面向新浪微博的情感社区检测算法
2021-01-15韩东红张宏亮朱帅伟齐孝龙
韩东红, 张宏亮, 朱帅伟, 齐孝龙
(东北大学 计算机科学与工程学院, 辽宁 沈阳 110169)
随着Web 2.0的出现和普及,互联网用户迅速从信息的消费者转变成了信息的生产者.借助微博为代表的社交网络平台,用户可以自由表达情感、互动交流,使得跨越地理位置而具有相同喜好的用户聚集成一个社区成为可能.因此通过挖掘分析海量社交网络数据,发现其中潜在社区已经成为近年来的热点研究问题.
社交网络中的社区发现概念最早由Newman等[1]提出,即发现社交网络中的内聚子群,其中节点与节点之间的联系非常紧密,而子群之间的联系相对稀疏.社区发现有助于进一步认识、理解复杂网络,可用于社会网络演变[2]、个性化推荐[3]、市场营销[4]等应用研究.情感社区的概念则由Xu等[5]首次提出,旨在发现社交网络中对某商品质量或服务有相同情感或观点的联系紧密的用户群,以帮助企业改进生产、设计营销策略.
作为最大的中文社交网络平台,截至2017年5月份,新浪微博用户数已超过Twitter,达到3.4亿.可见,在线社交网络已成为连接网络虚拟空间和人类物理世界不可或缺的桥梁.如果能通过微博用户的文本及网络交互信息,分析在某一话题下具有情感倾向一致性的用户群体,对于微博情感分析、舆情监测及心理学研究等领域都具有重要意义.例如在网络舆情分析方面,通过挖掘微博热点事件中的情感社区,可以帮助政府了解网络舆情以及不同情感社区的构成;在心理健康分析领域,对微博用户进行情感社区划分,便于进一步对其中的高压力人群实施针对性的心理疏导和专业干预.
基于此,本文对面向新浪微博的情感社区检测算法进行了深入研究.作为首个面向中文微博进行情感社区发现的研究项目,本文首先在构建情感社区检测框架的基础上,融合微博情感表情建立情感词典,提出基于朴素贝叶斯半词典半表情(SL-SE-NB)算法进行文本情感倾向预测;并提出一种基于潜在狄利克雷分配(latent Dirichlet allocation,LDA)话题模型的用户-超话题-关键词(UTK)模型,使之能准确挖掘用户话题,同时解决微博网络稀疏性问题;最后由于传统社区划分算法大多基于网络结构而忽略用户产生的文本内容,本文在标签传播算法(label propagation algorithm,LPA)基础上加入话题概念,并抽取带有情感倾向的用户作为种子集进行标签传递,提出SMB-LPA算法以发现情感社区.
1 相关研究工作
情感分析和社区发现是社交网络挖掘中重要的两个研究领域,本研究融合了两个领域中的相关技术,下面分别介绍它们的研究成果.
1.1 社交网络中的情感分析
情感分析亦称观点挖掘,由Nasukawa等在2003年提出,旨在通过文本分析进行情感计算,从而提取用户的情感倾向(极性)及所持观点[6].有研究将情感分析划分为篇章级、句子级和词及属性级三种层次[7].其中词语级情感倾向研究是核心,即发现文档中的主观词或用户在实体及属性上表达的观点词并分析其情感倾向.情感极性包括粗粒度和细粒度两种,前者将情感分为正、中、负三类,而后者则给出“喜怒哀乐惊恶恐”等复杂情绪倾向.目前,社交网络情感分析方法分为基于情感词典(无监督)和基于机器学习(有监督)两类[8].
基于词典和规则的方法一般不需要训练数据,通过构造文档或句子中的情感函数,计算出情感极性[9].Fersini等[10]综合考虑形容词、表情符号、拟声词等作为微博情感分析中的表达符号,并证明了该方法能够丰富特征空间及提高情感分类的性能.杨佳能等[11]基于情感词典对微博文本进行依存句法分析并且构建情感表达树,再根据制定的规则计算微博文本情感强度并判断文本的情感倾向类别.Saif等[12]提出了一种不同于典型情感词典的方法,即对Twitter文本进行情感分析时,考虑了在不同语境中词的共生模式以便捕捉其语义,并相应更新其在情感词典中的极性.
基于机器学习的方法则使用含大量标注的训练数据,选择不同的监督学习方法如朴素贝叶斯、最大熵、SVM等构造分类器,实现对微博文本的情感极性预测[13].Wang提出了一种融合情感词典和机器学习的方法对旅游评论进行情感极性分析[14],即采用向量空间模型并通过情感词典降低特征空间维度,通过TF-IDF计算权重,再利用SVM分类器对旅游评论的情感极性分类.一种深度信任网络DBN模型和多模态特征抽取方法对中文短文本进行情感分类亦被提出[15],多模态特征结合传统文本特征作为DBN模型的输入向量,RBM层利用输入数据的概率分布抽样来学习隐藏的语义结构,最后RBM分类层完成对中文短文本的情感分类.
1.2 社区发现
社区发现又称社群监测,用以发现社交网络中的社区结构,相关算法主要分为3类,即基于网络拓扑结构的社区发现、基于语义的社区发现及融合拓扑结构和语义的社区发现[16].
基于网络拓扑结构的算法分为非重叠社区划分和重叠社区划分,前者主要包括谱聚类方法(如最小割算法[17])、模块度优化方法(如GN算法[18])、基于标签传递策略(如LPA)[19],而重叠社区划分算法的代表包括基于团渗透改进的CPM算法[20]、基于种子集传递的LMF算法等[21].用户的文本内容是衡量其情感、兴趣倾向等的重要载体,此类方法的特点是仅考虑用户之间的拓扑关系,用户间的相似度度量并不全面.
基于语义的社区发现算法则通过文本内容的相似性进行聚类,并根据文本相似性划分社区.话题模型是典型的文本聚类方法.Blei等[22]提出的LDA模型将“话题”概率化,认为模拟文章的生成过程,可以先从文档-主题分布中抽取一个主题,再从主题-词分布上抽取一个词,抽取概率均由狄利克雷分布模拟生成.针对社交网络中出现的短文本数据,Yang等提出了TS-LDA模型[23],从文本内容中抽取出随时间变化的潜在动态话题.Song等[24]提出PTM模型,将成对的用户关系融入到话题模型中,以发现潜在话题和转移话题.A-LDA模型[25]为了能够抽取出某段时间内的微博热点话题,在LDA的基础上加入了时间属性和标签属性.Li等进一步提出PAM模型[26],用一个有向无环图(DAG)表示语义结构,不仅可以 描述词之间的相关性,而且可以灵活描述主题之间的相关性,较LDA具有更强的文本表示能力.
融合拓扑结构和语义的社区发现算法是结合网络拓扑结构和文本信息建立模型,旨在挖掘有共同兴趣的群体.Zhang等提出了一个联合框架,即挖掘兴趣社区时融合了话题模型和用户的关注关系网[27].Yang等[28]在CESNA算法的基础上,提出融合网络结构和节点属性的重叠社区发现算法.
1.3 情感社区发现
与传统社区发现不同,情感社区检测是指挖掘社交网络中有相似情感倾向或持相似观点的社群.尽管社区发现的研究成果已经频频问世,情感社区挖掘的研究才刚刚开始.Xu等[5]首先给出“情感社区”定义,同时提出两种情感社区发现算法,目标是使社区内用户情感的一致性最大化.通过Epinions网站API获取的数据建立用户信任关系网,将用户对产品的评论分为“积极”、“中性”、“消极”三种极性,并基于所提出的算法将社区划分为对应的三种情感社区.Wang等[29]提出了两种情感社区检测方法,目标分别是模块度最大化和最小化情感差异.通过爬取电影评论网站Flixster获取数据集并根据彼此分享影评以建立朋友关系网,利用提出的情感社区发现算法区分具有不同情感极性的社区.Deitrick等[30]则首先利用随机游走策略划分社区,并在全局社区内及某话题下社区内进行不同层次的情感分析,最后通过@technet社交网络数据验证所提出算法的有效性.文献[31]利用情感分析强化社区发现,即在社区检测考虑评论、转发、回复等文本内容作为Twitter特征.
以上成果均面向英文社交网络,目前尚无针对中文社交媒体的情感社区发现研究,而该研究对网络舆情、公共心理健康、个性化推荐等领域均有重要意义和应用价值.
2 情感社区检测算法
2.1 相关定义
定义1微博用户集合U:U={u1,u2,…,uN},其中ui表示第i个用户,ui∈U,N为微博总用户数.
定义2微博博文集合B:用户ui发表的微博集合为Bi={bi1,bi2,…,biM},其中M表示用户ui发表的博文总数,Bi∈B.
定义3博文词集合W:对于用户ui发表的博文bij可表示为词的集合Wij={wij1,wij2,…,wijK},K表示bij中包含词的总个数,wijK表示博文bij中第K个词.
定义4博文表情集合E:对于用户ui发表了微博bij,在该篇博文bij中使用的表情集合为Eij={eij1,eij2,…,eijP},其中P为ui在博文bij中使用表情的个数,eijP表示博文bij中第P个表情.
定义5情感词典集合:本文一共涉及4种词典,分别是积极情感词典(用PWD表示)、消极情感词典(用NWD表示)、积极表情词典(用PED表示)和消极表情词典(用NED表示).
定义6博文情感倾向:先分别计算积极情感词、消极情感词、积极表情、消极表情在博文中出现的后验概率Ppw,Pnw,Ppe和Pne,情感倾向计算如式(1)~式(3)所示.
Aw=Pnw-Ppw.
(1)
Ae=Pne-Ppe.
(2)
A=aAw+bAe.
(3)
其中:Aw为博文考虑情感词后的情感倾向;Ae为博文考虑表情后的情感倾向;A为二者综合考虑后博文最终的情感倾向.若A>0,判定该博文的情感倾向为负向;若A<0,判定博文的情感倾向为正向;若A=0,则判定该博文情感倾向为中性,其中a和b为参数,a+b=1.
定义7超话题:微博话题主要是指#号与#号之间的内容,如#魏则西百度推广事件#,所谓超话题就是进一步抽取话题,如上述话题可拆分成#魏则西#和#百度#等超话题.
定义8子话题:本文所提出的UTK模型是基于LDA模型改进的,主要是对用户-超话题-子话题-关键词模型建模,在本模型中的子话题相当于LDA模型中的话题角色,是基于用户微博内容进行抽样得到的类别分布结果.
定义9情感社区:在特定的话题下,微博用户对该话题具有相同情感倾向的社交网络群体,称为一个情感社区.
2.2 处理框架
面向新浪微博情感社区发现的总体框架如图1所示.首先爬取微博文本和用户关系;在数据预处理阶段,数据经三轮清洗后,利用构建的情感词典对文本进行分词处理;对用户博文进行情感词和表情词统计,利用SL-SE-NB算法进行情感倾向计算;接着使用UTK模型进行话题抽取,最后抽取带有情感倾向的用户作为种子集进行标签传递,利用SMB-LPA算法发现情感社区.

图1 情感社区检测处理框架
2.3 情感检测SL-SE-NB算法
构建情感词典时本文借助了目前所有较权威的情感词典,其中有褒贬词及其近义词词典、博森实验室网络情感词典、清华大学李军中文褒贬义词典、大连理工大学中文情感词汇、台湾大学NTUSD简体中文情感词典和知网Hownet情感词典.去除一些不常用的词或者短语,最后获得68 432个正向情感词,41 382个负向情感词.再从微博中提取表情文字并进行词频统计,过滤不常用的表情符号后进行人工标注,共获得573个正向情感表情,343个负向情感表情.最后,得到由情感词词典和情感表情词典构成的情感词典集合.为预测微博文本的情感极性,本文提出了基于情感词词典集合和朴素贝叶斯的SL-SE-NB算法,其伪代码如下.
输入:情感词典集合,训练集, 未标注的微博数据集
输出:有标注的微博数据集
1. For eachbijin 训练集
2. 统计消极训练数据集中情感词及情感表情的权重;
3. 统计积极训练数据集中情感词及情感表情的权重;
4. 统计中性训练数据集中情感词及情感表情的权重;
5. End for
6. For eachbijin 未标注的微博数据集
7. For eachwijK∈Wij‖eijP∈Eij
8. If (wijK∈NegativeWordDic‖wijK∈
Positive WordDic) then
9. 统计当前微博中的情感词wijK的词频;
10. For eachwijKin 当前词的权重
11. 计算wijK出现在消极微博中的后验概率;
12. 计算wijK出现在积极微博中的后验概率;
13. End for
14. End if
15. If (eijP∈NegativeEmojiDic‖eijP∈
PositiveEmojiDic) then
16. 统计当前微博中情感表情eijP的词频;
17. For eacheijPin 当前表情的权重
18. 计算eijP出现在消极微博中的后验概率;
19. 计算eijP出现在积极微博中的后验概率;
20. End for
21. End if
22. If(A>0) then
23. 极性=-1;
24. Else if (A<0) then
25. 极性=1;
26. else
27. 极性=0
28. End if
29. End if
30. End for
31. End for
SL-SE-NB算法是先训练分类器模型再对测试数据进行情感极性预测的过程.其中第1~5行是统计情感词和情感表情在消极训练数据集、积极训练数据集和中性训练数据集中出现的权重,至此分类模型训练完毕.第6~7行开始遍历实验数据集中每篇博文的每个单词和每个表情;如果这些情感词出现在情感词典(积极情感词典或者消极情感词典)中,分别计算该词在消极微博中的后验概率和在积极微博中的后验概率,代码如8~14行所示,NegativeWordDic与PositiveWordDic分别为消极情感词典与积极情感词典;同理可以计算出每篇博文中每个表情出现在消极微博中的后验概率和每个表情出现在积极微博中的后验概率,代码如15~21行,NegativeEmojiDic与PositiveEmojiDic分别为消极表情词典与积极表情词典;第22~29行是根据式(1)~式(3)判断博文情感极性,但为了使算法达到最优还需进行调参.
2.4 话题UTK模型
LDA是一个文档-话题-词的三层贝叶斯框架模型,可以发现主题和词之间的相关性,却忽略话题之间的相关性.本文提出了基于LDA的UTK模型,即利用微博#与#之间的话题,将其加入到LDA模型中,将原LDA模型修改为用户-超话题-子话题-关键词的4层模型,旨在准确地挖掘出用户主题,同时解决了微博网络稀疏性问题.
UTK模型如图 2所示.
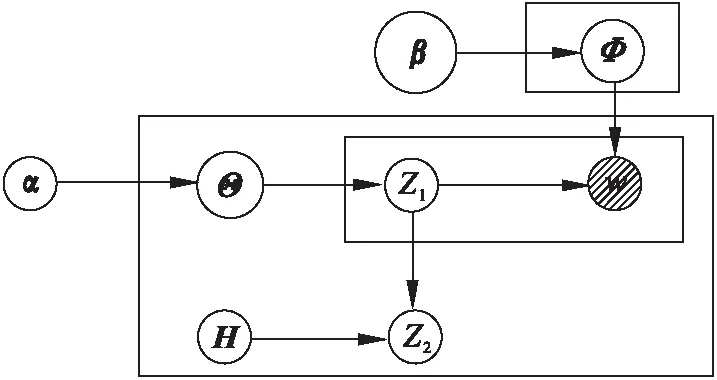
图2 UTK模型
文档生成的超话题分布Z1、子话题分布Z2和关键词分布参数矩阵为Θ的联合概率如式(4)所示.其中w为关键词的多项式分布,H为超话题多项式分布的先验均匀分布的参数矩阵,α和β分别是参数矩阵为Θ和Φ的狄利克雷分布的超参数.
P(w,Z1,Z2|α,β)=P(w|Φ,Z1)·
P(Z1|Θ)P(Z2|H).
(4)

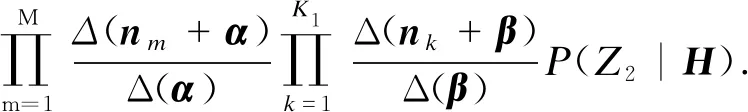
(5)
式中,Δ(·)为狄利克雷分布的归一化因子.
基于式(5),本文用吉布斯抽样法对博文中每个词的主题进行抽样,得到UTK模型算法的伪代码如表1所示.

UTK模型算法中第1~2行分别对训练集中每篇博文抽取关键词并加载语料库.第3~5行是为了保证让训练的主题个数至少为1,第6行计算词汇表中关键词对的超话题的概率,第7行进行吉布斯采样,通过计算文档-主题矩阵和主题-词矩阵以获取Θ和Φ概率矩阵.第8行获取最大概率的前10个关键词对应的超话题,第9~11行是保存每个主题出现概率最高的10个词,至此UTK模型训练完成.第12行是抽取每篇新博文中的关键词,第13行是结合新博文和UTK模型中的词汇表,构建一个新词汇表.第14行利用Φ矩阵计算重新采样每个词的话题,第15~17行输出新文档中话题概率最高的10个话题,并把结果写入到UserTopics文件中.
2.5 SMB-LPA算法
社区发现的经典算法包括LPA和GN算法.LPA优点是收敛速度快,但遇到多个标签时,LPA的随机选择会带来算法的不稳定,即算法每次执行后的结果都会不同.GN算法考虑了全网结构,找到的社区准确率较高,但计算最短路径时时间复杂度较高.并且二者均利用网络结构进行社区检测,未考虑带有情感倾向的文本信息,故不能直接用于情感社区发现.
本文对上述两个算法进行优化,提出了用于情感社区挖掘的SMB-LPA算法.在标签初始化部分采用了SL-SE-NB算法的情感倾向计算结果,通过从微博中提取具有代表性的种子集,将其情感极性作为该用户节点的标签,这样就可以基于某个话题,将其划分为积极、消极和中性社区.SMB-LPA算法见表2.

第1行加载边关系和根据种子集初始化标签,第2行初始化记录迭代次数iter_time.第3~20行是进行标签传递的过程,若can_stop()为true且迭代次数小于最大迭代次数max_iter,则进行标签传递.第6~8行若标签为种子集中的标签,则不进行标签更新.第9~12行若只有一个最大标签,直接选取最大标签为新标签.第13~18行若遇到多个最大标签,则采用最小边介数进行标签传递;第19行将迭代次数加1进入下次标签传递.
3 实验与结果分析
3.1 实验环境与数据集
本文的实验所需数据主要包括了微博用户内容、微博用户关系和数据清洗完以后的数据以及用户关系等.本文通过搭建分布式爬虫框架,爬取了2016年5月2日到2016年5月16日发布的微博数据,共搜集9 028 632篇微博,539 564个用户.这些微博原数据经过3轮数据清洗后,清洗掉一些转发微博、回复微博、广告、新闻等内容,同时过滤了一些中英、中日、中韩混用的微博,并且把繁体微博转化成简体微博,大约剩下1 471 234篇微博可供实验选择.
因为本文主要研究的是计算原创微博的情感倾向,并且主要针对的是大众用户和活跃用户,鉴于此,本文根据微博用户信息又进行了一次筛选,最后符合本实验的微博用户有以下几个特点:① 在2016年5月2日到2016年5月16日期间发表微博篇数在25到35之间,且没有被新浪微博屏蔽的用户,本文称这些用户为活跃用户; ② 用户必须有粉丝或者关注;③ 有认证信息的用户不作为研究对象,因为有认证的大多数微博用户发表的博文是积极的.基于上述要求,本文最后选取了98 250篇微博,3 323个微博用户作为实验数据集.最后又爬取了这3 323个微博的关注或者粉丝关系,一共获得479 543条边关系.
本文采用的软、硬件参数如表3所示.
3.2 情感倾向计算实验结果分析
首先需要确定式(3)中的两个参数值,其中a为情感词特征的权重,b为情感表情特征的权重.为了使分类准确率最高,本文对a和b进行了参数设置.进行参数设置的数据集选取了已经标注的2 000条数据进行召回率对比实验.如图3所示,当a=0.8或者b=0.2,召回率最大.本文选取了基于情感词典的情感分类算法(Senti-Lexicon)[32]、朴素贝叶斯分类算法(Naive Bayes) 进行性能对比.本文采用召回率和F1值作为实验评价指标,结果见图4和图5.
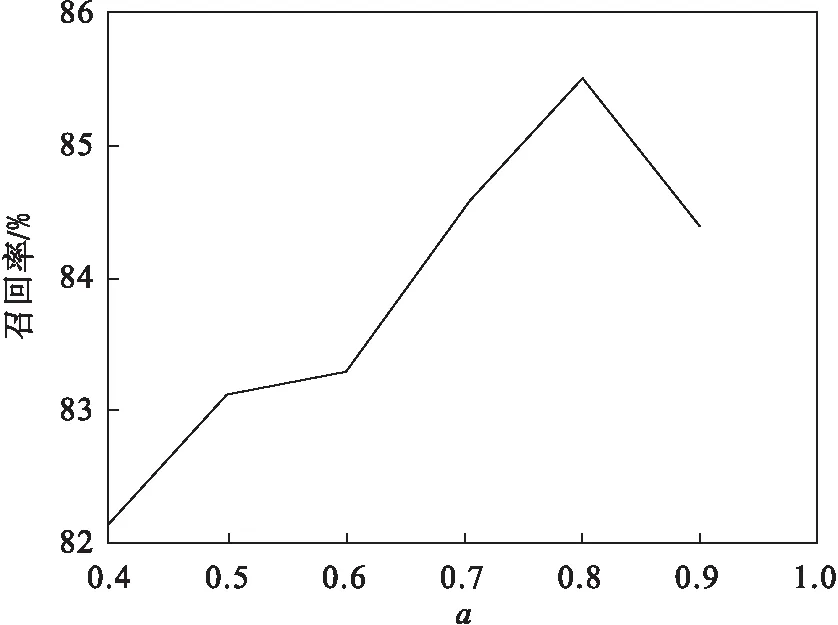
图3 a取值对召回率的影响
从图4中可以看出SL-SE-NB算法比其他两种算法(Senti-Lexicon和Naive Bayes)的召回率都要高,但是随着数据集样本量增加,三种算法的召回率都呈递减趋势.这主要是因为测试数据集存在一定噪声数据,随着样本量增加,噪声数据也越来越多,从而导致了召回率下降.
从图5中可以看到,本文所提出的SL-SE-NB算法的F1值高于其他两种算法,但随着实验数据集样本量增加,F1值均呈下降趋势.原因是实验数据集由本实验室人工标注,故存在个人标注差异,数据量较小时,这种差异不明显,随着数据量的增加,差异性就会显现.

图4 不同算法的召回率对比
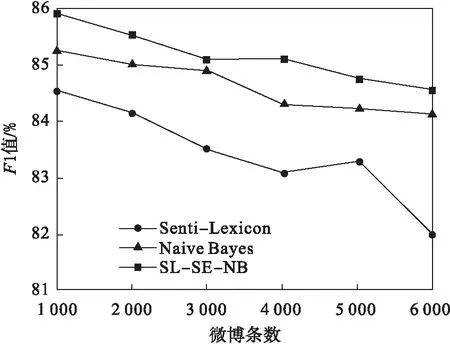
图5 不同算法的F1值对比
3.3 UTK模型结果分析
在UTK模型中有3个参数需要设置,分别是话题数K、狄利克雷分布的超参数α和β,以及迭代次数.在评价话题抽取模型的性能时,采用召回率、困惑度作为评价指标;对比算法选取了LDA模型和PAM模型.
关于最优话题数K的设置, Blei等[22]提出了一种根据设置不同的topic数量画出话题数-困惑度曲线图,然后来确定最佳的话题K.本文采用该方法设置话题数K如图6所示.可以看出,随着话题数增加,困惑度趋于减小;当话题数达到100以后,困惑度值基本趋于收敛,所以本文取话题数K=100.此结果与训练数据集比较吻合,训练数据集的超话题数共有102个.这也从侧面说明本文所提出的UTK模型可以找出与训练数据集中话题个数相等的话题.其他参数如狄利克雷分布的超参数α和β,及迭代次数,最后又经验调优得到α=0.1和β=0.1(向量的每一维都相同,为0.1),而最大迭代次数为1 000.
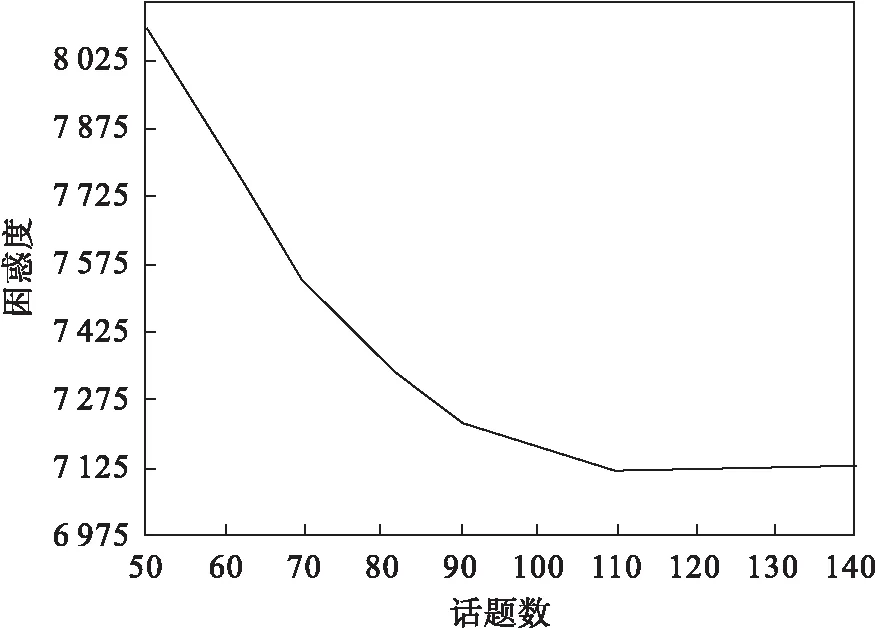
图6 话题-困惑度关系
测试数据集的超话题编号集合为{1,12,28,35,42,56,63,71,85,97,101},从图7中可以看出,UTK话题模型的召回率均高于传统LDA模型和PAM模型.在1号超话题和63号超话题的测试数据集上,UTK模型的召回率可以达到83.20%和82.56%.但在56号超话题上UTK的召回率降到了70.45%,原因是它是关于#戛纳电影节#的一个超话题,其中涉及到的明星名字非常多,会导致在话题抽取的时候把其中关于某个明星的内容归类到其他超话题中,从而出现召回率降低的情况.相对于LDA模型,PAM模型融入了层次化思想,不仅可以对子节点进行聚类,而且可以抽取更有代表性的父节点层,所以PAM模型得到的实验结果虽不如UTK模型,但是比LDA模型有优势.

图7 主题质量图
在相同参数下,分别计算UTK模型、PAM模型和LDA模型的困惑度,结果如图8所示.可以看出,随着迭代次数的增加,困惑度趋于收敛,UTK模型的困惑度要比其他模型的困惑度小.这也说明UTK模型可以用于真实数据集建模和预测.同时也可以看到当迭代次数超过1 000时,困惑度基本不再变化,所以本文在真实数据集上进行话题抽取的时候,选取的迭代次数为1 000.

图8 迭代次数-困惑度关系
3.4 SMB-LPA算法实验结果分析
本文采用模块度、规范化互信息和算法的运行时间等评价指标,对比算法是LPA,GN,SCD[33],GEMSEC[34]和Edmot[35].使用开源框架Karate Club[36]来实现SCD,GEMSEC以及Edmot算法,并且在实现的过程中,将用户作为节点,将用户所发的经过分词后的微博作为该节点的特征.
模块度是指给定一个由n个节点和m条边组成的网络,在任意两个节点vi和vj之间,边的期望值为(didj)/(2m),其中di和dj分别是两个节点vi和vj的度.考虑一条边从节点vi出发,随机连接网络中的任意节点,那么它以di/(2m)的概率连接节点vj.由于节点vi的度为di,也就是说,这个节点有di条边,所以在两个节点vi和vj之间,边的期望值为(didj)/(2m).结合上述解释,模块度的计算公式为
(6)
为了计算方便常常引入参数1/(2m),让模块度值归一化到-1~1之间.模块度越大证明社区划分的质量越好.
规范化互信息是用来度量两个聚类结果的相似度的,计算公式为
NMI(πa;πb)=
(7)

实验抽取了两个比较活跃的话题进行了模块度计算,最后的模块度值是对5次结果求平均值取得的.结果如表4所示,可以看出SMB-LPA算法是6个算法中模块度值最大的,同时每次计算的模块度值差别不大,这也说明SMB-LPA算法具有很好的稳定性.LPA的模块度值差异较大,这是由标签传播算法的随机性造成的.SCD与GEMSEC算法的模块度值较小,这是由于聚类算法没有种子集作为起始标签,仅由节点的特征来进行聚类,而且节点的特征矩阵又较为稀疏,所以聚类的结果中很多社区只有单一一个节点,这样的原因也导致了算法检测出的社区数量非常多,算法的模块度与规范化互信息都很低.而Edmot算法通过边增强的方法,增强了输入网络的原始连接结构以生成重新连接的网络,从重新连接的网络中获得的社区数量较少,所以其模块度较高.虽然Edmot算法的模块度高,但是其规范化互信息较低,原因是虽然其划分出的社区数量少,但是划分的准确度低,与标注值的差异依然很大,所以其模块度高但是规范化互信息低.且由图9可知,SMB-LPA算法的规范化互信息高于其他的算法.
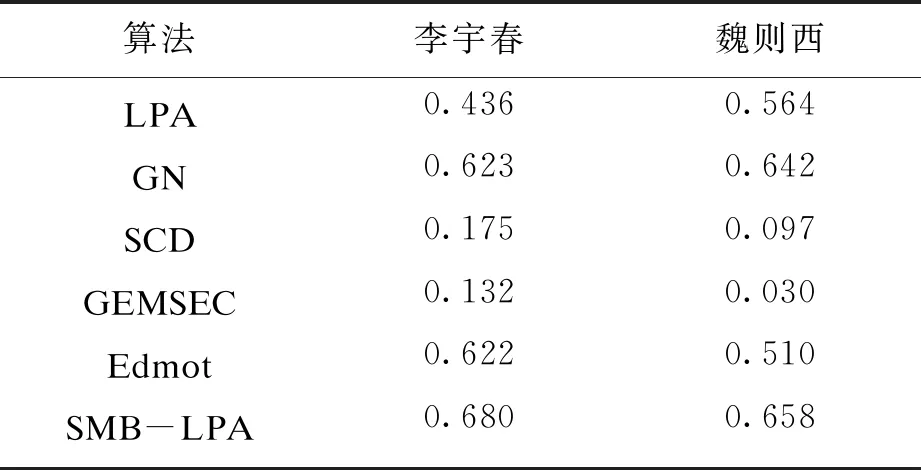
表4 模块度值比较
本文对平均运行时间也进行了对比,即将每个算法分别运行30次求平均值,结果如表5所示.可以看出LPA的运行时间最短,而SMB-LPA次之,然后就是GN算法,其余算法的运行时间较长,尤其是GEMSEC算法的运行时间特别长.LPA运行时间短的原因是其执行时只需要根据标签进行随机传递,不需要计算其他额外变量;而SMB-LPA算法在LPA的基础上,需要计算最小边介数,所以运行速度不及LPA; GN算法需计算全部的边介数,SMB-LPA算法在最大标签个数不唯一时才需要计算边介数,所以SMB-LPA算法要比GN算法的运行速度快.SCD,GEMSEC以及Edmot算法由于其在聚类过程中需要将节点及其邻接节点的特征值纳入计算过程中,而且没有种子集作为起始标签进行传递,所以计算过程较长.
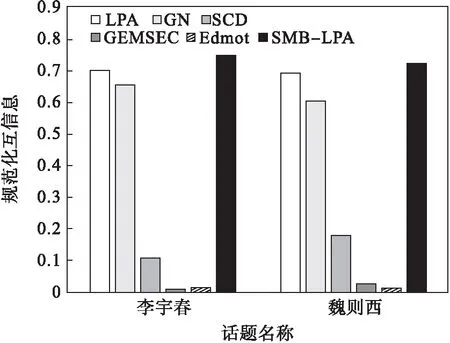
图9 规范化互信息值比较
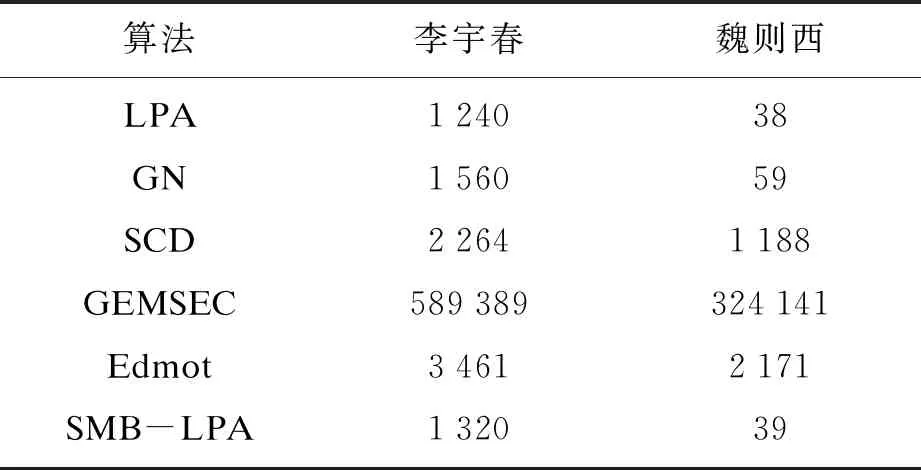
表5 运行时间比较
4 结 语
本文针对新浪微博平台构建情感社区检测框架,融合微博情感表情建立情感词典,并基于朴素贝叶斯算法提出SL-SE-NB分类模型计算文本情感倾向;为更准确地挖掘出用户主题,加入了超话题的概念,提出一种基于LDA话题模型的用户-超话题-关键词UTK模型;在LPA基础上加入话题概念,并抽取带有情感倾向的用户作为种子集进行标签传递,提出SMB-LPA算法以检测情感社区;最后通过实验验证了本文算法在召回率、模块度值、F1值、规范化信息等指标优于其他算法.
