文本分类任务中到的常见损失函数
2021-01-18
普华讯光(北京)科技有限公司 北京 丰台 100071
1 交叉熵损失函数
交叉熵是香农信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息,可以通过最小化交叉熵来得到目标概率分布到的近似分布。在信息论里,-logp(x)被信息论的创始人香农定义为事件x的自信息,即一个概率为p(x)的事件x具有的信息量,单位是比特。熵就是所有事件的自信息的加权和,即这些事件的自信息的平均值。
熵也反应了这些事件的不确定度。熵越大,事件越不确定。如果一个事件的发生概率为1,那么它的熵为0,即它是确定性的事件。如果我们确定会发生什么,就完全不必发送消息了!结果越不确定,熵越大,平均而言,当我发现发生了什么时,我获得的信息就越多。
如果有两件事各以50%的概率发生,那么只需发送1比特的消息就够了。但是,如果有64种不同的事情以相同的概率发生,那么我们将不得不发送6比特的消息(2的6次方等于64)。概率越集中,我就越能用巧妙的代码编写出平均长度很短的消息。可能性越分散,我的信息就必须越长。
例如:在决策树分类算法里,我们需要计算叶子节点的impurity(非纯洁度)。我们可以用熵来计算非纯洁度,一个叶子越纯,里面的分类越少,确定性越大,它的熵越小。如果一个叶子里的观察值都属于同一类,即它是完全纯的,那么这是一个确定性事件,它的概率等于1,所以它的熵为0。
那么,为什么要关心交叉熵呢?这是因为,交叉熵为我们提供了一种表达两种概率分布的差异的方法。p和q的分布越不相同,p相对于q的交叉熵将越大于p的熵。
2 为什么不用classification error?
classification error顾名思义就是用错误的分类数来除以分类总体数量。
下面通过两个例子来说明一下classification error的计算:
假设下面为两个模型的结果,两个模型预测的相同的三条数据。
其中predict为模型的预测值,target为真实的分类。
对于模型一的结果:
模型的预测值为:[0.3,0.3,0.4],[0.3,0.4,0.3],[0.1,0.2,0.7]
模型的标签值为:[0,0,1],[0,1,0],[1,0,0]
模型的预测结果为:yes,yes,no
则其对应的计算为:classification error =1/3
对于模型二的结果:
模型的预测值为:[0.1,0.2,0.7],[0.1,0.7,0.2],[0.3,0.4,0.3]
模型的标签值为:[0,0,1],[0,1,0],[1,0,0]
模型的预测结果为:yes,yes,no
则其对应的计算为:classification error =1/3
通过上面两个表的对比,可以看出模型2的效果要明显优于模型1,但是从classification error的分类损失上发现两个模型计算出的效果是一样的,这就是classification error存在的问题,它不能准确的描述模型与理想的模型之间的差距。
3 为什么不用Mean Squared Error
Mean Squared Error即均方误差,它是反映估计量与被估计量之间差异程度的一种度量。其定义为使用估计量与被估计量的均方误差作为度量。
我们依旧使用上述的两个模型的例子来分别计算一下这两个模型的MSE。
对于模型一的结果:MSE=(0.54+0.54+1.34)/3=0.81
对于模型二的结果:MSE= (0.14+0.14+0.74)/3=0.34
MSE看起来还不错,对较好的模型确实损失小一些,但是不用它的原因如下:
·MSE的假设是高斯分布,交叉熵的假设是伯努利分布,而逻辑回归采用的就是伯努利分布;
·MSE会导致代价函数J(θ)非凸,这会存在很多局部最优解,而我们更想要代价函数是凸函数;
·MSE相对于交叉熵而言会加重梯度弥散。
4 使用交叉熵的损失
交叉熵的损失函数定义如下:
我们以y作为真实的label值,p为模型的预测结果。
当y=1时,CE=-log(p)
当y=0时,CE=-log(1-p)
依旧使用上述的例子分别计算一下各自的交叉熵损失函数的值。
对于模型一的结果:CE=-(ln(0.4)+ln(0.4)+ln(0.1))/3=1.38
对于模型二的结果:CE=-(ln(0.7)+ln(0.7)+ln(0.3))/3=0.64
从上面的结果可以看出交叉熵损失函数很清晰的描述了模型与理想模型的距离,并且其作为损失函数本身也是一个凸函数,很容易进行梯度下降和更快的收敛。这也是为什么文本分类的任务中基本上都是使用交叉熵损失函数作为分类问题的损失函数的原因。
5 交叉熵的基础上的一些改进的损失函数
在现实的任务中,正负样本的不平衡比比皆是,下述的几种方法就是对样本的不均衡的问题的改进手段。
5.1 Focal Loss Focal Loss的提出最初是为了解决图像标注的样本不均衡的情况的,由于其较好的效果,后来逐渐应用于自然语言处理的文本分类任务中。在Focal Loss中以二分类为例将样本数据一共分为了四类,分别为正难样本、负难样本、正易样本、负易样本。解释一下这四类样本如何理解,其中的正样本顾名思义就是目标分类的样本的集合,负例就是不包含目标分类的样本的集合,而难样本就是模型学习不好的样本,假设为正样本情况下,通过损失函数表现出来就是虽然该样本为正例,但是模型预测出的p值很小,可能只在0.1或者0.2左右,易分样本就是假设为正样本情况下,通过损失函数表现出来的p值很大,直接接近1。
在真实的场景中,其实绝大部分的样本都是易分样本,占比非常高,所以易分样本对模型的整体贡献就会非常高,就会导致模型过多的关注易分的样本而过少的关注难分样本,作者认为这么做是有问题的,因为易分样本对模型的提升非常小,模型应该关注那些难分的样本,进而来改善模型的效果。
我们先看一下Focal Loss函数的形式:
当y=1时,FL=-α(1-p)^γlog(p)
当y=0时,FL=-(1-α)p^γlog(1-p)
该函数与上面提到的交叉熵函数一对比就会发现,与交叉熵的总体形式是一样的,只不过就是多了两个参数,α和γ。下面我们来分析一下这两个参数的意义:
在正例的前面乘以α并且在负例的前面乘以(1-α),可以很明显的看出,这样做的直观理解就是如果正负样本不平衡,设置一个参数来动态的调节正负样本的比例,若负样本特别多的情况下,就相应减少负样本贡献的权重,若负样本特别少的话,就相应增加负样本贡献的权重,进而来改善正负样本比例不均衡的问题。
再看公式中的γ,其位置放在指数的位置,并且与模型的预测概率p相关的。对正例样本来说,若预测的概率为p,则前面用一个(1-p)的γ次幂与其相乘,因为p本身是一个小于1的数字,则这两项相乘的结果就是以指数的形式衰减,则我们可以推断出该参数的意义就是用来解决难易样本分类的问题的,对简单容易分类的样本进行抑制的,因为易分样本其实就是模型预测出来的值与真实的值相差的很小的样本。假设p=0.968,则说明该样本模型的预测的很好了,取γ=2的时候,我们计算一下(1-0.968)^2≈0.001,相当于对于该样本其损失了1000倍。
可以看出Focal Loss的设计非常的巧妙和简单,不需要很复杂的形式,仅仅通过两个参数就既解决了正负样本的问题又解决了难易样本的问题,大道至简。
5.2 GHM_C GHM_C是在Focal的基础上的进一步改进,首先看一下作者认为Focal存在的问题:
首先,让模型过度关注特别难分的样本其实是有问题的,因为那种样本点很可能本身就是离群点或者是标注错误等造成的样本。其次,Focal中的α与γ是根据实验得出来的,并且α与γ的值也会相互影响,不同数据需要不断尝试调整α与γ。
作者对样本不均衡的本质影响进行了进一步探讨,找到了梯度分布这个更为深入的角度。认为样本不均衡的本质是分布的不均衡。更进一步来看,每个样本对模型训练的实质作用是产生一个梯度用以更新模型的参数,不同样本对参数更新会产生不同的贡献。由于简单样本的数量非常大,它们产生的累计贡献就在模型更新中就会有巨大的影响力甚至占据主导作用,而由于它们本身已经被模型很好的判别,所以这部分的参数更新并不会改善模型的判断能力,也就使整个训练变得低效。
基于这一点,研究者对样本梯度的分布进行了统计,并根据这个分布设计了一个梯度均衡机制,使得模型训练更加高效与稳健,并可以收敛到更好的结果。
首先定义一个统计对象——梯度模长g=|p-p*|,其实就是交叉熵损失函数下对x的导数求得。
作者通过梯度模长的定义将难分样本与易分样本进行可区分,对于易分样本其梯度模长较小,对于难分样本其梯度模长较大,既然梯度模长已经知道了,那怎么同时衰减易分样本和特别难分的样本呢?谁的数量多衰减谁,那怎么衰减数量多的呢?定义一个变量,让这个变量能衡量出一定梯度范围内的样本数量。于是,作者定义了梯度密度GD(g):
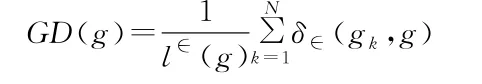
其中:δ(g,g)就是在样本N中,梯度模长分布在∈k范围内的样本数。l∈(g)代表了的区间长度。因此梯度密度GD(g)的物理含义是:单位梯度模长g部分的样本个数。最终GHM_C的定义形式就是:
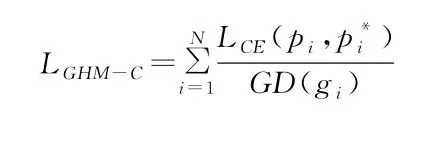
可以看出上述公式就是在交叉熵损失函数的基础上使用梯度模长的概念进行了归一化,就是针对特别易分的样本和难分的样本均给与了一定程度的打压,进而可以让模型更好,更平衡的对正难样本、负难样本、正易样本、负易样本进行学习。
在论文中作者总结了交叉熵损失函数、Focal Loss损失函数和GHM-C损失函数分别对样本梯度产生的作用。
当Focal Loss作为损失函数的情况下对于易分样本的确是存在抑制作用的,因为相比于普通的交叉熵的损失其曲线位于交叉熵损失函数下面,但是对于难分的样本曲线随着梯度模长的增长而增长,可以看出Focal Loss对难分的样本很关注。
当GHM-C作为损失函数时不仅对易分样本有抑制,并且对特别难分的样本也是存在抑制作用的。因为GHM-C的作者本身就认为模型太关注难分样本本身就是有问题的,应该让模型去均匀的关注样本中的各个类别。所以在梯度模长很大的时候,对样本进行了一定程度的抑制。
6 总结
本文首先介绍了为什么使用交叉熵作为损失函数以及它的优越性,然后针对实际的问题介绍了几种对交叉熵损失函数的改进。最后分析了GHM-C相比于Focal Loss和普通交叉熵的优越性。
