FACR:一种快速且准确的车辆识别器*
2021-01-14周龙王伟强吕科
周龙,王伟强†,吕科
(1 中国科学院大学计算机科学与技术学院, 北京 101408; 2 中国科学院大学工程科学学院, 北京 100049)
近年来,细粒度识别在计算机视觉领域受到广泛关注,包括识别鸟类[1]、花类[2]、车型[3-4]、犬种[5]等。由于车型具有独特的分层结构和大量的子类别,细粒度车辆识别成为一个具有挑战性的课题。不同于其他细粒度类别,车辆具有独特的分层结构[6],自顶向下分为4层,即汽车类型、生产商、汽车型号和生产年份,如图1所示。因此,分层分类对于识别车辆是一个很好的选择。不同于一般的图像识别,细粒度车辆识别目的是识别车辆更精细的子类别,由于细粒度类别存在细微的局部类间差异和巨大的类内方差[7],使得细粒度识别成为一项具有挑战性的任务。如图2所示,由于细微的局部类间差异和巨大的类内方差,传统的CNN方法将车辆识别错误,而本文方法(FACR, fast and accurate car recognizer)通过定位注意力区域,得到判别性特征,从而准确识别车辆。
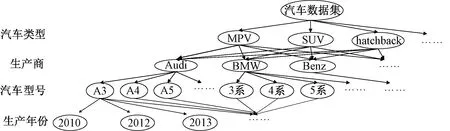
图1 汽车的分层结构Fig.1 The hierarchical structure of cars

图2 FACR与传统的CNN对比Fig.2 Comparison between FACR and traditional CNN
随着深度学习的成功,它在细粒度车辆识别领域得到应用,并且在判别性特征提取、局部注意力定位和细粒度分类等方面取得显著进展。文献[8]提出一种有效的深度卷积网络,用于从图像中提取判别性特征。文献[3]提出一个注意力候选网络(APN)用于定位注意力区域。虽然这种方法取得了很好的性能,但运行速度相对较慢。同时,文献[7]提出全卷积注意力网络(FCANs)用于细粒度识别任务,其中弱监督增强学习过程用于定位注意力区域。然而,当图像中存在多辆汽车时,这种方法注意力区域定位不够准确。另外,文献[2]和文献[9]利用与图像相关的文本注释帮助提升注意力区域定位的准确性,取得了很好的效果。但是额外的局部位置或文本注释等监督信息往往很难大量地获取到。大多数的细粒度车型识别方法使用单个softmax预测所有的类别,如图3(a)所示,但是这种方法不适用于细粒度车辆识别。因为类别之间不是互斥关系,不满足softmax操作的前提假设。文献[10]建立WordTree用于分层分类,其中多个softmax操作在不同层次上进行计算,如图3(b)所示,这为细粒度分类提供了一个全新的思路。
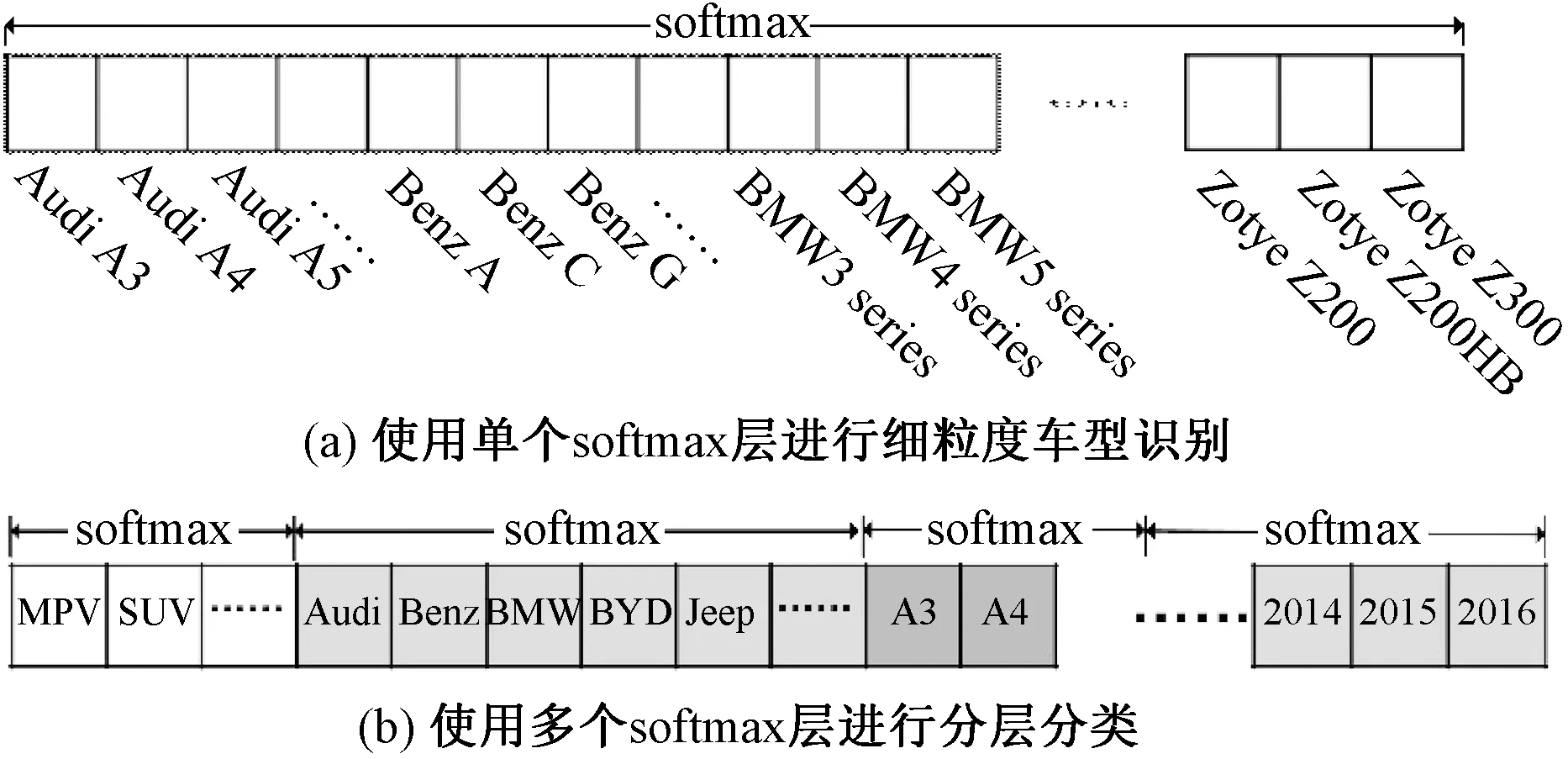
图3 两种细粒度分类对比Fig.3 Comparison between two fine-grained classifications
与现存工作相比,本文提出一种快速且准确的车辆识别器FACR用于细粒度车辆识别。FACR能有效地从粗粒度到细粒度学习判别性注意力区域和基于区域的特征表示,并且不需要额外的局部或文本作为监督信息。此外,FACR重复使用粗粒度特征图生成细粒度特征图,这使得训练和预测过程变得更高效。
1 本文提出的方法
如图4所示,本文提出的FACR包含3个组件:特征图生成组件、注意力区域定位组件(attention region localization component, ARC)和分层分类组件(hierarchical classification component, HCC)。首先,深度卷积神经网络从给定的图像中提取判别性特征图。然后区域回归器和局部估计器用于定位注意力区域,其中区域回归器预测车辆的位置(红色),特征图上对应的位置裁剪并归一化作为局部估计器的输入,局部估计器输出车辆的局部位置(黄色),归一化后的特征图以相似的方式获得。最后,3种尺度(图像、车辆、局部)的特征图输入分层分类组件进行细粒度分类。
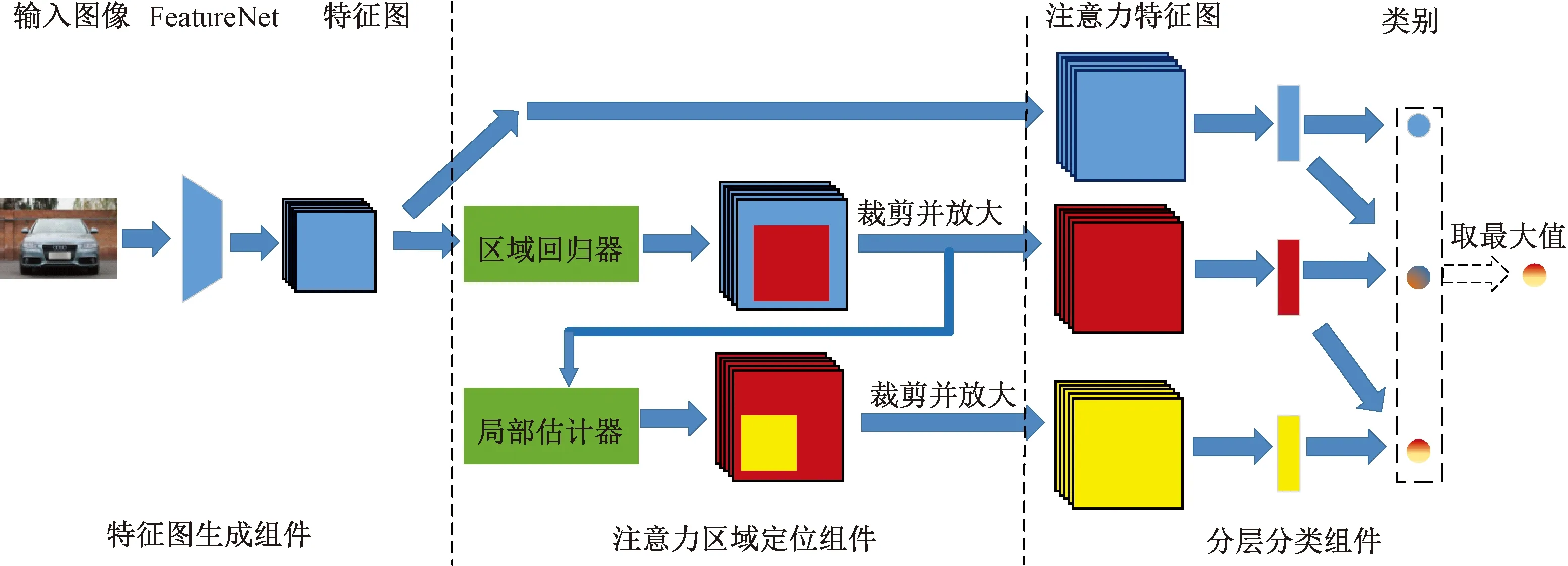
图4 FACR的框架结构Fig.4 Architecture of FACR framework
1.1 特征图生成组件
现存方法通常采用较为流行的CNN架构[8-11](例如,VGG-16,ResNet-50)生成多尺度特征图。本文设计了一个新的深度卷积神经网络,命名为FeatureNet,并在ImageNet数据集[12]上进行预训练,在细粒度车辆数据集上进行微调。类似于YOLOv3模型[13],使用步长为2的卷积层替代池化层,以避免特征信息丢失过多。图5(a)显示FeatureNet中残差模块的结构,其中M和N分别表示输入输出的通道数。标识为CONV.的矩形框表示卷积层,卷积核大小为K×K,步长为S,
给定一张输入图像X,首先将大小归一化到512×512,然后送入FeatureNet生成通道数为1 024、大小为16×16的特征图。整个计算过程可公式化为φ0=f(X;Wc),其中Wc表示FeatureNet里所有的参数,f(·)表示函数映射,φ0表示FeatureNet的输出。
1.2 注意力区域定位组件
注意力区域定位组件ARC包括两个计算步骤。首先,训练区域回归器定位车辆的注意力区域,然后局部估计器进一步估计潜在的局部注意力区域。区域回归器由两个堆叠的全连接层组成,局部估计器由1个通道数为1、卷积核大小为3×3的卷积层和1个softmax层组成。
特征图φ0送入网络中的区域回归器,能够得到车辆注意力区域的预测结果。车辆注意力区域由一个四维向量t=(xr,yr,wr,hr)表示,即
t=g(φ0;Wr).
(1)
其中:(xr,yr)表示车辆注意力区域左上角点的坐标,(wr,hr)表示车辆注意力区域的宽度和高度,g(·)表示区域回归器里的函数映射,Wr表示区域回归器里的所有参数。在特征图φ0上对应t的位置进行裁剪,并使用双线性插值的方式放大到与φ0同样大小。最终,得到通道数为1 024、大小为16×16的车辆注意力特征图,用φ1表示。
局部估计器以车辆注意力特征图φ1作为输入,经过通道数为1、卷积核大小为3×3的卷积层,将φ1转换为通道数为1、大小为16×16的置信度图。然后置信度图经过一个softmax操作,进一步转换为概率图。最终,在概率图上找到一个大小为8×8且概率和最大的区域,将其定义为局部注意力区域,用p=(xp,yp,wp,hp)表示,即
p=h(φ1;Wp).
(2)
其中:(xp,yp)表示局部注意力区域左上角点的坐标,(wp,hp)表示局部注意力区域的宽度和高度,h(·)表示局部估计器里的函数映射,Wp表示局部估计器里的所有参数。在特征图φ1上对应p的位置进行裁剪,并使用双线性插值的方式放大到与φ1同样大小。最终,得到通道数为1 024、大小为16×16的车辆注意力特征图,用φ2表示。
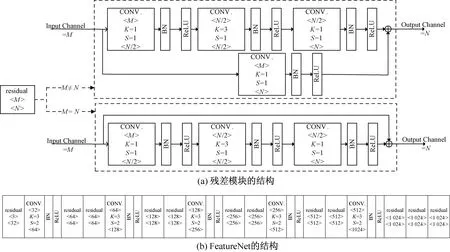
图5 FACR的特征图生成组件Fig.5 The feature-map generation component of FACR
虽然本文中只使用了一个局部估计器,但是多个局部估计器能以相似的方式堆叠和计算,得到更多不同大小和尺度的局部注意力特征图φk,k=3,4,…。譬如,在概率图上选取一个大小为4×4且概率和最大的区域,这样就能得到不同大小的局部注意力特征图,多个局部注意力特征图可并行计算,增加的耗时可忽略不计。
1.3 分层分类组件
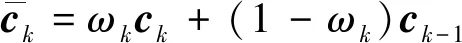
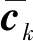
P(Tk,Fk,Mk,Yk)=
(3)
通过上述计算,在不同尺度上得到分类预测值Tk,Fk,Mk,Yk。最终的分类结果通过公式q=argmaxkP(Tk,Fk,Mk,Yk)计算得到。这就意味着FACR最终的输出为[Tq,Fq,Mq,Yq]。
1.4 损失函数
FACR训练的过程中,损失函数定义为L=Lc+λLa,其中Lc和La分别表示分层分类损失和注意力区域定位损失,λ是两种损失之间的平衡因子,在本文实验中,λ=1。

2 实验
为验证本文提出的FACR的性能,在两个公开的细粒度汽车数据集(Compcars[6]和Stanford Cars[14])上进行了评估实验。这两个数据集的相关信息总结在表1中。
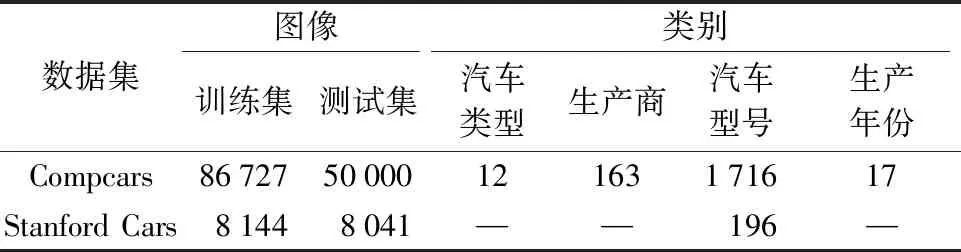
表1 数据集的相关信息Table 1 Related information of datasets
训练过程中,FACR使用ADAM优化算法,批大小设置为32。初始化学习率为0.01,每处理20 000批,学习率乘以0.1,直到学习率为10-4为止。网络模型的训练直到损失收敛为止。
2.1 模型分析
1.1小节,具体介绍了FACR采用的网络结构FeatureNet,它与DarkNet[13]的结构存在很大区别。首先网络层数不同,DarkNet-53有53个卷积层,而FeatureNet有12个残差模块,共36个卷积层;其次网络基础模块不同,DarkNet网络结构中基础模块是卷积层,而FeatureNet的基础模块是残差模块,残差模块的优点在于加速网络收敛,能够有效地减弱深层神经网络结构中梯度消失的影响。虽然DarkNet-53中有Residual结构,但这仅仅是跨层连接操作,其与相邻的卷积层结合构成的模块,也与本文中的残差模块结构不同。因此FeatureNet与DarkNet结构不同。
2.2 计算效率
在工作站上进行实验,评估FACR与现存方法的计算效率。工作站的配置为单个Titan Xp GPU 和Intel(R) Xeon(R) CPU E5-1603 v4@2.80 GHz。处理Stanford Cars数据集中的所有图像,并计算平均时间,实验结果总结在表2中。可以看出FACR分类速度达10.80 fps,有着更高的计算效率。另外,将FACR中的FeatureNet替换为Resnet50,命名为Resnet50+ARC+HCC,其中ARC表示注意力区域定位组件,HCC表示分层分类组件。与FCANs[7]中提取图像特征图的网络架构保持一致,Resnet50+ARC+HCC仍然比现存方法[3,7,15]有更高的计算效率。
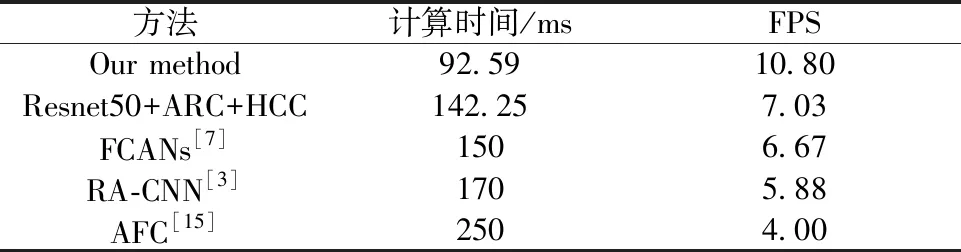
表2 计算效率对比Table 2 Comparison of computational efficiency
2.3 定量结果对比
为了评估FACR方法进行细粒度识别的准确度,在公开可用的数据集(Stanford Cars和Compcars)上进行了对比实验,FACR与现存方法的定量结果对比见表3、表4和表5。
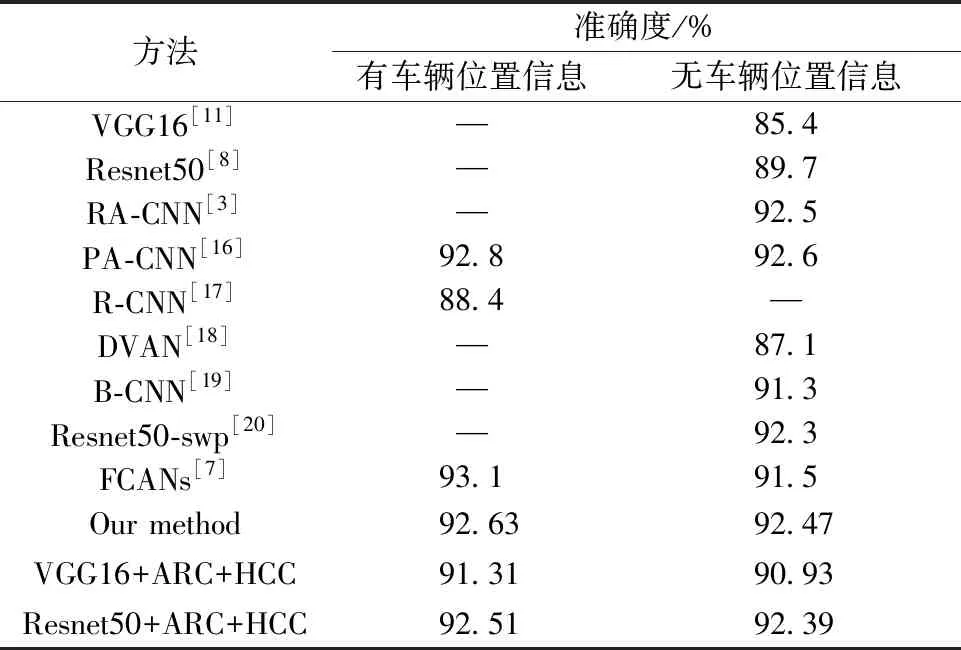
表3 Stanford Cars对比结果Table 3 Comparison of the results on Stanford Cars
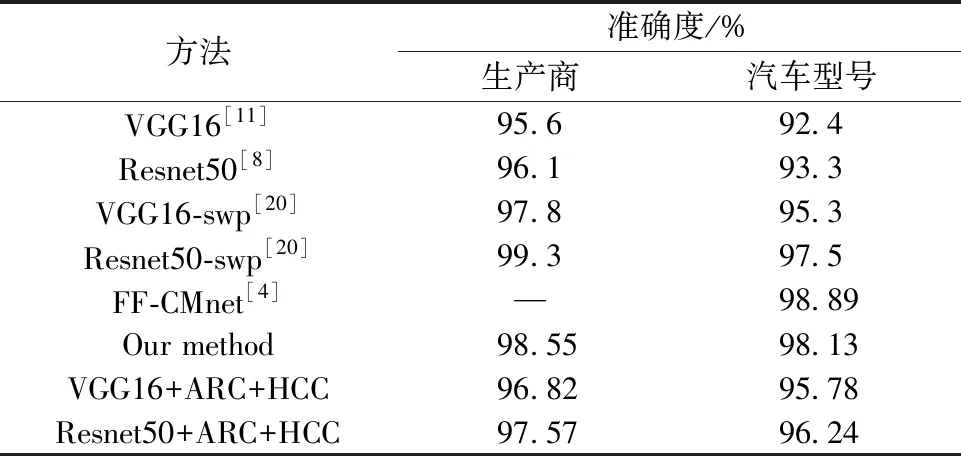
表4 Compcars对比结果Table 4 Comparison of the results on Compcars

表5 分层分类结果Table 5 Results of hierarchical classification
Stanford cars数据集提供的汽车类别之间互斥,因此FACR使用单个softmax操作,直接输出分类结果,而没有采用分层分类。在本实验中,根据输入是否有车辆位置信息分为两种输入模式。若有车辆位置信息,则将图像中车辆区域裁剪后作为输入;否则整个图像作为输入。表3显示,与现存方法相比,FACR有较高的准确度。有、无车辆位置信息两种情况下,FACR仅比PA-CNN准确度稍低。
在表3中,可以看出输入图像是否有车辆位置信息,对FACR不会产生太大的影响,而FCANs在没有车辆位置信息的情况下,性能降低1.6个百分点。原因在于FACR中的区域回归器会对图像中的车辆进行定位,局部估计器进一步在车辆区域提取注意力特征,而FCANs是直接在原图上提取注意力特征,会受到背景车辆的干扰。
表4显示,在Compcars数据集上与现存方法相比,只在生产商层次上,FACR比Resnet50-swp准确度低,但是在汽车型号层次上的准确度比它高。另外,在汽车型号层次上,FACR比FF-CMnet准确度稍低。因此,在单个层次上进行细粒度车辆识别,FACR具有良好的性能。
在Compcars数据集上,虽然FACR的识别精度并不是最优,但是它可使用单个网络同时识别汽车类型、生产商、汽车型号和生产年份,如表5所示。而其他方法,只对汽车一部分信息进行识别。如表4所示,FF-CMnet方法只对汽车型号进行识别,Resnet50-swp方法只对生产商或者汽车型号进行识别。相比于这些方法,FACR更加完善。
此外,Compcars数据集提供了更多的类别信息,包括汽车类型、生产商、型号和生产年份,而汽车类别与生产商之间不互斥,因此FACR使用分层分类的方法进行细粒度车辆识别。表5显示,FACR在4个细粒度层次上分类实现了94.47%的准确度,而其他方法并没有在数据集上进行此方面的工作。
2.4 消融实验
为了探究FACR定位到的车辆区域注意力特征和局部注意力特征对细粒度车型识别结果的影响,在Stanford Cars和Compcars数据集上设计了几组消融实验。其中√表示使用该类特征,“区域”指的是车辆区域的注意力特征,“局部”指局部注意力特征。在Stanford Cars数据集上进行实验时,输入图像不带有车辆位置信息,这样能更好地验证区域注意力特征的有效性。在Compcars数据集进行实验时,使用分层分类的方法进行细粒度车辆识别,如表6所示。
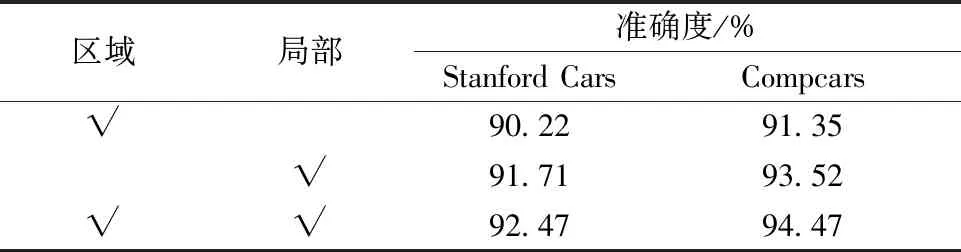
表6 消融实验Table 6 Ablation experiment
表6显示,同时使用区域注意力特征和局部注意力特征用于细粒度车型识别,相比于只使用区域注意力特征或只使用局部注意力特征,识别性能均有提升。
2.5 定性结果对比
为了对比FACR与FCANs注意力特征定位的性能,在Stanford Cars数据集上进行了相应的对比实验。图6显示几组样例图像的对比结果,其中红色的矩形框表示FACR定位的车辆区域注意力特征,黄色的矩形框表示FACR定位的车辆局部注意力特征。蓝色和白色的矩形框表示FCANs定位的多个局部注意力特征。

图6 FACR与FCANs定性对比Fig.6 Qualitative comparison between FACR and FCANs
从图6(a)可以看出,当输入图像带有车辆位置信息时,FACR的结果(红色和黄色标记的矩形框)和FCANs的结果(蓝色和白色标记的矩形框)都能定位到车辆注意力特征。从图6(b)可以看出,当输入图像没有车辆位置信息时,FACR的结果总能定位在目标车辆上,而FCANs的结果会因为背景里存在干扰车辆而不准确。说明FACR对背景噪声更鲁棒。
对比图6(a)和6(b)实验结果,可以看出,FACR在两种输入模式下,定位到的注意力区域,基本一致。而FCANs方法在不同输入模式下,定位到的注意力区域,有明显差异。当输入不带车辆位置信息时,更容易受背景车辆的干扰。
3 总结和展望
本文提出一种快速且准确的细粒度车辆识别器FACR。通过准确地定位注意力区域和使用层次分类方法,构建单个网络来实现复杂的细粒度车辆识别。在标准数据集Stanford Cars和Compcars上的实验结果表明,与现有方法相比,FACR方法有较高的计算效率和准确度。
