基于YOLO算法的红外图像目标检测的改进方法
2021-01-14刘智嘉赵金博夏寅辉高旭辉
刘智嘉,汪 璇,赵金博,夏寅辉,高旭辉
(1.北京波谱华光科技有限公司,北京 100015;2.湖北大学知行学院 计算机与信息工程学院,湖北 武汉 430011)
1 引 言
红外热成像指利用光电技术捕捉和检测物体热辐射的信号,并将这些信号转换成为人类视觉可感知和接收的图形或图像,因此,红外热像仪可以在完全黑暗、强光照射、浓烟、雾霾以及不大于中雨的条件下对周围环境及探测目标成像,能够极大地弥补可见光成像受光照条件制约的不足,满足全时段、全天候观测的需要。国防及安全应用中对红外图像中出现的特定目标进行监测是核心任务之一,如对机场、监狱、以及军事管制区域进行24 h监控;边境检查站和巡逻监控;车辆辅助驾驶系统中的行人监测等。红外热成像能够满足上述领域对全天候、全时段成像的需求。传统的红外图像目标检测算法是利用人工设计行人比例模板,通过人工设计的目标轮廓提取方法对图像中目标轮廓进行特征提取并与比例模板进行比对,对图像中的目标进行判断和定位,主要的传统检测方法有:梯度直方图(Histogram of Oriented Gradient,HOG[1])算法、局部二值模式(Local Binary Patterns,LBP[2])特征算法、尺度不变特征(Scale Invariant Feature Transform,SIFT[3-4])检测算法及哈尔特征(Haar-like Features[5])算法等。特征提取方法和比例模板的设计对设计人员的经验和专业知识要求较高,且应用场景单一,泛化能力较弱。
基于深度学习的目标检测算法的基本原理是利用大量卷积运算实现检测算法自主对图像中目标的特征进行抽象和提取,并对提取到的特征进行拼接和总结来获得更多特征,提升对目标检测准确率。得益于人工智能及相关技术近些年的高速发展,深度学习目标检测算法进步迅速,并在可见光图像中已经获得了非常优秀的检测效果。深度学习检测算法主要分为两类:两步检测算法和单步检测算法,两步检测算法将检测过程分为两个阶段,第一阶段任务主要是对图像备选区域进行划分,第二阶段任务是对备选区域内的可能目标进行判断,该类方法的主要代表为基于区域的卷积神经网络(Region-based Convolution Neural Networks,R-CNN[6])算法及后续的改进算法如Fast R-CNN[7]和了Faster R-CNN[8]。单步检测算法是将区域选择和检测判断结合在一起构成一体化的检测网络,此类算法的主要代表为:SSD[9-10](Single Shot multibox Detector)算法和(You Only Look Once,YOLO)YOLO检测算法[11-12]。为弥补传统红外图像目标检测方法对设计者要求高、提取特征少以及迁移能力差的不足,利用深度学习目标检测算法对红外图像中目标进行检测,能够取得更高的准确率和更强的泛化能力。
由于深度神经网络结构复杂且运算量巨大,检测效率一直都是影响深度学习目标检测实现大规模实际应用的瓶颈。因此,研究者们也逐渐将研究重点转移到在保证必要检测准确率的前提下如何尽可能提高检测效率的问题上。两步检测算法结构相对复杂,网络结构中独立部分需单独训练,大大增加了整体优化难度且运行速度较慢,对于实际应用的终端部署也较单步检测算法更难实现。
SSD算法创新性地提出了多尺度预测结构并且具有较快的检测速度,但SSD仍被YOLO的后续改进算法YOLOv2和YOLOv3超越,并且由于SSD在网络中一些参数值需要人工预设定,调试过程对调试经验依赖性很大,所以YOLO算法特别是最新的YOLOv3在各方面均有更佳的表现。对于嵌入式平台或者FPGA平台的终端部署,YOLOv3的实际应用仍有些缓慢,为了改善YOLOv3终端应用的表现,本文提出一种基于YOLOv3的改进算法——Darknet-19-yolo-3,在检测准确率基本一致的情况下检测速度可以明显提升。
2 YOLOv3系列算法原理及网络结构
YOLO系列算法的基本思想一脉相承:首先将输入图像等分成S×S个网格(如图1所示),若待检目标的坐标中心落入前述某个网格中,那么这个网格单元就负责对该目标检测。所有网格在检测过程中都需要预测B个目标边界框、待检目标的置信度以及类别信息,其中置信度表示算法模型认为边界框中包含目标的概率值和预测边界框的准确率。

图1 YOLO算法图像分割示意图Fig.1 Diagram of image segmentation based on YOLO algorithm
YOLOv3(架构图如图2所示)算法改进了YOLOv1和YOLOv2将原图像仅提取13×13单层特征图输出的结构,而是引入多尺度结构:将输入图像分为13×13、26×26和52×52三层特征图输出,图中Resn部分即为YOLOv3的残差结构,用于加深学习网络的深度。

图2 YOLOv3架构图Fig.2 Architecture diagram of YOLOv3
YOLO算法的前两个版本——YOLO和YOLOv2对图像仅做13×13的单尺度分割提取特征,这导致上述检测模型对小目标检测的效果不太理想。YOLOv3算法经过对多尺度预测方面进行改进,可令网络在学习到图像中层、深层特征的同时也学习到浅层特征,并利用将浅层特征图特征叠加至相邻通道的方式,将26×26×512的特征图与13×13×256的特征图相叠加。由于分割尺度越大,单位格子的面积就越小,感受野也随之变小,这使YOLOv3具备了提取细粒度特征的能力。另外,在骨干网络后端的检测部分的每条支路上都加入了5个DBL结构,DBL结构即该网络的卷积层结构,由卷积、正则化和Leaky ReLU函数构成,这样的结构加深了网络深度,提升了对小目标的检测性能。
虽然YOLOv3在速度上已经进行了优化,但是其运行速度对于实际应用来说仍然不够快,只有使用Titan XP及性能更佳的显卡作为硬件基础才能实现实时检测,所以作者同时也提出了一种即为精简的模型——YOLOv3-tiny。为节省运算资源,该模型骨干网络结构不使用残差层,仅使用7层卷积层和最大池化层组合,并将YOLOv3中三尺度预测结构改为两个,5个DBL构成的卷积结构删除至仅剩一个(如图3)。虽然速度上有明显提升,但是损失了极大的准确率。
3 改进模型Darknet-19-yolo-3
YOLO系列算法是利用回归的方法进行深度学习的检测算法,经过不断改进,性能逐步提高,特别是YOLOv3算法保留了YOLO前两个版本和其他算法的一些优点,利用自身端到端训练和检测的优势,其在整体性能上有不错的表现。表1显示了YOLOv2,YOLOv3以及YOLOv3-tiny在COCO测试集上利用Titan X GPU进行测试的结果,其中YOLOv3在检测准确率方面表现最优,YOLOv3-tiny则在速度上占有绝对优势。
虽然YOLOv3算法检测精度最高,但是由于其较深的网络层数,导致检测速度较慢而不适合实际使用终端部署。YOLOv3-tiny速度较快但其检测准确率较差,使用相同数据集进行测试,其检测准确率仅有其他算法准确率的一半左右。YOLOv2性能表现相对平衡,但其检测结构尺度单一,对小目标检测效果不佳。

图3 YOLOv3-tiny架构图Fig.3 Architecture diagram of YOLOv3-tiny

表1 YOLO算法性能对比Tab.1 Performance comparison of the YOLO algorithm
YOLOv3的骨干网络Darknet-53借鉴了ResNet-101和ResNet-102的残差结构,并且设计了大量的卷积层,所以在检测精度上得到了明显提升,但是因为残差网络具有高精度低速度的特点,所以检测效率上受到了影响。如表2显示,Darknet-53的检测准确率已经超过ResNet-101并接近ResNet-152,但在检测速度方面较YOLOv2的骨干网络——Darknet-19差距明显。

表2 主流骨干网络性能对比[13]Tab.2 Performance comparison of mainstream backbone networks[13]
由于检测图像为相对可见光图像分辨率普遍较低的红外图像,同时待检目标特征也较可见光图像中样本特征减少很多,所以使用较深卷积结构的YOLOv3并不适合红外图像检测应用。YOLOv2算法仅输出13×13的特征图,该特征图所包含语义信息较为高级和抽象,属于判断较大目标的深层网络特征,而检测小尺寸目标需要轮廓和位移特征,这些特征属于由浅层网络提取的较低级别特征,所以YOLOv2对小目标识别的表现较差,容易出现漏检或误检。
针对以上问题,本文基于YOLOv2和YOLOv3系列算法的优点提出了一种改进的网络结构算法模型Darknet-19-yolo-3,该算法模型使用Darknet-19骨干网络进行图像特征提取,结合YOLOv3具有3个尺度特征提取的yolo层,并根据YOLOv3-tiny在yolo层中减少了大量卷积运算的思路减少卷积结构,使整体网络结构在保持适度深度的同时具备多尺度检测的能力,以更适合红外图像的目标检测。
Darknet-19-yolo-3网络结构图如图4所示,Darknet-19-yolo-3将Darknet-19骨干网络与改进的yolo层相结合,通过对不同卷积层的进行检测并将各层特征进行融合达到多尺度检测的效果,使改进网络同时具备Darknet-19较为准确和高效的特征提取,又具备YOLOv3系列算法检测网络的多尺度检测结构对不同尺寸目标检测的适应性。预测结构由三路yolo层构成:
1) yolo1(小尺度特征图):13×9尺寸特征图负责检测小尺度目标。若小尺度特征图接收一张416×288的图像,经过步长为2的5次最大池化,即416/25=13和288/25=9,输出特征图为13×9×512。随后经过图中的卷积结构,卷积结构共有3层,由1×1、3×3和1×1的卷积层依次构成。卷积结构输出的特征图在进行两次分别为3×3和1×1的卷积后,得到13×9×18的第一特征图,预测的第一支路即在这个特征图上进行首次预测。

图4 改进模型网络结构图Fig.4 Network structure diagram of improved model
2) yolo2(中尺度特征图):26×18尺寸特征图负责检测中尺度目标。将小尺度卷积第一支路卷积结构所得的输出作为输入,将该输入进行一次卷积为两倍的上采样,之后将上采样后尺寸为26×18×256的特征图与第13卷积层特征(26×18×512)进行连接输出尺寸为26×18×728的特征图,然后经过卷积结构和两次卷积后运算后得到输出为26×18×18的第二特征图并在该特征图上进行第二次预测。
3) yolo3(大尺度特征图):52×36尺寸特征图负责检测大尺度目标。这部分的操作与中尺度特征图相同,将第二支路过程中的卷积结构输出作为输入,对输入进行一次卷积为两倍的上采样,最后将上采样特征与第8卷积层特征进行连接,也同样经过卷积结构和两次卷积后运算后得到输出为52×36×18的第三特征图,并在该特征图上进行第三次预测。
重新设计的网络模型使用较少层数的骨干网络以适合红外图像特征较少的特点,通过减少了不必要的运算提升速度。与此同时,相对YOLOv2增加至三个尺度的yolo层,可以提升不同大小目标的检测效果,提高整体检测准确率。
4 实验及结果评价
4.1 实验工具及流程
实验所采用的训练平台配置如表3所示。实验使用数据集由公开数据及和自采数据集两部分构成,公开数据集采用CVC9及CVC14,自行采集数据集取自户外街道,所采集图像包括白天和夜间不同光照条件,如图5所示。数据集中图像总数量为35986张,其中CVC数据库共有正样本11140张,负样本2589,自采图像正样本17805张,负样本4452张。数据集中图像分辨率均为640×480。本文所做识别研究为行人单类别识别,所准备的数据集内数据数量完全可以满足识别模型训练的需求。

表3 训练平台主要配置参数Tab.3 Main configuration parameters of training platform

图5 红外数据集图像Fig.5 Image of infrared dataset
图6为框架内模型准确率获取流程。平均准确率由训练时得到检测模型后对测试集进行测试并根据测试结果计算获得。

图6 模型准确率测试流程
4.3 训练实验结果
图7、图8和图9分别显示了Darknet-19-yolo-3、YOLOv3-tiny以及YOLOv3在同一数据集下训练的损失值曲线和平均准确率曲线。

图7 Darknet-19-yolo-3训练Loss曲线及平均准确率曲线图Fig.7 Loss curve and average accuracy curve of Darknet-19-yolo-3 training
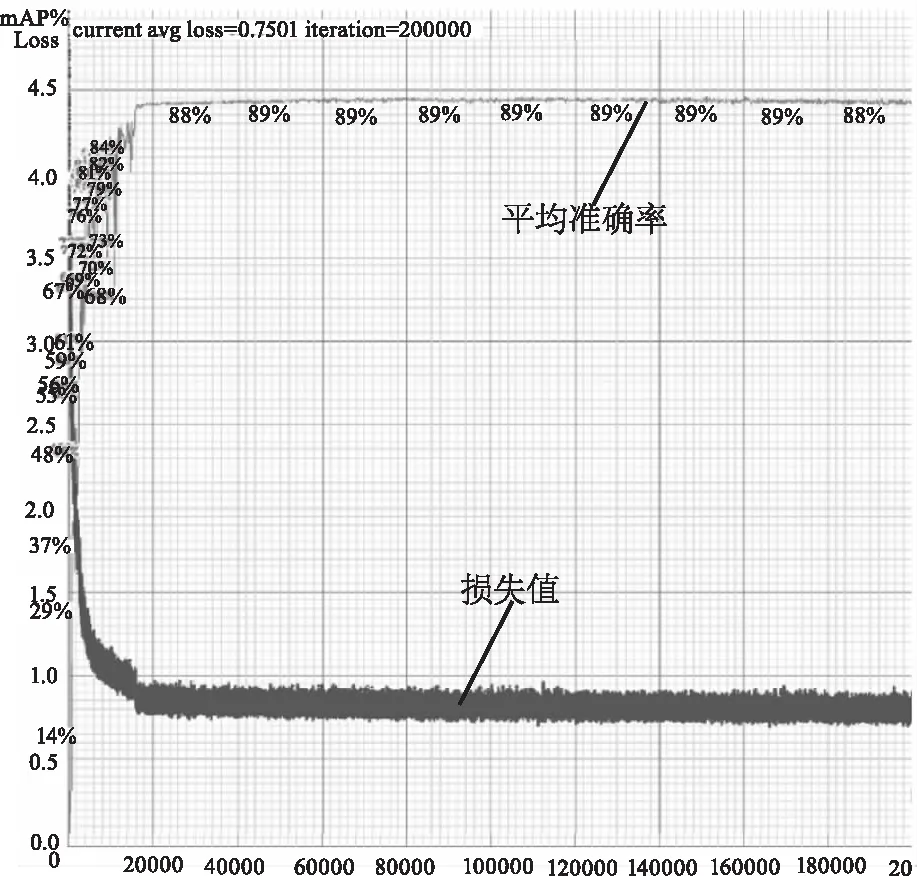
图8 YOLOv3-tiny训练Loss曲线及平均准确率曲线图Fig.8 Loss curve and average accuracy curve of YOLOv3-tiny training

图9 YOLOv3训练Loss曲线及平均准确率曲线图Fig.9 Loss curve and average accuracy curve of YOLOv3 training
4.4 评价指标
目前各类算法比赛中使用最广泛的检测准确度定量评价指标为各类别的检测准确率(Average Precision,AP)和平均检测准确率(mean Average Precision,mAP)。准确率(Average Precision,AP)即交并比(intersection over Union,IoU)的值,平均准确率(mean Average Precision,mAP)即为各个类别的准确率的平均值,由于本文中检测目标为单类目标,所以准确率与平均准确率数值一致。目前各种识别算法挑战赛的检测精度的定量比较均通过平均准确率来确定,一般规定当IoU>0.5的检测框即被认定为检测成功。
4.5 结果分析
根据图7~9,本文将三种模型训练中数据分别统计至表4。为了保证模型训练的一致性和对比测试的准确性,三种模型所用于训练、验证及测试的数据分布完全一致,三种模型训练总批次均为二十万次。由图7至9中可观察到,三个模型训练的损失曲线都呈快速收敛并单调下降,过程中没有出现震荡或者先下降后上升的情况,说明训练数据集划分、网络配置和超参数设置正确有效,曲线反映训练中模型性能表现稳定。模型训练结束前损失曲线基本平缓,损失值不再持续向下明显衰减,表明训练过程迭代次数能够充分满足模型训练需求。
表4展示了三个模型训练的最终损失值,可以明显看到YOLOv3的损失值最小,改进模型Darknet-19-yolo-3训练损失值略高于YOLOv3,排名居中,YOLOv3-tiny损失值最大,分别为前两名的5.83倍和2.72倍。通过训练参数对比可以看出,改进的模型在训练中对数据拟合的表现相对于YOLOv3-tiny已经有了大幅提高,并且更接近YOLOv3的表现。

表4 Darknet-19-yolo-3及YOLOv3系列 模型训练数据对比Tab.4 Comparison of training data of darknet-19-yolo-3 and yolov3 series models
YOLOv3具有最高的平均准确率97 %,而且取得最高准确率是在迭代至2至8万次之间,而YOLOv3-tiny也在迭代过程的中间阶段获得最高准确率89 %,但成果较YOLOv3有明显差距。本文改进模型Darknet-19-yolo-3以96 %的平均准确率居中,仅落后YOLOv3一个百分点,较YOLOv3-tiny检测准确率优势明显。训练实验结果说明网络结构改进对于检测准确率方面优化效果良好,符合预期。
4.6 检测效果
图10为改进模型对测试集CVC公开数据集中图像进行检测效果图,经过训练的改进算法模型Darknet-19-yolo-3对于红外图像中大小目标、多目标及有遮挡目标都有较好的识别效果。

图10 Darknet-19-yolo-3检测效果图Fig.10 Effect diagram of darknet-19-yolo-3 detection
4.7 检测速度测试
本实验为令检测表现更接近应用端性能而选择使用嵌入式平台——英伟达公司的出品的Jetson TX2,如图11所示,为本次实验所使用的嵌入式平台,为了扩展存储容量增加了256 G固态硬盘。嵌入式平台的主要参数配置如表5。
表6所示为三种模型检测速度数据,使用检测视频为自拍摄640×480户外红外视频图像。从表6中可以看出,在检测速度方面,YOLOv3-tiny由于网络结构相对简单以每秒35帧的处理排在第一,YOLOv3检测平均帧数约为每秒8.6帧,改进模型Darknet-19-yolo-3利用Darknet-19较为高效的优势,在Jetson TX2上达到了每秒检测速度最低29.1帧的成绩,如图12所示。

图11 Nvidia Jetson TX2Fig.11 Nvidia Jetson TX2

表5 Jetson TX2主要性能参数Tab.5 Main performance parameters of Jetson TX2

表6 Darknet-19-yolo-3及对比模型检测效率对比Tab.6 Comparison of detection efficiency between darknet-19-yolo-3 and contrast model
Darknet-19-yolo-3可以达到每秒检测不低于29.1张红外图像的处理速度,高于实时检测的每秒检测图像不低于25张图像的要求,该检测速度虽然较YOLOv3-tiny的检测速度仍有一定差距,但是改进模型在速度方面相对YOLOv3已经大幅提高,并且在嵌入式平台Jetson TX2上实现实时检测,具有一定的实用性。实验结果证明网络结构的改进对于检测速度的提升有效。

图12 Darknet-19-yolo-3检测640×480红外视频速率Tab.12 Detection of 640 × 480 infrared video rate by Darknet-19-yolo-3
5 总 结
通过对改进模型Darknet-19-yolo-3及对比模型YOLOv3、YOLOv3-tiny使用相同数据进行的训练及检测实验,三个模型的平均准确率分别为96 %、97 %和89 %,在Jetson TX2上对视频检测速度为29.1 FPS、8.6 FPS和35 FPS。改进模型的网络复杂程度在三个模型中居中,检测准确率和检测速度都位列第二。通过对骨干网络重新选择以及增加三通道优化yolo层的改进方法,改进算法模型平均准确率仅落后YOLOv3一个百分点,但检测速度得到很大提升。实验中,改进模型检测平均准确率超过YOLOv3-tiny七个百分点,虽然速度稍慢与后者的35FPS,不过仍然取得了29.1FPS检测速度,在Jets29.1FPS检测速度,在Jetson TX2平台上实现实时检测。对比实验结果证明,使用相对于YOLOv3的较少卷积运算的同时增加了相对YOLOv3-tiny优化的检测通道的改进模型更适合红外图像数据特点,该模型与复杂的YOLOv3模型检测准确率基本一致,由于减少了卷积运算和对各项参数进行优化,模型检测速度更接近YOLOv3-tiny,实现实时检测。实验证明改进理论及原理分析正确,改进方案有效,改进后模型整体性能表现更有利于应用终端部署,一定程度上实现了检测准确率与检测速度的相对平衡。
