基于SSD模型的船载危险驾驶行为检测系统设计∗
2021-01-19刘常榕赵雪寒刘庆华杜春旺张翟容
刘常榕 赵雪寒 刘庆华 金 文 杜春旺 张翟容
(1.江苏科技大学 镇江 212003)(2.江苏金海星导航科技有限公司 镇江 212002)
1 引言
交通安全一直是社会重大安全问题之一,每年多少人都因为道路交通事故失去宝贵的生命,一方面是由于行人等自身不遵守交通规则,一方面也是因为驾驶员的危险驾驶行为导致灾祸的发生。在道路交通领域中,危险驾驶一直是人们比较关注的地方。道路交通事故统计资料表明,驾驶员超速、疲劳驾驶、酒后驾驶等危险驾驶行为是造成交通安全事故的主要因素。杨晓峰等人提出了一种基于脸部特征提取的驾驶员低头行为的检测方法[1],吴超仲[2]等人以驾驶疲劳状态监测为研究对象,介绍现有几种疲劳检测方法及其优缺点,提出了对驾驶行为操作和驾驶员生理指标进行建模,建立疲劳识别模型,实现了对疲劳驾驶行为的检测。李娟根据数据融合的思想,采用粗糙集模型融合人眼疲劳识别特征参数和车道线危险识别特征参数,建立危险驾驶识别的数据融合模型,得出了最终的危险识别结果[3]。然而,水上驾驶安全也同样重要。每年,全国范围内水上交通事故发生也非常多,水上交通安全问题日益凸显,如何降低水上交通事故发生已经成为江河流域管理部门的重大难题之一。我们认识到,水上危险驾驶行为是导致水上交通事故的主要原因[4],严重威胁水上交通安全。因此,如何实现对船舶驾驶员的危险驾驶行为的实时检测对于减少水上交通事故显得尤为重要。
在水上交通安全领域,船员的危险驾驶行为主要有低头、闭眼、打哈欠、打电话、抽烟、转头等行为。这些行为可以通过安装在船长驾驶室的摄像头进行捕捉画面,并且通过分析画面中的相应行为来检测是否有危险行为发生,这其实就涉及到对人脸、电话等的目标检测问题。目前,在计算机视觉领域,目标检测是一个非常重要的研究方向,很多新型科研领域如无人驾驶、人脸识别、智能监控等都有广泛的应用。它是以图象分类技术为基础,检测图像中的目标对象并进行分类,并且在目标对象周围绘制适当大小的边框对目标对象进行定位实现的[5]。传统显著性目标检测方法常假设只有单个显著性目标,其效果依赖显著性阈值的选取,并不符合实际应用需求。近来利用目标检测方法得到显著性目标检测框成为一种新的解决思路[6]。选取SSD模型可以同时精确检测多个不同尺度的目标对象,其对小尺度目标检测精度不佳的问题在船舶驾驶员行为检测中影响较小,因此,采用SSD模型实现对船舶驾驶员行为的检测是可行的。
本文将首先介绍整个船载危险驾驶行为检测系统的整体设计,并且阐述使用SSD模型实现目标检测功能的原理,并选取典型的目标检测数据,制作用于目标检测模型的图像数据集,结合SSD_MobileNet预训练模型,在具有安装NVIDIA显卡的主机上训练危险驾驶行为检测模型,最后将训练好的模型集成到安装好特定环境并带有NVIDIA显卡的主机上,实现危险驾驶行为检测的功能,并且分析这些行为检测的准确度并且得出相应结论。
2 系统设计
2.1 硬件系统设计
整个船载危险驾驶行为检测系统的主机为惠普i5-9400F,其内存容量为8GB,硬盘容量为1TB,显卡型号为NVIDIA GetForce GTX1660,满足作为训练主机和正式环境的要求。在训练模型时,我们可以使用该主机对SSD模型在增加数据集的基础上进行训练;在实际船舶环境中,我们可以将该主机放置在船长驾驶室内,配置相关程序供电之后即可使用。
该行为检测系统硬件框图如图1所示。首先,船舶一般配置一台路由器和一台交换机,安装在船员驾驶舱前面的海康摄像头通过连接到交换机通过配置相关参数即可使该摄像头具有静态的IP,搭载检测模型的主机通过连接到交换机与该摄像头同处一个局域网下,就能通过摄像头固定的本地地址实现通信。主机上的检测程序主要是通过实时流传输协议RTSP(Real Time Streaming Protocol)将驾驶员的实时监控视频流获取到,然后将该视频流输入到船载危险驾驶行为检测的深度学习模型中,模型根据视频流会进行几种驾驶行为的检测,如果发现检测到危险驾驶行为,则会通过报警模块将该行为信息通过声音播报出来并且会通过MQTT协议的数据消息发送到远程后台管理平台,后台管理平台可以将这些信息保存到数据库并且通过界面展示出来。
船载主机可以设置掉电自动重启功能,每次船舶开始启动通电时主机能够自动开机,检测程序随之能够实时地检测船员的危险驾驶行为,非常方便,不需要人工干预。
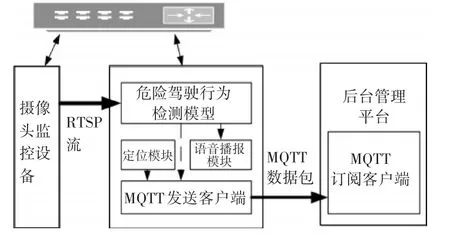
图1 硬件系统设计示意图
2.2 软件系统设计
放置在船上的主机里面集成了危险驾驶行为的检测程序,其主要的流程如图2所示。首先,当主机通电时,检测程序自动开始运行,首先会进行系统初始化,根据主机、端口和主题等配置向MQTT服务器发起订阅,订阅成功则开始检查TTS模块是否正常启动,其次,加载危险驾驶行为检测模型,然后开始读取视频流,读取每帧的图片进行检测,如果检测到危险驾驶行为则通知TTS模块播放对应的提示语音并且通过MQTT向远程平台发送MQTT数据包。
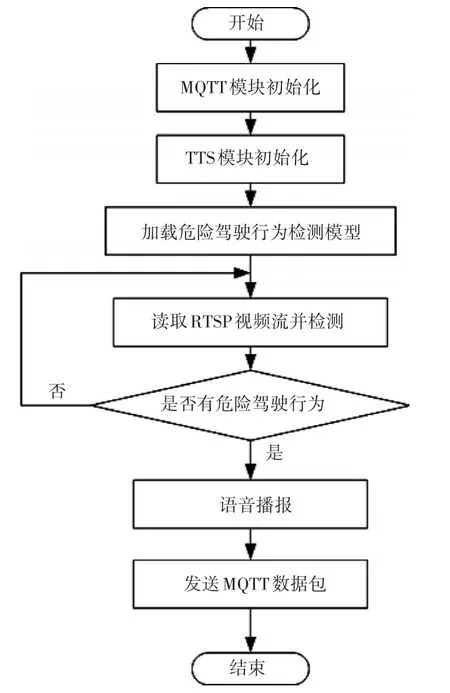
图2 检测程序执行流程图
MQTT协议[9]特别适合应用在物联网领域,本系统中,我们就是采用MQTT协议发送数据包。MQTT协议是一种基于Publish/Subscribe模式的协议,它的主题支持通配符格式,一般常用的是“+”和“#”。本系统设计的主题格式主要是根据公司代码还有船舶九位码来区别不同的船舶发送过来的驾驶行为的数据,主要形式为/ship/+/+/alert/publish,其中第一个“+”匹配的是公司代码,第二个加号匹配的是船舶九位码,这样设计的目的是可以根据主题的层级关系每个公司可以只订阅自己管理的船舶的主题,便于后续需要。MQTT的数据格式采用json格式,各字段含义主要如表1所示。
系统的后台管理平台主要使用的语言为java,主要的架构为Springboot+mybatis+JSP实现,将项目打包成war直接使用docker部署。平台主要使用的是postgresql关系型数据库,整个架构如图3所示。
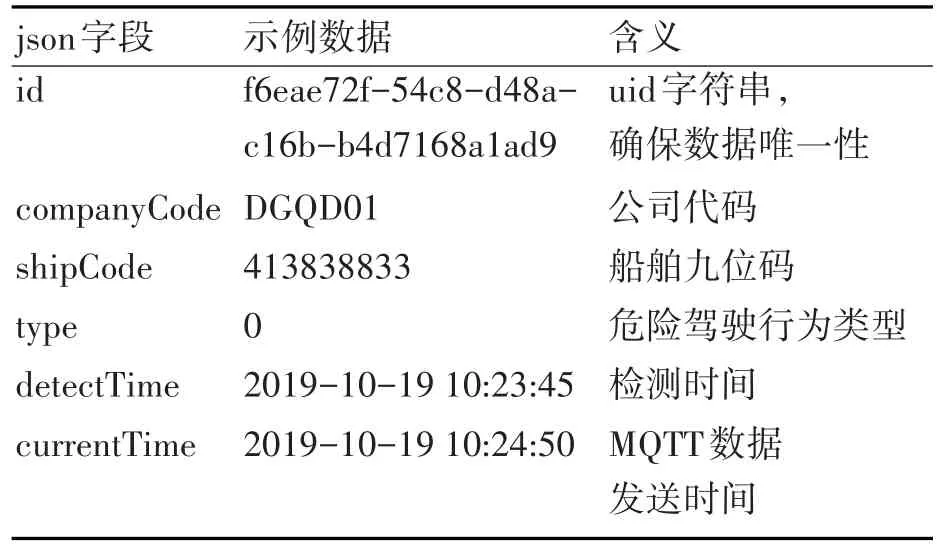
表1 MQTT数据包字段说明
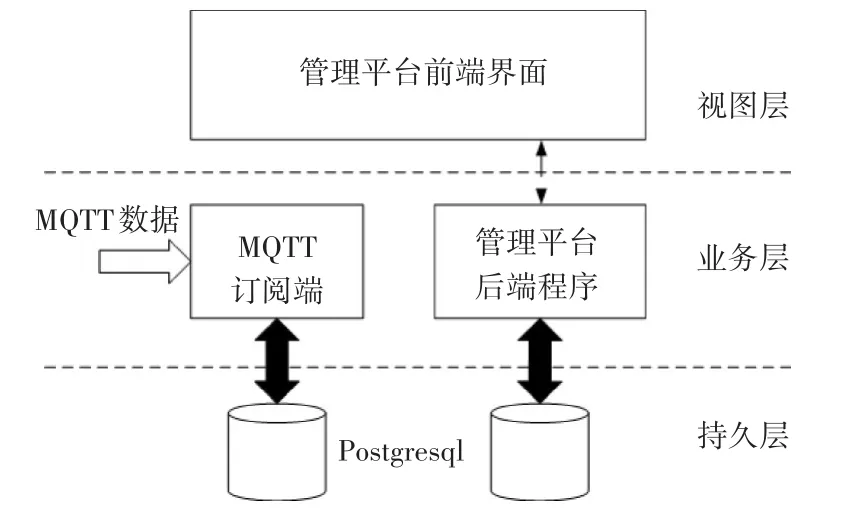
图3 网络模型结构图
3 算法实现
3.1 SSD网络模型简单介绍
SSD模型是由WeiLiu,Dragon Anguelov等[7]提出的使用单个深层神经网络检测图像中对象的方法。其结构示意图4所示:SSD模型的前五层为VGG-16网络的卷积层,第六和第七层全连接层转化为两个卷积层,之后再加上三个卷积层和一个平均池化层。SSD模型的主要特征就是采取VGG-16卷积神经网络作为基础,然后连接多层卷积层和池外层来提供额外提取特征的效果。SSD模型获取目标对象位置和类别的方法虽然也是回归方法,但是主要去除了候选框的操作,使用候选对象位置周围的特征,采用的是Anchor机制。在使用SSD模型进行对象的检测时,各个卷积层会将特征图分割为若干称为feature map cell的大小相同的网格,针对每个网格使用固定大小的Default boxes对目标对象进行包围,预测这些Default boxes的偏移和类别得分,最后采用非极大值抑制方法获取目标检测的结果。Default boxes可以作用于不同层次的多个特征图上,帮助我们以最合适的尺度来匹配目标对象的实际区域范围。
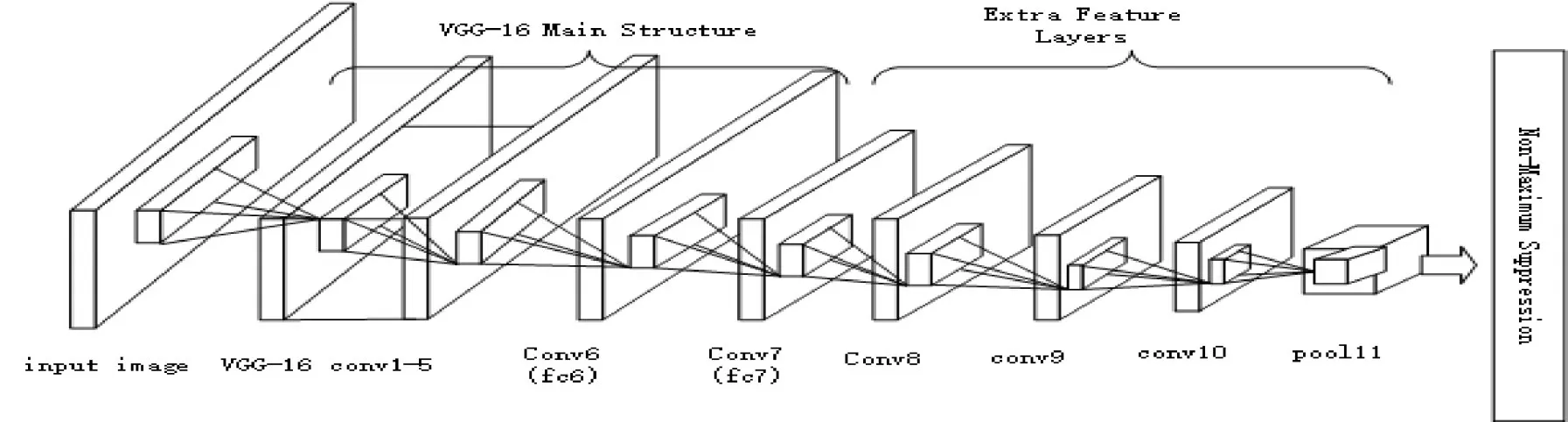
图4 VGG结构图
SSD_MobileNet模型是将MobileNet网络替换VGG网络成为该模型的基础网络结构的。MobileNet的设计之初是为了应用于嵌入式视觉,它十分高效,主要的特点就是将标准卷积核进行分解计算,引入宽度乘数和分辨率乘数两个超参数减少计算量。Andrew G.Howard等人针对COCO数据集进行实验,得出了使用基于SSD框架下的这两种模型的训练及测试的结果[8],如表2所示。综合这实验结果可以得出,SSD框架使用MobileNet网络结构作为基础网络结构,虽然在检测的准确率上面会有些许下降,但是在图像处理时的计算量和参数量会大幅度下降。在嵌入式应用中,硬件资源一般都是有限的,机器的性能也不是很高,减少计算量,提高目标检测实时性非常关键,而使用MobileNet这种轻量级、延迟性低的检测模型能够显著地提高目标检测的速度。
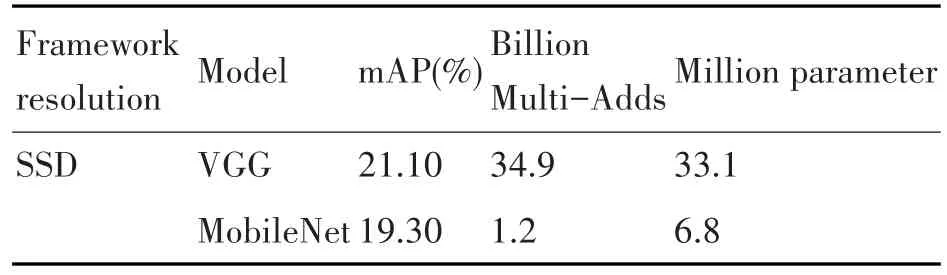
表2 VGG和MobileNet对比实验结果对比
3.2 数据集的处理
危险驾驶行为模型的数据集使用全新的数据集,数据集取自镇江市新区大港汽渡公司。通过船舶上面对驾驶员的监控视频处理得到的图片,采用专门的图形标注软件对各种危险驾驶行为进行目标对象标注,并且转化为标准的目标检测数据集格式。一般数据集格式包含Annotations、ImageSets和JPEGImages三个文件夹,Annotations文件夹保存了图片的标注信息,一般是xml格式;用于训练、验证和测试的样本名称记录在ImmageSets文件夹,一般是txt格式;而JPEGImages文件夹保存了所有图片,图片的格式为JPG格式。经过人工的筛选和标注,我们最后搜集的图片每类图片各1000张,共6000张。通过水平翻转、调节图片对比度、多角度旋转图片、放大裁剪等多种方法扩充数据集数量至10000张,其中图片标注文件也需随图片变换做相应的坐标变换。
3.3 SSD网络模型训练
危险驾驶行为检测模型在SSD模型的基础上,训练模型的服务器GPU为GTX1060,训练参数如下:模型识别种类数为6;每次训练更新参数时,批处理图片的数量为24,即batch_size值为24;载入模型的训练图片大小为300*300;初始学习率为0.004,每训练1000次学习率变为上次学习率的0.99倍,使用不断减小的学习率提高模型权重值的准确度,由此提高整个模型的识别精度;momentum动量优化值为0.9;模型采用l2正则化,如式(1)所示,其作用为对最优的元素进行不同比例缩放;计人计车模型的总训练次数为20万次,即epoch值为200000。

4 结果分析
本系统采用docker部署,docker现在在业界应用越来越广泛,而且docker运行相当于在一个容器里面,不会与主机中其他依赖产生冲突,启动、重启和关闭都比较方便。根据制作的数据集和训练过之后的模型,我们对真实视频进行处理。视频为真实室内环境,视频帧尺寸为450×450像素,视频处理帧率为15fps,实现了实时处理。针对每种危险驾驶行为,我们对检测模型的结果和实际的情况进行统计,主要结果如表3所示。
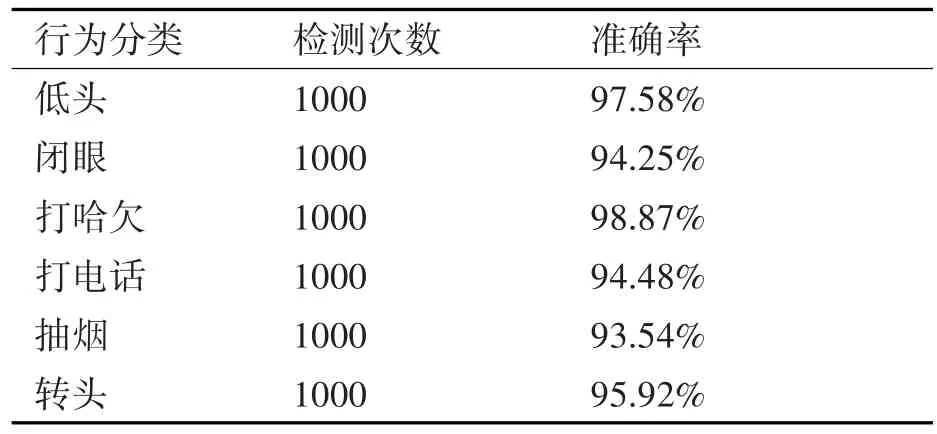
表3 检测结果
测试效果如图5所示。针对驾驶员的低头、闭眼、打哈欠、打电话、抽烟、转头这些危险驾驶行为,训练好的危险行为检测模型都能很好地检测出来。

图5 测试效果图
5 结语
本文提出了一种基于SSD模型的船载危险驾驶行为检测系统。该系统主要是通过检测模型读取监控视频的实时RTSP流进行分析,检测到有危险驾驶行为出现的话,就会有语音报警,并且检测程序会通过MQTT数据包将该行为检测的信息发送到远程后台管理平台。后台管理平台可以接收到这些消息并且保存到数据库当中并且通过界面展示,这极大地方便了管理部门查看船员的驾驶情况,也能够避免江河流域上面交通事故的发生。从实验结果来看,采用SSD模型经过数据集的训练之后,准确度识别度为95.76%,视频处理平均帧率为15fps。由此可见,该船载危险驾驶行为检测系统检测效果明显,具有非常广泛的应用价值,如果应用到水上交通安全上将会规避很多不必要的事故发生,保障生命安全,减少人民财产损失。
