Application of Hyperspectral Imaging Technology in Rapid Detection of Preservative in Milk
2021-01-15SunHongminHuangYuWangYanandLuYao
Sun Hong-min, Huang Yu, Wang Yan, and Lu Yao
College of Electrical and Information Engineering, Northeast Agricultural University, Harbin 150030, China
Abstract: To ensure the quality and safety of pure milk, detection method of typical preservative-potassium sorbate in milk was researched in this paper. Hyperspectral imaging technology was applied to realize rapid detection. Influence factors for hyperspectral data collection for milk samples were firstly researched, including height of sample, bottom color and sample filled up container or not. Pretreatment methods and variable selection algorithms were applied into original spectral data. Rapid detection models were built based on support vector machine method (SVM). Finally, standard normalized variable (SNV) — competitive adaptive reweighted sampling (CARS) and SVM model was chosen in this paper. The accuracies of calibration set and testing set were 0.97 and 0.97, respectively. Kappa coefficient of the model was 0.93. It could be seen that hyperspectral imaging technology could be used to detect for potassium sorbate in milk. Meanwhile, it also provided methodological supports for the rapid detection of other preservatives in milk.
Key words: hyperspectral imaging technology, preservative, milk, potassium sorbate, competitive adaptive reweighted sampling (CARS)
Introduction
Milk is rich in protein, fat, vitamin and minerals. It is the best source of calcium for human beings especially for children and old people (Chalupa-Krebzdaket al.,2018). There are many kinds of milk drinks on the market, such as pure milk, milk beverage and yogurt.Pure milk effectively retains the nutrients in raw milk and contains no preservative and additive. Standards for the use of food additives in China (GB2760-2014)clearly stipulate that preservatives are not allowed in pure milk. It is mainly extended quality guarantee period by ultra-high temperature sterilization. Pure milk is popular with consumers. The processing of pure milk needs strict disinfection production environment and high-precision production equipment and technology, which will greatly increase production costs. Therefore, some unscrupulous traders added preservatives into pure milk to obtain longer shelf life (Mussa and Ramaswamy, 1997; Chenet al., 2019).Potassium sorbate is common preservative in food.Studies have shown that acute, chronic poisoning or allergic reactions in humans may be caused by excessive use of sorbic acid (Naseriet al., 2009; Fujiyoshiet al., 2018). It is reported that potassium sorbate was detected in pure milk of Zhenjiang Yangtze River Dairy in China in 2014, and the potassium sorbate added per kilogram of milk was as high as 12.2 g, including pure milk. It seriously endangered the health of consumers.The quality and safety of pure milk should be paid close attention. Detection methods of preservative or additive in pure milk should be researched. Potassium sorbate was taken in this paper as an example to research detection method of preservative in pure milk.
For potassium sorbate detection, high performance liquid chromatography, gas chromatography, UV spectrophotometry, ion chromatography, etc. are commonly used at home and abroad. But these methods need complex process and long time. Spectral technology is an efficient method for rapid detection.It has been gradually used in the preservative detection of food (Martinset al., 2019; Wanget al., 2019; Wanget al., 2013). Hyperspectral imaging technology is an emerging technology that combines traditional twodimensional image technology and spectral technology. It has been proven to be suitable for the detection of complex mixed liquid (Li and Xiong, 2012).Hyperspectral imaging technology has been used to analyze fat, protein and bacteria in milk (Zhang and Tan, 2015; Zhao and Wei, 2018). Method of potassium sorbate detection in pure milk based on hyperspectral imaging technology was researched in this paper.
Milk is composed of many macromolecular particles. Scattering problem can not to be ignored, when hyperspectral imaging technology is applied into milk.Firstly, influence factors of collecting hyperspectral image data were researched, based on classification of different brands of pure milk. Secondly, detection method of potassium sorbate in pure milk was researched in this paper.
Materials and Methods
Samples for classification of different brands of pure milk
Hyperspectral imaging technology was used to collect analysis data in this paper. To research influence factors, different brands of pure milk were chosen as samples. The brands of milk and numbers are shown in Table 1. Height of samples and bottom color of container were researched, based on classification among three kinds of pure milk.
Samples for potassium sorbate detection
Qualitative analysis model should distinguish milk with potassium sorbate from pure milk. Pure milk from Mengniu, Yili and Wandashan were chosen to make samples. Twenty pure milk samples were saved from each brand of pure milk. There were 60 pure milk samples. For each brand of pure milk, 25 samples of milk with potassium sorbate were configured.Firstly, weighed a certain amount of potassium sorbate and dissolved them in deionized water to configure standard aqueous solution. Then, mixed potassium sorbate stand aqueous solution and pure milk with different contents as mixed liquid samples (Wang and Zhu, 2018). All the mixed liquid samples were with concentration of potassium sorbate from 0.2 g · L-1to 5 g · L-1and the concentration gradient was 0.2 g · L-1.There were total 75 samples of milk with potassium sorbate.

Table 1 Different brands of pure milk and numbers
Data collection system and data acquisition
Data collection system was the hyperspectral imaging system produced by Headwall Company in the United States. The system consisted of image acquisition unit,light source and sample delivery platform. Hyperspectral image spectrometer had slit width of 25 μm,spectral range from 400 nm to 1 000 nm, spectral resolution of 2.5 nm and spatial resolution of 0.15 mm.The hyperspectral imaging system was connected to a computer and the hyperspectral image acquisition and transmission was performed in the computer through hyperspectral software from hyperspectral imaging system. Sample transport platform moving speed was set to 8.5 mm · s-1and the object distance was 45 cm.
For collected hyperspectral image, black-and-white correction was necessary, because of uneven distribution of light source intensity and brightness, dark current, noise and so on. White reference (Rwhite) was captured by a standard white board with a reflectance of approximately 99% and dark reference image (Rblack)was obtained, when the lamps were turned off and the optical lens were completely covered by its cap (Panet al., 2016).RwhiteandRblackwere obtained under the same parameters as the sample image acquisition.The corrected images were calculated, according to formula (1):

Rrawrepresented the original hyperspectral image andRrepresented the calibrated image. The calibrated images were used for further data processing and analyzing.
Hyperspectral images of samples were processed using ENVI 4.6 software. For each image, three 10 mm×10 mm rectangles were selected as the region of interest (ROI), and the average spectral reflectance of ROI was calculated as the spectral reflectance of the samples.
Methods and evaluation parameters
In the process of research influence factors, random sampling (RS), principal component analysis (PCA)and support vector machine method (SVM) were used to divide sample set, select variable and build model,respectively. So as to the process of research detection method, RS, PCA and SVM were used.competitive adaptive reweighted sampling (CARS)algorithm and some pretreated algorithms were applied into detection method.
Effects of models were evaluated by accuracy of calibration set and testing set and reliability of model was evaluated by Kappa coefficient. Generally,Kappa coefficient fell between 0 and 1, and could be divided into five groups to represent different levels of classification accuracy: 0.0-0.20 (poor), 0.21-0.40(normal), 0.41-0.60 (good), 0.61-0.80 (relatively good)and 0.81-1 (very good).
In this paper, the regions of interest were extracted by ENVI 4.6 (ITT Visual Information Solutions,Bodler, USA). Pretreatment of spectral data, variable selection methods of PCA, CARS and SVM modeling were all realized by programming in Matlab R2018a(The Math Works, Natick, USA).
Results
Sample loading
Transparent measuring cup was chosen as sample container in this paper. Samples were loaded into measuring cups. To explore how to get better hyperspectral image, samples were filled the container or not. Hyperspectral images for two kinds of loading type are shown in Fig. 1.

Fig. 1 Hyperspectral image for different sample loading styles
Fig. 1 (a) was the image not filled up the container and Fig. 1 (b) was the image filled up the container.The image in Fig. 1 (a) contained grayish black shadow, which would affect extraction of region of interest and easily made the spectral reflectivity deviation of the samples. That was because the samples were not full of the container. The container edge not filled with samples would produce shadow,when data were collected by hyperspectral image system. Fig. 1 (b) proved that samples filled up containers could solve this problem.
To prove shadows would affect spectral reflectivity of the samples, one sample was loaded in different containers. All the containers had the same bottom area and different heights. The sample was loaded in five containers with height of 3, 3.5, 4, 4.5 and 5 cm. The container with 3 cm height was filled up. Other four containers were not filled up. Hyperspectral images were collected under the same condition with data collection system. There were four images with shadow. ROIs far away from shadow were selected and spectral reflectivity values were contrasted in Fig. 2.

Fig. 2 Spectral reflectivity values with different height containers for the same sample
The spectral reflectivity values in Fig. 2 were different.Samples were the same and data collection conditions were also the same. Different values were resulted from different heights of containers. So ROIs far away from shadows would also influence spectral reflectivity. Milk samples should fill up containers, when data were collected by hyperspectral image system.
Height and bottom color of container
Hyperspectral imaging technology could obtain spectral reflectivity data of samples to do analyses.Milk was not a pure liquid, but a turbid liquid. Applying hyperspectral imaging technology into milk research should consider transmission, diffuse reflection and light absorption problems. Sample height was too low, light transmission problem would be serious. On the other hand, sample height was too high, diffuse reflection and light absorption problems would be obvious. All of these problems would reduce value of spectral reflectivity and influence effect of analysis.
Fitful height of sample was researched combined with black bottom or not in this paper. Black bottom of container could reduce the problem of transmission. Five brands of pure milk were chosen to research the best height and details about samples are shown in Table 1. The purpose of this experiment was to find the best height for black bottom and transparent bottom.Firstly, one sample was chosen to load into different height containers with black bottom or not and fill up containers. Fig. 3 showed spectral reflectivity values with transparent bottom in different heights of containers. The heights of containers were from 1 cm to 5 cm with step of 0.5 cm. Fig. 4 showed spectral data about black bottom. The biggest reflectivity value was corresponding to the height of 3 cm height for transparent bottom and 2 cm height for black bottom. Based on the results, validate experiments were done with classification for different brands of pure milk.

Fig. 3 Spectral reflectivity values with transparent bottom
Each brand of pure milk was chosen 30 samples.There were total 90 samples in the experiments.Proportion of sample numbers in calibration set and testing set was 7 : 3. For transparent bottom, the biggest spectral reflectivity value changed at height of 3 cm,all the samples were loaded into containers with height of 2.5, 3 and 3.5 cm individually. For black bottom, all the samples were loaded into containers with height of 1.5, 2 and 2.5 cm individually. All the classification models were built by PCA-SVM for three groups of the samples. The results are shown in Table 2.
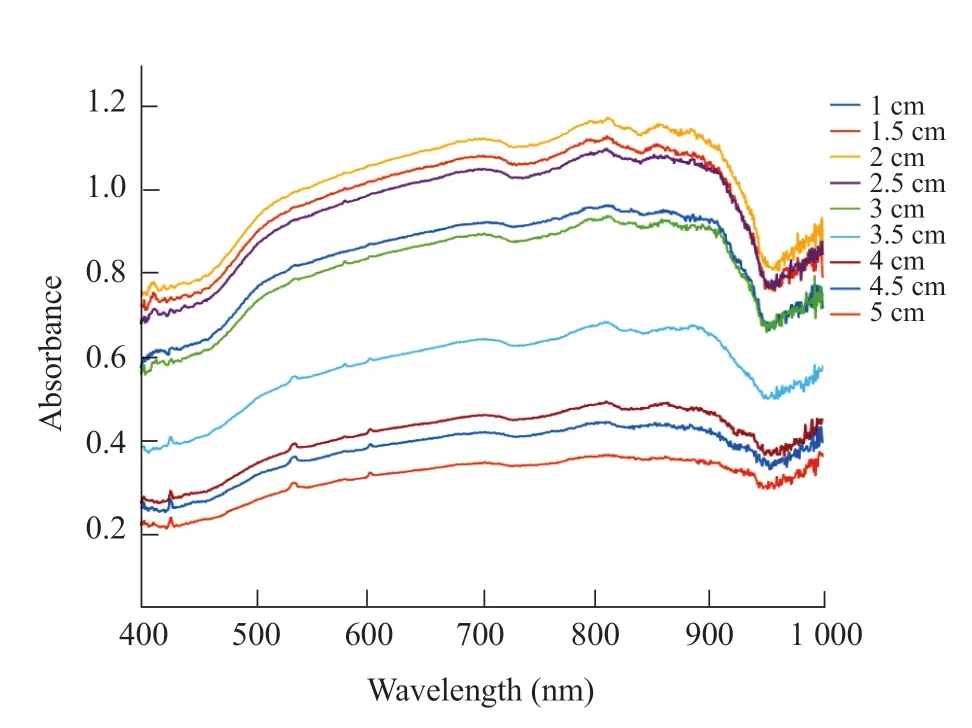
Fig. 4 Spectral reflectivity values with black bottom

Table 2 Model effects for different samples' height with different bottoms
Table 2 showed that 3 cm was the best height for transparent bottom, when applied hyperspectral imaging technology into milk research. And 2 cm was best height for black bottom. The best height of black bottom was lower than transparent, which was because black bottom effectively reduced the transmission.
In continued potassium sorbate detection method research, 3 cm height of transparent bottom container was chosen. All the samples should fill up containers.
Hyperspectral analysis data
There were total 135 samples including 60 pure milk samples and 75 samples of milk with potassium sorbate. Spectral reflectivity values for all the samples are shown in Fig. 5. There were large amount of random noise at the front and back wavelengths.Spectral data of the 50 bands before and after the raw data were removed, and spectral data with wavelength ranged from 436.86 nm to 963.71 nm was selected for subsequent research, for a total of 712 bands.

Fig. 5 Spectral data for all the samples from 400-1 000 nm
All the samples were divided into calibration set and testing set as proportion 2 : 1 with RS algorithm.Details are shown in Table 3.

Table 3 Proportion of pure milk samples and samples of milk with potassium sorbate
Spectral pretreatment
Redundant information in spectral data, which was independent of nature of samples, would infect accuracy of prediction model. Spectral data needed to be pretreated before modelling (Wuet al., 2016). The method of savitzky-golay smoothing (SG), SNV, the first derivative (the 1st Der), the second derivative (the 2nd Der) and mean centering (MC) were worked on spectral data of all the samples in this paper. Detection models were built based on SVM under raw spectral data and pretreatment spectral data with five methods.Results are shown in Table 4.

Table 4 Model effects for different samples' heights with different bottoms
Table 4 showed that SNV and SG method had better effects. Accuracies of calibration set and testing set of SVM models were improved after pretreatment by SNV method than no pretreatment. Results showed that SNV method could eliminate interference signals unrelated to potassium sorbate and retain useful spectral information. After analysis, it was found that milk had strong scattering properties due to presence of fat globules and suspended protein micelles of milk(Bogomolovet al., 2012). SNV could eliminate the influence of particle size and uniformity changes on the spectrum, so the interference caused by scattering could be effectively eliminated after treated by SNV (Penget al., 2019). Therefore, SNV was selected as the best spectral pretreatment method in this research.
Variable selection
There were lots of invalid and redundant information in high dimension hyperspectral data. Variable selection method was necessary in the research. Variable selection could not only enhance the prediction performance of calibration model by reducing variable collinearity and eliminating the uninformative variables, but also help to interpret the relationship between the model and the sample compositions (Hasanlouet al., 2015). PCA method and CARS algorithm were used for variable selection in this paper to remove irrelevant information and find effective band information.
PCA method was one kind of common data dimension reduction method. It could recombine variables that might be correlated by linear transformation. The principal components after dimension reduction retained as much information of the original variables as possible and were independent of each other. The principal components were used as the input variables for modeling, which reduced the number of input variables and effectively improved the running speed of the algorithm (Fabiyiet al., 2019).
CARS algorithm was a variable selection method based on Darwinian Theory of survival of the fittest.Firstly, partial least squares (PLS) model was established based on the calibration set selected by Monte Carlo sampling. Then absolute value weight of the wavelength regression coefficient was calculated. The wavelength variables with small absolute values were removed, and the numbers of wavelength variables were determined by the attenuation exponential method.Finally, based on the remaining wavelength variables,adaptive reweighted sampling was adopted to select the wavelength to establish the PLS model, and the wavelength corresponding to the PLS model with the smallest mean square error of internal cross-validation(RMSECV) was the selected characteristic wavelength(Wanget al., 2017).
For PCA variable selection method, principal components with contribution rate greater than 99% were selected. There were 84 principal components being chosen. Contribution rate of chosen principal components is shown in Fig. 6. Contribution of the first component was 56.3%. The 84 principal components could explain original spectral data by 99.04%.
Process of selecting variables by CARS could be embodied as shown in Fig. 7. Fig. 7 (a) indicated the tendency of the number of variable to change. It could be seen that the modeling variables decreased rapidly with the increase of sampling times at the early stage of sampling, and then decreased flatly with the increase of sampling times. The exponential relationship between the number of variables and the number of runs decreased, indicating that the selection of wavelength variables was divided into two processes "primary selection" and "subtle selection".

Fig. 6 Contribution rate of chosen principal components by PCA
Fig. 7 (b) showed the change trend of RMSECV values. RMSECV values in Fig. (b) indicated the prediction effect of PLS model based on variable selection of CARS. RMSECV values showed decreasing trend at first, indicating that uninformative variables were continuously eliminated, during the sampling process. Then, RMSECV value did not change significantly, indicating that the number of variables did not change significantly. Finally, RMSECV value gradually increased, indicating that some key variables were eliminated.
Fig. 7 (c) showed the variation trend of regression coefficient value of each variable. Each line in Fig. 7 (c)represented the variation trend of regression coefficient values for each variable at different sampling times.During each sampling process, some useful variables were extracted. When RMSECV value was minimum,which was the 24th sampling operation in Fig. 7 (c),the optimal number of modeling variables was determined. After the 24th sampling, the RMSECV values in Fig. 7 (b) gradually increased because some key variables were eliminated. Therefore, according to the principle of minimum RMSECV values, 45 key variables were extracted to replace the original spectrum for further analytical modeling.

Fig. 7 Results of variable selection by CARS
Detection models with SVM
PCA and CARS variable selection methods were researched. There were 84 principal components chosen in PCA and 45 variables selected in CARS algorithm. To find better model, detection models based on SVM were built under original spectral data,analysis data by PCA and spectral data by CARS.Results are shown in Table 5.

Table 5 Detection model for original data and analysis data by PCA and CARS
Contrasted values of calibration set accuracy, testing set accuracy and Kappa coefficient for different models, models for analysis data by CARS algorithm had better effects. Accuracies of correction set and testing set all reached 0.97. Kappa coefficient of the model was 0.93. Accuracy and stability of the model were suitable for detection of potassium sorbate in practice. SNV-CARS-SVM model was chosen in this paper to detect potassium sorbate in milk.
Disscussion
Hyperspectral imaging technology as a rapid detection tool for potassium sorbate in milk
Results in Table 5 showed that hyperspectal imaging technology could be applied into potassium sorbate detection in milk. The accuracies of calibration set and testing set for SNV-SVM model without variable selection were higher than 0.9. Kappa coefficient was higher than 0.8. Values of accuracy and Kappa coeffi-cient would be increased after variable selection. The accuracy and stability of detection model could be suitable for rapid detection of potassium sorbate in milk in practice. Combined with the results in Table 2,hyperspectral imaging technology could be used to classify different brands of pure milk. Hyperspectral imaging technology could be applied into related research of milk, such as other preservative, additive and components.
Variable selection using for potassium sorbate detection in milk
From Table 5, it could be concluded that variable selection was useful for potassium sorbate detection method in milk. Values of accuracy of testing set for model with PCA or CARS were higher than model with no variable selection. Similar results were shown in Kappa coefficient. Accuracies of calibration set and testing set based on PCA and CARS methods were significantly improved compared with none variable selection. After variable selection by PCA, accuracy of correction set was increased by 0.02%, and variables had been reduced from 712 to 84. For CARS method,accuracies of calibration set and testing set were increased by 0.06 and 0.03, respectively. Numbers of variables reduced from 712 to 45. The results showed that variable selection by PCA and CRAS algorithms could effectively replace the original spectral data for modeling. While improving the accuracy of the model,the numbers of variables were reduced, and the computation and complexity of the model were reduced.
CARS algorithm removed irrelevant variables for potassium sorbate detection
In Table 5, accuracy of the calibration set and testing set for SNV-CARS-SVM model was higher than SNVPCA-SVM model. And Kappa coefficients had the similar trend. Accuracy of calibration set for SNV-PCASVM model was equaled to SNV-SVM model. That was because PCA was algorithm according to dimensionality reduction. Variables from PCA were not original variables, but could represent all the variables.Method of CARS was algorithm according to selection.Variables from CARS were part of original variables.Selecting closely relate variables was more useful in potassium sorbate detection. Therefore, CARS was better variable selection method than PCA in this research.
Conclusions
To ensure quality and safety of pure milk, potassium sorbate was taken as an example to explore rapid detection method by hyperspectral imaging technology. Influence factors for hyperspectral image data collection for milk samples were researched firstly.Milk sample should fill up container. The best sample height for transparent bottom container was 3 cm. SG,SNV, the 1st Der, the 2nd Der and MC were used to pretreat original spectral data and SNV was the fitful pretreatment method. PCA and CARS were used to select variables. Detection models were built with SVM for original data and variable selection data by PCA and CARS. Finally, SNV-CARS-SVM model was the best model to detect potassium sorbate in milk in this paper. Accuracies of calibration set and testing set were both 0.97 and Kappa coefficient was 0.93. The results proved that hyperspectral imaging technology could be used to detect preservative in milk.
杂志排行

Journal of Northeast Agricultural University(English Edition)的其它文章
- Anti-inflammatory Effects of Baicalin (In Vitro and In Vivo)
- Length-weight and Length-length Relationships for Nine Freshwater Species from Huaihongxinhe River, Huaihe River Basin, East China
- Effect of Chromium Propionate Substituting 25% Rumen-protected Choline on Production Performance and Blood Indicators of Perinatal Dairy Cows
- Effects of Crop Rotation and Microbial Fertilizer on Nutrient Absorption and Beneficial Bacterium Abundance in Rhizosphere of Continuous Cropped Eggplant
- Effects of Two Chelating Agents on Availability of Calcium and Phosphorus in Black Soil of Vegetable Fields
- A Bicycle Tourism Based Study on Planning and Designing of Urbanrural Recreational Greenway
—— A Case Study of Harbin City