基于CNN层内结构优化的图像分类
2021-01-16黄颖聪孟凡阳
黄颖聪,孟凡阳
(1.深圳信息职业技术学院 广东省智能视觉工程技术研究中心,广东 深圳 518172;2. 鹏城实验室,广东 深圳 518055)
1 概述
卷积神经网络(CNN)[10]由于其在数据处理、特征提取以及模式分析上的优势,已经成为大多数图像识别的优先架构,在与计算机视觉和图像处理相关的一些竞赛中有着出色的表现。CNN采用了多个特征提取阶段,从而使其具有强大的学习性能[12]。CNN是一个端到端(end to end)的训练过程,它从输入端到输出端会最终得到一个预测结果,与真实结果相比较会得到一个误差,这个误差会在模型中的每一层传递(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或达到预期的效果才结束。在这个过程中,CNN采用了多个特征提取阶段,利用了数据中的空间或时间相关性,可以挖掘数据中的信息,从中自动学习表征。
计算能力的提高以及大量标记数据的出现,再加上改进的算法,这些都推动了CNN的研究进程。由于CNN在许多计算机任务上获得成功,针对CNN结构的改进也层出不穷。从上世纪90年代末到如今,CNN的学习方法和架构进行了各种改进,使其可以扩展到大型、异构、复杂和多分类问题[13]。
目前,为了提高网络的性能,CNN网络结构优化方法可以分为两类:注重特征有效性的层间结构优化和注重特征关联性的层内结构优化。如图1所示。层间优化通过设立不同层之间的连接来实现不同级别的语义信息之间的交互,从而解决了线性堆叠卷积层所带来的梯度消失和网络退化的问题[1-3]。但是这类方法往往需要设计复杂的网络结构才能实现层间的特征有效性,会增加额外的计算复杂度。层内优化则通过对卷积层内部结构进行优化,使用分组卷积[4]和深度可分离卷积[5-7]等技术实现同一层内通道与通道之间的信息交互,对特征提取的效果更为明显。同时这类优化网络可以集成到现有的CNN骨干网络结构中,而且不用带来额外的计算代价。因此,第二类方法更受到青睐。像国内的科研机构旷视科技提出了一种高效的CNN层内优化模型,融合了通道混洗(Channel Shuffle)操作,利用特征关联性交互不同分组特征信息解决了不同分组之间难以充分流通的问题[11]。

图1 层间优化和层内优化
尽管CNN网络结构的发展为图像识别研究带来了很大的进展,取得了不错的识别性能,但是仍存在一些问题。现有的CNN网络结构利用了分层内各个通道间的关联性,融合了层内不同通道间的信息,但是缺乏对于每个分组通道内部的信息的融合,不能充分挖掘各分组通道内部特征的联系。网络不同层次的特征具有不同的尺度。通常,深度网络模块各通道的早期层次操作在一个精细的尺度上(为了提取低层次的特征),而随后的层次(通过跨步卷积)过渡到粗糙的尺度上,允许全局上下文融合进入下一模块。这种操作仅仅利用了最后层次的粗尺度信息,缺乏分组内早期层次的细尺度信息,导致了细节丢失,不利于图像的精确识别。
2 多尺度层内优化网络Res2Net
2.1 多尺度特征的提取
在CNN的特征提取过程中,使用能从输入中提取局部特征的可学习的卷积核来计算特征图,然后使用非线性激活函数将非线性引入模型中。其中,卷积层的特征提取操作可以表示为:

从公式(1)可以看出,多尺度特征的提取由先前层输入的尺度和卷积核的数量所决定。提取多尺度特征一般可以分为以下两种方法:
(1)通过设置多个不同大小的卷积核对输入数据进行卷积运算,提取不同卷积核的尺度特征。这类方法通过卷积核感受野的多样性丰富样本特征,便于后续特征融合,提高网络对多尺度信息的利用率。例如,GoogleNet[5]提出的Inception模块中就设计了不同大小的卷积核组合,使用并行结构、不对称卷积核结构进行特征提取,提高了特征表述力和稳定性。但不足之处是由于计算资源的限制,卷积核的尺寸设计不能过大,这会导致感受野较小。
(2)利用分组卷积来获得多尺度特征图。在公式(1)的基础上可以得到分组卷积过程如公式(2)所示。

2.2 Res2Net网络模型分析
来自南开大学的团队提出了一种很有前景的新的卷积骨干网络:Res2Net[8]。这种体系结构允许多尺度信息的集成和处理,它将单个残差块进行分组,并在不同分组之间构造层次残差连接,实现了特征的多尺度表示和集成了更细粒度的卷积操作。Res2Net与传统的bottleneck相比,在1×1卷积操作后,没有马上进行3×3卷积,而是将n个通道分成s组,每组w个通道(n=s×w)。每一个分组的特征图被3×3卷积提取特征后的输出会被送入下一组,与另一组的输入特征图一起再进行3×3卷积。重复多次这个过程,直到处理完所有的特征图。最后,将分组卷积的结果连接起来,并使用“1×1”卷积进行信道融合。Res2Net进一步采用分组卷积在残差块中构造更精细的二次残差连接,使得网络有更丰富的感受野来学习多尺度特征。如图2所示,Res2Net块是对传统残差块的分解,因此模型可以在单个残差块中学习多尺度特征。
每个分组的输出 可以用下式来表示:

图2 Res2Net module
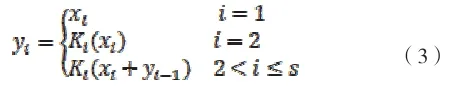
式中的 来表示3×3卷积,s代表分组数也即尺度(scale),代表每个分组的输入特征图。可以看到,特征信息在各分组之间流动,下一个分组可以接收到来自前面所有分组的特征信息。由于组合爆炸效应,Res2Net模型的输出可以学习多尺度的特征,提取更丰富的语义信息。该模块可以集成到经典的backbone网络之中,例如ResNet[1],ResNeXt[9]等等。
在ResNet网络中,保持其他的结构不变,仅仅把其中的bottleneck block替换为Res2Net module搭建完整的Res2Net网络。通过堆叠不同数量的block结构可以构建不同深度的网络。实验所用网络深度有18、34和50层,网络参数如表1所示。在网络结构前期,采用步长为2的7×7卷积和步长为2的3×3最大池化,然后经过逐一block进行特征提取和学习,最后经过平均池化再进行输出。

表1 网络具体设置参数

?
3 Skip2Net网络优化模型
3.1 改进思路
高层特征包含上下文信息,而低层特征具有丰富的空间细节。尽管Res2Net在残差块中实现了多尺度卷积,但其单个分组通道内部的信息流动比较单一,没有充分利用本组特征图的低层特征。而skip connection作为层间优化的常见结构,能有效融合不同层级之间的上下文信息。因此,我们将skip connection的思想引入层内优化网络。通过在Res2Net结构基础上进行优化,我们提出了一种新的网络模块:Skip2Net。该模型在每个分组内引入一个skip connection的残差结构,实现了在高层特征中嵌入更多的空间细节来增强特征融合。通过在每个分组通道内建模空间依赖关系,从不同层次的特征映射中学习表示,编码了多尺度特征。
3.2 Skip2Net网络结构优化设计

图3 Skip2Net module

Skip2Net通过s个并行的分组卷积执行了金字塔编码机制。各个分组内通过skip connection的残差连接增加了本组的信息流动,不同的分组又通过从先前分组提取的所有特征进行处理来增强分组间的信息流。这种结构可以被视为s个空间金字塔编码模块,其中上下文的特征在s个尺度下进行编码。Skip2Net的最终输出是由多尺度特征生成的特征图,该特征图携带局部和周围的上下文信息。
4 实验及结果分析
为了证明提出的Skip2Net模型的有效性,在CIFAR数据集和ImageNet数据集上进行了实验。此外,还进行了消融实验来揭示各种成分对性能的潜在影响。为公平对比,采用分类准确率和模型计算参数量作为评价指标来评估提出方法的优势。分类准确率指的是Top-1准确率,是一种常用的图像分类评估指标。
实验环境的核心是带有CUDA的PyTorch深度学习框架和cuDNN GPU加速库。在CIFAR实验中采用带动量的SGD算法来优化网络的loss,其中动量值为0.9。激活函数采用ReLU激活函数,损失函数则采用交叉熵损失函数。权重衰减设置为0.0005,以避免复杂模型造成的过度拟合。设置最大epoch为200,初始的学习率为0.1。学习率衰减为0.2,也就是每经过60个epoch除以50。
在ImageNet实验中,采用动量为0.9和权重衰减为0.0001的SGD优化算法进行实验。设置最大epoch为90,初始的学习率为0.1,每经过30个epoch除以10。
4.1 模型有效性分析
实验使用Res2Net50作为比较的基准模型,为了实验的公平,仅仅把其中的Res2Net模块换成Skip2Net模块,其他不做改变。然后分别在CIFAR-10和CIFAR-100数据集从参数量和准确率上验证提出模型的有效性。为了简单起见,设置尺度(scale)s = 4。
表2给出了相应的实验结果。由表2可以看出:在CIFAR-10上,深度都为50的前提下,Skip2Net50的计算参数量与Res2Net50相比没有增加,而分类准确率高达95.46%,与Res2Net50的分类准确率相比提高了0.23%。在CIFAR-100数据集上,Skip2Net50的分类准确率达到80.24%优于Res2Net50,与其相比提高了0.36%。实验结果证明,本文提出的模型能在不增加计算负载的同时有效地提高识别精度。原因分析:Skip2Net通过在各自分组内引入跳跃连接,能有效地增加信息的来源,实现特征重用,减少一些重要特征的丢失从而提取到更有效的特征。通过多尺度信息的再利用,提高了识别精度。与在CIFAR-10上相比,Skip2Net在CIFAR-100上识别准确率提高较多,这说明了我们提出的模型在更复杂的数据集上的泛化性能更好。

表2 两个模型在CIFAR-10和CIFAR100的准确率
为了直观展示提出模型性能提升带来的效果,将两种算法在数据集上的对比效果展示在图4中。图4给出了两种模型在训练过程中随着迭代次数的增加,图像分类准确率的变化。图中横轴表示迭代次数,纵轴表示分类准确率。从图中可以看出,该模型前期的分类准确率提升较快,趋于稳定时也略高于Res2Net。

图4 两种模型在CIFAR训练过程中的准确率
图5则显示了两种模型在训练过程中随着迭代次数的增加,实验损失的变化。如图所示,该模型与Res2Net相比测试损失的性能更稳定。在CIFAR数据集对比这两种结构,可以看出该模型的实验损失波动较小,最终的损失值也较小。此外,Skip2Net和Res2Net相比还有更快的收敛速度。

图5 两种模型在CIFAR训练过程中的损失
4.2 影响网络性能因素分析
(1)通常,网络越深,表征能力越强。为了验证网络的深度对模型的影响,在保持其他因素不变的前提下,实验设置了不同深度的Skip2Net网络与Res2Net进行对比实验。表3给出了Res2Net和本文的模型深度分别为18、34、50时在CIFAR-100上的计算参数量和准确率对比。
从实验结果来看,随着深度的增加,两种模型的识别精度都有所提高。该模型在50层时获得了最高的准确率80.24%,相比同深度的Res2Net50提高了0.36%,有显著的性能提升。而在深度为18、34时也分别同比增长了0.41%、0.54%。
结果表明,该模块可以与更深层次的模型集成,以获得更好的表现。更深的模型拥有更大的感受野来编码更多周边特征,能够更好地学习多尺度表征来提高识别精度。

表3 不同深度的模型在CIFAR-100上的准确率比较
(2)考虑到尺度的选取会对分类性能的准确率造成影响,该模型设置了不同的尺度与Res2Net进行对比实验。采用三种不同的尺度方案来评估模型分类的效果,将尺度分别设置为4、6、8。
表4为训练结果。通过对比实验发现,分类准确率随着尺度的增大而提高。在尺度为8时,该模型分类准确率达到80.73%,相比尺度为8的Res2Net50模型有了0.44%的提升。而在尺度为6时,该模型相比同尺度的Res2Net50分类准确率提升最为明显,达到了0.56%。但是,随着尺度从4增加到8,该模型准确率改善的幅度变小,这可能是由于CIFAR数据集的分辨率太小(32×32)使得尺度不能太大。随着尺度的增加,计算参数量也有所增长。为了在精度和计算复杂度之间做出权衡,在最终的架构中将s设置为4。

表4 不同尺度的模型在CIFAR-100上的准确率比较
4.3 大数据集对比实验
为了验证该模型的泛化能力,在更大的数据集ImageNet设置实验对比两个模型的分类性能。同样设置尺度s为4,深度同为50的Skip2Net50和Res2Net50进行实验。
实验结果如表5所示:与Res2Net50相比,Skip2Net50的计算参数量没有较为明显的增加,而分类准确率达到了77.18%,有0.16%的性能提升。说明该模型在更为复杂的大数据集上也能有不错的表现,证明了该改进模型是有效的。

表5 两个模型在ImageNet的准确率比较
4.4 模型可解释性分析
一个深层的CNN网络经过堆叠的卷积层和池化层,最后一层往往包含了最丰富的语义信息,具有可区分性。为了更直观地理解我们的网络模型是如何进行分类的,我们使用CAM技术来产生热力图可视化网络。CAM是一种可视化的工具,通过产生热力图的方式,能够从流入CNN最后一层的梯度信息来了解每个神经元对于决策感兴趣的重要性,从而帮助获悉模型是依据哪些像素点来判断图片的分类归属。
如图6所示的可视化示例中,第二行是CAM梯度图,第三行是CAM热力图。其中热力图中浅色覆盖集中的地方就是CAM较强的区域,即对最后影响越大生成的热度就越高。可以看出,基于Skip2Net的CAM结果基本上覆盖了每张图片上所要识别的整个对象。比如,第三行中的鸟和猫分别被红色高亮显示为“鸟”类和“猫”类,表示网络在进行识别判断时正在查看正确的位置,我们的网络是通过关注这些区域来得到结果的。第二行的梯度图倾向侧重于图像的纹理信息和细节。例如,当可视化“猫”和“狗”时,CAM不仅能突显出他们的轮廓和区域,还会刻画出他们身上的纹理,这对预测更加精确的特定种类十分重要。

图6 基于Skip2Net的可视化CAM图
5 结语
已有的层内优化网络没有充分考虑各分组通道内部信息流动问题,导致特征提取的效率不高从而影响网络用于图像分类等计算视觉任务的性能。针对这个问题,提出了一种新的层内优化网络Skip2Net,通过对每个块内分组增加一个skip connection,从而加强了特征图通道内的信息流动。直观地说,引入的skip connection对较早的层启用了隐式监管,并增加了同一分组内的信息流。在不同图像数据集上的实验表明,新提出的Skip2Net与原先的Res2Net相比,能够在不增加参数量的同时获得更优的分类效果,在CIFAR10和CIFAR100上分别达到95.46%和80.24%的准确率,在ImageNet上也能达到77.18%的准确率,显著提升网络在图像分类识别中的准确率。
