基于并行监督强化学习的车辆制动策略研究*
2021-01-14张涛孙晓霞赵宁
张涛 孙晓霞 赵宁
中国北方车辆研究所 北京 100072
引言
自适应巡航控制(Adaptive Cruise Control,ACC)是先进驾驶辅助系统(Advanced Driver Assistance Systems,ADAS)的重要组成部分[1],属于车辆的主动安全性和舒适性控制系统。ACC系统的主车通过距离传感器检测与前方目标车辆之间的相对速度与相对距离等信息,自动调节主车的行驶速度,确保主车与前方目标车辆达到一种动态稳定的安全距离。ACC系统一方面减少人工驾驶操作失误而增强车辆主动行驶的安全性,另一方面能够提高驾驶的舒适性并减轻驾驶员的驾驶负担。近年来,车对车(V2V)通信技术的发展,如DSRC和LTE-V[2],为主车提供了与周围车辆交换信息的机会。这意味着ACC系统不仅仅通过主车传感器来感知外部环境,还能通过车联网设备直接获得前车的速度、加速度等信息来进行系统控制,由此产生的车辆巡航功能称为协作式自适应巡航控制(Cooperative Adaptive Cruise Control,CACC)系统。
关于ACC/CACC的研究最早可以追溯到美国的PATH项目[3]等。在早期的巡航控制系统中的跟踪控制策略中,线性前馈和反馈控制器由于其算法简单、硬件实现方便等优点被广泛应用[4],然而由于车辆动力学的非线性和环境的不确定性,控制器的参数需要手动调整,控制器难以对未知干扰进行自适应和鲁棒性。模型预测控制(Model Predictive Control, MPC)也被引入到巡航控制系统中,通过预测系统动力学和状态约束来生成最优控制命令[5],但是MPC设计涉及的参数较多,需要更多的时间进行计算调整。此外为了获得更好的驾驶舒适性,在控制器设计中有必要考虑驾驶员的心理和驾驶习惯。在文献[6]中,将数据驱动的自学习算法与MPC相结合,提出了一种基于人的自主控制方案,结果表明在保持安全跟踪距离的情况下,可以降低车辆的速度“颠簸”。然而目前大部分自适应学习算法存在收敛速度较慢,不能充分利用计算资源,无法进行在线学习等诸多弊端。
ACC/CACC系统归根结底是一项驾驶员辅助系统,传统基于PID、MPC等控制方法并不能很好的模拟驾驶员开车时的特性,尤其是在主车跟踪前车进行减速停车时,有些驾驶员倾向于高速接近前车并进行急刹车,而有些驾驶员因驾驶风格较为平滑而倾向于缓慢减速接近前车。但是,现有的跟踪巡航控制过程过于呆板,导致因为跟车距离或者控制效果不够拟人化而让驾驶员感觉不舒适,很可能由于驾驶员的感受不好而对系统产生了否定,因此就对自适应巡航控制系统提出了更高的要求。
为了提升自适应巡航系统的拟人化停车制动效果,本文提出一种基于多路并行监督强化学习(Supervised Reinforcement Learning, SRL)的CACC系统制动控制策略,该控制策略能充分利用计算资源、快速迭代缩短网络训练时间。通过在离线学习过程中加入模拟驾驶员特性的神经网络,使得巡航制动控制单元的控制输出量包含了离线学习过程中的驾驶员驾驶特性,又包含在线学习过程中对控制量的评价指标而添加额外的控制量,使得控制单元在驾驶员驾驶过程中能够不断在线学习更新控制策略来更好地模拟驾驶员特性。
1 系统架构与网络组成
1.1 系统的控制框架结构图
ACC/CACC系统的基本功能是调节主车辆的加速度,使得主车辆和其最近的前车之间的相对速度以及车辆间距离和期望距离之间的误差收敛到零。图1显示了车辆辅助驾驶系统的控制框架结构图
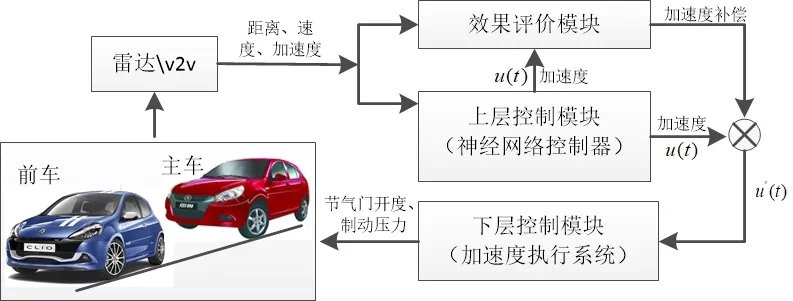
图1 系统的控制框架结构图
车辆系统通过总线信息以及车载测距系统采集主车车速、加速度等状态变量以及与前车的相对车距、速度等环境变量,同时可以通过V2V模块采集前车的加速度、航向角、GPS坐标等变量;离线训练好的上层控制模块根据当前主车状态变量x(t)生成车辆期望加速度的控制量u(t);效果评价模块根据状态变量x(t)和期望加速度控制量,并结合人工驾驶时实际控制量对上层控制模块的控制效果进行评价,如果评价结果为不符合要求,系统进入在线学习模式,如果评价结果为符合控制要求,则将控制量下发给下层控制模块;离线学习用于生产系统的初始最优参数,在线学习用于根据控制误差,实时修正网络参数,满足驾驶员使用需求后固定系统参数结束在线更新过程。下层控制模块根据车辆动力学模型解算当前车速和需求加速度下的期望油门开度和制动压力,结合执行器对加速和制动踏板进行控制。其中上层控制模块的构建包括离线训练和在线训练两部分,评价模块用于估计上层控制模块的代价函数,用来定量化指导上层控制单元的迭代优化。
1.2 监督强化学习神经网络
强化学习(Reinforcement Learning,RL)算法是依靠神经网络拟合学习控制的最优策略,即从当前状态到当前行动的映射,以优化某些控制性能的标准[7]。然而仅仅依靠RL,学习网络并没有被告知当遇到某种状态时应该采取何种行动最合适,而是必须通过反复学习来发现哪些行动会带来最大的回报。研究人员提出,使用监督模块对学习网络进行正向引导可以使学习问题更容易解决[8]。对于车辆动力学控制问题,可以利用人类驾驶员实际驾驶操作的数据作为RL的监督引导者。
图2所示为本文所采用的SRL的基本单元体结构体。行动-评价架构用于建立车辆状态和动作之间的直接关系以及状态、动作和控制性能之间的持续更新关系[9]。监督单元可以理解为驾驶员行为的数据库,根据当前车辆状态给出合理的“拟人化”控制量输出,并与行动单元给出的“机械化”控制量输出作比较,向行动单元提供关于哪些操作可能适合或不适合的更新提示;同时,由权重调节器混合两种动作的复合动作被发送到车辆系统,系统从当前车辆状态通过响应复合输入动作转换到下一个状态x(t+1),并对该动作给予奖励回报。
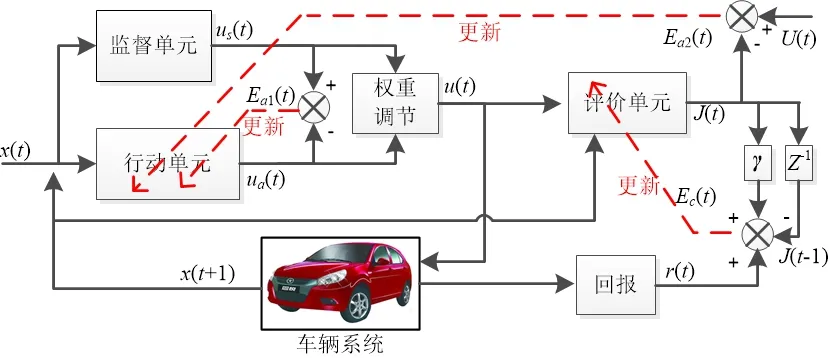
图2 行动-评价监督强化学习的基本单元体
图2中的实线表示数据流方向,虚线表示根据误差进行学习的方向,定义输入状态变量x(t)=[Δd(t),Δv(t),Δa(t)],包括主车与前方目标车辆之间的距离误差、速度误差和前后加速度误差。根据输入的状态变量x(t),监督单元生成的具有不同驾驶员特性的监督控制变量u s(t),行动单元输出的直接控制变量为u a(t),权重调节器混合两种控制量为u(t),将u(t)施加在仿真车辆系统或实际车辆系统上,由车辆下层执行器响应并产生下一时刻的状态变量x(t+1)。根据每一次的动作响应效果给出奖励回报r(t),评价单元根据行动u(t)及其对应的动作状态x(t+1)计算得到代价函数的估计值J(t)。同时,监督单元的u s(t)与控制单元的u a(t)形成了行动单元学习的误差E a1(t),控制变量输入到评价单元并结合期望控制目标U(t)构造行动单元的另一种学习误差E a2(t)。最后根据回报r(t)、当前代价估计值J(t)(带学习率γ)和上一次代价值构造评价单元的学习误差Ec(t),Z-1为Z的变换符号,将当前时刻的变量变换为前一时刻变量以便利用递推法则。
1.3 监督网络设计
在提出的SRL控制算法中有三种神经网络:行动单元网络、评价单元网络和监督单元网络。行动网络负责根据状态生成控制命令,利用评价网络来近似折现的总奖励,并对控制信号的性能进行评估。监督网络用于模拟驾驶员的行为,提供驾驶员的预测控制信号,指导行动网络和评价网络的更新训练。行动网络和评价网络均采用简单的三层前馈神经网络,其具体含义及公式化网络已经在[9-10]中介绍,本文为简化不再重复叙述。
驾驶员行为的建模可以采用参数模型,如智能驾驶员模型[11],也可以采用非参数模型,如高斯混合回归模型和人工神经网络模型。在文献[12]中,研究了一种基于神经网络的建模驾驶员行为的方法。在这一部分中,驾驶员的行为是由一个前馈神经网络建模的,它与行动网络的结构相同。收集真实场景主车人工驾驶跟随前车在路口减速停车时的驾驶员的操作数据及车辆状态,形成数据集D。使用数据集D= {e d(t),v r(t),a r(t),a des(t)}训练监督网络,可以根据给定状态[e d(t),v r(t),a r(t)]预测驾驶员的命令a des(t)。监督网络的权值通过预测误差的反向传播进行更新,并采用梯度下降的原则对网络进行训练,直到权值收敛。
需要注意的是,行动网络、监督网络和权重调节器生成一个用于主车辆的复合动作,公式如下所示:
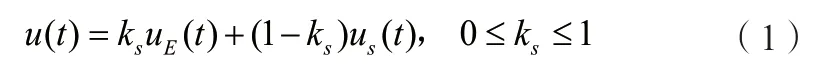
其中u s(t)在[1,1]范围内进行归一化处理;u E(t)是行动单元的探索行为,且u E(t)=u a(t)+N(0,σ),N(0,σ)表示均值0和方差σ的随机噪声。权重ks为行动网络和监督网络之间的控制比例。这个参数在监督学习过程中非常重要,因为它决定了驾驶员特性参与的自主程度,也决定了监督网络的指导强度。
2 基于并行监督强化学习的控制框架
本文所设计的上层控制模块学习过程,一方面包括先进行驾驶特性的离线学习以使其达到接近驾驶员行为特性,再进行行驶过程中的在线学习进行控制算法的迭代与优化。在离线学习过程中,为了能够充分利用计算机资源,且需要确保神经网络快速收敛并能够避免收敛于局部最优解,本文提出采用多路并行的学习方式,其完整的离线学习过程包括一个全局学习模块以及n个子训练模块,如图3所示。需要指出每个子训练模块与全局训练模块的结构相同,均为基本的行动-评价-监督网络单元。
在车载系统训练开始前,先根据控制器的计算资源确定子训练模块的数量,并初始化全局模块和各子模块的神经网络参数;之后,各子单元在其各自监督单元的引导下进行独立的训练,由于采用了系统多线程资源,确保各子单元的训练可以同时进行。当所有子单元的训练过程结束后将各子训练单元所获得的神经网络权值更新量上传到全局单元,此时全局单元根据各子单元的权值更新量来更新全局单元内的神经网络。由于全局单元直接获得了更有“倾向性”网络参数,有利于进行网络的收敛训练,在全局模块网络训练结束后,将更加优秀的网络参数下发到各子单元。此后,根据上述方式依次循环训练,当训练次数达到设定值或者全局单元的性能指标达到要求时停止训练,此时得到的神将网络参数即为离线学习的最终参数。该并行训练方式与传统串行训练方式相比,相同时间步长内的训练次数是其n倍,因此达到相同训练效果所用时间是其1/n,与此同时,由于网络随机探索,因此一次训练能够进行更多的网络探索行为,系统不容易收敛于局部最优,同时能够更好地利用计算平台的计算能力,达到更好的训练效果。
3 数据仿真与试验分析
3.1 个性化驾驶行为数据采集
为了建立满足驾驶员停车驾驶风格的监督网络,需要针对驾驶员跟车制动行为进行数据采集。现场测试中通过一辆改装的纯电动车辆进行驾驶数据的收集,车辆上配置了高精度定位导航仪,用于测量主车速度和加速度值,此外,安装了Mobieye摄像头与德尔福雷达融合的测距系统用于测量与前车的相对速度与距离,通信设备用于与前车交互获得前车加速度,改装车辆如图所示。

图4 用于驾驶员驾驶数据采集的车辆平台
挑选市中心合适的城市道路,确保司机在行程中穿过了许多交通灯控制的交叉路口,针对不同驾驶员,收集主车在跟踪前车到达路口并完成减速停车的完整行驶数据。图5统计了两种完全不同驾驶风格的驾驶员车辆距离与加速度图,图5(a)中的驾驶员跟踪前车到达路口进行减速停车的过程中,往往在较远的距离时便进行刹车减速,然后缓慢减速接近停车,而图5(b)中的驾驶员更倾向于稳定的驾驶到路口车辆近距离处,在进行急刹车确保车辆停止在目标车辆的后方。
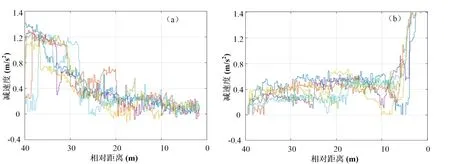
图5 不同驾驶风格的车辆制动减速度图
3.2 网络训练与数值仿真讨论
选用没有监督单元反馈的RL,SRL,以及并行SRL,分别针对图5(a)的驾驶数据进行网络训练,仿真中设置的车辆动力学行为模型如下:
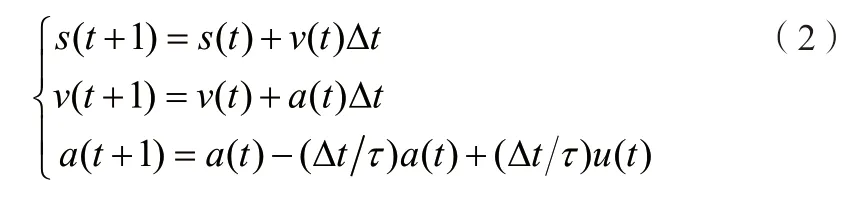
其中,s(t)表示车辆行驶的距离;a(t)表示经由下层执行器响应控制输入u(t)之后得到的车辆加速度;τ表示执行器的延时;此外,期望的车间距离d d(t)与速度v(t)成正比,即d d(t)=d0+hv(t),h为车间时距[13],可近似代表驾驶员的跟随驾驶风格。
设计一个包含最多1000个连续的训练周期试验。在试验结束时(试验次数小于1000次),如果主车能在期望的范围内与前一辆车保持稳定状态,则认为试验成功。作为对比,针对与并行SRL相同的训练过程,采用了没有监督单元的RL算法以及仅有一个单元体的SRL算法进行相同网络的训练。每个实验进行100次实验。如表1所示的训练结果表明,使用所提出的并行SRL算法,训练收敛过程总是成功的,且需要的试验比使用SRL和RL算法少很多。

表1 训练结果
进一步,为了分析并行SRL的所达到的拟人化效果,进行下述的对比试验:分别利用离线的监督网络以及完整并行监督强化学习网络并行网络控制相同的车辆仿真模型,图6展示了两种不同的控制效果。在上述实验中,监督网络近似作为人类驾驶员,从实验结果可以发现并行SRL网络的输出控制效果接近于人类驾驶员,且获得的加速度更为平滑,同时在一定消除了部分减速过程中的“颠簸”。

图6 并行监督强化学习的仿真控制效果
4 结束语
在本研究中,我们提出了一种基于并行SRL的框架,用于ACC/CACC系统的纵向车辆制动动力学控制。特别是通过引入真实驾驶数据搭建的监督单元,指导强化学习过程融入驾驶员的特性。其次并行学习的机制能够充分利用了计算资源以实现神经网络的在线与离线快速迭代,大大缩短了网络训练时间。通过数值仿真发现,该控制策略可以成功地模仿驾驶员的停车特征,从而提高驾驶员的舒适度并接受ACC/CACC系统。
