一种基于Boosting的差分互补卷积网络
2021-01-16李超,柳伟
李 超,柳 伟
(1.深圳信息职业技术学院 广东省智能视觉工程技术研究中心,广东 深圳518172;2.深圳大学 电子与信息工程学院,广东 深圳 518060)
1 概述
卷积神经网络(Convolutional Neural Network,CNN)作为深度学习方法的重要分支,由于其在图像特征提取上的优势,越来越多的学者将基于CNN的图像特征提取方法引入计算机视觉的下游任务中。CNN通过局部感知和参数共享,不仅有效地利用了图像局部关联性降低计算量,而且便于构建深层的网络结构,通过对大量样本的无监督学习,自动提取更具鉴别性和鲁棒性的特征。而这种强大的特征提取能力大部分依赖于网络中卷积层的设计,卷积层的形式不仅可以在很大程度上决定整个网络的性能;同时它也可以直接影响训练过程的复杂度。因此,如何设计更有效的卷积层以提供更强大的特征表示是CNN网络结构优化研究中的核心问题之一。先前的一些研究试图通过使用人工设计的策略对卷积层的形式进行扩展来生成丰富的特征表示。文献[1]将宽度扩展策略应用于瓶颈结构,与原始的网络相比,它显示出更好的训练稳定性和可靠性。文献[2,3]通过利用特定的稀疏结构扩展了滤波器的形式,进一步增强了卷积层的多尺度表示能力。但是,无论宽度卷积还是通道分组,当网络结构变得越来越复杂时,这些策略往往会限制卷积层通道之间的信息流通并可能获得一定的负增益。
受深度学习和集成学习紧密的相似性的启发,例如,分组卷积可以认为是一种Bagging模型,而Res2Net也可以拟合成一种简单的Boosting算法,因此从深度学习和集成学习的共有角度出发,设计了一个简单而有效的类分组卷积单元,该单元帮助卷积神经网络通过利用相邻分组之间的相互依赖性来提取更完整的特征表示并对其进行多尺度特征融合,从而避免大幅度调整当前的网络架构。在通用图像识别数据库ImageNet和Cifar100的实验研究表明,提出的基于Boosting 的差分互补卷积具有更高的识别精度,并且不会引入额外的参数量。
2 相关技术概述
2.1 Boosting
Boosting是集中学习中一种典型的架构,近些年在模式识别领域受到广泛关注,该架构主要通过特定的策略将整体样本集分成份不同的子样本集,并在子样本集中训练出个简单且性能一般的基学习器, 最后将这些基学习器集成拟合出一个高精度的估计[4,5,6]。在分类算法中, 每个基分类器代表着相对粗糙的分类规则,识别率相对较低,如决策树个体,单层神经网络等,但它们在经过加权融合之后就形成了一个强分类器,从而提高了该弱分类算法的识别率。而根据子集划分的手段和集成策略不同,目前Boosting架构下算法变体有很多,其中以AdaBoost最具代表性。
AdaBoost算法的核心思想在于给定一个训练集(x1, y1), …, (xm, ym),用均匀取样的方式将训练集上的分布指定为1/m,并按照该分布调用对应的基分类器进行训练,每次训练之后,根据基分类器的输出更新训练集上的分布,并按照新的样本分布进行下一个基分类器的训练,总共进行T轮迭代之后,最终得到一个基分类器的估计集,每个估计都具有一定的权重,最终的估计则是采用有权重的投票方式获得。
综上所述,在Boosting算法中,通过设定有效的样本集划分方式,并对样本子集进行迭代更新,最后通过弱估计的融合提升算法的性能。同时该思想也适用于深度学习的卷积神经网络当中。
2.2 分组卷积
分组卷积旨在压缩模型大小并提升网络的特征表征能力。它将通道平均划分为某些分组,并在不同分组中使用独立的卷积运算。随着卷积神经网络的快速发展,分组卷积的模式在之前的工作中得到了广泛的探索。研究表明,分组卷积不仅可以看作是结构化的稀疏,而且还可以等同于特殊的正则化。在文献[1]中,首次提出了分组卷积的概念,并使用分组卷积实现了在2个GPU上并行训练特定的神经网络结构。随后根据分组卷积的扩展版本的侧重点不同可分为两大类:网络轻量化和网络高效性。从轻量化的角度出发,文献[7]引入了具有跳跃连接的深度可分离卷积层作为线性组合,从而在保证精度的同时大幅度减少了其参数量。此外,一种基于分组思想的随机信道混洗方法[8]也使网络的参数量得到进一步压缩且一定程度上提升网络性能。但是无论是深度可分离卷积还是通道混洗操作,都是在分组卷积后进行通道之间信息的交互,这被证实相较于在分组卷积中进行通道交互是一种更低效方式。从模型高效性的角度进行探索,文献[2]根据通道将各个骨干块平均划分为一组具有相同拓扑孔结构滤波器,这种拆分变换合并的操作减少了参数量,并增强了模型特征表示的能力。为了再此基础上更进一步,文献[9]在单个分组卷积中采用分层式跳跃连接使模型能够提取多尺度样式的特征图像。但是Res2Net的分层跳跃连接只是通过简单的逐像素相加进行信息的交互,而没深入探讨相邻分组之间的相关性。文献[10]在Res2Net中引入注意力机制,利用空间和通道相关性进一步提升网络性能。
综上所述,单独使用通道分组式卷积会因为每个通道独立性划分的限制,从而导致通道相关性的缺失,而在分组卷积过程中进行通道交互是一种提高分组卷积性能的有效策略,因此如何利用分组卷积去减少网络参数并利用分组通道之间的相关性建模有效的信息交互方式以实现网络的高效性是分组卷积亟待解决的问题之一。
3 基于Boosting的差分互补卷积
3.1 卷积结构
通过对不同通道之间特征图的可视化分析,各组特征图之间存在一定程度的相关性,因此采用Boosting和分组卷积的样本集细分的思想,对每个批次的特征图集合进行按通道划分,并通过差分互补连接利用上一组的特征差异去增强并更新下一组输入的特征表示,最后通过特征拼接来实现特征的多尺度融合。差分互补卷积结构图如图1所示。

图1 差分互补卷积的结构图
为了更好地理解所提议的差分互补卷积,下面以残差网络中经典的瓶颈结构进行说明,差分互补瓶颈结构图如图2所示。
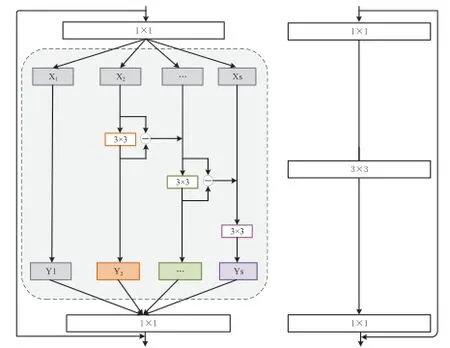
图2 基于差分互补卷积的瓶颈结构
根据结构框图,基于Boosting的差分互补卷积的逻辑步骤如下:
(1)在第一个1×1卷积之后,输出特征图X按照通道数被均匀地划分为s个特征图子集,每个分组上的特征子集空间形状与X相等,且通道数仅为原来的1/s。为了控制参数量,除了第一个分组,每个特征子集都配备了单独的3×3卷积运算;
(2)对这些特征图进行分组之后,可以根据前一组的差分建立相邻通道之间的信息交互连接,差分反映了前一组输入和输出之间差异的程度。将当前组的输入更新为原始输入和前一组差分的累加;
(3)根据不同组的卷积得到的不同尺度的特征图,将输出特征图子集进行通道拼接,获得新的特征图Y。算法公式如式(1)。
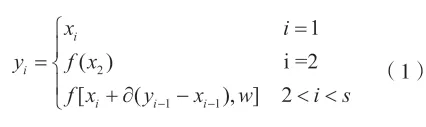
综上所述,差分互补卷积通过建立差分互补连接,使得每个分组的学习区域各有侧重,即新的输入将更加关注先前的差异区域,并形成像素级别的信息补充,从而使每一组的卷积提取的特征信息更加完整,一定程度上缓解了传统卷积中的特征冗余;同时,随着分组数的增加,滤波器的感受野也进一步丰富,例如第二组的感受野大小为3×3,第三组的感受野为3×3和5×5,因此在最后的特征融合的时候可以利用更多尺度的特征信息生成更精准的特征表示,从而提高网络的性能。
3.2 参数平衡策略
我们通过残差神经结构设计了网络,该结构优化了多尺度表示能力和参数策略。因为在总通道保持恒定的情况下,增加特征分组的数量会获得较少的参数和复杂性, 但也导致了相对较低的性能。因此,为了提高基准性能并保证参数的公平比较,差分互补卷积中使用与Res2Net类似的参数策略。s是组数,c是输入通道数,w是用于控制精度和参数之间权衡的超参数。这种参数策略如表1所示。

表1 参数平衡策略
4 实验及结果分析
4.1 实验设计
实验中使用的基准数据集为Cifar100[12]和ImageNet[13]。数据集的具体信息如表2所示。

表2 图像分类数据集
CIFAR-100数据集由100个类别的图像组成,其中包括5万个训练图像和10k测试图像的集合,而ImageNet是128万个训练图像和50K验证图像的集合,由1K个类别组成。对于CIFAR-100数据集,训练批次大小设置为128,并训练200个epoch,在优化过程中,使用SGD作为优化器,其动量设置为0.9,权重衰减为5e-4。
对于ImageNet的数据预处理,我们在原始图片上进行标准的尺寸裁剪和水平区域翻转。同时我们利用平均信道减法对给定的输入图进行归一化处理。此外,使用与文献[2]相同的设置在ImageNet上训练我们的模型,包括SGD优化器,衰减1e-4,动量0.9,持续100个epoch的训练周期;初始学习率设置为0.1,每30个epoch衰减10倍。 对于损失函数,采用了交叉熵损失,其定义如下:
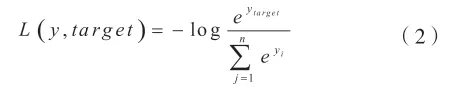
4.2 实验结果
为了初步验证差分互补卷积的有效性,我们首先对一些广泛使用的骨干网使用提出的差分互补卷积:ResNet,ResNetXt 和Res2NetXt,类似于标准做法[2],我们只用差分互补卷积模块替换了Bottleneck模块中的3×3卷积层,同时保留了其他相同的网络配置。表2显示了在不同网络中集成差分互补卷积模块的CIFAR-100结果。与原始骨干网络相比,我们的卷积模块提高了所有基线模型的性能,特别是,当差分互补卷积替换掉ResNet中的3×3的卷积之后,网络的Top-1准确率从79.60%提升为80.62%,提升幅度为1.02%,相同的提升在其他的常用网络结构也能观察到,这说明了差分互补连接分层级增强了内部分组的输入特征,同时显著改善了每个卷积层的特征表述能力,初步证明了我们提出的差分互补卷积的有效性和可靠性。
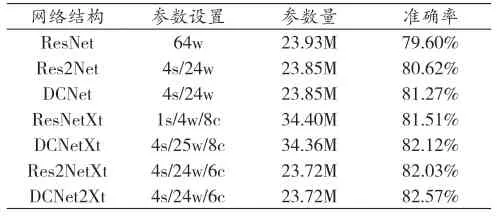
表3 Cifar100的Top-1准确率
为了进一步探讨我们的方法的优越性能是否可以推广到CIFAR以外更大的数据集。因此在ImageNet数据集上进行了一些实验,与一些具有代表性的CNN结构进行了比较。表3显示该模型是一种有效的性能改进方法,随着可忽略参数量的增加,Top-1准确性达到77.62%,与ResNet相比增加了1.22%。另外,与一些注意力算法相比,该方法具有更强的特征表示能力,相对可观的增益以及相似甚至更少的参数量。
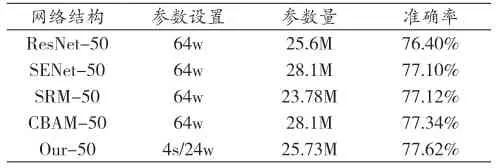
表4 ImageNet的Top-1准确率
4.3 消融实验
为了进一步探讨不同分组数的差分互补卷积对基线模型的准确率的影响。消融实验中采用的差分互补卷积具有两种消融模式,分别是全复杂度模式和保留复杂度模式。全复杂度模式具体为在增加分组数时设置只改变维度s,从而直接增加模型的参数量进行测试,而对于保留复杂度测试,则是通过在增加分组数的同时调整第二维度W进行参数的控制,维持相似的参数量。所有消融实验均在Cifar100上进行,同时为了保证对比公平,选择Res2Net作为基准模型。表3显示了在不同实验配置下的CIFAR-100测试准确性和模型尺寸。从增加复杂度下的结果可以看出,随着分组的增加,DCNet可以稳定而可靠地获得收益。 特别是,s = 4的性能从Res2Net的80.62%增加到DCNet的81.27%。而保留复杂度的结果可以看出,尽管网络参数量的减少导致了Top-1准确率的下降,但是相比于Res2Net,在相同的分组数仍高出,表明了网络的有效性和稳定性,从实验结果中观察到在分组数为6, 8的时候性能增益不明显,分析认为是CIFAR100数据集中的图像太小,分组数过多无法补充更细致的信息以生成更多的多尺度特征组合。
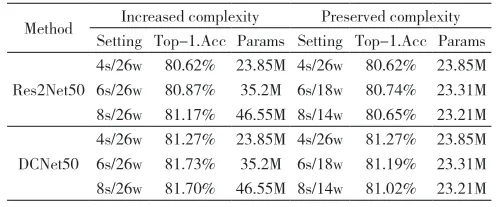
表5 消融实融
4.4 类激活可视化
为了探索DCNet的特征表示能力,我们利用Grad-CAM[11]进行观察性的类激活映射(CAM),该方法最常用于标注显著区域以进行图像分类,高亮部分为注意力区域。实验所采用网络均在ImageNet上训练完毕,采用18层的网络作为标准。从图3可以直观观察到,与Res2Net相比,基于DCNet的CAM示例在图像区域上具有更精准的激活图,在电车图中,Res2Net过多的聚焦于道路区域,而DCNet则可以更精准地注意车体本身,而减少对于干扰因素的激活。同样的现象也能在茶壶图片中发现,Res2Net仅激活了其中的两个茶壶,而其余则被标注为较浅的区域,而DCNet则可以聚焦在4个茶壶。这表明DCNet通过差分互补卷积具有更好的特征表示能力。可以观察到无论是Res2Net还是DCNet,均无法完全囊括整个区域,这是因为18层的网络的特征提取能力相对较弱的性能。
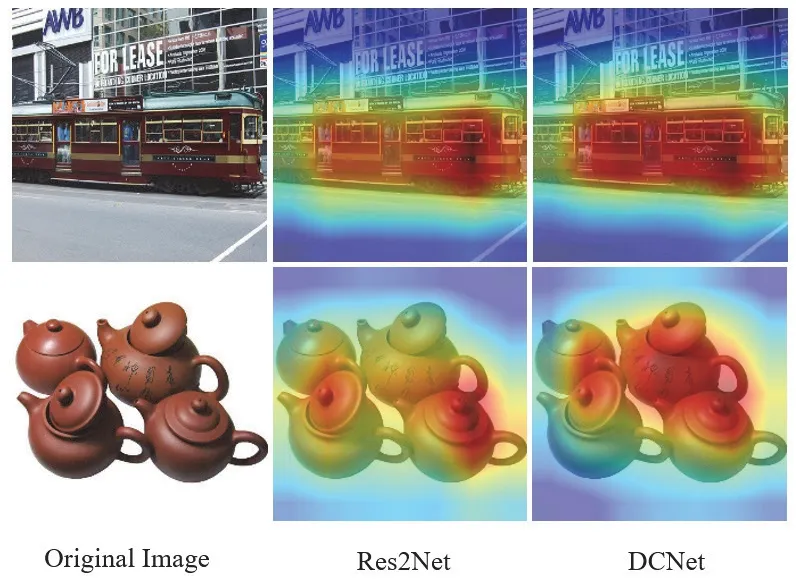
图3 基于差分互补卷积的瓶颈结构
5 结语
本文提出了基于Boosting的差分互补卷积模块作为分组卷积的扩展版本,可以利用差分信息多层级增强内部分组输入特征,并显著提高卷积层的多尺度表示能力,同时可以轻松地将其集成到常用的骨干网络中。实验结果表明,差分互补卷积巧妙地结合了集成学习和深度学习的共同理念,可以改善卷积神经网络的特征转换能力,并提高图像分类任务的准确率。因此可以进一步探索集成学习和深度学习的结合。
