基于HBase的小集群风电SCADA系统高效数据存取算法研究
2021-01-11汤晓安
陈 敏,汤晓安,刘 行,谢 鑫
(1.湖南信息学院 电子信息学院,长沙410151;2.国防科技大学 电子科学学院,长沙410073;3.长沙北斗产业安全技术研究院,长沙410205)
当前,风力发电已成为二十一世纪全球最重要的绿色再生能源。预计2020年,世界风力发电机的装机容量将达到12.45 亿千瓦,发电量占世界电力消费量的12%[1]。目前中国的中小风力发电厂占全国风力发电企业总数的90%[2],可以看出现阶段中小型风力发电厂是我国风力发电行业的主力军。对于风力发电而言,高性能数据存取是风力发电SCADA 系统的核心,是风电行业健康发展的基石[3]。随着风电行业的高速发展,数据量随之增多,而传统数据库数据存取性能有限,不能很好地支持风电数据高性能的存储、查询和分析[4]。
关于高性能数据存取,现阶段主要采用大数据分布式列式数据库系统HBase 作为存储载体[5]。此方面,国内外已有较多研究成果,文献[6]已经成功应用HBase 并且进行了开源版本很多再开发和创新;文献[7]利用HBase 重构了其存储层,进行了基于HBase 的实时传输平台研究;文献[8]提出了一种基于HBase 的时序监控数据存储以及提升数据存储和处理效率的方案;文献[9]深入研究了基于HBase的配用电海量时序数据存取技术;文献[10]设计了一个基于Hadoop 集群的变压器在线监测数据存储方案,该方案利用HBase 具有快速实时读写数据的优势,将变压器在线监测系统采集的海量数据实时快速地存储;文献[11]研究并实现了一个基于HBase的高效数据存取平台;文献[12]通过改进 HBase 表的设计以及k-means 聚类算法,较大程度地提高了公安大数据图片的检索效率。
但是上述研究成果主要是面向大集群、高成本的业务需求,众多国内基于小集群低成本环境(当前小集群低成本主要指不超过5 台中低性能服务器)的中小风力发电厂由于其固有的服务器规模小、成本投入低等局限性无法直接使用现有研究成果,所以针对现有众多小集群、 低成本环境下的风电SCADA 系统,开展其高性能数据存取算法研究意义重大且迫在眉睫。
本文以HBase 为工具载体,研究基于HBase的、 适用于小集群风电SCADA 系统的高效数据存取算法。本文研究以长沙北斗开放实验室下属风能新技术开放实验室的 “风电场跨平台中央监控系统”为应用场景。论文对现有Hbase 数据存取方法的存取性能进行了深入对比研究;基于此,综合运用Hbase API、批量存取、多线程等相关技术,创新性地提出适用于小集群、 低成本风电SCADA 系统的高性能数据存取算法;最后对该算法进行了实现与系统应用。实际应用表明,该算法较好地实现了小集群、低成本环境下的高性能数据存取,满足应用系统的实际需求。
1 Hbase 数据存取性能对比研究
HBase 具有数据存储量大、面向列、稀疏存储的特点。HBase 系统主要由HMaster 服务器和HRegion服务器群构成,它遵循简单的主从服务器体系结构模型。具体到表格存储而言,HBase 是以Region作为最小单位实现存储负载,依据存储量分裂成多个Region 模块分配到不同的集群之中达到分布式存储。
Hbase 数据存取又称为“HBase 数据导入导出”。当前,主流的HBase 数据导入导出方式有2 种,一种是“单条数据导入导出”,另一种是“批量数据导入导出”;同时,后者又可分为“HBase API 批量导入导出”与“MapReduce 批量导入导出”2 个方法。
以下就上述Hbase 数据存取3 种主要的数据导入导出方法的性能进行对比分析,测试环境为大数据软件环境Hadoop2.7.6+HBase1.4.9,通过5 台中低性能服务器在实际风电场搭建小集群环境进行研究。因同条件下导出与导入性能差异不大,下面仅对数据导入展开研究:
方法一“单条数据导入”主要是对环境的随机数据写入能力进行分析,试验通过多次运行Java代码,发现单条数据导入运行效率保持在100 ms~250 ms 之间,实际的效率与实时CPU 性能关系密切。
方法二“HBase API 批量数据导入”主要是测试HBase 在写入不同规模数据时所消耗的时间,导入数据为风力发电实时秒级数据,数据列固定118列,批量规模从10 条到500 万条。批量数据写入通过Java 代码编写,其中使用到BufferedMutator 类进行批量导入的容器管控。
方法三“MapReduce 批量数据导入”主要是测试MapReduce 在写入不同数据规模时的性能情况,直接使用原生API 将文件进行导入。
上述3 种HBase 数据导入方法的测试结果对比如表1 所示,逐步增加导入数据的规模并记录实际消耗时间。因为HBase 自带的数据导入算法都是单线程实现,所以无论是方法一还是方法二都无法满足高性能数据导入要求,而且会出现CPU 负载高,HMaster 服务崩溃 (如表1 中,“-” 代表服务崩溃)。方法三由于是采用多线程实现,其性能显然优于前两种方式。但是,通过进一步对小集群研究发现,MapReduce 其自启动需要消耗一定的基础资源,且其性能优劣与集群规模大小呈正相关,对于数据量到达千万级及以上大小的大集群才能发挥比较好的性能表现,而小集群数据规模通常保持在500 万以下,因而,小集群规模环境下其性能优势并不明显。因此,小集群想要获得更高效的数据导入,并不能直接采用方法三“MapReduce 批量导入”,而需要设计一种新的算法,本文考虑对方法二“HBase API 批量数据导入”进行算法改进。新算法的设计目标是性能超越现有3 种主流HBase 数据导入方法中最好的方法三。

表1 HBase 数据导入性能对比Tab.1 HBase data import performance comparison
2 基于Hbase 的小集群风电SCADA 系统高效数据存取算法
2.1 算法总体思路
分析表1 可知,要想实现基于小集群的HBase高效数据导入算法,既要充分利用小集群的CPU 以及其它硬件资源,同时也要实现导入算法服务本身较低的资源占用。基于以上分析,现采用多线程与HBase 的原生API 算法二者相结合的方法,进行多线程文件数据读取以及批量数据导入;同时依据服务器实时性能情况,进行资源负载均衡。
2.2 算法处理流程
基于上述算法总体思路,设计高效数据存取算法的处理流程如图1 所示。首先通过获取文件,并对其是否已经完成导入做好标记;接着获取服务器的性能情况,依据实际的服务器性能给予不同的多线程开启;然后对获取的文件进行分解,依据HBase提供的原生API 进行批量导入;在导入的过程中对服务器性能进行监控并做好负载均衡;最后判断文件是否完全导入完毕,整个高性能导入算法结束。

图1 基于HBase 的小集群高效数据存取算法流程Fig.1 High efficient data access algorithm flow chart of small cluster based on HBase
2.3 算法运行测试与对比分析
依据图1 所示算法,基于现搭建的小集群环境,使用中小风力发电厂常用的CSV 文件与数据库DB 文件进行测试,测试结果如表2 所示。表中,第3列“新算法”是指图1 所示算法,也即对表1 中的原“方法二”的改进算法。进一步将表2 中“新算法数据导入耗时”与表1 中原“方法三:MapReduce 批量数据导入耗时”进行对比分析,可以发现新算法导入性能有明显提升,依然分别针对10~5000000 数据行数,数据导入耗时分别减少17.3%~92.1%不等,平均减少约36.5%,如表2 所示。
进一步将新算法与原方法三“MapReduce 批量导入算法”的服务器性能情况作对比,分析其是否充足利用了服务器资源,测试结果如图2 和图3。可以发现,原方法三“MapReduce 批量导入算法”占用CPU 保持在50%左右,新算法保持在95%左右,显然,新算法实现了对CPU 的充分利用。
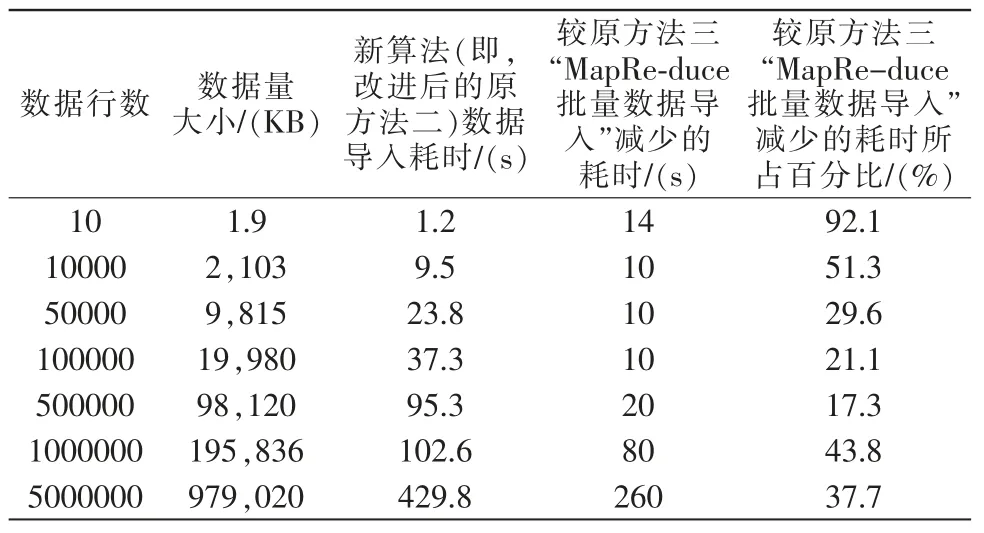
表2 新算法数据导入性能及与原方法的对比Tab.2 Data import performance and comparison of new algorithm

图2 原方法三“MapReduce 批量导入算法”执行资源消耗情况Fig.2 Execution resource consumption of original MapReduce batch import algorithm

图3 新算法执行资源消耗情况Fig.3 New algorithm performs resource consumption
3 系统设计与算法应用
本文所研究的高性能存储算法是基于长沙北斗开放实验室下属“风能新技术开放实验室”的“风电场跨平台中央监控系统”(以下简称“系统”)为应用环境,该系统软硬件架构如图4 所示。由图4 可以看出本系统是一个天然的小集群分布式架构,其无法直接套用大公司的高性能大集群存取方案,因而当前不得不采取MySQL 数据库存储+文件存储方式。系统监控50 台风机,数据总量800 G/年,原系统在进行较大数据量存取时,经常出现系统崩溃或者等待时间超过5 min 等问题,无法满足实际应用的需求。
本文通过对该系统原有系统架构进行分析,在原有系统软件架构中增加“数据高性能处理区”,修改系统原有的“数据存储分析区”内容并搭建分布式数据库HBase 存储环境;将数据交互方式由直接从“数据存储分析区”获取数据(图4 左部分空心旧通道)改为由“数据高性能处理区”获取数据(图4左部分实心新通道)。将本文设计的算法应用于系统“数据高性能处理区”,系统搭建成功后,系统总体运行稳定,系统的实时监控模块与高分辨率数据分析模块性能优化均十分明显,其中,高分辨率数据分析模块能够实现共两个月时间范围、秒级数据的实时查询与波形图显示,满足应用的实际需要,如图5 所示。
4 结语

图4 小集群风力发电SCADA 系统软硬件架构图Fig.4 Software and hardware architecture of SCADA system for small cluster wind power generation

图5 风电场跨平台中央监控系统“高分辨率数据分析模块”数据高性能存取展示Fig.5 High performance data access display of“high resolution data analysis module” of wind farm cross-platform central monitoring system
小集群环境是现阶段众多风力发电厂的主要特征,小集群风力发电厂由于其成本与技术的劣势无法满足日益增长的高性能计算需求。基于以上背景,本文依托长沙北斗开放实验室下属风能新技术开放实验室的“风电场跨平台中央监控系统”项目开展了基于小集群背景下风电SCADA 系统高性能数据存储算法的研究与优化工作。论文对现有多种Hbase 数据存取方法的存取性能进行了深入对比分析,从原理中寻求小集群存储优化的解决方案,提出并实现了一个基于大数据存储平台Hbase、 适用于小集群低成本风力发电SCADA 系统的高性能数据存取算法。应用表明,该算法性能高效,能够满足小集群风电监控系统存取需要,因而具有较好的工程推广价值。
