基于交互特征表示的评价对象抽取模型
2021-01-15曾碧卿韩旭丽
曾碧卿 曾 锋 韩旭丽 商 齐
1(华南师范大学软件学院 广东佛山 528225)
2(华南师范大学计算机学院 广州 510631)(zengbiqing0528@163.com)
对象级情感分析是一种细粒度的情感分析,主要关注点是确定人们对评论文本中特定对象(方面、属性)的情感态度和情感极性[1],近年来引起较多研究人员的广泛关注.对象级情感分析的关键任务是:意见词抽取、评价对象抽取和对象级情感分类.评价对象抽取在一些文献上称为目标抽取或者方面词抽取.例如在评论文本“这台手机的屏幕质量很好,但是电池寿命比较短.”中,“屏幕质量”和“电池寿命”是对象,“很好”和“比较短”是意见词.意见词抽取的目的是识别“很好”和“比较短”2个意见词;评价对象抽取的目的是识别评论文本中的“屏幕质量”和“电池寿命”2个对象;对象级情感分类的目的是判断“屏幕质量”和“电池寿命”的情感极性.本文主要关注点是评价对象抽取,评价对象抽取是对象级情感分类的基础,评价对象抽取质量的好坏直接影响对象级情感分类的效果.
评价对象抽取任务划分为分类问题和序列标记问题,本文将评价对象抽取当作是一个序列标记问题.评价对象抽取任务采用的模型如条件随机场(conditional random field, CRF)、长短期记忆神经网络[2](long short-term memory network, LSTM)、卷积神经网络[3](convolutional neural network, CNN)等,这些模型结合手工特征组成复杂的模型,性能上会有较大的提升.Jebbara等人[4]指出在评价对象抽取任务中,一个特别的挑战是评论文本质量低,文本中包含了拼写错误的单词、新词以及罕见的单词等,对评价对象抽取任务带来不利的影响.为了克服评论文本质量低的问题,Jebbara采用字符级嵌入来捕获常规词嵌入不具备的与对象提取相关的字符级信息.另外,CRF,LSTM,CNN在不借助手工特征的情况下,模型特征学习能力是有限的,不能学习深层次的特征,因此难于取得具有竞争力的性能.手工特征的获取需要耗费大量的人力和时间.因此,本文提出基于交互特征表示的评价对象抽取模型(aspect extraction model based on interactive feature representation, AEMIFR).
为了解决评论文本低质量的问题,AEMIFR模型借鉴Jebbara在评价对象抽取任务中的做法,采用字符级嵌入来捕获常规词嵌入所缺乏的字符形态特征,并寻找字符与词语之间的内在联系.字符级嵌入通过捕获字符相关的信息辅助评论文本中的评价对象抽取,以及能较好地处理错词、新词和罕见的词.为了在不借助手工特征的情况下,提高模型学习特征表示的能力,AEMIFR模型利用卷积神经网络和双向循环神经网络分别学习词嵌入信息和字符级嵌入信息,得到2种不同的特征表示.在不借助手工特征的情况下,提高了模型的性能并学习到更多的特征表示.卷积神经网络通过控制卷积核的大小来控制信息流的大小,获取评论文本的局部特征表示.双向循环神经网络通过记忆功能获取评论文本的上下文依赖特征表示.本文将局部特征表示和上下文依赖特征表示进行交互结合,探究交互机制对实验效果的影响.
本文主要贡献总结为3个方面:
1) 采用单词级嵌入和字符级嵌入作为模型的输入,模型可以学习单词层面的语义特征、字符形态特征以及字符与词语之间的内在联系,并增强模型的特征输入.
2) 利用卷积神经网络学习局部特征表示与双向循环神经网络学习上下文特征表示,将局部特征表示和上下文特征表示进行结合.在不借助手工特征的情况下,通过2种特征表示之间的交互关系,增强模型特征表示的学习能力.
3) 与借助手工特征的模型以及多任务模型相比,AEMIFR模型学习深层次特征表示的能力更强,在多个数据集上进行验证,实验效果具有不同程度的提升.
1 相关工作
评价对象抽取可以分为无监督学习的方法和有监督学习的方法,有监督学习的方法总体上比无监督学习的方法的效果好.无监督学习的方法包括规则匹配[5-6]、句法关系提取[7]等.这些无监督学习的方法需要进行手工特征的提取,特征提取耗费大量的时间和人力,实验效果并非理想.
有监督学习的方法将评价对象抽取任务当作序列标记问题,常采用隐马尔可夫模型[8](hidden Markov model, HMM)和条件随机场[9](CRF),这2种方法是基于统计学习的序列标记问题的经典方法.近年来,随着深度学习在自然语言处理领域的发展,深度学习也被成功应用在评价对象抽取任务中.Xu等人[10]提出基于双嵌入的卷积神经网络模型,将通用的词嵌入和领域词嵌入输入卷积神经网络中进行对象提取,并取得了较好的效果.Luo等人[11]和Guo等人[12]将双向的循环神经网络与CRF结合,借助句法依赖信息进行评价对象抽取.Li等人[13]结合词性信息和字典,提出基于字符级的双向循环神经网络条件随机场模型,该模型利用字符的相关信息增强模型的性能.此外,注意力机制广泛应用在评价对象抽取任务中,Giannakopoulos等人[14]在评论文本中利用注意力机制选择具有实际观点的句子,从而提取无噪音的句子构造新的数据集,并证明在评价对象抽取任务中构建新的数据集时,句子选择的重要性.Li等人[15]认为循环神经网络虽然具有记忆功能,但是还没有机制来学习不同时刻预测之间的关系,因此他提出一种历史注意力机制去捕获历史预测的评价对象与当前预测评价对象之间的关系,进行评价对象抽取任务的研究.

Fig. 2 AEMIFR model
上述研究只关注评价对象抽取任务,而多任务学习还关注评价对象抽取以外的任务.因此,多任务学习模型也被用于评价对象抽取任务.Wang等人[16]提出了耦合多层注意力多任务学习模型,同时进行评价对象和意见词的抽取,模型的一个注意力层用来抽取评价对象,另外一个注意力层用来抽取意见词.通过交互式地学习评价对象和意见词之间的双向传播信息,模型可以进一步挖掘评价对象和意见词之间的相互关系.Li等人[17]提出一种结合情感分类和意见词抽取的多任务评价对象抽取模型,该模型利用2个LSTM神经网络学习评价对象和意见词之间的交互作用以及关系,为了确保评价对象来自带有情感极性的句子,模型使用另外一个LSTM对具有情感的句子进行分类,以更准确地提取评价对象.Yu等人[18]提出一个多任务学习框架模型,隐式地捕获评价对象抽取和意见词抽取之间的关系,然后提出一种全局推理的方法,该方法显式地建模评价对象抽取和意见词抽取2个任务之间的语法约束,并揭示它们之间的内外关系,寻求2个任务之间最有效的方法.Nguyen等人[19]将评价对象抽取和对象级情感分类2个问题进行结合,重新定义为信息抽取的任务,并仔细设计了标签集合,使评价对象抽取和对象情感分类的标签能够包含在同一个标签序列中,从而使一个模型可以同时进行2个任务.
2 评价对象抽取模型
本文将评价对象抽取任务视为序列标记的问题,采用IOB[20]的方法进行标签标注.根据IOB方法,评价对象抽取任务中评论文本包含B-A,I-A,O这3个标签,分别代表对象的首词、对象的非首词、其他单词或者符号,如图1所示:

Fig. 1 Label example
图2为本文提出的AEMIFR模型,该模型包含嵌入层(embedding)、表示编码层(representation encoder)和条件随机场层(CRF).词嵌入将单词嵌入和字符级嵌入进行结合,捕获单词的语义特征、字符的形态特征以及字符与词语之间的内在联系.表示编码层由卷积神经网络和双向循环神经网络学习不同的特征表示,卷积神经网络通过卷积层学习评论文本的局部特征表示;双向循环神经网络具有记忆功能学习评论文本的上下文依赖特征表示.将局部特征表示和上下文依赖特征表示结合,然后输入到条件随机场层,进行标签序列的预测.
2.1 词嵌入层
假设单词序列为(w1,w2,…,wn),单词的字符序列为(c1,c2,…,cm),标签序列为[B-A,I-A,O].单词序列映射成词嵌入矩阵Ew∈Rdw×|Vw|,字符序列映射成字符嵌入矩阵Ec∈Rdc×|Vc|,其中dw和dc分别为词嵌入矩阵和字符级嵌入矩阵的维度,Vw和Vc分别为单词词典的大小和字符词典的大小.
嵌入层将单词嵌入和字符表示进行拼接,字符表示是由字符级嵌入输入双向循环神经网络中学习得到的,通过双向循环神经网络的记忆功能,捕获字符的形态特征以及字符与词语之间的内在联系.这个过程的网络结构如图3所示.首先将字符级嵌入输入到双向长短期记忆网络(BiLSTM)中,计算过程为
xm=Eccm,
(1)
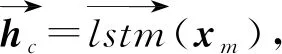
(2)

(3)

(4)

xn=Ewwn,
(5)
ecw=Cr⊕xn.
(6)
ecw是嵌入层最终的输出,嵌入层将词向量和字符表示进行拼接,能够获取单词的语义特征、字符的形态特征以及字符与词语之间的内在联系,使输入模型的特征更加充足.

Fig. 3 Network structure of character representation
2.2 表示编码层
表示编码层由3个不同卷积核的卷积神经网络和双向循环神经网络组成,不同卷积核的卷积神经网络获取评论文本的不同局部特征表示,经过卷积操作后输入最大池化层进行池化操作,将3个卷积操作得到的输出结果进行拼接,计算为
xf=cnnf(ecw),
(7)
poolf=max(xf),
(8)
xcw=pool3+pool4+pool5.
(9)
cnnf代表卷积操作,其中f代表卷积核的大小,卷积核的大小分别为3,4,5;xcw表示3个卷积操作结果的拼接.将嵌入层输出的结果输入双向循环神经网络中,获取评论文本的上下文依赖特征,计算过程为

(10)
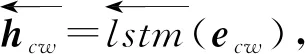
(11)

(12)

Zt=Relu(xcw⊙hcw),
(13)
其中,⊙是点乘(dot product)操作符号,Relu为激活函数.交互机制捕获局部特征表示和上下文依赖特征表示之间的交互关系,得到2种特征表示之间的重要联系.经过表示编码层编码,在不需要手工特征的情况下获取重要的特征表示.
2.3 条件随机场
CRF相对于传统的交叉熵损失模型,在序列标记问题中具有较好的表现.将表示编码层的结果输入到CRF层进行预测,得到预测的序列标签.假设输入的序列为x=(x1,x2,…,xT),标签序列为y=(y1,y2,…,yT),则标签预测得分计算为
(14)
其中,A是转移分数矩阵,Ai,j表示从标签i转移到标签j的得分,Z表示编码层的输出,Zt,i代表第i个标签的分数.在训练过程中,最小化标签序列的负对数似然函数,计算为

(15)

(16)
其中,Yx是包含所有序列标签的集合,p(y|x)表示在给定x的条件下y标签的概率,最后通过维特比算法(Viterbi algorithm)预测最佳标签序列.
3 实 验
3.1 数据与实验参数设置
模型使用SemEval数据集验证模型的性能,数据集统计如表1所示.L-14和R-14是SemEval 2014①的数据集,R-15和R-16分别是SemEval 2015②和SemEval 2016③的数据集.L-14数据集是关于电子产品的评论文本,R-14,R-15,R-16数据集是关于餐厅的评论文本.#Sentences表示评论文本的数量,#Aspects表示评论文本中对象的数量.
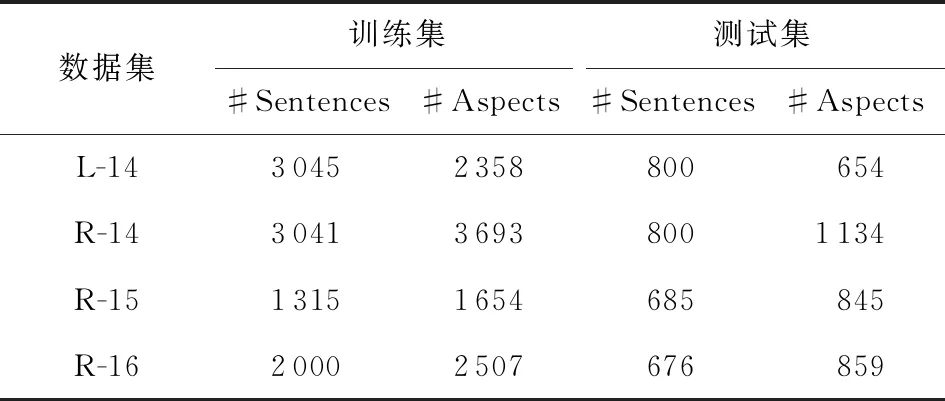
Table 1 Data Set Statistics
模型训练采用Adam[21]优化器进行优化,采用Glove训练好的词向量初始化词嵌入,采用Dropout防止过拟合,其值设置为0.5.随机初始化字符级嵌入,词嵌入和字符级嵌入的维度大小分别设置为300和100.卷积神经网络的卷积核设置为[3,4,5],嵌入层的LSTM隐藏单元数设置为100,表示编码层的LSTM隐藏单元数设置为300,学习率设置为0.001.
3.2 对比模型
对比模型有9组:
1) ITOE[4]
将单词的字符结构信息整合到模型上,探究字符级词嵌入对实验性能的影响.
2) WDEmb[22]
利用上下文信息和句法依赖信息训练词嵌入和句法依赖嵌入,将词嵌入和句法嵌入输入CRF中进行评价对象抽取.
3) RNCRF-O,RNCRF-F[23]
将循环神经网络与条件随机场结合作为统一的框架进行评价对象抽取和意见词抽取,RNCRF可以添加手工特征增强模型.RNCRF-O使用意见词标签来训练模型,RNCRF-F在RNCRF-O的基础上添加了其他的手工特征.
4) DTBCSNN+F[24]
利用基于依赖树的堆叠卷积神经网络捕获句法特征,不需要其他的手工特征.另外,也可以灵活地结合其他的语言学特征增强模型.
5) MIN[17]
一种基于LSTM的多任务学习模型,通过2个LSTM学习对象和意见词抽取任务之间的关系,同时解决评价对象抽取和意见词抽取2个任务.
6) CMLA[16],MTCA[25]
CMLA是多层注意力模型,在不需要任何其他语言资源预处理的情况下,通过多层注意力进一步挖掘对象和意见词之间的间接关系,从而更准确地提取特征信息.MTCA是一种端到端的多任务注意力模型,针对在特定的类别条件下的评价对象抽取和意见词抽取,探索不同任务之间的共性和关系,以解决数据稀疏性问题.
7) LSTM+CRF,BiLSTM+CRF[26]
该模型用于解决词性标注、命名体识别等序列标注问题,本文将此模型作为对比的基线模型.
8) BiLSTM+CNN[27]
与LSTM+CRF,BiLSTM+CRF相同,都是解决序列标注问题,该模型将字符嵌入输入卷积神经网络中,提升了词性标注和命名体识别的效果.本文将该模型作为对比的基线模型.
9) BiDTreeCRF[11]
BiDTreeCRF模型的关键思想是在句法依赖树中通过双向传播来增强树结构表示,将句法依赖信息和序列信息输入双向循环神经网络中进行学习,最终输入CRF中进行评价对象抽取.BiDTreeCRF#1表示在神经网络共享全部权值,BiDTreeCRF#2表示共享部分权值,BiDTreeCRF#3表示不共享任何权值.
3.3 实验结果分析
本文使用F1值作为评判标准,实验结果如表2所示.模型IOTE只将字符嵌入和词嵌入融合输入到模型中,没有借助手工特征,效果比较差.模型WDEmb,RNCRF-O,RNCRF-F,DTBCSNN+F都添加手工特征进行增强模型,F1值都比模型AEMIFR小.模型LSTM+CRF,BiLSTM+CRF,BiLSTM+CNN在解决词性标注、命名体识别等序列问题上具有竞争优势,但在评价对象抽取任务中效果却比模型AEMIFR差.模型MIN,CMLA,MTCA是多任务学习模型,模型使用更多的标签信息和任务之间的关联信息,作为单任务学习模型AEMIFR的效果仍优于多任务学习模型MIN,CMLA,MTCA.说明本文提出的模型在不需要任何手工特征的情况下,学习到更重要的特征,以及学习的特征质量更高.
除在R-14数据集上的效果比模型BiDTreeCRF#2和模型CMLA略差,模型AEMIFR在L-14,R-15,R-16数据集上的效果最好.在数据集L-14,R-14,R-15,R-16上,模型AEMIFR的F1值比模型BiDTreeCRF#1分别提升了0.41%,0.13%,4.3%,1.03%.在数据集L-14,R-15,R-16上,模型AEMIFR的F1值比模型BiDTreeCRF#2分别提升了0.55%,5.13%,0.76%.在数据集L-14,R-14,R-15,R-16上,模型AEMIFR的F1值比模型BiDTreeCRF#3分别提升了0.20%,0.38%,2.61%,0.28%.因此,在不借助手工特征的情况下,模型AEMIFR在不同的数据集上都比其他的基线模型具有竞争优势.
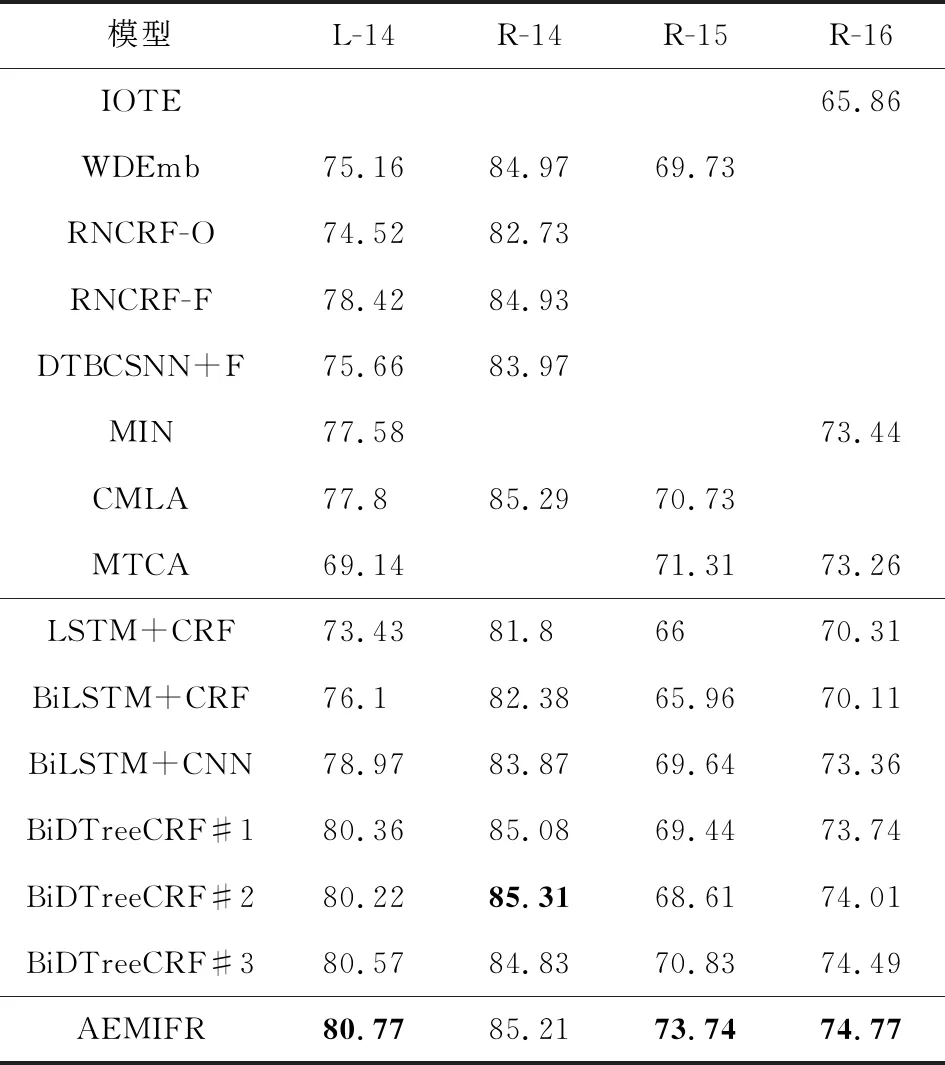
Table 2 The Experimental Result F1
综上分析,本文提出的模型在不借助任何手工特征的情况下,通过卷积神经网络学习局部特征表示和双向循环神经网络学习上下文依赖特征表示,将特征表示进行结合,增强了模型的特征学习表示,并通过交互机制学习局部特征和上下文依赖特征之间的交互关系,从而提高模型的性能.
3.4 交互机制的影响
为了探究交互机制对模型的影响,本文设计了3组实验.
1) AEMIFR-CNN
只有AEMIFR模型的左侧部分,即将嵌入层的输出只输入不同卷积核的卷积神经网络中.
2) AEMIFR-BiLSTM
只有AEMIFR模型的右侧部分,即将嵌入层的输出只输入双向循环神经网络中.
3) AEMIFR-C
将不同卷积核的卷积神经网络学习的局部特征和双向循环神经网络学习的上下文依赖特征进行直接拼接.
交互机制对模型影响的实验结果如表3所示.模型AEMIFR-C在L-14,R-14,R-15,R-16数据集上的实验效果比AEMIFR-CNN,AEMIFR-BiLSTM的好,说明将不同卷积核的卷积神经网络学习的局部特征表示和双向循环神经网络学习的上下文依赖特征表示进行直接拼接,可以增强模型学习特征的能力.
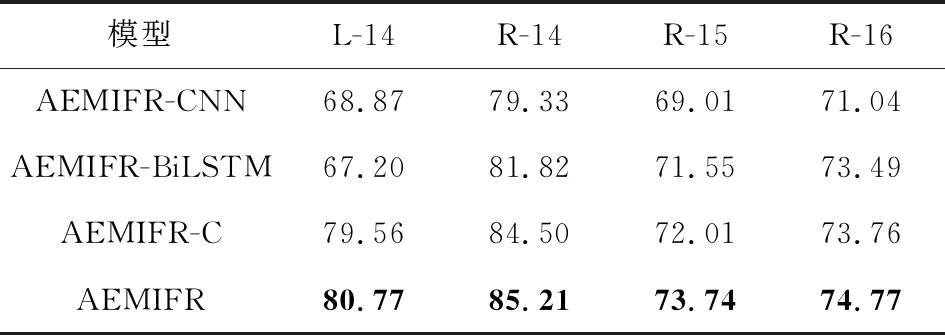
Table 3 Experimental Results of Interaction Mechanisms on Models
模型AEMIFR在L-14,R-14,R-15,R-16数据集上的F1值比模型AEMIFR-C分别提升了1.21%,0.71%,1.73%,1.01%,表明本文的交互机制比直接拼接能够学习更准确和更高质量的特征信息,通过交互机制将卷积神经网络学习的局部特征表示与双向循环神经网络学习的上下文依赖特征表示进行结合,能够学习局部特征表示和上下文依赖特征表示之间的交互关系,捕获特征之间的重要联系.
3.5 字符级嵌入的影响
为了验证字符级嵌入对模型的影响,本文设计了2组实验,分别为是否具有字符级嵌入作为模型输入的对比实验,以及字符级嵌入维度的对比实验.是否具有字符级嵌入作为模型输入的实验结果如表4所示.
如表4所示,以字符级嵌入和词嵌入作为输入的AEMIFR-CNN,AEMIFR-BiLSTM,AEMIFR-C,AEMIFR模型分别比只有以词嵌入作为输入的AEMIFR-CNN-N,AEMIFR-BiLSTM-N,AEMIFR-C-N,AEMIFR-N模型的F1值大.模型AEMIFR-C在数据集L-14,R-14,R-15,R-16上的效果分别比模型AEMIFR-C-N提升了1.92%,1.10%,5.05%,0.30%,模型AEMIFR在数据集L-14,R-14,R-15,R-16上的效果分别比模型AEMIFR-N提升了1.51%,1.34%,5.01%,2.11%.通过实验对比,说明字符级嵌入提供了词嵌入不具备的字符级形态特征以及字符与词语之间的内在联系,而这些信息对模型抽取评价对象的能力具有积极的影响.

Table 4 Experimental Results of Interaction Mechanisms on Models

Fig. 4 Effect of character dimension on AEMIFR-C model
选取了50,100,150,200维度的字符进行字符维度对模型影响的实验,图4是字符维度对模型AEMIFR-C的F1值的影响折线图,图5是字符维度对模型AEMIFR的F1值的影响折线图.从图4中看出,L-14, R-14和R-15数据集在字符维度150时F1值达到最大值,R-16数据集在字符维度为150时达到次最大值,说明字符维度为150是模型AEMIFR-C最适合的字符维度.从图5可知,4个数据集在字符维度为100时,F1值基本是最大的.在图4和图5中,数据集L-14和R-14的折线图变化波动较小,数据集R-15和R-16的折线图变化波动较大,可能的原因是数据集R-15和R-16的数据相对小.由于数据的稀疏性,模型在学习特征过程中学习不稳定,难以学习更重要的特征表示.

Fig. 5 Effect of character dimension on AEMIFR model
4 总 结
针对数据规模较小、特征信息不充分等问题,本文提出了基于交互特征表示的评价对象抽取模型,模型利用卷积神经网络获取局部特征表示和利用双向循环神经网络获取上下文特征表示,结合局部特征表示和上下文特征表示之间的交互关系,以获取2种特征表示的重要联系,增强2种特征之间的相似特征的重要性,减少无用特征对模型的消极影响.利用词嵌入和字符级嵌入分别捕获单词的语义特征、字符的形态特征以及字符与词语之间的内在联系,对模型性能的提升具有积极的影响.实验结果表明,在不借助任何手工特征的情况下,AEMIFR模型能够借助交互机制学习特征之间的重要交互关系,以及学习更高质量的特征表示,因此本文的AEMIFR模型更具有竞争力.
虽然本文提出的AEMIFR模型在4个数据集上的实验结果具有提升,但仍可以借助手工特征进一步提升模型的性能.另外,由于考虑到评价对象抽取是对象级情感分析的关键任务,评价对象抽取的质量会直接影响到对象级情感分类的准确性,因此,下一步考虑将评价对象抽取和对象级情感分类设计为多任务学习,针对评价对象抽取任务和对象级情感分类任务进行统一建模,减少评价对象抽取过程中的错误传播给对象级情感分类任务.
