倾向性评分方法及其规范化应用的统计学共识*
2021-01-09CSCO生物统计学专家委员会RWS方法学组黄丽红王永吉王素珍执笔薛付忠夏结来主审
CSCO生物统计学专家委员会RWS方法学组黄丽红 王永吉 王素珍 赵 杨 王 彤 执笔 薛付忠 陈 峰 夏结来 主审
随机对照试验(randomized controlled trial,RCT)一直被誉为药物临床疗效评估的金标准,但基于理想状态下开展的RCT及其得到的有效性证据,与临床实践存在一定差距,有时难以推断在存在并发症、伴随治疗等普遍情况下的风险和效益,其在临床实践中的外推性可能受限[1-3]。现实世界研究(real world study,RWS),又被称为真实世界研究,是一种RCT之外临床疗效评价的有益补充,近年来得到广泛重视。2019年12月,国家药品监督管理局组织发布《真实世界数据用于医疗器械临床评价技术指导原则(征求意见稿)》,2020年1月发布《真实世界证据支持药物研发与审评的指导原则(试行)》,2020年5月发布《真实世界证据支持儿童药物研发与审评的技术指导原则(征求意见稿)》,进一步指导和规范RWS证据用于支持器械及药物研发和审评的有关技术要求,保障器械及药物研发的质量和效率。
RWS,尤其非随机化RWS中混杂偏倚的控制尤为重要,真正的混杂因素需要满足与处理因素(treatment)相关,给定处理因素后和临床结局(endpoint)相关,但不是处理因素-结局的因果关系通路上的中间变量三个条件,混杂因素的存在将歪曲(夸大或缩小)处理因素与结局的真实因果关联[4]。流行病学中常用有向无环图(directed acyclic graph,DAG)来图示混杂。以G、Y和C分别代表处理因素、临床结局和混杂因素,一个典型混杂现象的DAG见图1A。

图1 有向无环示意图
根据因果推断(causal inference)的相关理论,当混杂存在时,应当有一条指向G并连接Y的未被阻断的路径,即指向G的“后门”路径(backdoor path)。这里,由于C同时指向G和Y,故G←C→Y,可以认为G和Y是相关的,该路径成为了一条后门路径。此时在估计G对Y的效应时若忽略了C,则估计G和Y时的效应时就受到了混杂干扰[5]。图1B中的M为中介因素,是解释G对Y的因果效应的变量,图1C中的B为碰撞节点(collider,即研究因素和研究结局的共同结果),图1D中的IV为工具变量(instrumental variable,独立于混杂因素,与所研究的处理因素相关,与临床结局无关,仅通过处理因素影响结局),均不是混杂因素。RWS应密切关注潜在混杂因素,采用适当的设计和分析方法,尽可能控制混杂效应,或使混杂因素的影响达到最小。
对于已知且已测量混杂,除了传统的分层分析、配对分析、协方差分析和多因素分析以外,倾向性评分法(propensity score,PS)作为一种对多个协变量进行调整的降维分析策略,在非随机对照的RWS中的应用越来越广泛,但如何正确使用PS法,如何规范化报道PS法的结果尚未形成统一的认识,为此中国临床肿瘤学会(CSCO)生物统计学专家委员会RWS方法学小组,经充分讨论,形成以下共识。
PS法基本原理及特点
PS由Rosenbaum和Rubin于1983年基于反事实理论首次提出,是多个协变量的一个函数,根据已知协变量的取值(Xi)而计算的第i个个体分入处理组的条件概率[6-8]:
e(X)=P(G=1|X)
这里G表示组别或处理因素,G=1表示该个体在处理组,G=0表示该个体在对照组;X为协变量向量X=(x1,x2,…,xm)。假定个体i所在组别与协变量无关,即分组变量G与协变量X相互独立,若PS用传统的logistic回归或probit回归方法计算,即以组别G为因变量,以所要控制的因素为自变量建立logistic模型:
logit[P(G=1|X)]=α+β1x1+…+βmxm
或probit模型:
Φ-1(P(G=1|X))=α+β1x1+β2x2+…+βmxm
Φ为正态累积概率函数。将每个个体的协变量取值代入模型中,即可估计得到该个体的PS:
可见,PS是给定协变量X的条件下,个体接受处理(G=1)的概率估计。
在实际应用中,经常会遇到处理变量X是多分类或者连续的情况,那么这种情况下,上述提到的构建PS的基本方法就不再适用,而应使用广义倾向评分(generalized propensity score,GPS)。
GPS由Imbens于2000年提出[9]。如果处理变量有k个水平1,2,…,k,根据已知协变量的取值(Xi)而计算第i个个体的处理水平为k的条件概率:
e(X)=P(G=k|X)
在此基础上,Hirano & Imbens于2004年将GPS拓展到了连续处理变量的情况下[10]。假设处理变量G的取值在k0到k1内,GPS即为给定X时G的条件密度:
e(X)=fG|X(G|X),∀G∈[k0,k1]
对于GPS的估计,可以用上述提到的基于回归的方法(logistic、probit回归等广义线性模型)、机器学习方法(例如gradient boosting machine(GBM))、基于广义矩估计的协变量平衡GPS法(the covariate balancing generalized propensity score)[11]等。
PS本身不能控制混杂,而是通过匹配、分层、加权或协变量校正的方法,不同程度地提高对比组间的均衡性,从而削弱或平衡协变量对效应估计的影响,期望达到“类随机化”(minic-randomization)的效果,又称为事后随机化[12-13]。
1.PS匹配:如果将PS评分相同或相近的研究对象在不同的组间进行匹配,理论上,组间各特征变量的分布将趋于均衡,从而削弱或抵消组间混杂因素的不均衡性对研究结果的干扰,这就是PS匹配法。倾向性评分匹配法可分为贪婪匹配(greedy matching)和最优匹配(optimal matching)。常用的贪婪匹配方法有最邻近匹配(nearest neighbor matching)、卡钳匹配(caliper matching)。将观察组中的每个个体,在对照组中寻找与其最接近的个体进行匹配,直到观察组中每个个体都找到匹配,称为最邻近匹配。如果两个个体的PS差值在事先设定的某卡钳值范围内才能进行匹配,称为卡钳匹配。此外,还有马氏距离法(Mahalanobis),以及由其衍生的GenMatch法(genetic matching)等。而最优匹配法将匹配问题转化为运筹学中网络流(network flows)问题,此时观察组和匹配的对照组个体PS差值并不是最小的,但是能保证匹配集PS总体差值的最小化。PS匹配完成后,再基于匹配成功的研究对象进行效应估计及假设检验。
2.PS协变量校正:将PS评分直接作为一个新的协变量进行模型校正,即在主分析模型中,以结局变量为应变量,以分组变量为自变量,PS评分作为协变量来构建模型,从而估计组间效应。
3.PS分层:PS评分也可以作为分层变量,将受试者按照PS评分的大小分为若干区间,视区间为层,进行分层分析。所有的观察组和对照组中研究对象均参与分析,此时,层内组间协变量分布认为是均衡的,当层内有足够样本量时,可以直接对单个层进行分析,也可以对各层效应进行加权平均。
4.PS逆概率加权:逆概率加权(inverse probability of treatment weighting,IPTW),又称为逆处理概率加权,基于因果推断方法中的边际结构模型(marginal structural model,MSM)),与传统的标准化法类似。根据PS评分值赋予每个研究对象一个相应的权重,从而构建出一个虚拟人群,在此虚拟人群中,协变量的组间分布没有差异,因此消除了混杂因素的影响。权重的计算通常有不稳定权重(unstable weight)和稳定权重(stable weight)两种。逆概率加权法中的不稳定权重被定义为研究对象实际分组情况的概率的倒数:
不稳定权重波动较大,不够稳健。稳定权重在此基础上做了一些改进,稳定权重算法中最常见的是将不稳定权重与实际接受处理的边际概率相乘,即处理组对象将其不稳定权重乘以样本中接受处理的比例,而对照组则乘以样本中接受对照的比例。
计算权重后,再应用加权回归的方法估计处理效应。
上述四种PS方法总结见表1。

表1 四种基本PS方法总结
PS法的应用范围
PS法主要用于观察性比较研究或非随机对照研究中组间协变量分布不均衡的情形。在RWS研究的3类基本设计(实用临床试验/实效临床试验、使用RWS证据作为外部对照的单臂试验、观察性研究)中,主要适用于观察性研究中的已测量(measured)混杂因素控制和使用RWS证据作为外部对照的单臂试验中,例如在肿瘤单臂试验中,借助历史对照数据进行PS法分析已有成功案例[14]。PS法也可用于随机化失败(randomization failure)的探索性临床研究中,比如实际研究中实施随机化所需的条件不可实行或完全不能被满足,使得受试者的随机化分配规则不经意地遭到违背或受到故意阻挠时,随机化通常就会失败。相较于传统的混杂因素控制方法,PS法更适用于基线不均衡的协变量较多的研究。虽然RWS的数据通常来自日常收集的各种与患者健康状况和/或诊疗及保健有关的数据,样本量通常较大且远超于RCT,但是所有的临床研究设计都需要考虑样本量问题,应用PS法同样需要考虑,其样本量要求与所选择的PS评分模型及效应分析方法相关,如进行PS匹配,匹配后的有效样本数应满足所选择效应比较方法的样本量需求。
PS法不适用于下列情况:
1.PS法不可用于未知或未测量(unmeasured)混杂因素的控制;
2.PS法不适用于时依性协变量所致混杂因素的控制;
3.PS贪婪匹配法不适用于组间PS评分重叠范围(overlap)过小时(图2),该情况下应用PS贪婪匹配法将导致匹配后损失大量样本,带来估计偏差;
4.PS分层、PS协变量校正、PS逆概率加权不适用于组间PS评分分布相互偏离较大时,此时的校正可能产生错误的估计值;
5.当干预措施随时间发生变化时,PS方法可能失效;
6.当干预措施罕见时将影响PS评分估计的效果,PS方法可能失效。
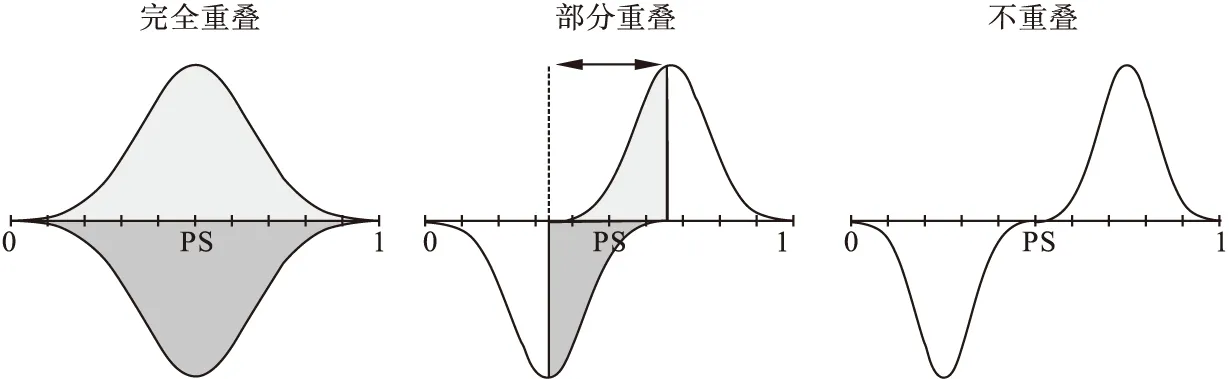
图2 PS评分重叠范围示意图
PS法中的常见问题
虽然PS法广泛应用于非随机对照研究中,但存在诸多误区和问题,需要引起重视和思考[10]。
1.运用PS法能取代随机对照设计的误区 PS法虽然具有理论优势,但仅能平衡已测量混杂因素,并且要求组间协变量的PS评分分布有所重叠;基于不同的PS方法,得到的估计结果可能不同,通常需要借助敏感性分析来评估结果的稳定性。RCT作为临床研究的金标准,能够有效均衡组间的已测量和未测量混杂,能够回答试验药物在某个特定条件下是否有效的问题,因此,借助PS法的RWS无法取代RCT[15-16]。
2.PS评分变量选择不充分 纳入PS评分模型的变量直接影响PS评分的计算结果。纳入不同的协变量,分析结果将有所不同。在制定分析策略阶段,应充分考虑所有可能的混杂因素,作为选择PS评分变量的基础。
3.不充分的调整前和调整后的分析 没有对调整前协变量不均衡情况进行描述,采用PS评分方法调整后,亦未对调整后的平衡程度进行描述,导致PS方法应用前提不明确,应用效果不确定。
4.PS匹配问题 PS评分方法中PS匹配的应用最为广泛,存在问题最为突出。例如:PS匹配需满足重叠假定,若在匹配前未评估,会导致匹配后损失大量样本,带来估计偏差;在应用卡钳匹配法时,若未对卡钳大小设定进行论证,导致采用不同的卡钳值得到不同的匹配结果,从而影响研究结论。
5.敏感性分析不充分 由于现有数据中协变量信息的限制,不同的匹配方法所得到的研究人群不同等原因,可能会导致PS法的结果不同。从应用角度看,当难以对假定进行检验时,对结果的敏感性分析就变得极为重要。当不同的分析方法得到的结论不同时,研究结论并不稳健,需要进一步验证。
PS法的应用规范
PS法分析结果的合理性与数据的质量和分析策略密切相关。随着PS法应用越来越广泛,其分析过程及结果报道的规范化愈加重要。在应用PS法进行数据分析前,需要遵照RWS相关指导原则对RWS数据的适用性进行评估,只有满足适用性的RWS数据才有可能产生RWE(real world evidence)。ICH-E9要求在进行临床试验设计时,在试验方案中对数据统计分析计划进行说明,在应用PS法进行验证性RWS数据分析时同样需要计划在先,执行在后,避免根据分析结果来选择分析策略的主观导向性。针对PS法的基本步骤(图3),其具体分析过程的规范化应考虑以下统计学问题[17-20]:
1.选择协变量
用于计算PS评分的协变量的选择直接影响PS法结果。关键的协变量包括影响结局的基线变量,在协变量取值可靠的前提下,结合专业知识尽可能排除中介因素(图1B)、对撞因素(图1C)和工具变量(图1D),识别后门路径中混杂因素(图1A),进而在PS模型中应尽可能地纳入所有已测量混杂因素。当然,如果我们阻断了所有的后门路径,就完成了对研究因素和研究结局的去混杂。

图3 PS法基本步骤
选择协变量应结合专业知识在制定分析计划时事先确定,确定后不应随意更改。在医疗器械研发领域,有学者提出PS两步法,其中选择协变量作为PS法的第一步,由与后续分析步骤不相关的独立研究者执行,以确保协变量选择的客观性[21]。
2.PS评分模型选择
PS评分计算最常用的模型为logistic回归、probit回归,也可采用判别分析、机器学习等方法。方法的选择不应受研究推论影响,无论采用何种模型,每一位观察对象进入处理组的概率不为零。评分模型应在制定分析计划时事先确定。
3.PS方法的选择及参数设置
根据四种PS方法的优劣,结合研究问题及资料特征进行PS方法的选择。通常,当样本量较大,预估匹配后样本的损失仍可满足最低样本量要求时,可以选择PS匹配法;当样本量有限时,应尽量采用利用所有数据的方法,如希望达到类随机化的效果,可考虑PS逆概率加权法。
得到PS评分后,需绘制PS评分分布图,考察重叠假定(overlap assumption),即观察组和对照组的PS取值范围有交叉重叠的部分(common support),通常若某观察个体的PS值高于对照组PS的最大值或低于对照组PS的最小值,可考虑去掉该观察个体,但若重叠取值范围有限,则不宜采用PS法。
另外,使用各种PS方法还应分别考虑以下问题:
(1)PS匹配:需根据对比组的样本量情况事先确定匹配比例(选择1:1匹配或1:n匹配)和匹配方法。如采用卡钳匹配法,需注意卡钳值的设定直接影响到最终匹配集的样本量,卡钳值越大,能够匹配成功的个体越多,但对比组间的均衡性可能较差;反之,卡钳设置过小,虽然可提高对比组间的均衡性,但匹配成功率可能降低,匹配集的样本量减少。因此,应在制定分析计划时事先设定卡钳值,通常将卡钳值设定为两组倾向性评分标准差的20%。另外,还需事前确定是否采用有放回的匹配方式,即配对后的对照组对象是否参加下一组的配对,如采用有放回的方式,每个对照可能出现在多个对子中,需要对方差进行调整。
(2)PS分层:PS分层的关键问题是分层数和权重应事先设定。权重一般由各层样本占总样本量的比例来确定,也有学者建议采用各层内处理效应方差的倒数[22]。根据文献报道,按PS将样本平均分为5层,能减少90%以上的偏倚,是PS分层中最常用的方法[23]。
(3)PS协变量校正:需要事先明确定义PS评分与结局变量关系的回归模型,该方法的正确性依赖于建模的正确性。PS评分通常作为唯一协变量纳入模型,如需添加其他协变量应在分析计划中事先设定,避免结果导向分析。
(4)PS逆概率加权:是基于个体的标准化法。有较低PS的处理组对象与有较高PS的非处理组对象将会获得较大的权重,可能带来结果不稳定的风险,而稳定权重可以有效避免极端PS评分的影响,因此如采用稳定权重,其计算方式应在分析计划中事先设定。
4.均衡效果评价
PS匹配后协变量应达到均衡,采用假设检验的方法并不妥当,均衡不是针对总体,不需要做统计推断,而仅针对进行匹配的分组样本特征。目前用于评价组间基线均衡性的方法有:
(1)指标评价法:标准化差值(standardized difference)可用于定量评价均衡性,一般认为标准化差值小于0.1,均衡性能被接受,不受样本量的影响。
对于连续型变量,定义为:

对于分类变量,定义为:
其中,pT和pC分别表示处理组和对照组中协变量的阳性率。
另外,对于GPS,为了评价协变量是否达到了均衡的效果,可以选用评价指标absolute correlations(ACs):
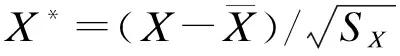
(2)图形法:可采用QQ图、并排箱式图、背靠背直方图、累积分布函数图等直观比较组间协变量分布的图形。
PS分层可通过比较层内组间PS的均衡性来检验所选定的层数是否合理。PS协变量校正效果可根据所选回归模型,通过衡量回归模型“优劣”的常用量化指标来判定,例如复相关系数R(或决定系数R2),剩余标准差,赤池信息准则(Akaike′s information criterion,AIC)等。PS逆概率加权产生的虚拟样本中观察组与对照组基线协变量应达到均衡,均衡性判定与PS匹配类似,可采用标准化差值法或图形法。
值得一提的是,若在应用倾向评分后,协变量均衡性并未改善,有学者提出还可进一步考虑模型构建合理性判别的步骤,通过增加或调整协变量,增加协变量之间的交互项或者采用非线性项(nonlinear terms),比如立方平滑样条曲线(cubic smoothing splines)等方法修正模型,再进行倾向评分估计和协变量的均衡性评价,直到组间协变量均衡性得到改善。
5.估计处理效应
如为探索性研究,通常不进行因果推断(causal inference)。当研究的目的是作为支持上市的主要证据时,需在分析中考虑进行因果推断并估计因果效应(causal effects)。
因果效应通常有两类,一类为总体人群的平均因果效应(average treatment effect,ATE),为所有个体均接受处理的平均潜在结果E(y1)与全部个体均接受对照条件的平均潜在结果的结局值E(y0)的差值,即ATE=E(y1)-E(y0);另一类为处理组平均因果效应(average treatment effect among the treated,ATT),为处理组个体接受处理条件后的平均潜在结果E(y1|z=1)与处理组个体接受对照条件后的平均潜在结果E(y0|z=1)的差值,即ATT=E(y1|z=1)-E(y0|z=1)。通常在临床试验中,所关心的因果效应是ATT。
直接从观察结果估计ATT时,会遇到一个问题,根据反事实理论,并不能同时观察处理组个体接受处理条件和对照条件的两个潜在结果(实际观察结果和未能观察到的反事实结果),这也是因果推断的一个核心问题、核心难点。在RCT中,试验组与对照组是随机分配的,基于反事实的一致性假设,对照组的观察结果为处理组个体接受对照条件的潜在结果的无偏估计,从而能够得到ATT的无偏估计值,这也是RCT可以进行因果推断的主要原因。在非随机对照研究中应用PS法能否进行因果推断,主要取决于最终的“类随机化”效果,需要注意的是,PS法只能考虑已测量混杂因素,但在实际研究中,人们可能永远无法找到所有的潜在混杂因素,那些未知的混杂因素,或虽然已知但实际测量有困难的混杂因素是PS法无法控制的,因而,PS法用于因果推断需要谨慎对待。通常,在非随机化RWS中,基于PS法的因果推断需要满足“正则性”假设,即各观察对象接受各种处理的概率均大于0,也就是观察对象需要有明确的分组。另外,还需满足条件可交换性,条件可交换性(exchangeability)要求研究者针对处理组,想象如果这组患者没有得到处理,其成员会发生什么,判断这一想象中的结果与那些实际上没有接受处理的小组的情况是否一致,只有在条件可交换性假定成立时,才能说明研究中不存在混杂因素的影响,才能进行有效的因果推断。
6.敏感性分析等其他考虑
PS法十分灵活,在分析过程中选择不同的方法,设定不同的参数,分析结果可能不同。充分的敏感性分析在PS法应用过程中十分必要,敏感性分析策略应在分析计划中事先设定。通常针对PS法的敏感性分析可以考虑:PS评分值采用不同模型、不同协变量组合计算的敏感性分析;PS匹配采用不同比例,不同匹配方法的敏感性分析;采用基于PS评分的不同方法(例如PS匹配法与PS校正法)的敏感性分析;PS逆概率加权采用不同稳定权重定义的敏感性分析;PS分层采用不同分层策略的敏感性分析等。
另外,数据缺失问题在临床研究中普遍存在,利用倾向性评分法进行数据分析时,如有任一协变量缺失,则无法估计PS评分值,因而缺失值的影响不可忽视。在制定统计分析策略阶段,需事先设定缺失值的处理原则。关于缺失数据的考虑可参照RWS研究的相关指导原则。
对于应用PS方法的临床研究,在分析过程规范化的前提下,应进行规范化的结果报道,在遵照相应国际指南(观察性研究的STROBE指南[15])的基础上,建议结果报道核查表2所列内容。

表2 PS法结果报道检查表
