基于已有实例的Linux驱动程序前向移植接口补丁推荐
2021-01-15贺也平马恒太芮建武
李 斌 贺也平,3 马恒太 芮建武
1(中国科学院大学 北京 100049)
2(中国科学院软件研究所基础软件国家工程研究中心 北京 100190)
3(计算机科学国家重点实验室(中国科学院软件研究所) 北京 100190)(libin@iscas.ac.cn)
当前操作系统开发中最大的问题之一是设备驱动程序与对应操作系统版本需要保持同步演进[1].国产操作系统厂商都在开源软件的基础上力求提高自主可控性,以Linux为代表的开源操作系统,在我国国产操作系统产品研制中起到了不可替代的作用.Linux内核版本升级非常的频繁,这些升级提升了内核性能、增强了安全性、增加了新特性以及修复了内核漏洞等,带来了很多收益.然而内核版本升级后,由于内核版本的变化引入了一些内核接口服务定义的变更,使得驱动程序代码中对应的内核接口服务调用不再适应更新后的内核接口服务定义,导致驱动程序在新的内核环境中可能出错或者不可用.为了适配频繁变化的内核版本并维持已有设备在新内核环境中的可用性,开发者需要对驱动程序进行前向移植.
内核版本变更对驱动程序带来的关联影响程度和影响范围都很大,针对内核版本变更引入的这种驱动程序接口服务调用不一致性问题应该引起更多关注.Padioleau等人[2]通过实证分析发现,由于Linux内核版本的变更使得对应驱动程序在移植中所需的适配性修改代码量高达35%以上.Padioleau等人[3]还进行了影响范围分析,该研究发现内核版本中引入的单一变更可能会影响驱动程序中分布在不同文件中的数百个代码调用点.另外,当前Linux内核版本更新速度越来越快,内核版本研发和发布周期越来越短.虽然少数集成在内核主线版本中的驱动程序会随内核升级而得到同步更新,但是大量的其他各种类型设备驱动程序需要投入额外成本进行持续的适配性修改,而且维护这些驱动程序和内核版本的一致性更加紧迫.然而针对上述不一致性问题,开发者通常手工进行适配性修改来完成驱动移植工作,其工作量繁重且容易引入新的错误,手工移植具有一定技术门槛且移植效率较低.其中人工分析接口服务相关的变更信息和进一步的手工构造适配性补丁更是驱动移植开发者面临的主要挑战之一.
针对上述问题,研究者们在驱动移植中间库辅助适配[4-5]和驱动移植辅助信息[6-7]等方面开展了研究,以便辅助开发者降低移植负担.其中,Rodriguez等人[5]发现待移植驱动针对兼容库所需的一致性修改是系统化的并且有一部分修改方式具有相似性,提出手工编写重写规则并利用Coccinelle的匹配及转换技术辅助开发者移植驱动.Thung等人[6]提出遍历分析引入错误提交点的方法缩小了辅助信息的检索范围,通过推荐示例语句的变化差异辅助提高了驱动移植的效率.Lawall等人[7]发现驱动移植中的1个错误问题所需的辅助信息可能来自多条历史提交数据,从而结合编译信息和出错源码信息丰富了检索关键词,相比git查询和Google搜索提高了辅助示例信息的检索精度和效率.上述已有研究提高了辅助信息本身的检索精度和效率,一定程度上减轻了驱动移植开发者的负担.但是上述辅助方法并没有对构造适配性补丁所需的细节信息进行深入分析,因此还需要开发者进一步分析辅助信息包含的内容和出错代码并人工构造补丁,辅助能力依然存在限制.
相比辅助信息,如果有高质量的适配性补丁辅助驱动移植开发者,辅助效果会更好.Tao等人[8]通过实证研究指出,当开发者有高质量的补丁做辅助的时候,错误修复的正确率会大幅提升.和上述已有研究的辅助信息不同,本文的主要研究目标是进行驱动移植场景中高质量的补丁推荐.更具体地说,本文主要聚焦在驱动移植场景中接口错误的适配性补丁推荐(由于宏替换和接口性质相似,本文也将其归为接口错误).从开源Linux开发情况来看,接口错误和条件错误在所有Linux程序出错类型中占比最高[9].因此,辅助提升驱动程序移植中接口错误的修复效率,对降低驱动移植开发者的负担具有重要的意义.
一般错误的补丁自动生成技术和驱动移植补丁推荐存在区别和联系,除了错误定位和补丁质量判定存在差异,驱动移植接口补丁推荐问题和一般错误补丁自动生成技术中的候选补丁生成问题类似,两者都需要将错误语句或者代码片段通过某种形式的修改或者转换形成正确的代码[6].一般错误的补丁生成技术中如何提高候选补丁的质量是关键研究问题之一[10-14],其通过选择针对性模板和推测合适的补丁内容等素材提高候选补丁的质量[15].其中选择模板的已有研究通过频度选用模板[16]并没有考虑待修复错误问题的特点,考虑上下文信息选用模板[17]相当于把错误问题的特点简化为上下文的特点,而充分考虑错误问题的特点才能获取针对性的素材.本文认为分析错误本身的特点是选择针对性素材的另一个可能的突破口.
本文利用和出错接口问题相似的历史开发信息分析驱动移植接口错误本身的特点,根据错误问题特点区分针对性的细粒度素材生成待推荐补丁.观察发现,依赖相同内核接口服务的多个不同驱动程序之间存在相同或相似的内核接口调用,如果内核版本升级一段时间之后,其他驱动的开发历史中可能存在和出错接口相同或相似的接口复用及变更信息,本文将这些变更代码称为已有实例.即已有实例中包含复用接口随内核定义变更而演化的接口使用信息,不同驱动程序的开发历史中针对同一接口的代码复用和适配性变更作为一组已有实例.因此,本文通过寻找和出错接口问题相似的一组已有实例分析错误问题本身的特点,即出错接口语句和相似已有实例的共性揭示了错误本身的特点,借助已有实例提取和分析针对性补丁素材并生成高质量待推荐补丁.
然而相比人工对这些实例代码片段的分析和利用,工具直接利用这些已有实例生成候选补丁并不简单(第1节进一步详细地举例说明).进一步分析发现,由于内核接口定义变更的共性(变更方式由内核组统一维护)和驱动程序使用内核接口可能引入的多样性(例如驱动在接口调用中使用私有变量作为实参),一组已有实例中包含的内容呈现共性和个性2种特征.因此,本文将细粒度补丁素材拆分为接口修改方式(接口定义变更的共性,类似模板)和修改内容(多样性)2类递进素材作为入手点.但是由于接口修改方式隐含在信息量庞大、提交风格存在差异的历史开发信息之中,而接口修改内容的多样性又使其难以统一枚举,因此准确地获取2类素材并不容易.为了获取针对性的接口修改方式,本文面临缩小搜索空间降噪、过滤干扰获取有效已有实例、提取针对性修改方式3个技术问题.本文首先通过分界点计算确定一个较小的有效历史开发信息搜索区间,然后在有效区间中获得一组候选已有实例并利用相似度计算对其排序确定有效实例,最后基于抽象语法树(abstract syntax tree, AST)的细粒度差异比较技术[18]提取有效实例隐含的修改方式,再通过计算修改方式的频度提高针对性.针对接口修改内容的多样性困难,本文提出了一种基于已有实例修改内容字段差异特征的分类算法,通过区分共性和个性2类修改内容,然后根据修改内容的特点再分别从历史开发信息和出错点源码上下文2种不同数据源提取.区分类型之后共性内容刻画的共享名称提取相对简单,而针对个性化修改内容刻画的私有名称,本文具体结合局部性原则和命名规则相似计算等技术从出错点上文源码中提取.最后利用上述方法获取的细粒度素材,采用编辑脚本技术[19]生成待推荐补丁并自然利用素材的优先级对补丁进行排序.
本文主要贡献包括:
1) 针对驱动前向移植中,驱动程序接口调用和内核接口定义不相适配的错误问题,提出基于历史开发信息提取细粒度素材合成候选补丁并进行推荐的方法.根据文献调研分析,这是一种专门针对驱动前向移植中接口错误而设计的补丁推荐方法.
2) 面对提取有效接口修改方式的困难,本文结合驱动前向移植中内核接口复用的问题特点,提出从出错接口问题相似的历史解决方案(已有实例)中提取针对性的修改方式,即通过已有实例的媒介作用分析错误特点,结合分界点识别、相似度计算、频度计算等技术和启发式规则提升接口修改方式的有效性.
3) 面对修改内容的多样性困难,本文提出了一种基于已有实例差异特征的分类方法,通过区分共性和个性内容再从不同特点的数据源分类提取;其中针对不易提取的个性化修改内容,本文结合局部性原则和命名规则相似计算等技术从出错点上文源码提取,实验显示本文的方法能够推荐多种不同类型驱动程序中7类接口调用错误所需的补丁,有效补丁占比约67.4%.
1 动 机
在驱动前向移植场景中,本文定义内核版本K1的新版本为K2,驱动D1在内核K1上可正常使用,开发者希望将D1手工移植到K2上并达到可以正常使用的目的.D1中调用的内核接口服务由于在新内核版本K2环境下“定义-使用”链可能被打破,导致D1驱动在该环境下出错.开发者希望引入一系列的补丁P修复D1中的错误后生成新的驱动D2,使得驱动D2在内核K2上正常运行.
本文的研究聚焦在驱动前向移植过程中发生的接口错误.图1是实际网卡驱动程序e1000移植中根据编译日志提取的接口错误,在这个实例中内核K1为Linux-3.5,内核K2为Linux-4.1,现在将驱动D1为e1000移植到内核K2版本上.-语句表示将要被替换的出错语句,其中1个出错接口__vlan_hwaccel_put_tag为行6语句,该接口将vlan报文信息记录到skb中供协议栈使用;+语句表示将要更新的补丁语句,本文期望推荐行7的补丁语句给开发者修复该错误.
在这个示例中,我们发现内核升级一段时间之后,由于内核接口的复用其他驱动程序开发历史中存在的和D1驱动出错接口__vlan_hwaccel_put_tag相同的接口复用及接口变更代码片段信息,包含这些接口复用和变更的代码片段本文中称之为对应接口的已有实例.针对图1示例中的出错接口,我们通过人工分析内核版本K1到K2区间中其他驱动的历史开发信息,获得了一系列和出错接口相关的已有实例.其中2个已有实例为飞思卡尔和IBM的网卡驱动程序开发历史中的代码片段,图2所示包含了__vlan_hwaccel_put_tag接口分别在上述2个驱动程序历史开发信息中的接口使用和变更情况.

Fig.2 Existing instances in git repository of driver development history

Fig. 3 Structure of patch recommendation for driver porting interface error
进一步分析图2的已有实例,我们发现针对出错接口的一组已有实例语句之间存在共性的同时也存在差异性.更具体地说,由于内核接口的定义和变更由内核开发组统一维护,因此一组已有实例之间语句的共性主要体现在接口的修改方式.例如图2实例的修改方式都是“增加出错接口的第2个参数”.而由于驱动调用接口时调用语句可能引入差异性,导致修改内容可能呈现多样性.例如图2实例新的接口中第3个参数名称分别采用vid,fcb→vlctl,cqe→vlan_tag不同的命名方式,而增加的第2个参数htons(ETH_P_8021Q)在该示例中虽然相同,但在其他情况下也可能呈现多样性.同时,接口__vlan_hwaccel_put_tag的调用也可能存在于不同形式的语句中,例如条件、循环等不同情形或者一些复杂的语句形式中.因此,一方面,根据本文的观察和分析,在历史开发信息中存在类似上述示例中的已有实例,可以通过有效的方法提取并用于解决接口错误的补丁推荐问题;另一方面,由于调用接口所在的语句形式、参数名称差异、上下文环境等可能存在差别,接口修改内容可能存在多样性,因此通过简单的匹配无法获得有效的已有实例,更无法通过匹配等简单操作获得补丁.除了以上差别,由于庞大的历史开发信息数量和提交风格等其他干扰性因素的存在,识别和提取有效的已有实例以及细粒度素材合成待推荐的高质量候选补丁并不容易.
2 方法概述
首先介绍方法的整体结构,如图3所示,本文的方法输入包括旧版本驱动源码(待移植驱动)、新旧版本内核源码(新版本内核为前向移植的目标内核版本)、新旧版本内核之间的历史开发信息(git仓库),输出内容是旧版本驱动移植到新版本内核过程中,针对驱动程序代码中接口调用错误推荐的候选补丁列表.本文针对驱动移植中发生的一系列出错接口,采用迭代方式逐个生成候选补丁列表,主要包括已有实例抽取和待推荐补丁生成2部分,生成的补丁经过排序推荐给驱动移植开发者进行补丁质量判定.本文借助已有实例提取针对性的接口修改方式和修改内容的细粒度素材合成待推荐补丁.其中,接口修改方式刻画共性特征提供修改方式的素材,接口修改内容刻画多样性特征提供修改细节的素材.例如,针对驱动前向移植中的某个出错接口,本文需要确定该接口修改方式应该采用修改接口名称,还是增加接口参数或者修改接口类型等修改方式素材,还需要分析该接口修改内容的名称应该使用哪个具体的新接口名称、增加的参数应该使用哪个具体参数名称或者接口类型需要替换为哪个具体类型等细节名称素材.
然而,准确地提取针对性的接口修改方式和修改内容2类细粒度素材并不简单.针对某个出错接口,即使从庞大的历史开发信息代码变更片段中找到了有效的接口修改方式,由于修改内容的多样性使得该类细节素材依然难于统一提取.进一步来说,各个驱动程序在具体调用内核接口时可能采用各不相同的命名方式或者编码风格.例如,不同的驱动程序调用某个相同内核接口时,由于内核版本升级该接口定义的变更要求具体调用时增加某个参数.然而该参数名称可能来自于各个驱动项目的私有局部变量,或者存在驱动程序各自定义的全局变量、常量作为实参等情形.因此,这种修改内容的多样性情形往往难于统一提取和枚举.
为了获取针对性的接口修改方式,本文提出从出错接口问题相似的历史解决方案(已有实例)中提取针对性的修改方式素材.借助和出错接口问题相同或者相似的一组已有实例作为媒介,通过分析接口错误特点提升接口修改方式提取的针对性.利用上述思路提取针对性接口修改方式并不简单,存在3个技术问题:1)历史信息数量庞大且提交风格迥异,如何确定一个较小的有效区间减少检索结果的噪声;2)有效区间中依然存在大量不相关的干扰实例,如何从中获取针对出错接口的一组有效已有实例;3)有效已有实例中包含的接口修改方式可能依然存在差异性,如何从中提取有效的接口修改方式.为了解决上面3个技术问题,首先,受到已有研究[6]的启发,本文采用分界点拓展出1个包含有效已有实例的区间(3.1.1节).进一步来说,由于驱动调用内核接口而使得内核和驱动之间存在接口“定义-使用”链的依赖关系,而分界点提交的commit中接口定义变更打破了这种依赖,因此分界点之后驱动程序才会陆续提交对应的变更适配commit.本文将分界点commit临近的内核版本到待移植的目标内核版本作为有效区间,该区间描述了检索出错接口对应已有实例的窗口边界.其次,如何从有效区间对应的历史开发信息中获取有效已有实例.分析历史开发信息发现,由于相同接口及变更代码实现相同或相似的语义功能,来自不同驱动程序对同一内核接口复用的一组已有实例中其接口调用语句也呈现相似性特征:接口调用点具有使用形式和上下文结构的相似性.基于以上分析,本文将已有实例择优问题转化为排序问题.首先基于接口错误关键字等信息从有效区间提取一组已有实例候选集合(3.1.2节);然后利用相似度计算技术对其进行排序(3.1.3节);最后,针对某个出错接口问题对应的top-N已有实例,为了获得已有实例中2条语句内部隐含的变更方式,本文利用AST级别的细粒度差异比较技术比较2条语句的变化类型抽取接口修改方式,并结合top-N顺序、频度和驱动类型等多维信息计算权重对其进行排序确定有效接口修改方式(3.2.1节).
为了克服接口修改内容多样性的困难,本文采用更加细致的方式推测有效的修改内容.本文发现接口修改内容刻画的名称多样性特征可以进一步分为共性和个性2种类型,因此依据修改内容的名称特点分别提取是一种可能的提取思路.让我们进一步分析这个问题:1)共性修改内容更倾向于共享和全局性名称(例如全局接口名称),经常1次定义或者赋值后在多个驱动项目中共享使用,因此历史开发信息中往往包含各种共性修改内容;而个性化修改内容一般是局部和项目私有的成员名称(例如私有变量名称、私有参数名称等),往往由各个驱动程序定义并在出错点附近的源代码上文赋值或者初始化之后使用,呈现出定义和使用的局部性特点,因此个性修改内容更可能存在于出错驱动程序上下文源代码中.2)分析一系列出错接口对应的每组已有实例,发现其中的修改内容字段呈现如下趋势:个性化修改内容在出错接口对应的一组已有实例中接口修改内容字段各自不同的比例更高,而对于共性修改内容往往该字段相同的比例更高.因此,本文首先基于一组已有实例修改内容字段的差异特征对其进行分类,为了获得已有实例语句中修改内容刻画的名称差异,具体采用AST差异比较技术抽取2条语句修改内容字段的值并利用编辑距离比较名称差异;然后再根据分类情况分别从历史开发信息和驱动程序出错点源码上下文2种不同数据源提取修改内容(3.2.2节).区分类型之后共性内容刻画的共享名称提取相对简单,而针对个性化修改内容刻画的私有名称,本文具体结合局部性原则和命名规则相似计算等技术从出错点上文源码中提取.
基于以上步骤提取的细粒度素材列表,候选补丁生成和推荐(3.2.3节)首先结合上述细粒度素材给出补丁定义,然后依据定义生成期望的候选补丁并很自然地利用素材优先级对候选补丁进行排序和推荐.综上所述,本文的方法针对驱动前向移植中出错接口候选补丁生成问题,采用迭代方式逐个生成候选补丁列表,最后以推荐方式输出并通过人工判定补丁质量.
具体结合图1和图2示例进行说明,第1阶段已有实例提取中,首先通过提取编译日志中的错误分析出错接口名称和所在位置等信息.示例中__vlan_hwaccel_put_tag接口出错,具体的出错位置L是driversnetethernetintele1000e1000_main.c文件中的4012行.然后通过获取的接口名称关键字构造一组查询,再从编译遍历过程确定的有效区间r(r为集合R中某个出错接口对应的有效区间项)检索历史开发信息,接着利用启发式规则清洗数据之后形成已有实例候选集合S,最后对出错点语句和候选实例中的语句利用相似度计算获得top-N有效已有实例.示例__vlan_hwaccel_put_tag接口对应的top-N已有实例中,其中前2个实例为Freescale和IBM的网卡驱动程序开发历史中对该接口的使用和变更代码片段.第2阶段补丁推荐,首先对有效已有实例进行细粒度差异比较和分析提取生成候选补丁所需的素材列表.其中,通过频度计算等技术获得示例接口的top-1修改方式OP为对该接口“增加第2个参数”,根据本文给出的算法判定接口修改内容C即示例中增加的参数属于公有参数且提取的唯一修改内容为“htons(ETH_P_8021Q)”全局函数.最后使用上述素材列表,利用基于AST的编辑脚本技术合成top-1候选补丁并推荐给驱动移植开发者:将driversnetethernetintele1000e1000_main.c文件中的4012行的语句修改为“__vlan_hwaccel_put_tag(skb,htons(ETH_P_8021Q),vid);”.
3 基于已有实例的补丁推荐
为了更加规范地描述已有实例以及其中包含的相关变更操作,本文首先给出已有实例的定义,具体借助抽象语法树进行刻画.抽象语法树是一种源代码语法结构的统一抽象表示,本文将代码片段的抽象语法树看作1棵有序的树,每个节点代表程序语句中的1个元素.本文定义源代码语句中的某个元素为节点n,那么Value(n)表示节点n的值,Type(n)表示节点n的类型.例如,如果节点n表示示例1语句中的出错接口字段,那么Value(n)表示出错接口名称__vlan_hwaccel_put_tag,Type(n)表示该节点是函数类型.Parent(n)和Children(n)分别表示节点n的父节点和孩子节点,Index(n)表示节点n在其孩子列表中的索引号,Root(t)表示抽象语法树t的根节点.
基于以上描述,那么本文给出如下定义.
定义1.已有实例集合S.已有实例集合S={s1,s2,…,sm},则每个实例sk(1≤k≤m)仅包含1个语句对的迁移(-语句和+语句),迁移可能包含1个或多个修改操作(单个修改操作是对某个叶子节点的变更;本文将多个修改操作刻画为单个修改操作序列,结果是对1棵子树的变更),每个具体的修改操作来源于如下3种修改操作集合.
1)Add(n,n1,i).表示在节点n的孩子序列号为i的位置之后增加节点n1.
2)Replace(n,n1).表示使用节点n1替换节点n.
3)Delete(n,i).表示删除节点n的孩子序列号为i的叶子节点.
定义2.接口修改方式OP.OP定义为一个或一组抽象的修改操作,即表示为单个节点或者子树中的多个节点类型发生的变化.一种接口修改方式是一个节点类型或者一组节点类型的变化,每个变更操作为:
Add(Type(n),Type(n1),i).表示在节点类型为Type(n)的孩子序列号为i的位置之后增加节点类型Type(n1).
Replace(Type(n),Type(n1)).表示使用节点类型Type(n1)替换节点类型Type(n).
Delete(Type(n),i).表示删除节点类型Type(n)孩子序列号为i的叶子节点.
定义3.接口修改内容C.C定义为一种接口修改方式生效后引入的节点变化内容,即修改内容表示为变化节点的值.
如果修改操作为增加和替换操作,则C=Value(n1);如果修改操作为删除操作,则C=Value(Index(i)).
结合图1和图2中的示例对定义1~3进一步说明.来自Freescale和IBM网卡驱动开发历史的2个实例分别包含一组语句的迁移,迁移操作均为Add(n,n1,2),表示在n节点__vlan_hwaccel_put_tag的孩子序列号为2的位置增加n1子树htons(ETH_P_8021Q),n1子树包含4个元素的叶子节点.则接口__vlan_hwaccel_put_tag的修改方式OP为Add(Type(n),Type(n1),2),表示“在接口的第2个孩子位置增加参数”(n1子树变更序列中各叶子节点变更操作类型相同),刻画了图2已有实例中的接口修改方式.接口__vlan_hwaccel_put_tag的修改内容C为Value(n1)(由于n1子树变更序列中变更操作类型相同,变更值可以按变更操作序列顺序合并),表示待增加的参数为“htons(ETH_P_8021Q)”,刻画了图2已有实例中的接口修改内容.
3.1 有效已有实例提取
3.1.1 接口错误和有效区间识别
根据第2节所述,为了提升细粒度补丁素材的针对性,本文借助历史开发信息中的已有实例提取补丁素材.然而整个历史开发信息数量非常庞大,由于内核和驱动程序代码中的接口“定义-使用”的依赖关系,驱动程序移植问题中开发人员一般使用新旧版本内核区间对应的驱动程序开发历史分析辅助信息.然而内核和驱动开发历史信息更新频繁,上述区间对应的历史信息数量依然庞大,尤其驱动移植版本区间跨度较大时对应区间的历史信息数量更多,这种庞大的检索空间可能会对检索结果引入更多的噪声.因此,本文通过提取出错接口相关的信息用于构造检索关键词,同时确定一个较小的有效区间历史信息窗口用于限定搜索边界.
首先,本文需要确定出错接口相关的信息.由于内核和驱动程序之间存在接口的“定义-使用”依赖关系,而内核升级可能打破这种接口“定义-使用”链.这种打破接口“定义-使用”链的错误位置,编译器在语法检测阶段能够给出错误报告,其中大部分包含准确的出错位置行号信息.因此,本文采用编译的方式,在新版本内核环境中编译旧版本驱动程序并从编译错误日志中提取出错接口相关的信息.根据先验知识,通常接口相关的编译错误有3类报错字段,具体包括:excepted,implicit and undeclared,arguments.其中excepted通常是宏定义相关的错误(由于宏替换和接口性质相似,本文也将其归为接口错误);implicit and undeclared是接口名称相关错误,例如接口名称变化、接口类型变化、接口声明所在引用文件变化等;arguments通常和接口参数错误相关,例如参数增加、参数减少、参数类型改变等.每一类语法错误都具有较为丰富的信息,具体包括错误类型、出错接口所在源码文件路径信息、出错接口名称、出错接口所在源码文件的行号位置L等.需要特别说明的是,虽然编译过程已经可以获取3类接口错误,但这种错误类型粒度太粗,提示的修改方式对于生成待推荐补丁的针对性依然不够.本文使用编译日志中提取的丰富内容,通过检索获取的已有实例进一步提取细粒度的补丁素材.
然后,如何获得一个较小的有效区间历史信息窗口.由于内核和驱动中接口“定义-使用”链的依赖特点和接口先定义后使用的原则,旧内核版本到新内核版本区间中引入的某个元素定义变更,导致使用该元素旧定义的驱动程序在新内核版本环境编译报错.分析以上过程,我们发现该元素定义变更是新旧版本内核之间的某次提交导致的.由于该元素定义变更之后,其他驱动的开发历史中才可能变更使用该元素新的定义.因此,该元素定义变更的提交点所在版本到新内核版本之间的区间为该元素对应的有效区间r,然而如何确定该元素定义变更的提交点.本文通过遍历内核代码提交找出导致待移植驱动由编译正确变为编译出错的内核commit提交点,本文称之为分界点.那么针对每个出错接口,该分界点所在内核版本到新内核版本的有效区间r组成了有效区间集合R.由于该分界点提交之后内核不一定会发布对应版本,具体方法中本文使用分界点所在的邻近内核小版本作为有效区间的起始版本.需要说明的是,本文和已有方法[7]存在不同,该方法的潜在假设是出错元素对应的定义变更和使用变更同时出现在该分界点所在的commit中,然后在该分界点commit寻找使用变更信息并用于分析驱动后向移植的辅助示例.该方法相当于在其假设条件下仅使用分界点所在的commit中元素的使用信息,而本文通过分界点扩展出一个有效区间,在更一般的情况下通过有效区间窗口检索更多的和出错接口相关的接口变更使用信息.
3.1.2 已有实例候选集
基于3.1.1节获取的出错接口信息和对应的有效区间集合R,针对每个出错接口,本文通过构造git检索关键字在对应有效区间r中进行检索.具体查询可构造为如下结构,git log--pretty=formate:“%h id HashID%s Message”-no-merges-p-S‘API name’ VKrVK2-dirdirvers>API-name-log.txt.其中API name是出错接口名称,有效区间在Kr和K2内核版本之间,Kr为对应分界点提交邻近的内核版本,-dir标识待检索的驱动项目开发历史,出错接口的使用变更信息来自有效区间对应的驱动开发历史.
然而,驱动程序开发历史中的commit提交信息可能包含缺陷修复、新特性开发或者二者的混合提交,一些不规范提交会引入大量噪声,为已有实例的有效提取造成干扰.为此本文设计了3个启发式规则对上述commit检索和提取过程进行限制和过滤.为了提取符合定义1刻画的已有实例集合S,本文设计3个启发式规则:
1) 由于接口错误不同于其他类型错误可能引入大块代码变更,往往接口调用的变更仅涉及2条语句,因此本文在匹配包含出错接口关键字的基础上进一步裁剪commit片段中的其他干扰代码,过滤后的commit代码片段仅包含2条语句的代码对.即代码对仅包含减掉1条包含出错接口名称的语句,紧接着再增加1条变更语句的情况,具体由于长语句换行等可能是占用行2~4修改量(使用正则表达式识别有些语句因为编码过长导致存在换行的情况).
2) 本文发现编译日志给出的错误类型信息虽然粒度太粗(如宏定义错误、接口名称错误、参数错误3类),却可以用于过滤检索结果.因此,本文尽可能让检索获得的commit代码变更和接口对应的出错类型信息一致,即进一步过滤掉和出错类型不符的同名字段变更、大代码块变更等提交导致截取实例错误(例如commit中存在多行连续删除后多行连续增加代码的变更情形,导致-+语句的配对匹配错位)可能类型不匹配的情况.分析发现上述不同类型的变更各有特点,例如,宏定义一般使用大写形式,接口名称相关代码往往采用驼峰命名规则(如大小写混合等),而参数一般对应的代码变更在括号区间中.因此,本文首先将集合S中的每个已有实例中包含的2条语句作为文本序列,分别按语句中出现的token依次分行(每个token占1行),使用diff-c或者diff-u的轻量级比较方法识别出存在变更的token.然后再使用上述特征过滤和错误类型不符的实例,具体实现通过正则表达式匹配具体实例中变更token的特征.
3) 还需要去除冗余和重复的已有实例,因为驱动开发中可能存在代码块的复用、回滚或者冗余功能等,具体通过计算每个已有实例的散列值并进行比较后剔除冗余.使用上述启发式规则对检索数据进行清洗,过滤掉一些干扰和冗余信息,最后形成每个出错接口对应的已有实例候选集合S.
3.1.3 已有实例相似度计算
针对上述步骤输出的已有实例候选集合S,很多情况下实际提取的实例数量较多且质量存在差异.为了提高生成待推荐补丁的质量和效率,本文需要优先利用和出错接口问题特点匹配的有效已有实例.如何从实例集合S中进一步识别出有效已有实例,本文利用相似度计算将其转化为排序问题.具体来说,针对1个出错接口和对应的1组已有实例候选集合S,本文通过计算出错接口所在的语句和一系列对应已有实例中语句的相似性,对候选集合S中的已有实例进行排序并选择top-N用于后续细粒度补丁素材的提取.本文计算2组语句内部的相似性,并依据求和函数的计算结果SUM进行已有实例的排序.
1)SUM1.表示已有实例和出错语句之间的相似度,度量已有实例中将要删除的语句(-语句)和出错语句之间的相似度.如果已有实例中的减语句和出错语句越相似,那么该已有实例的使用场景和语义越接近出错语句的实际情况.因此本文认为已有实例中的减语句和出错语句越相似,则表示该实例和出错语句的错误问题越相似.
2)SUM2.表示已有实例中语句之间的相似度,度量已有实例中将要删除的语句(-语句)和将要增加的语句(+语句)之间的相似度.根据已有研究[20]的启示,出错语句和补丁语句的相似度越高,则该补丁正确的可能性越高.事实上,已有实例中包含的加减2条语句可以认为是实例所在驱动中出错语句和对应的补丁语句.因此2条语句的相似度越高,则表示该已有实例在其所属驱动中的语义变更正确的概率更高.
基于本文的分析:使用相同内核接口服务的不同驱动程序存在相同或相似的接口调用,而复用相同内核接口服务的不同驱动程序在其对应接口调用点具有上下文结构和使用形式的相似性.因此,本文具体定义2种相似性度量指标:
1) 结构相似性.结构相似性关注2条语句的AST内部结构变化特征,抽取2条语句对应的AST叶子节点值特征Value(n)进行比较.
2) API usage相似性.API usage衡量2条语句中接口使用方式的变化差异,本文将2条代码语句作为序列并关注AST叶子节点的序列特征,抽取2条语句对应的AST叶子节点类型特征Type(n)进行比较.
综上所述,本文定义SUM=(SUM1+SUM2)2对已有实例进行排序.即综合考虑2种相似度,通过SUM1从问题特点相似角度进行排序,同时通过SUM2从参考答案角度进行排序.由于本文在语句级别计算出错语句和已有实例中减语句,以及已有实例中加减语句之间的相似度,为了避免格式和字符长度等因素的影响,本文不采用字符串相似度比较算法,而是通过相似度计算[21]在token粒度进行相似度比较.针对SUM1和SUM2,每种相似度综合计算2种相似度指标取算术平均值,结构相似性特征计算2条语句值特征中叶子节点token的交集和并集之间比值作为度量值,API usage相似性特征计算2条语句类型特征中token交集和并集的元素数量比值作为度量值.
每种相似性特征的度量值计算方法为
其中,Sim表示2条语句之间相似度,取值范围在0~1之间.分子表示2条语句分别包含的token1和token2值集合或类型集合的交集数目,分母表示2条语句所包含的token1和token2值集合或类型集合的并集数目.最后针对每个出错接口提取的已有实例候选集合S,通过上述相似度指标计算度量值获取对应的top-N已有实例列表,作为后续细粒度补丁素材提取的有效已有实例.
3.2 补丁推荐
3.2.1 接口修改方式提取
接口修改方式是候选补丁合成素材之一,本文从出错接口对应的有效已有实例中提取隐含的接口变更方式,作为出错接口候选补丁生成的指导信息.本文将已有实例top-N列表作为输入,采用抽象语法树级别的细粒度差异比较技术,分别提取top-N中每个已有实例的接口修改方式OP.针对每个已有实例中OP的提取,具体在抽象语法树级别进行差异比较,本文使用GumTreeDiff框架[22]改造实现对应功能.图4所示,基于抽象语法树级别的差异比较包括2个步骤:节点映射和节点差异比较[19].其中在节点差异比较阶段,本文比较变化节点并输出节点类型差异(参见定义2)的变更操作.如果变化节点只有1个,则直接输出该节点在语句迁移中的类型差异操作;如果存在多个变化节点则会对应一组语句迁移的操作序列,需要进一步将相邻的操作和节点进行合并.具体将相邻的相同操作合并,对应的节点合并为子树并获取该子树的根节点类型,目前本文的方法实现处理操作序列仅包含相邻节点的相同变更操作,且变化节点可以合并为子树的情形.
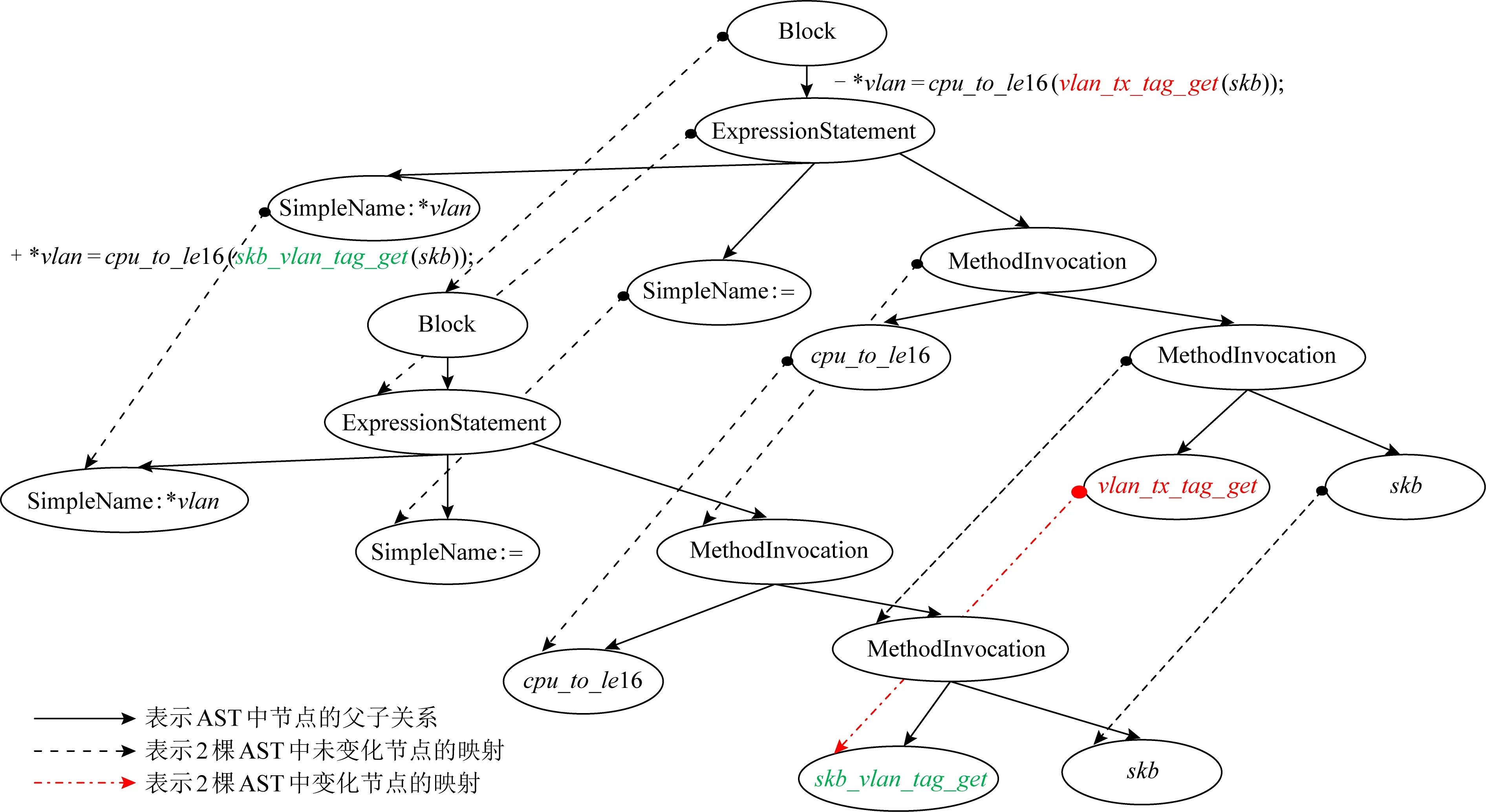
Fig. 4 Comparison of fine-grained differences based on AST
然而,由于问题相似度定义的精度以及相同问题解决方案可能存在的差异性,top-N已有实例中提取的接口修改方式OP依然可能存在差异.为了提高候选补丁的生成精度,本文需要优先利用针对性更高的有效接口修改方式OP.针对同一接口,由于内核接口定义的变更范围在确定的版本区间内是有限的,而不同驱动程序调用相同接口及其接口变更的目的是为了实现相对固定且相同或相似的语义功能.因此在top-N已有实例中,使用相同接口修改方式的多数已有实例对应的OP可能更有效.综上所述,为了进一步提高OP的针对性,本文对OP进行字典方式排序.首先按top-N已有实例所在顺序作为对应OP的基础排序;然后计算每个OP在top-N已有实例中的频度,并将频度作为权重值对OP进行2次排序.具体的2次排序规则包括:权重值高的OP绝对优先,基础排序相同的OP权重值高者优先.
进一步地,我们发现相同类型驱动的开发历史中相同或者相似的问题对应的解决方法更接近,因此利用OP所在已有实例的驱动类型和出错驱动的类型对OP排序的优先级再次进行调整.具体通过计算出错接口所在文件和OP对应已有实例所在文件的路径前缀相似度,确定两者驱动类型的相近程度.首先分别计算出错接口语句所在文件和各OP对应的已有实例所在驱动文件两者的公共路径前缀,公共路径前缀的目录层次越深则表示两者具有更细粒度级别的相同驱动类型,具有更深目录层次的公共路径前缀对应的OP则设置更高的优先级.具体来说,Linux系统中“”符号之后的字段表示路径中的一个目录层次(每个目录层次的深度记为1),本文的方法将路径看作字符串序列并以单个目录作为最小比较单位计算公共路径前缀的深度.综上所述,本文输出带有权重的OP列表.针对图4示例中的已有实例,提取的接口修改方式OP:“Update(Type(vlan_tx_tag_get),Type(C))”,表示更新接口vlan_tx_tag_get的接口名称(此阶段已知C的类型为接口名称但具体Value值未提取,即C的值为下文待提取的接口修改内容).
3.2.2 接口修改内容提取
通过上述步骤输出的接口修改方式OP,刻画了候选补丁生成所需的修改方式素材,然而仅仅使用OP生成候选补丁相应素材依然不足.由于各个驱动调用接口时可能引入的参数名称等元素的命名方式或者编码风格的差异,接口修改内容C在现实世界中存在多样性.为了提高补丁生成精度,需要对接口修改内容C进行细致分析.我们发现接口修改内容C可以进一步分为共性和个性2种类型,根据第2节分析,历史开发信息数据源中倾向于包含共性修改内容,而个性修改内容往往存在于待移植驱动出错点源码的上下文中.为了细致地分析和提取接口修改内容C,算法1首先对C进行分类,然后根据不同情况再分别从历史开发信息和出错点上下文2种数据源提取相应的C.
算法1.区分共性和个性修改内容并分情况提取补丁素材列表.
输入:接口错误语句代码片段errorP、接口错误位置L、权重值最大OP对应的已有实例集合instanceList;
输出:节点标签和节点的值Node(l,v),即C的名称.
① IFcompare(instanceList,0.9) THEN
②commVar=getModifyNode(instanceList);
③ RETURNNode(comm,Value(commVar));
④ ELSE
⑤varSet=collectVarList(L,errorP,N);
⑥varList=rankByDistance(varSet,L);
⑦ IFcompare(instanceList,M) THEN
⑧commStr=getSubcon(getModifyNode(instanceList));
⑨tempList=varList;
⑩varList=reRank(tempList,commStr);
根据我们在驱动移植场景中的观察,共性和个性修改内容在已有实例中呈现的趋势为:个性修改内容在出错接口对应的一组已有实例中接口修改内容字段各自不同的比例更高,而共性修改内容在对应的接口修改内容字段往往相同的比例更高.本文算法1中使用权重值最大的OP对应的多个已有实例组成的集合中包含的接口修改内容字段区分共性和个性修改内容C,如果该字段大部分相同则为共性C,否则为个性C.其中算法1输入:errorP表示出错接口所在程序片段,L表示出错接口所在位置,instanceList表示该出错接口对应的权重值最大的OP所在的已有实例集合;算法1输出:Node(l,v)表示二元组,l表示接口修改内容C的类型是共享名称还是私有名称,v表示接口修改内容C的值或值列表(共享名称C为1个值,而私有名称C为1个值列表).算法1行①~③,如果权重值最大的OP对应的多个已有实例中接口修改字段90%以上相同,则该出错接口对应的修改内容C为共性类型,直接返回对应已有实例的修改字段Value()值并设置标签为共享名称.行④~,否则该出错接口对应的C为私有名称.其中行⑤⑥,根据私有元素的先定义后使用原则,首先收集出错点所在源码上文的N条语句中出现的变量、表达式左值和函数实参等(实验中根据经验取N=5);然后基于变量使用的局部性原理,哪些变量或者token离出错点的距离更近,则更可能被作为候选的私有修改内容C.本文依据候选变量所在的行和出错点的程序距离对候选C进行基础排序,具体使用语句间的物理距离作为程序距离进行度量.由于驱动程序源代码中驼峰命名规则等编程规范使用比较普遍,一些内涵相似的私有名称或者token(例如,相似接口中使用的参数命名)虽然名称不同但具有一定相似性,最常见的情形是具有相同的前缀或者后缀.例如,virtio驱动中接口vring_new_virtqueue更新后新增参数KVM_S390_VIRTIO_RING_ALIGN,而其他驱动调用该变更后的接口时新增LGUEST_VRING_ALIGN,VIRTIO_PCI_VRING_ALIGN等具有相似后缀的参数.行⑦⑧,算法1通过判断权重值最大的OP对应的多个已有实例中接口修改字段的相似度大于M值(实验中根据经验取M=0.5),则提取这些已有实例中接口修改字段的最长公共字符串,commStr表示该子串.行⑨⑩,则利用该公共子串commStr和已收集的候选私有名称列表tempList之间的相似度对其进行2次排序.具体对字符串长度小于公共子串commStr的候选token保持原有基础排序,而对字符串长度大于公共子串commStr的候选token依据相似性度量值进行冒泡位置调整,这里使用编辑距离进行2个字符串的相似性计算.行返回私有字段列表的值Value(varList)并设置标签为私有类型.如果对应已有实例集合中的修改内容字段满足大于M的相似性要求,则返回经过2次排序的候选列表Value()值,否则返回基础排序的候选列表Value()值.
3.2.3 候选补丁生成和推荐
结合上述步骤收集的细粒度补丁素材,本文将待推荐的候选补丁定义为P=patch(L,OP,C)[14].其中L表示接口出错的位置,也是修复该接口的打补丁位置;OP表示出错接口补丁采用的修改方式,C表示出错接口补丁采用的修改内容,也可以理解为修改方式OP的参数.整个待推荐候选补丁生成过程,利用已经收集的细粒度素材列表,采用编辑脚本生成技术[19]进行实例化产生推荐补丁列表.
待推荐候选补丁生成阶段还需要解决2个问题.1)出错接口所在语句内部的修改位置如何确定.L即使是准确的错误位置,也仅仅刻画了出错接口语句所在位置的行号,而接口修改方式OP中的节点及其索引号,刻画了出错语句对应的已有实例中引入变更的语句内部相对位置.由于出错接口待生成的补丁和对应的有效已有实例之间,出错接口名称和语句内部引入变更的相对位置相同.因此,本文的方法通过锚定出错接口名称并利用权重最大的OP匹配出错语句中的待修改节点,最终确定出错接口所在语句内部的修改位置.2)生成的待推荐候选补丁如何排序.由于细粒度补丁素材从不同侧面刻画了待生成补丁的质量,本文的方法很自然地通过合成候选补丁时采用的素材列表优先级确定最终推荐补丁列表的顺序.具体来说,本文采用编辑脚本生成技术,依据补丁定义在抽象语法树级别进行出错语句的转换并生成候选补丁,通过补丁素材OP列表和C列表的优先级位置共同确定候选补丁列表的顺序.然而上述过程中可能会合成位置错误或者语法错误的候选补丁,本文对编译出错的候选补丁直接抛弃.最后对输出的顺序在前n个补丁列表进行推荐,如果没有输出待推荐补丁,则推荐失败.本文方法进行了细粒度的排序,在实验中往往第1个候选补丁的质量很高,因此本文直接设置n=1.
针对推荐补丁的质量判定,本文采用人工方式确认补丁有效性.首先每款待移植驱动程序设定历史上已经针对目标内核版本移植后的1个驱动程序版本为正确的参考程序版本Dbase,然后逐个出错接口依次进行补丁质量判定,依据参考程序版本中相应的代码变更片段和推荐的第1个补丁进行人工对比.需要进一步说明的是,目前程序自动修复研究中的一般错误补丁生成通过测试集自动判定候选补丁的质量,通过测试集中的全部测试用例的候选补丁被认为是正确的补丁[23].然而,本文研究的驱动移植错误补丁采用推荐方式,具体原因为:一方面驱动程序的开发一般由设备制造商主导,现实世界中很难收集充足的驱动程序相关测试集,即使有少量测试用例,驱动程序版本升级和运行环境(内核)变更也会对已有测试集带来影响,而且还需要真实的驱动设备支持其实际执行;另一方面,程序自动修复研究中一般错误的补丁质量判定,由于弱测试用例导致判定结果存在过拟合问题[23-24].也就是说由于测试集并不能刻画完整的程序规约,使得通过测试集判定的候选补丁依然可能包含错误的补丁,输出的补丁还需要人工2次判定或者使用其他方法进行择优.针对驱动移植错误补丁质量的自动判定,我们将在后续进行研究.
4 实 验
本节介绍实验数据集和实验环境,以及相关实验结果及其分析.总体来说,本文的实验期望回答如下2个问题.
问题1. 本文的方法针对真实驱动移植中的接口错误进行补丁推荐的有效性如何?
问题2. 本文的方法针对驱动移植接口错误进行补丁推荐的性能如何?
4.1 数据集建立
本文的实验在真实的前向移植场景中进行,目标是检验旧版本驱动程序的原有功能在新版本内核环境中复用时针对出错接口的补丁推荐情况.为了方便检验方法的有效性,本文选择实验对象中的驱动程序和内核环境依据如下标准.
1) 内核版本从K1升级到K2,K1环境下的待移植驱动D1在升级过程中已经存在K2环境下对应的驱动程序的升级版本Dbase,从D1到Dbase的前向演化过程中引入的变化存在内核接口调用的变更,本文的研究只关注移植过程中发生的接口调用不一致问题.
2) 待移植驱动D1在前向演化过程中所发生的一些接口调用变化,在K1到K2内核区间中已经存在其他驱动对该类接口调用的使用和变更历史开发commit提交信息.即驱动在移植过程中发生的一些接口调用错误,在该区间对应的git仓库中存在其他驱动程序复用和变更该接口调用的历史commit提交信息.
3) 待移植驱动D1在原来的旧内核版本K1上编译正常通过,但D1在待移植的新内核版本K2上编译产生的编译错误日志包含接口调用错误.
通过以上标准并结合实际实验资源的综合考虑,筛选和收集待移植的驱动程序数据集.确定版本区间K1:Linux-3.5.4,K2:Linux-4.1.0版本,该区间总计跨越61个Linux迭代的内核小版本.最终收集了Linux-3.5.4对应的9款驱动程序,总计包含116个文件和126 097行代码.表1展示了本文收集的待移植驱动程序数据集的具体情况.

Table 1 Dataset of Driver Porting in the Experiment
4.2 实验设计
我们实现了本文的方法并形成了驱动移植场景中的接口补丁推荐工具DriverFix.本文采用git log-S构造检索形成已有实例候选集合S,然后利用启发式规则和相似度排序获得top-N已有实例列表,实验中设置N=5,采用git-2.7.4版本.然后基于GumTreeDiff框架进行抽象语法树级别的差异比较并提取每个已有实例中包含的OP,通过频度计算对其进行排序形成有效OP.其中,基于抽象语法树的差异比较采用gumtree-2.1.2版本,抽象语法树解析前端采用cgum-1.0.1版本.接着通过算法1区分共性和个性接口修改内容,然后从历史信息(权重值最大的OP所在的有效已有实例组成的集合)提取共性C,基于变量使用局部性原理和命名规则相似性过滤方法从出错点上文提取个性C列表.最后根据给出的补丁定义和GumTreeDiff编辑脚本生成算法合成候选补丁,对候选补丁列表进行去重和排序并输出第1个补丁进行推荐并由人工判定补丁质量.实验中,对收集的9款驱动分别进行前向移植实验,针对驱动程序从旧内核K1:Linux-3.5.4版本移植到新内核K2:Linux-4.1.0版本过程中产生的接口错误进行候选补丁生成.历史开发信息git仓库采用Linux官方主分支信息,使用DriverFix工具依次对每个驱动移植中产生的接口调用错误生成待推荐补丁,最后人工确认实验效果.本文的全部实验使用ubuntu 16.06 64位操作系统环境,编译环境使用gcc-5.4.0版本,硬件采用1台PC机器,4核3.20 GHz Intel CoreTMi5处理器、8 GB内存.
4.3 实验结果
问题1. 本文的方法针对真实驱动移植中的接口错误进行补丁推荐的有效性如何?
表2展示了本文的实验结果,对4类总计9款驱动程序进行了前向移植,采用本文的方法针对其中的接口调用错误进行了补丁推荐.在待推荐补丁生成过程中,依据本文从已有实例中自动提取的接口修改方式OP的不同将接口错误自然分为7类,包括宏定义错误、接口名称错误、接口类型错误、修饰符错误、缺少参数错误、多余参数错误和参数类型错误.实验中,总计针对46个接口调用错误生成了34个补丁,其中31个人工确认有效,推荐正确率为67.4%,有效补丁通过和基准版本驱动程序版本Dbase中的对应代码进行人工比较确定语义相同并进行双人交叉确认.从各个错误类型角度统计补丁推荐情况,总体上修饰符错误(99)、多余参数错误(22)和函数类型错误(33)这3类错误补丁推荐准确率最高.从实验数据分析,前2类确定了有效修改方式是修饰符错误和多余参数错误这2类错误,确定了有效修改方式是去除无效修饰符和无效参数即可生成补丁,而第3类函数类型错误在实验数据集中主要出现的是可以强制类型转换的情形,因此上述3类错误呈现较高的正确率.而函数名称错误(917)从逻辑上是一类简单错误,实验中补丁生成准确率却很低.主要原因在于实验中总计10个错误问题没有找到对应的有效已有实例,其中8个对应函数名称错误,因此在历史信息中存在对应已有实例的情况下函数名称错误补丁生成正确率依然很高.相比之下,缺少参数错误(45)、宏定义错误(49)和参数类型错误(01)补丁生成正确率较低,主要原因在于有些宏定义需要多参数进行变换,接口修改方式很难刻画该类复杂变换.另外,针对参数类型错误和缺少参数错误,由于需要引入新的参数等多样性修改内容素材,补丁生成的有效性往往较低.其中,针对个性化修改内容素材(14),本文的方法提取有效性占比25%.
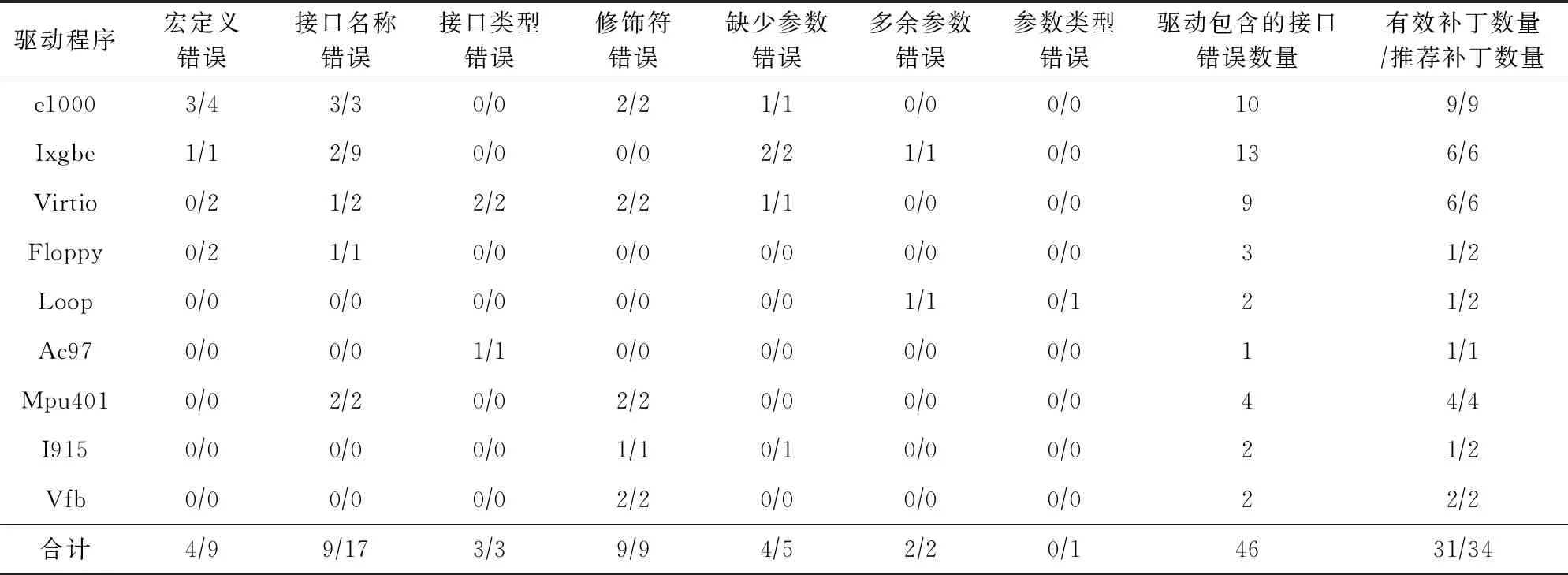
Table 2 Distribution of Recommended Patches Details
表3展示了生成补丁的过程中提取的已有实例所属的驱动程序项目和对应开发历史信息.我们分析了实验中提取已有实例使用到的其他驱动程序历史开发信息,总体上网络相关的驱动项目开发历史占比相对较高,上述现象和本文待移植的驱动数据集中网络设备驱动占比较高比较一致.另外,实验中从历史开发信息获取已有实例,最后汇总发现使用了17款其他驱动程序包含的已有实例,这些已有实例的总数量(156个)能够支撑实验并且不均匀地分布在各个参考的其他驱动程序中.实验中,有些接口错误对应的已有实例较多,而另一些接口错误的实例较少甚至没有找到对应实例(4.4节进一步分析).
问题2. 本文的方法针对驱动移植接口错误进行补丁推荐的性能如何?
使用本文的接口补丁推荐工具DriverFix,在实验中主要时间消耗包括:编译以及编译错误日志解析、有效区间识别、已有实例提取和排序、OP和C提取及排序、候选补丁生成及排序等部分.具体编译过程需要迭代提取相应的接口出错信息、不同驱动程序中相同的接口错误语句可以复用已有实例候选集合等信息.图5统计了9款驱动程序中所包含的接口错误在生成对应的候选补丁时消耗的时间,横坐标为实验中的9款驱动程序,纵坐标为针对每个驱动程序中的接口错误进行补丁推荐消耗的时间,总体上针对各个驱动生成候选补丁的数量和耗时成正比.相比已有研究[7]中提取辅助信息的方法,人工利用该方法输出的辅助信息构造每个补丁平均耗时在30 min,一方面本文的方法直接推荐候选补丁而并非辅助信息,另一方面本文的DriverFix针对实验中每个驱动程序推荐接口补丁平均耗时大约在10 min以内,有效提高了驱动移植中错误处理的效率.

Table 3 Distribution of Existing Instances Used in Other Driver Development History
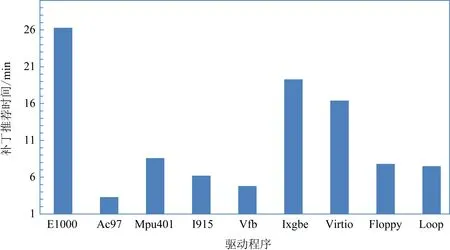
Fig. 5 Performance analysis of candidate patch generation
4.4 威胁分析及讨论
本文方法的有效性检测外部威胁主要来自Benchmarks.由于本文使用的数据集相对较小,可能并不能完全代表驱动移植接口错误的实际数据分布.但是本文所使用的实验数据集全部都是真实的错误,并且来自不同类型的驱动程序,一定程度上覆盖了一大类驱动移植错误.内部威胁主要来自手工判定补丁质量可能引入误判.为了缓解这种威胁,本文通过2人分别独立手工判定生成的候选补丁质量,如果判定结果不一致则该补丁不被计入正确的实验结果.
以下我们进行威胁分析,同时讨论相关的限制以期成为后续可能的改进方向.本文的方法在合成待推荐的候选补丁时使用编译方式进行定位,编译方式的静态定位和运行测试集的动态定位不同,同时编译报错信息存在误报和不准确问题,该问题我们在后续研究中进一步改进.进一步地,我们收集了实验中的一些失败案例,进而分析本文通过提取细粒度素材合成候选补丁过程中存在的限制.从实验结果分析,本文的方法对7类接口调用错误有效,为了保证补丁生成的质量,本文的方法采取保守策略.例如,接口变化内容素材C仅考虑来自已有实例commit或者出错点上文的内容.其中缺少参数和参数类型错误需要引入新的修改内容C,如果是个性素材仅考虑出错点上文数据源有限的较小范围,未考虑其他类型数据源或者引入新变量进行预先赋值等情形.函数类型错误暂未考虑类型不匹配的情况需要对其进行类型转换等,最大限度地遵守错误所在项目的编程规范.函数类型错误在手工判定补丁有效性时,只针对接收值和接口返回值类型能够进行默认强制类型转换的情况认为有效(例如int型和bool型之间的转化等).
Table 4 Analysis of Recommended Patches Generation FailureError Type
表4 待推荐补丁生成失败错误类型分析

Table 4 Analysis of Recommended Patches Generation FailureError Type
补丁推荐失败类别宏定义错误接口名称错误缺少参数错误参数类型错误推荐失败的补丁数量(推荐失败补丁数量∕错误总数)∕%未找到已有实例28001021.7AST映射和比较出错200024.3生成的待推荐补丁错误101136.5
本文的方法还存在一些不足,我们使用实验中出现的一些案例进行分析说明.表4统计了待推荐补丁生成失败或者补丁错误的具体情况,其中10个接口错误在历史开发信息中没有找到对应的已有实例,包括2个宏定义错误和8个接口名称错误的待推荐补丁生成失败;本文推荐补丁的质量客观上依赖于历史开发信息中包含的已有实例数量和质量,实验中总计46个接口错误其中36个找到了对应的相似已有实例.有2个错误对应的有效已有实例在AST映射阶段产生混乱,最终无法提取有效的修改方式OP素材导致补丁生成失败;还有3个错误由于对应已有实例差异较大,或者修改方式刻画困难等情况导致生成错误的待推荐补丁.
失败案例1.已有实例AST映射失败.
SET_ETHTOOL_OPS(netdev,&e1000_ethtool_ops);*error code*
-SET_ETHTOOL_OPS(netdev,&atl2_ethtool_ops);
+netdev→ethtool_ops=&atl2_ethtool_ops;
-SET_ETHTOOL_OPS(dev,&typhoon_ethtool_ops);
+dev→ethtool_ops=&typhoon_ethtool_ops.
失败案例2.已有实例差异大且变换复杂.
PREPARE_DELAYED_WORK(&fd_timer,fd_watchdog);*error code*
-PREPARE_DELAYED_WORK(&old→work,fw_device_update);
+old→workfn=fw_device_update;
-PREPARE_DELAYED_WORK(&hub→init_work,hub_init_func3);
+INIT_DELAYED_WORK(&hub→init_work,hub_init_func3).
失败案例1显示的是网卡驱动e1000中的宏定义错误待推荐补丁生成失败,通过分析可以看出找到的已有实例中包含的语句变化复杂.针对该情况,GumTreeDiff框架中的已有映射算法无法匹配正确的节点,导致AST映射失败.我们人工分析其修改方式为“将出错代码中宏定义的第2个参数赋值给第1个参数的ethtool_ops成员并替换出错的宏SET_ETHTOOL_OPS”,即使AST映射成功,其复杂的迁移语义刻画也比较困难. 失败案例2待推荐补丁生成错误的主要原因是找到的已有实例差异大且变换复杂,其中Instance1的已有实例AST映射失败,Instance2的已有实例修改方式为“替换宏定义名称”,但该实例在Floppy驱动中是错误的.另外2个生成错误的补丁也是类似失败案例2的变换情况,比较复杂.综上所述,针对上述复杂情况,本文的方法依然有待提高,具体包括AST映射和差异比较、个性化修改内容提取等方面还需要引入新的解决思路进行技术突破.
5 相关工作
5.1 补丁生成
补丁推荐和补丁生成虽然是2个不同问题,在技术上却存在区别和联系.在错误定位和补丁质量判定方面存在差异,但是补丁推荐和候选补丁生成中将错误语句变更为正确语句的代码迁移或者变换两者具有相同之处.针对一般错误问题,Le等人[25]假设修复补丁存在于待修复程序所在的当前项目中,提出GenProg方法利用遗传算法对候选代码片段进行变异和交叉组合操作生成补丁,其采用的随机变异方式会产生很多无意义的候选补丁.Kim等人[26]假设修复补丁可以在其他项目中找到,通过人工定义的修复模板生成补丁并提出PAR方法,通过模板约束随机变异提高了候选补丁质量.Le等人[16]认为不同模板的修复能力是不同的,通过挖掘人工修复的补丁中所使用的模板频度,赋予修复模板权重从而进一步提高了候选补丁的质量.Wen等人[17]提出补丁生成技术CapGen,利用AST考虑出错语句和修复模板的上下文信息选择修复模板指导候选补丁生成,并提出3种模型获取补丁修复的内容素材,提高了补丁质量.文献[16-17,25-26]所述方法相关研究的问题和方法与本文都存在一些不同,文献[16-17,25-26]所述方法面对的一般错误问题场景具有测试集刻画出错信息并用于错误定位和补丁质量判定,这些测试集作为程序规约可以用于构造适应度函数或者提取错误相关的约束条件来指导补丁生成,而本文的驱动移植场景没有对应测试集却具有编译日志.文献[16-17,25-26]所述方法由于面向的一般错误问题目标范围较大,对应方法往往先预定义高频模板集合再指导一般问题中常见的具体错误生成补丁.而本文的方法面向的驱动移植场景中接口出错的问题类型相对较少,同时由于内核接口复用的特点,驱动历史开发信息中可能存在这些接口变更的使用信息,即已有实例.因此本文结合驱动移植中接口错误的问题特点寻找已有实例,然后通过已有实例的媒介提升修改方式等补丁素材的针对性,本文提取修改方式的思路可以认为是一种定制模板.和文献[16-17,25-26]已有方法先有模板集合再选择模板的思路不同,本文的方法先有出错接口问题再从对应已有实例中提取针对性的定制化修改方式(通过问题特征找模板).文献[16-17,25-26]所述方法在当前项目、其他项目数据源中寻找补丁生成素材,而本文的方法和文献[16-17,25-26]所述方法不同,通过区分修改内容类型再从不同特征的数据源中提取素材.
针对条件错误问题,Nopol[27-28]关注Java语言中的条件错误并通过测试集提取条件约束,将补丁生成转化为约束求解问题进行定位和补丁合成.而熊英飞等人[29]提出ACS针对单变量条件类错误问题,基于变量间的依赖关系排序、相似上下文代码片段所使用的谓词频率排序等技术,提出了针对条件错误的高精度补丁生成方法.针对系统构建领域的构建脚本错误,Hassan等人[30]提出利用失败日志检索历史上相似的构建错误,再基于历史修复方案提取模板并枚举补丁细节素材生成补丁的HireBuild方法.Lou等人[31]通过补充实验发现HireBuild方法的不足在于不灵活的补丁生成规则并提出新的方法HoBuFF,HoBuFF将构建错误问题聚焦在一类常见的配置错误(配置项和对应值).该方法提出基于数据流分析并利用构建错误日志进行错误定位,基于搜索当前项目信息(构建代码和日志、构建依赖的外部资源)进行补丁素材提取和补丁生成.条件错误和构建错误研究与本文也具有一定差异,条件错误一般需要修改条件(增加减弱)或者增加删除前置条件等对应的修改方式类型较少,主要困难在于如何合成有效的条件表达式,文献[27-29]方法具体使用约束求解和上下文相似性计算等技术提取表达式素材.构建错误问题也有自身特点,一般没有对应测试集但存在构建错误日志信息,构建语义往往是依赖或者版本问题甚至抽象为键值对的配对问题(配置项和对应值).本文中驱动移植的接口调用错误本质上由于打破了内核接口“定义-使用”链引起的不一致性问题,没有错误对应的测试集信息但是具有编译错误日志和历史开发信息中的已有实例等信息可以使用.
5.2 驱动移植
Rodriguez等人[5]提出Coccinelle自动分析驱动针对兼容库需要修改的变化内容,从而辅助驱动适配兼容库达到移植驱动的目的.Thung等人[6]通过分析内核commit信息,以推荐系统的方式给出驱动移植辅助信息.具体通过遍历移植区间中内核commit并找到由于内核提交使得驱动出错的commit提交点,然后在该提交点commit中进一步分析移植错误相关的错误元素使用变更代码片段用于辅助后向移植,主要推荐的变化示例包括更改记录访问、删除函数参数、函数名的变化、常数变化和IF条件变化等类型.Lawall等人[7]发现驱动移植中的1个错误问题所需的辅助信息可能来自多条commit提交数据,针对该类问题,其结合编译信息和出错源码信息提取检索关键字,再利用补丁检索语言(patch query language, PQL)查询历史开发提交数据获得移植所需的辅助信息.相比git查询和Google搜索,该方法通过加强检索条件并采用补丁检索语言进一步提高了辅助信息的检索精度和效率.虽然文献[5-7]已有研究和本文都使用了历史开发信息,但两者有所不同.文献[5-7]方法是从历史开发信息检索驱动移植辅助信息本身,而本文的方法是将历史开发信息作为辅助媒介提取针对性的细粒度补丁素材.文献[5-7]方法仅仅提取了辅助信息本身给出了驱动移植中一般错误问题的参考信息和辅助示例,一定程度上减轻了驱动移植的负担.而本文的方法针对驱动移植中的接口调用出错问题,通过分析辅助信息提高了细粒度补丁素材的针对性,具体利用了历史开发信息中的已有实例分析错误特点并提取针对性的接口修改方式和修改内容等素材进行高质量补丁推荐,进一步降低了驱动移植难度并减轻了人工负担.
6 总结和展望
本文的特色在于利用出错接口问题和相似已有实例的共性分析驱动移植的接口错误特点,通过已有实例的辅助作用提高了细粒度补丁素材提取的针对性.具体来说:一方面,本文的方法基于已有实例获取出错接口修改方式,针对性更强.相比已有一般错误候选补丁生成方法,先有模板集合而后通过策略选择用于具体错误问题,本文的方法是先有具体错误问题并通过错误特征寻找定制修改方式(定制模板);另一方面,本文的方法分析修改内容的多样性更加细致,借助已有实例的差异性区分共享名称和私有名称等修改内容,区分不同情况从历史开发信息和出错点上文源码2种数据源提取修改内容更加自然.最后,在真实驱动移植场景中的实验表明,本文的方法能够对不同类型驱动程序中7类接口调用错误进行补丁推荐,补丁推荐的质量较高,有效提升了驱动移植中错误处理的效率.
未来,我们计划在提高驱动移植接口修改方式、个性修改内容提取的质量方面考虑语义信息进行研究,针对驱动移植补丁质量的自动判定等方面进一步开展研究工作,同时在更大规模的驱动移植接口错误数据集进行实验和分析.更进一步地,我们计划将本文的思想推广到更一般场景的补丁推荐或者候选补丁生成问题.例如,一些通过代码继承关系传播的同源错误修复是一个重要问题,原本相同的软件开发分支分叉(fork)之后发展为不同定制版本,其中包含的继承错误、继承错误变种和相应补丁之间具有一定的共性实例,值得深入研究.
