基于加权随机森林的三阴性乳腺癌microRNA组学数据的分类预测*
2021-01-09郭志飞王碧珏杨海涛王菊平曹红艳周立业
郭志飞 王碧珏 杨海涛 李 治 王菊平 曹红艳,6△ 周立业△
【提 要】 目的 基于microRNA组学数据,探讨加权随机森林在三阴性乳腺癌分类预测中的应用,为疾病诊断提供方法学支撑。方法 以TCGA乳腺癌数据为例,采用加权随机森林构建三阴性乳腺癌的分类预测模型,并与随机森林、logistic回归、支持向量机、LASSO和岭回归五种模型进行比较。结果 通过比较六种模型的5个评价指标,加权随机森林模型的预测性能明显优于其他五种模型,加权随机森林模型的灵敏度为0.852、特异度为0.873、准确度为0.871、AUC值为0.862和G-means值为0.861。结论 加权随机森林构建的分类预测模型较好地识别了三阴性乳腺癌患者,可为三阴性乳腺癌的诊断提供方法学上的参考。
乳腺癌是全球发病率仅次于肺癌的第二大癌症,是45~55岁女性死亡的主要原因,严重危害女性的健康和生命[1]。三阴性乳腺癌(triple negative breast cancer,TNBC)是乳腺癌的一种亚型,占乳腺癌的15% ~ 23.8%[2-3]。与非 TNBC相比,TNBC具有侵袭性强、恶性程度高、五年生存率低、预后差等特点[3-4]。目前对于TNBC的诊断大多是从影像学上进行判断,其中,核磁共振成像是诊断TNBC最精确的影像检查技术,诊断符合率高达98.28%,但其存在检查费用昂贵、耗时长的问题;X线摄影作为乳腺首选的影像学检查方法,容易漏诊和误诊,尤其对40岁以下患者的诊断准确性欠佳,且辐射较大,对孕妇等特殊人群不太适用[3,5-6]。因此,如何实现低成本、检测快、无副作用的TNBC患者的分类预测非常重要。
近年来,大量研究证实microRNA(miRNA)与乳腺癌等疾病的发生、发展密切相关,其在疾病诊断中有较高的应用价值[7-8]。由于TNBC占乳腺癌的20%左右,在构建TNBC分类预测模型时存在类别不平衡的问题。传统的机器学习算法在处理类别不平衡数据时,更关注于多数类的识别,对少数类的预测精度偏低[9]。代价敏感性学习方法结合不平衡数据的特点引入类权重概念,对传统分类算法进行改进,提高了不平衡数据的整体分类性能[10]。
因此,本文针对TCGA(The Cancer Genome Atlas)乳腺癌数据,采用基于代价敏感性学习思想的加权随机森林(weighted random forest,WRF),构建三阴性乳腺癌的分类预测模型。同时,将加权随机森林与随机森林、logistic回归、支持向量机、LASSO和岭回归五种方法进行比较,为识别TNBC患者提供辅助意见。
资料与方法
1.资料来源
使用TCGA-Assembler软件在TCGA网站下载乳腺癌数据[11-12],从中选取包含临床和miRNA组学数据的女性患者共740例,其中TNBC患者81例,non-TNBC患者659例。
2.研究方法
(1)变量筛选
miRNA有1871个变量,删除零表达值所占比例≥20%的变量后,剩余811个变量。为了降低预测变量中的冗余信息,筛选出与结局相关的变量,故在构建模型前需进行变量筛选。Fan J等人[13]提出了确定独立筛选(sure independence screening,SIS),该方法根据预测变量与反应变量的边际相关程度筛选出边际相关强的变量。SIS可以快速有效地降低数据维度,筛选出重要变量,从而提高预测性能。因此,本文使用SIS对变量进行筛选,最终得到了67个变量。
(2)岭回归、LASSO和支持向量机
岭回归和LASSO是通过对系数进行约束或加罚来拟合模型的两种方法[14-15]。二者都是将系数的估计值往0的方向进行压缩。但LASSO可以将某些系数的估计值强制压缩为0,使所得模型更易解释。
支持向量机(support vector machine,SVM)通过非线性映射函数将低维输入空间映射到高维特征空间中,并在特征空间构造判别函数对样品进行分类[16]。
(3)随机森林
随机森林(random forest,RF)通过bootstrap重采样技术,从乳腺癌原始数据中有放回地抽取n个样本生成n棵分类树,这n棵分类树最终组成随机森林,新数据的分类预测结果由分类树投票决定[17-18]。
新数据的分类预测结果可用公式(1)表示:
(1)
其中,hi是单棵分类树的基础分类模型,Y是输出变量(TNBC和non-TNBC),I(·)表示示性函数。
(4)加权随机森林
在处理类别不平衡数据时,RF以错误率最小化为目标,倾向于将样本划分为多数类,导致其对少数类的预测精度偏低。因此,基于代价敏感性学习的思想,Chao C等人[19]提出了加权随机森林的方法来解决上述问题。在二分类数据中,分布较大的称为多数类,其他称为少数类。两个类别都有各自的权重,WRF给予少数类较大的权重,多数类较小的权重[20]。在设置不平衡数据权重时,将少数类的权重设置为2或3较合适[21]。
WRF在引入类权重后,选择划分属性的基尼指数会发生改变:
(2)
Δi=i(N)-i(NL)-i(NR)
(3)
其中,N是根节点,NL和NR是左右两个子节点,Wj是第j类的权重,nj是第j类的样本量,Δi是节点降低的不纯度。在构建分类树时,通常选择节点基尼指数最小的属性为最优划分属性。
类权重也会影响每棵分类树的终端节点。随机森林每个终端节点的最终预测结果是通过综合考虑每棵分类树的加权投票(案例数×每个类的指定权重)来确定的。
(4)
WRF有三个重要的参数:类权重classwt的大小;每个节点随机选择特征的数目mtry;树的棵树ntree。经验证,这三个参数分别设置为classwt=1∶2,mtry=3,ntree=400时,WRF模型的预测性能最佳。
(5)模型构建与比较
采用分层抽样,从TNBC和non-TNBC样本中分别抽取70%样本作为训练集,用于构建模型。将剩余的30%样本作为测试集,用于评价模型的预测性能。将变量筛选后得到的67个预测变量作为输入变量,将是否为TNBC作为结局变量,将WRF、RF、logistic回归、SVM、LASSO和岭回归这六种方法在同一训练集上构建分类预测模型,并利用测试集数据进行预测,通过灵敏度(Se)、特异度(Sp)、准确度(ACC)、受试者工作特征曲线下的面积(AUC)和G-means五个指标对模型的性能进行评价。为了保证预测结果的稳定性,抽样和模型构建过程重复500次。
从研究结果可以看出,无论是语际错误,还是语内错误中的词汇错误与句法错误,知识能力的不足都是其根本原因。
(6)统计方法实现
支持向量机选择的核函数为高斯核函数,其带宽使用默认值。logistic回归是一个概率预测模型,概率大于0.5为患病,小于等于0.5为未患病。统计分析采用R软件,screening包用于变量筛选,e1071包用于构建支持向量机模型,glmnet包用于构建LASSO和岭回归模型,randomForest包用于构建随机森林和加权随机森林模型。
结 果
1.研究对象的基本特征
本次研究共纳入740例样本,其中TNBC患者81例,占10.95%,non-TNBC患者659例,占89.05%;平均年龄为(58.16±13.18)岁,45~54岁年龄段的人数居多,占29.46%;生存状态中生存人数675人,占91.22%,死亡人数65人,占8.78%;临床分期共4个阶段,其中处于Ⅰ~Ⅱ阶段的人数居多,占75.14%。详见表1。
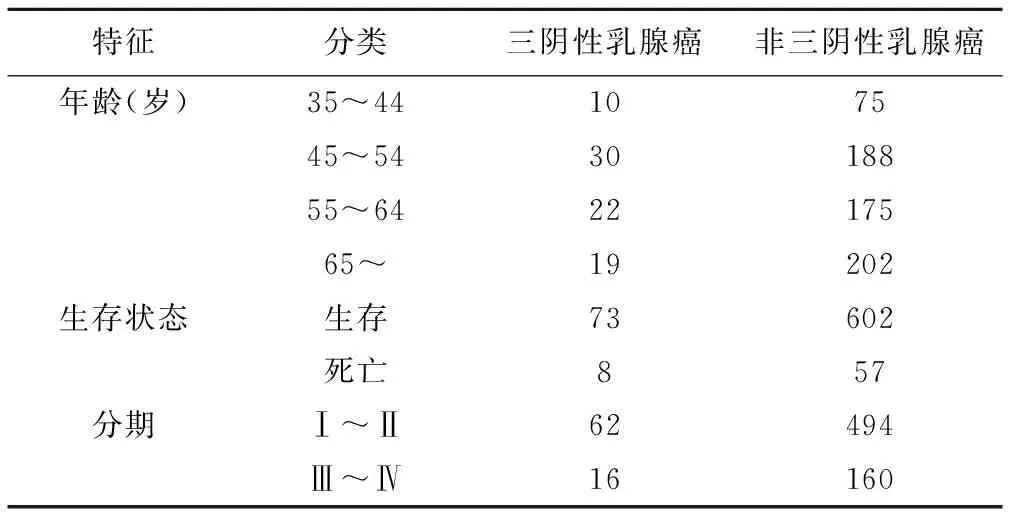
表1 一般人口学资料
2.参数选择
(1)加权随机森林classwt的设置
WRF不设类权重,即类权重设置为1∶1时,分类效果并不理想(Se=0.305,Sp=0.973)。我们将类权重分别设置为1∶2、1∶3、1∶4和1∶5,并在测试数据集上进行验证,不同类权重构建的各模型预测性能结果如表2所示。
(2)加权随机森林mtry的选择
在构建WRF模型时,ntree设定为默认值(ntree=500),逐渐增加变量建模,比较模型袋外数据的错误率均值。由图1可以看出,特征数目为3时,模型的错误率最低。为进一步通过综合评价指标AUC和G-means来评价模型的性能,故将mtry分别设置为2、3、4、5、6、7、8、9和10,并在测试数据集上进行验证,不同特征数目时各模型的预测性能结果如表3所示。
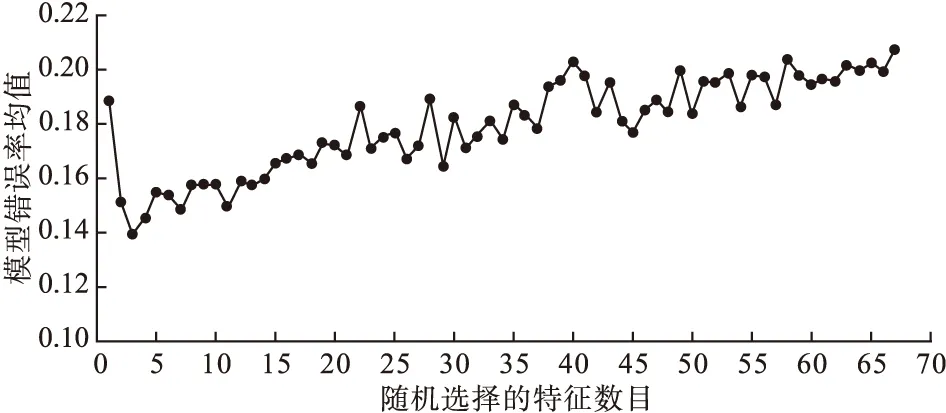
图1 模型错误率均值随选择特征数目变化曲线图

表2 不同权重构建的加权随机森林模型的预测性能比较
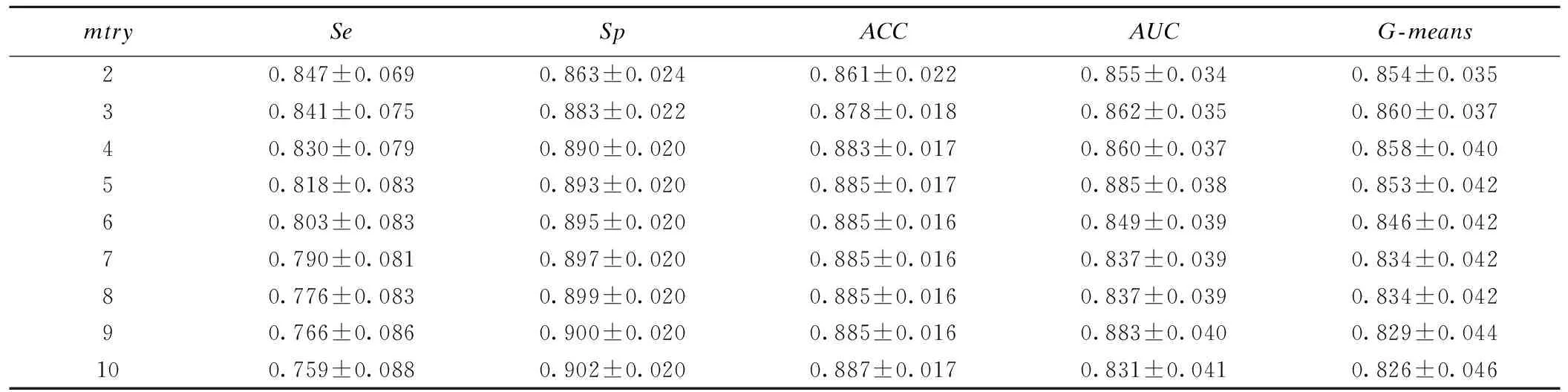
表3 不同特征数目的加权随机森林模型的预测性能比较
从表3中可以看出,随着mtry的逐渐增加,模型的灵敏度逐渐降低,特异度逐渐增加。当mtry取值为3时,模型的AUC和G-means最优,因此模型的参数mtry设定为3。
(3)加权随机森林ntree的选择
将参数ntree分别设置为200、400、500、600、800和1000,并在测试数据集上进行验证,对不同树棵数的加权随机森林模型进行预测性能的比较,各模型的预测性能如表4所示。

表4 不同树棵数的加权随机森林模型的预测性能比较
从表4中可以看出,五个不同参数模型的分类效果相差不大,当ntree≥400时,各个加权随机森林模型的各项评价指标均趋于平稳,因此模型的参数ntree设定为400。
(4)模型性能总结
表5展示了重复抽样500次,六种机器学习方法的5个评价指标的结果。五种模型(RF、logistic回归、SVM、LASSO和岭回归)的ACC值均高于0.87,Sp值均高于0.92,都偏向于识别non-TNBC样本。但这五个模型的Se都较低,分别为0.309、0.466、0.012、0.122、0.105,可以看出传统的机器学习方法对少数类(TNBC患者)的识别能力较差。
从表5RF和WRF的评价指标可得,WRF在Se、AUC和G-means指标上均明显优于RF。尤其在Se指标上,WRF比RF高出了0.543,可见在分析不平衡数据时WRF能够有效地识别少数类患者。
根据综合指标AUC值和G-means值来看,WRF的分类预测性能最好,其AUC值为0.862、G-means值为0.861,其余各指标的值参见表5。综上,WRF在多个指标上明显优于其他五种方法,可帮助临床医生识别TNBC患者。

表5 六种机器学习方法在三阴性乳腺癌预测中的结果比较
讨 论
构建TNBC的分类预测模型时,大多是利用图像特征来构建分类预测模型。Wu T等人[22]利用超声图像特征构建了logistic回归模型,其灵敏度和特异度分别为0.869 和0.829。Wang J等人[23]在提取核磁共振图像的特征后,使用支持向量机构建了TNBC的分类预测模型,模型的灵敏度和特异度分别为0.570和0.947。然而,通过提取图像特征构建的模型灵敏度或特异度较低,使就诊患者存在较高的被误诊或漏诊的可能性,在用于辅助临床诊断时尚不能让人满意。
miRNA与人类多种疾病密切相关,其对疾病分类预测有重要的临床意义。蔡莉等人[24]使用miRNA识别多发性骨髓瘤患者时,灵敏度达0.86。张杰铭等人[25]发现循环miRNA在鼻咽癌患者的诊断中有重要的潜在价值,模型AUC值高达0.91。本研究对乳腺癌数据进行了挖掘,探索了miRNA在筛检TNBC患者中的临床意义,发现使用miRNA数据对TNBC进行预测时效果良好,提示miRNA在TNBC分类预测中有潜在的生物学价值。
针对传统机器学习在处理类别不平衡数据时不能有效识别少数类的问题,本研究在建模时运用了基于代价敏感性学习思想的WRF方法,其构建的模型有良好的分类预测性能。WRF在处理不平衡数据时,有两大优势:不同于重采样技术需要将原始的不平衡数据构造为类别平衡的数据集,WRF不需要改变原始数据的结构,其在构建模型的过程中,所用的医学数据仍能够代表该疾病的普遍发生率;WRF通过对不同类别设置权重,让少数类的权重增大,从而加大少数类错分的代价,使模型对成本敏感,达到错分代价最小化的目的,让模型在保持了较高特异性的同时,也能够提高对少数类预测的准确性。
综上所述,加权随机森林是一个良好的分类器,有助于识别三阴性乳腺癌患者,能够为三阴性乳腺癌的诊断提供理论指导,同时加权随机森林算法也为在运用医学非均衡数据构建疾病分类预测模型时提供了思路。
