基于xgboost模型的消费者信用评级系统
2021-01-13王明月张青云李晓会
史 伟,王明月,张青云,李晓会
基于xgboost模型的消费者信用评级系统
史 伟,王明月,张青云,李晓会
(辽宁工业大学 电子与信息工程学院,辽宁 锦州 121001)
设计了一种基于xgboost模型的消费者信用评级系统,通过人脸识别方法选出一部分特征作为消费者标签,量化消费者信息,以此叙述消费者形象;对-means聚类进行改进,提出了基于核密度的人脸识别聚类算法,将消费者分成不同的类别,据此完成信用评级。系统能够缓解噪声点敏感,使原始中心点选择更加简单,并且较少使用银行交易记录,具有较高的可用性。
xgboost模型;信用评级;消费者画像;聚类算法
目前,人工智能技术[1]的快速发展,使其再次成为国内外学者的研究热点,而人脸识别技术是最受关注的应用之一,甚至对金融行业也产生了积极的影响。随着人脸识别等技术的不断应用,也对金融行业的风险保护问题提出了挑战,例如借贷过程中可能存在的欺诈现象,需要对消费者的信用进行评级,进而控制风险。因此,建立一种安全、准确的消费者信用评级系统是非常必要的。
信用评级[2]是指利用消费者的个人基本信息以及信贷信息进行分析,得出消费者的信用等级,进而判断消费者是否有能力接受借贷服务,接受哪个等级的借贷服务,以及违约的风险和损失等级。
有很多传统的信用评级模型,例如FICO[3]通过统计分析原始数据来建立数学模型,预测消费者的信用评级,但是缺少正确数据的存储,还不适用于处理企业信贷问题;David Durand提出了判别分析法[4],通过对原始样本的规律建立函数,实现对大量的原始数据的有效分类,具有较高的精确度和效率,然而得出的结果缺少经济方面的意义;第十二届全国人大三次会议中,李克强总理第一次提出了“互联网+”[5]计划,促进新兴技术和传统行业的融合发展,特别是金融行业,我国互联网金融行业随着余额宝等理财产品的产生而快速发展。
由上述分析可以看出,传统的风险评级方法都存在着一定的缺陷。因此,本文提出了一种消费者信用评级系统,基本步骤如下。
(1)利用人脸识别技术获取消费者信息,在Hadoop分布式平台利用MapReduce分布式架构、HDFS分布式文件系统和xgboost回归法描绘消费者的形象。
(2)利用核密度人脸识别聚类算法将消费者分成不同的等级,对其进行分析,以达到金融风险控制的目的。
1 消费者画像构建
消费者画像构建是指建立标签体系[6],在Hadoop分布式平台[7]利用xgboost回归法[8]将消费者原始标签信息定量化,利用HDFS分布式文件系统[9]存储、MapReduce分布式架构[10]计算消费者数据,进而描述消费者画像,便于计算机处理,消费者画像广泛应用于金融领域,可以找出适应需求的消费者或者生产出适合消费者的产品。消费者画像形成过程如图1所示。
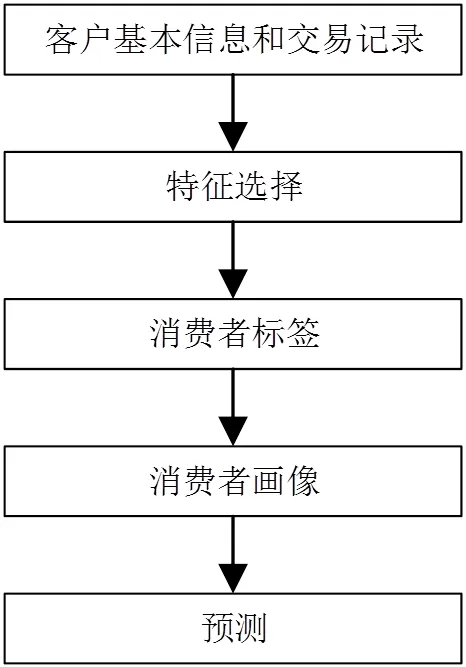
图1 消费者画像
构建消费者画像的详细步骤如下。
(1)建立标签体系[11]。标签体系是用于描述消费者画像,首先通过对消费者依次进行人脸检测、图像预处理、特征提取和人脸识别[12]得到消费者的具体信息,选出有代表性的特征数据,即为标签数据,通过标签来对消费者的特点进行描述,即产生正确的消费者标签,建立标签体系,每个消费者都具有自己的特征标签,分析每个特征标签,根据消费者所在的群体可以得出其独有的特征,分析可得消费者的违约风险等信息。
(2)定量化消费者数据。消费者标签信息属于定性化数据,因此需要对其进行定量化以便后续计算,xgboost回归法可以实现此操作。xgboost回归法是指任一样本根据某个特征值进行分裂,每次分裂形成1棵树,添加1棵树的实质是机器学习1个特征标签,每一棵树都被学习之后,通过样本中叶子结点(即经过机器学习的所有树)的分数对特征进行转换,直到每个特征转换成数值型数据,以提高相似性计算的效率。
(3)形成消费者画像。Hadoop分布式平台即分布式系统的基础架构,由Apache基金会开发,实现了MapReduce分布式架构和HDFS分布式文件系统。转换之后的消费者数据利用HDFS来存储,在大数据环境下,利用1台计算机不能对数据进行有效存储,需要多台计算机对其存储,提高了成本,但是HDFS可以同时处理全部文件数据。然后利用MapReduce分布式架构对数据进行计算,其处理模块是自定义的,解决了某些架构不能修改错误模块而创建补丁导致后续操作可能存在问题的缺陷。MapReduce由Map和Reduce函数构成。原理图如图2所示。
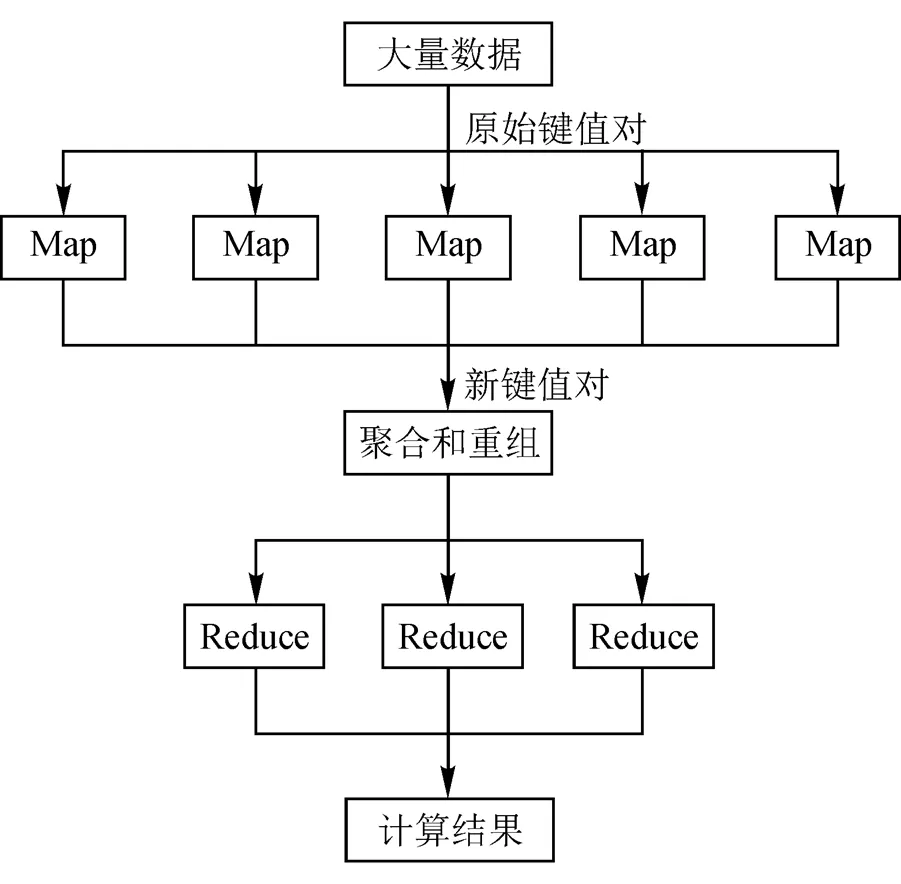
图2 MapReduce原理图
2 聚类算法研究
聚类通过训练样本的全部数据来得出其规律。
2.1 k-means聚类
-means聚类[13-14]随机选择个初始点作为每个簇的中心,遍历数据集的全部数据,计算每个数据之间的距离,将距离较近的数据放在一组,即为1个簇,簇的中心会连续更新,最终达到全部数据到中心的距离最小或某个阈值。-means将距离作为样本分类的标准,数据间的距离越近说明越相似,数据间的距离越远说明差异越大。
样本相似性[15]的判别方法是距离长短,距离可以通过3种方式度量。
(1)闵科夫斯基距离:点与点的真实距离:
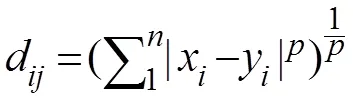
(2)马氏距离:数据之间的协方差距离,考虑样本特征间的关系。
(3)夹角余弦:通过夹角的余弦值得出相似性。
(4)相关系数:
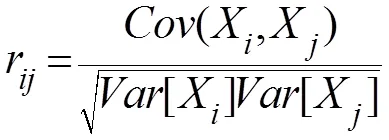
判断特征之间的线性关系。
-means具有操作简单和效率高等优点,然而也存在一些缺陷:(1)需要预先知道分类个数,实际上很不容易实现;(2)对孤立点过于敏感,可能会造成局部最优;(3)每个簇初始点的选择不确定,导致结果不一定最优。
2.2 基于核密度的人脸识别聚类
核密度估计[16]是非参数估计方法,基于核密度的人脸识别聚类算法是对-means聚类算法的改进,可以解决以上问题,首先在预先不知道数据分布的情况下得出近似的概率密度函数,以得到数据分布的特征,可以使用这种方法选取核密度极大值作为初始点,然后再进行-means聚类算法。
基于核密度的聚类算法基本步骤为:(1)遍历一次数据集得出核密度估计结果;(2)计算出节点的值和聚类的初始点;(3)进行-means聚类算法。
算法的基本思想是:首先对节点进行聚类,设均值向量为聚类的初始点集合,分别计算其余样本值与初始点的欧氏距离,与初始值距离最小的样本归入到该簇中,循环迭代直到全部样本都归入到对应的簇中(算法1第1~11行);还需要额外考虑一种数据,即有些样本数据是噪点但被分到簇中,设Ni为任意样本,如果A和B的距离半径不大于A和Ni的距离,则Ni即为噪点,除去噪点形成新的簇(算法1第12~22行)。聚类的伪代码如下:
算法1 聚类算法
输入:初始样本A
输出:聚类合并结果O”={O1,O2,…,Om}
1: A.forEach(function(value,index,array))
2: 均值向量为μ={μ1,μ2,…,μm}
3: Oj’=Ø(1≤j≤m)
4: for(j=1;j≤m;j++){
5: for(i=1;i≤n;i++){
6: dij=||xi-μj||2;
7: θi=min dij;
8: Oθi’=Oθi’∪{xi};
9: }
10: }
11: return O’={O1’,O2’,…,Om’};
12: While(O’!=Null)
13: OA”=Next(O’);
14: ZDA=GetPoints(OA”);
15: OB”=Next(O’);
16: ZDB=GetPoints(OB”);
17: do
18: if(Zr(DA,DB) <= distance(DA,Ni))
19: O”=sub(Ni);
20: End
21: until 所有样本比较完毕
22: return O”;
23: End
3 系统分析
系统硬件环境采用Intel(R) Core(TM) i3-3240 CPU@3.40 GHz处理器,4 GB内存,500 G硬盘;软件环境采用Windows10操作系统和pycharm开发平台。
首先根据人脸识别获取消费者特征,将消费者特征转换为对应的标签,便于处理,再对消费者分配,利用标签并在Hadoop分布式平台上,采用HDFS分布式文件系统存储消费者的数据,MapReduce分布式架构计算消费者的数据,利用xgboost回归法使机器能够学习消费者的数据,分析其数据可以得出消费者的特征,以此来描绘消费者画像。然后根据基于核密度的人脸识别聚类算法将所有消费者进行等级划分,实现金融风险的控制。
将消费者数据分别进行-means聚类和基于核密度的人脸识别聚类,2种方法的聚类结果都形成5个簇,即将消费者分为5个等级,如图3和图4所示。进行对比可以得出基于核密度的分布式聚类有较高的准确率,噪声点较少,簇内更紧密,簇间差距更显著。
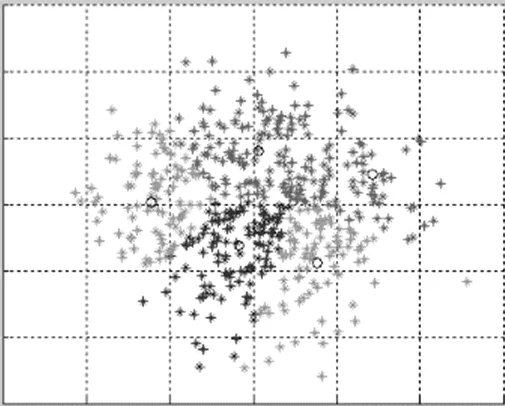
图3 k-means聚类结果图

图4 基于核密度的人脸识别聚类结果图
从数据中取出5组数据量不同的数据,2种方法所需时间如图5所示。可以得出数据量越大基于核密度的人脸识别聚类所需时间与-means相差越大,因此在数据量大的情况下,优先使用基于核密度的人脸识别聚类方法。
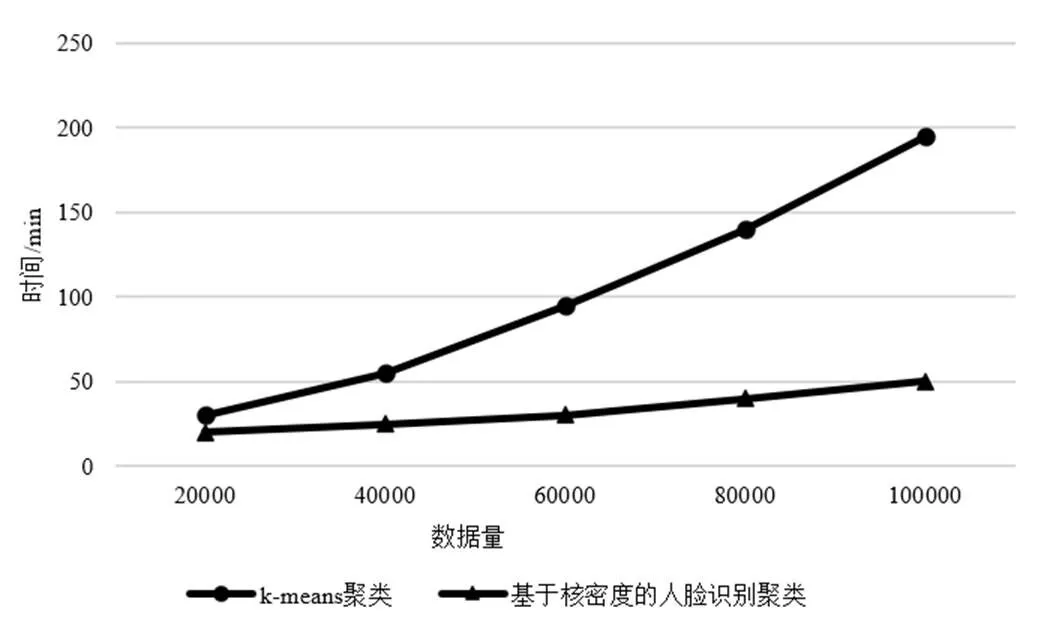
图5 聚类效率对比图
4 结束语
基于xgboost模型的消费者信用评级方法解决了传统评级系统较多的使用消费者银行交易记录的缺陷,提高了聚类算法的效率和精确度,并且如果采用具有更快CPU和更大内存的计算机,还可以继续提高聚类效率。本文给出了基于xgboost模型的消费者信用评级系统的开发流程,建立消费者画像和消费者分类的关键技术,以及消费者的信用评级对控制金融风险具有的重要意义。
[1] 董建文. 人工智能时代互联网金融信息安全风险及防范[J]. 科技与金融, 2019(11): 60-63.
[2] Brendan Daley, Brett Green, Victoria Vanasco. Securitization, Ratings, and Credit Supply[J]. The Journal of Finance, 2020, 75(2): 17-26.
[3] 姜琳. 美国FICO评分系统述评[J]. 商业研究, 2006(20): 81-84.
[4] 石勇, 孟凡. 信用评分基本理论及其应用[J]. 大数据, 2017, 3(1): 19-26.
[5]李克强主持召开国务院常务会议 通过《“互联网+”行动指导意见》 用“互联网+”助推经济发展[J]. 决策探索: 上半月, 2015(7): 4.
[6] 高广尚. 用户画像构建方法研究综述[J]. 数据分析与知识发现, 2019, 3(3): 25-35.
[7] 孙超. 基于Hadoop平台的机器学习聚类算法研究[D]. 西安: 西安电子科技大学, 2018.
[8] Chen T, Guestrin C. XGBoost: A Scalable Tree Boosting System[C]. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, 16(8):13-17.
[9] 王大志. 基于HDFS的跨集群分布式文件系统研究[J].信息技术与信息化, 2019(8): 229-230.
[10] 林丹楠, 黄锐. 大数据挖掘中的MapReduce并行聚类优化算法研究[J]. 太原师范学院学报: 自然科学版, 2019, 18(4): 49-53.
[11] 商丽媛. 基于用户画像的中小企业营销策略研究[J]. 科技经济市场, 2019(11): 155-156.
[12] 崔庆华. 基于局部特征分析的人脸识别方法[J]. 计算机产品与流通, 2020(4): 140.
[13] Hartigan J A, Wong M A. A K‐Means Clustering Algorithm[J]. Journal of the Royal Statistical Society: Series C: Applied Statistics, 1979, 28(1): 100-108.
[14] 熊忠阳, 陈若田, 张玉芳. 一种有效的K-means聚类中心初始化方法[J]. 计算机应用研究, 2011, 28(11): 4188-4190.
[15] 李桂林, 陈晓云. 关于聚类分析中相似度的讨论[J]. 计算机工程与应用, 2004(31): 64-65, 82.
[16] Tao X, Li Y. Concept-Based, Personalized Web Information Gathering: A Survey[C]//Knowledge Science, Engineering and Management, Third International Conference, KSEM 2009: 25-27.
Consumer Credit Rating System Based on the Xgboost Model
SHI Wei, WANG Ming-yue, ZHANG Qing-yun, LI Xiao-hui
(School of Electronics & Information Engineering, Liaoning University of Technology, Jinzhou 121001, China)
A consumer credit rating system based on xgboost model is designed, which uses face recognition method to select some features as consumer labels, quantifies consumer information, and narrates consumer image. The k-means clustering is improved, and a face recognition clustering algorithm based on kernel density is proposed, which divides consumers into different categories for credit rating. The system can alleviate noise point sensitivity, make the selection of original center point more simple, and use less bank transaction records with high availability.
xgboost model; credit evaluation; consumer portrait; clustering algorithm
TP311
A
1674-3261(2021)01-0001-04
10.15916/j.issn1674-3261.2021.01.001
2020-06-03
国家自然科学基金项目(61802161)
史伟(1978-),女,辽宁锦州人,实验师,硕士。
责任编校:孙 林
