基于XGBoost的中文网络评论分类方法研究
2021-01-20刘思聪卢甘霖崔子良尹建烁西北农林科技大学信息工程学院
刘思聪 卢甘霖 崔子良 尹建烁 西北农林科技大学信息工程学院
引言
网络论坛相关技术的发展,使其能够承载更多网络用户产生的信息。但网络评论来源的复杂性,造成了网络论坛中的评论文本质量良莠不齐。因此,对网络评论文本进行实时并且快速的分类成为了当前比较紧迫的商业需求。
但当前网络评论文本分类的有关研究还未成熟,其亟待解决的问题可总结为:文本分类的类别设置不全面;使用的分类算法性能不佳。为解决以上问题,本文建立了一套较为科学的评论文本分类标签,提出了一套基于XGBoost算法的分类系统。
1 相关技术
1.1 数据获取与预处理流程
采用网络爬虫抓取网络论坛上的评论信息,运用NLTK工具集对无关信息进行清洗,建立符合需求的评论文本数据集。
1.2 文本分词处理流程
使用Jieba进行中文分词,该工具包实现了高效的词图扫描,能找出基于词频的最佳切分方式。
1.3 基于TF-IDF的特征提取流程
通常运用TF-IDF提取文章的特征,具体如下:
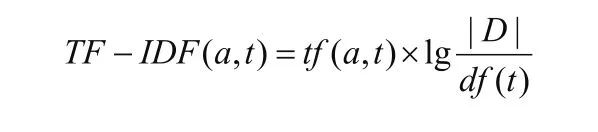
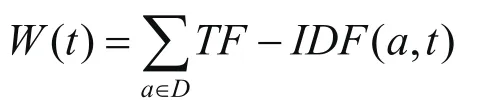
2 XGBoost算法
该分类算法的基本思想是选择部分样本和特征生成一个简单模型,将其作为基本分类器。在生成新模型时,学习以前模型的残差最小化目标函数。重复执行,最终产生准确率很高的综合模型。它的目标函数 Oobj经过泰勒公式展开后,最终化简为
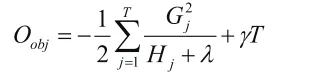
3 网络评论分类系统的构建
分类系统由文本获取(使用网络爬虫从网络论坛抓取文本信息)、文本整理与清洗(剔除文本中的无关信息)、文本分词(对经过预处理的文本进行分词)、特征提取(对分词后的文本建立特征矩阵)和模型训练(训练出XGboost模型)构成。
4 实验验证
4.1 实验验证平台
硬件平台:CPU:Intel i5 7300HQ,内存:DDR4 12G,硬盘:260G硬盘;
开发及运行环境:操作系统 Windows 10 OS, 编程语言:Python 3。
4.2 项目所使用数据集
首先,设定体育、健康等12类标签。其次,在SougoCS数据集的基础上,使用网络爬虫和手工标注将训练集和测试集分别增强到24000条和12000条。
4.3 分类性能评判标准
使用准确率,召回率和F1三个指标作为分类器评判标准,定义如下:
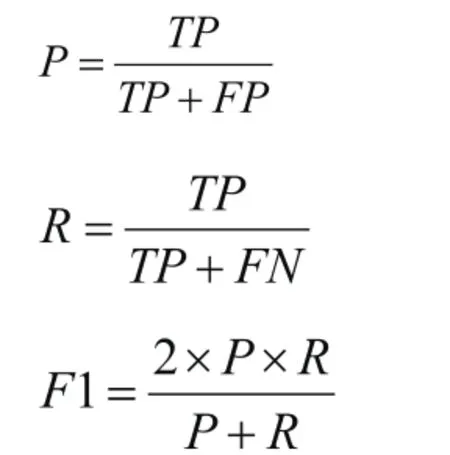
4.4 不同分类模型的比较
为验证XGBoost的分类准确性,选择Logistics、随机森林和朴素贝叶斯三种算法,在100%数据量下,进行比较。由表1可知,XGBoost模型的结果好于其他三种算法。其中,较排名第二的Logistics仍高出8%。
4.5 不同数据量的影响
随机选取20%、40%、60%、80%的数据作为训练集。从折线图中可以看出,随着数据量的增加,模型的结果逐步增强,且未出现明显的下降趋势。
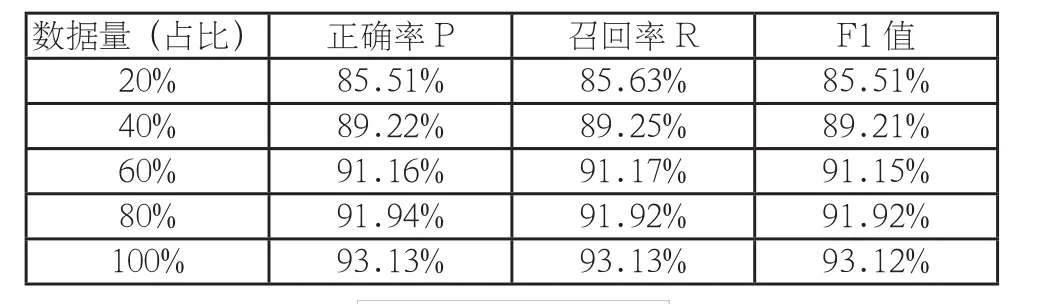
表2 训练样本量对XGBoost算法的影响
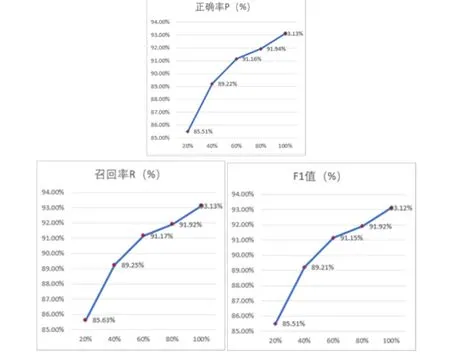
图1 XGBoost在不同数据量下测试结果的变化
5 结论
(1)针对当下分类标签设定不科学的问题,可在原有基础上。根据实际,设计出更精细的标签;然后,利用人工标注的方法,逐步增强适用于网络评论分类的评论语料。
(2)针对准确率的问题,提出了一套基于XGBoost算法的分类方法。通过与其他分类算法的比较可得:XGBoost算法的结果好于其他算法;通过在不同数据量下的测试可得:随着训练样本的增加,准确率保持稳定增长,未出现较明显的下降趋势。
