频域宽带波束形成GPU并行加速
2021-01-13张德泽范威
张德泽 范威
(水声对抗技术重点实验室,上海,201108)
宽带信号的广泛应用与阵列规模的扩大使得水声信号处理中的数据量不断增加,高效计算问题逐渐成为制约水声信号处理发展的关键技术难题之一。阵列信号的波束形成算法就是其中典型的大规模计算问题,多基元阵列信号数据量巨大,计算复杂的特点使其很难在常规 CPU平台上实现高效处理,而采用DSP元件的信号处理机等设备虽然满足计算资源需求,但却具有成本高昂,开发难度较大,升级困难等缺点[1]。GPU是一种高效的通用平台并行计算协处理器,利用 GPU并行计算加速水声信号的处理是当前的研究热点之一。相对于 DSP或FPGA,GPU平台具有通用性强、易开发和易升级等优势,且可与CPU形成异构计算,进一步提升数据处理效率[2]。本文基于NVIDIA公司生产的GPU平台与CUDA编程模型,实现了线阵信号的频域宽带波束形成算法。
1 频域宽带波束形成
波束形成的主要功能是对信号进行空域滤波,提高信号的信噪比,估计信号方位[3]。在时域上,波束形成算法是一种卷积运算,根据线性系统理论,可将其转化到频域变为乘积运算。图1为频域宽带波束形成算法原理[4]。
设各阵元原始输入信号为[x1(t),x2(t),…xN(t)],其中N为阵元数。算法第一步采用傅里叶变换将各阵元的时域信号转换到频域,得到信号频率分量:
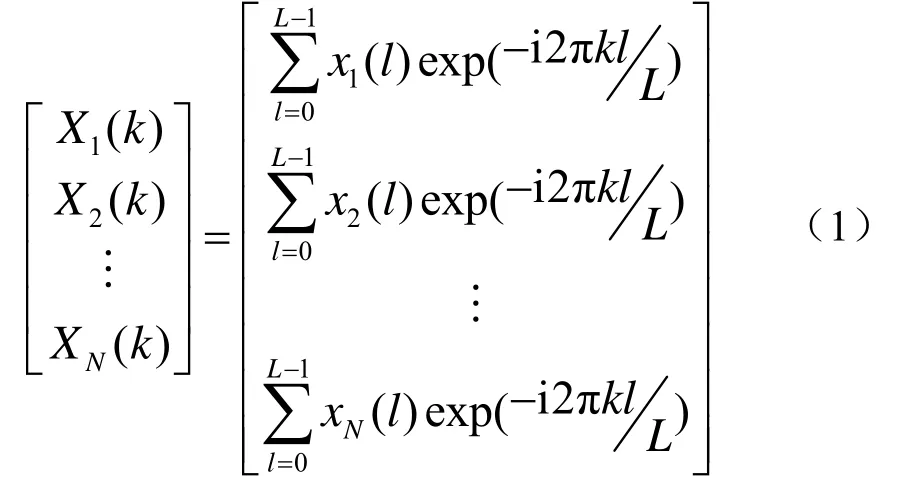
式中,k为频域数据点,k=0,… ,L- 1,l为时域数据点,L为每段数据总点数。
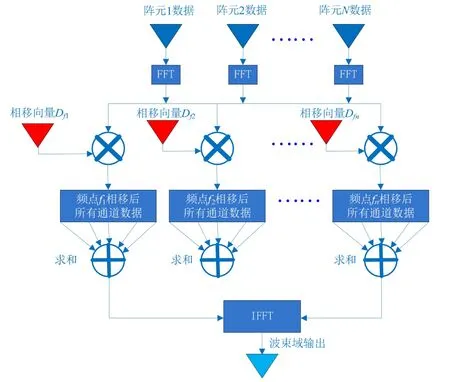
图1 频域宽带波束形成
随后计算阵列信号在各方位角和各频点处的相位偏移矩阵。对于线阵而言,其在频率点k、方位角θi处的相位偏移为
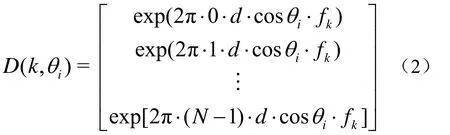
式中,N为阵元总数,d为布阵间隔,fk为第k个频点所对应的频率。设波束总数为M,则波束域频域数据为
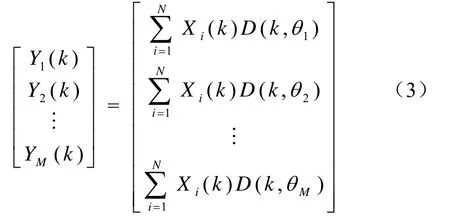
式中,L为数据长度。得到波束域频域数据后,再对其进行傅里叶逆变换,即可得到波束形成结果。
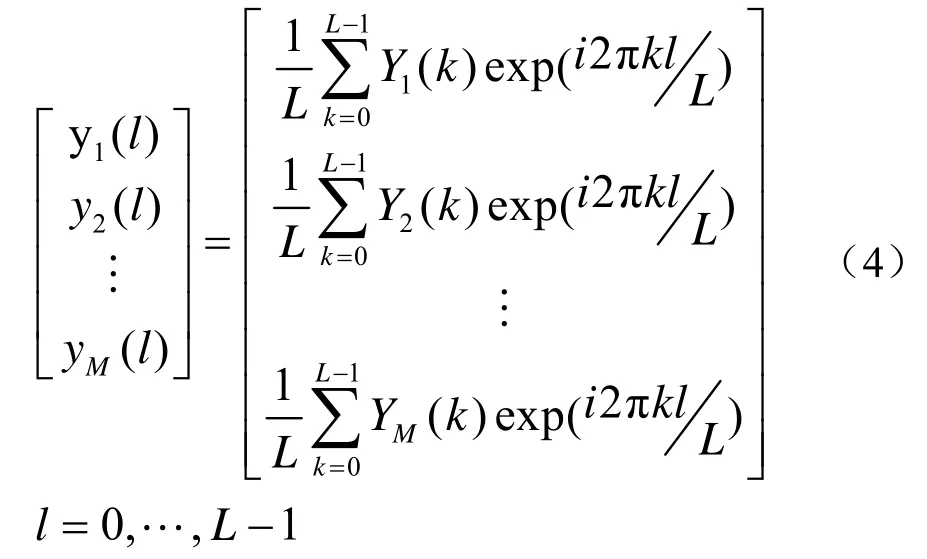
从算法原理中可以看到,宽带波束形成算法中主要的步骤是对各阵元的信号在各个方位角和频点上进行相移,这一步运算涉及方位角与频率的两重循环,是最主要的计算开销,使该部分运算并行化是提高算法效率的关键。
2 CUDA模型与波束形成并行化
2.1 CUDA编程模型
GPU作为一种多核心协处理器,在大规模计算方面展现出了优异的性能。从NVIDIA公司发布第一款 GPU以来,其一直保持着很高的发展速度。当前其浮点运算性能已经远超多路CPU系统,是密集型大规模数据计算的首选[5]。NVIDIA GPU的编程开发环境为CUDA,支持C、C++、Fortran等多种编程语言。其编程模型如图2所示。
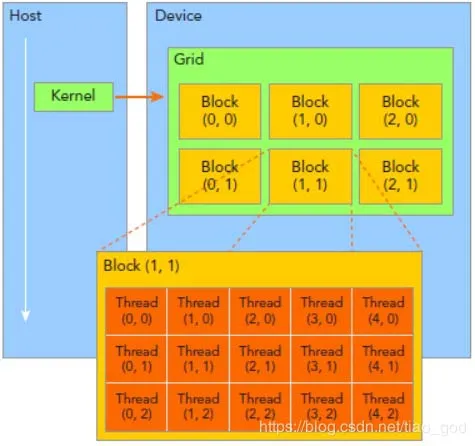
图2 CUDA 线程模型
图2中,CPU端为Host,GPU端为device。在GPU上运行的函数为kernel函数,每一个kernel函数对应一个 grid,每个 grid中包含了一定数量的block,每个block中包含一定数量的thread,数量大小可自行设置。每个block与thread在程序中均有对应编号。程序运行时,每一个thread按照kernel函数的指令运行相同的步骤,完成并行运算。每一个thread在硬件端对应GPU中的一个流处理器。GPU中包含上千个流处理器,因此可迅速完成大规模的数据计算。
2.2 波束形成并行化
宽带波束形成的主要计算开销在于频率点和角度点的循环。而 GPU可将循环并行化,大幅缩短计算时间。图3展示了波束形成并行化的原理。设波束形成计算中的计算频点共L个,计算时开启L个block,图3显示的是第k个block中的计算过程。每个block中包含N个thread,与阵元数一致。波束总数共M个,从θ1到θM。Data(n,k)为第n个阵元在频点k的频域数据,n=1-N,k=1-L。D(n,θi,k)为第n个阵元在θi方位向和频点k处的相移,i= 1-M。
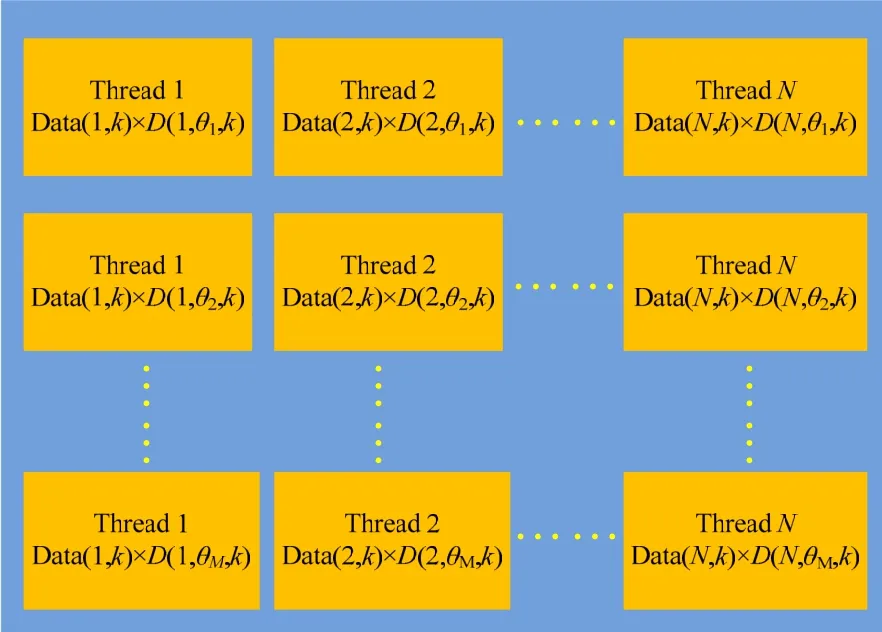
图3 波束形成并行化
并行化的波束形成算法中,每一个block负责计算每个频点的各通道数据相移,block中的所有thread负责计算每个通道数据点与相移量的内积。根据频点的数量设置block的数量,可同时对所有频点数据进行计算。而在block内部,每次可对一个方位角上的所有阵元数据进行相移并归约求和。这样就可将算法中方位、频点、阵元的三重循环减少为仅方位上的单层循环,大幅提高计算效率。数据的傅里叶变换可采用CUDA中的cuFFT库进行[6]。
3 仿真测试
测试采用仿真数据,分别计算在不同数据长度的情况下,宽带常规频域波束形成在 CPU串行程序、CPU并行程序、GPU单block并行程序与GPU多block并行程序中的时间开销。仿真数据采样率为4096 Hz,波束形成处理带宽为10 Hz~1 kHz,阵列为128元线阵。测试平台CPU为双路Intel Xeon Gold 6136,共计24核48线程。GPU为NVIDIA Quadro RTX 5000。图4与表1为各程序在不同信号长度下的运行时间对比,其中 CPU程序在 Matlab R2019下运行,GPU程序在Visual Studio 2013下运行。
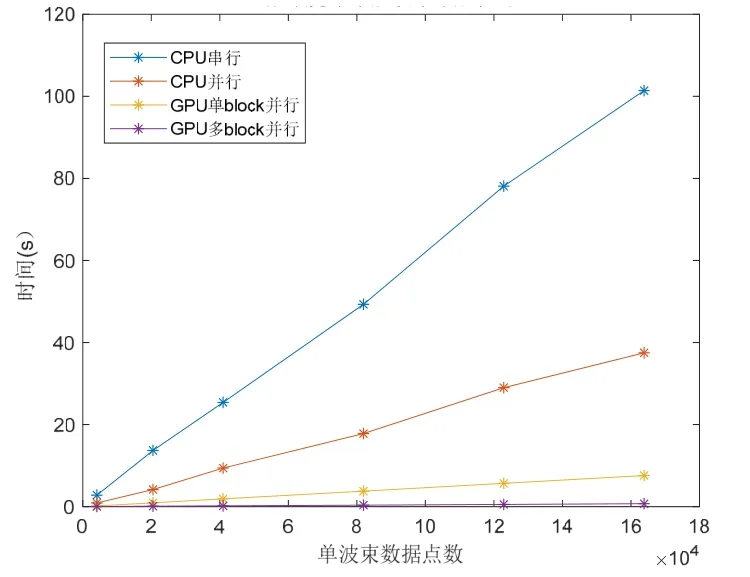
图4 波束形成耗时曲线
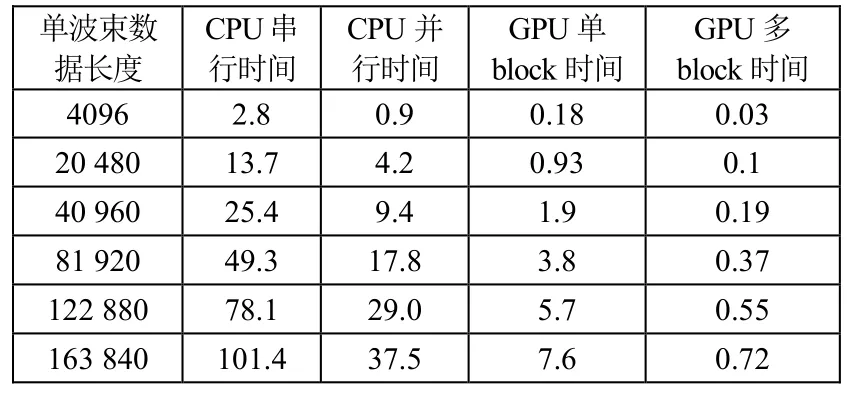
表1 波束形成算法耗时 s
从图4与表1中可以看到,并行化对波束形成算法的计算效率提升巨大。CPU并行的效率约为其串行的3倍。而GPU平台得益于其巨大的核心数量,效率远优于CPU平台。在仅开启一个block、128个thread的情况下,其计算效率为CPU并行的5~6倍。而在开启多个block,对频点进行并行运算时,效率得到了进一步提升,最大可达到CPU并行的50倍
从表中数据还能看到,GPU运算的效率提升随着数据长度的增加而越发明显。这证明,GPU平台对于大规模数据计算具有极大的优势。因此,在保证显存空间足够的条件下,GPU可显著提高阵列信号波束形成的计算速度,且开启的核心越多,数据量越大,加速效果越好。而在数据量较小时,GPU程序的数据传输时间开销相对较大,因此效率提升程度有所下降。
4 总结
本文基于CUDA编程,在GPU平台上实现了频域宽带波束形成算法的并行化,其计算效率相对于 CPU平台有显著提升,在数据量较大时,在本文所述硬件配置下其效率最高可达到 CPU并行计算的50倍。GPU平台相对于DSP和FPGA,具有低成本、易开发、易升级等多种优势,适合作为小型化的信号处理平台。后续工作将针对自适应波束形成等高分辨波束形成算法的并行化展开,进一步提高算法的效率及精度。
