本步骤如下:
步骤1从原始训练集S={(xi,yi)}(i=1,2,…,n)中bootstrap抽样生成k个训练样本集,每个样本集是每棵分类树的全部训练数据。
步骤2每个训练样本集单独生长成为一棵不剪枝叶的分类树hi。在树的每个节点处从M个特征中随机挑选m个特征(m≤M),在每个节点上从m个特征中依据Gini指标选取最优特征进行分支生长。这棵分类树进行充分生长,使每个节点的不纯度达到最小,不进行通常的剪枝操作。
根据生成的多个树分类器对新的测试数据xi进行预测,分类结果按每个树分类器的投票多少而决定,即分类公式为:
式中:majorityvote表示多数投票;N tree表示随机森林中树的个数。在训练过程中每次抽样生成自助训练样本集,原始训练数据集中不在自助样本中的剩余数据被称为袋外数据(out-of-bag,OOB),OOB数据被用来预测分类的正确率,每次的预测结果进行汇总得到错误率的OOB估计。
随机森林的边缘函数为:
随机森林的泛化误差上界为:
式中:ρ为相关系数的均值;s为分类器的强度,s=Ex,ymr(x,y)。随机森林通过在每个节点处随机选择特征进行分支,最小化各棵分类树之间的相关性,提高了分类精确度。
3.2 模型训练
本文以10 s为时间窗,从实验所采集的数据中提取了前面的各个特征,共得到3 200组正常驾驶样本和2 600组疲劳驾驶样本。本文从样本中随机选择2 240组正常驾驶样本和1 820组疲劳驾驶样本进行训练。在Matlab平台上编写相关程序,设置变量个数m try=2,随机森林树的个数N tree=400,利用所选择训练样本数据训练随机森林模型,确定2个变量与驾驶员状态之间的非线性关系。
4 模型测试
4.1 测试结果
用剩余的样本数据对疲劳检测模型进行测试,结果如表3所示,由表3可知:模型对于驾驶员正常驾驶准确识别812个,错误识别148个,疲劳驾驶准确识别634个,错误识别146个。本文选取准确率、真阳性率和真阴性率对模型结果进行有效评价,结果表明:模型的准确率为83.10%,真阳性率为81.28%,真阴性率为84.58%。

表3 测试结果
4.2 结果分析
由上述结果可知,在960组正常驾驶数据中,有148组被错误识别为疲劳驾驶。通过对驾驶员的面部视频分析发现,导致错误识别的主要原因是驾驶过程中佩戴智能手表的手脱离方向盘。其中,3号和7号驾驶员在驾驶过程中出现将佩戴智能手表的手放在腿上的行为,导致智能手表的传感器数据几乎不变而被错误识别为疲劳情形下长时间不修正方向盘行为。
而在780组疲劳驾驶样本中,有146组被错误识别为正常驾驶。分析视频资料发现,错误识别的样本主要来自于4号驾驶员。由于4号驾驶员在疲劳驾驶时不断使用佩戴智能手表的手挠痒,使得疲劳状态下所采集的数据特征和正常状态下的数据特征相似,从而造成模型的误判。
5 结论
使用智能手表采集了10名驾驶志愿者在正常和疲劳状态下驾驶时的手腕运动信息,并从中提取了多个统计特征和样本熵特征,建立了基于随机森林的疲劳驾驶监测模型,完成了模型检验。结果显示:通过加速度和角速度数据的统计特征和样本熵特征等能够有效地实现疲劳驾驶检测。960组正常驾驶和780组疲劳驾驶样本的测试结果表明:模型的准确率为83.10%,真阳性率为81.28%,真阴性率为84.58%。
使用智能手表作为驾驶员转向行为的数据采集装置,能够准确感知转向差异,但由于驾驶志愿者在驾驶过程中将佩戴智能手表的手脱离方向盘以及挠痒等而导致了一些误判。因此,在后续的研究中还可以考虑对这些行为进行识别或者与其他方式结合,以便进一步提高模型的检测准确率,使得该方式更具有实用性。
