杜鹃花各生长期识别与监测研究
2021-01-07裴晓芳
裴晓芳,胡 敏
(1.南京信息工程大学 滨江学院,江苏 无锡214105;2.南京信息工程大学 江苏省大气环境与装备技术协同创新中心,江苏 南京 210044;3.南京信息工程大学 电子与信息工程学院,江苏 南京 210044)
近年来,我国花卉销售产业规模日益扩大,但由于缺乏专业养护知识,优质花苗的培植成了棘手的问题。图像检索作为计算机视觉的一个分支[1],可以自动识别植株病症与生长状态,实时协助种植者发现问题并采取应对措施解决问题,已被越来越多地应用到花卉种植领域。但是,图像光照变化、视角转换、尺度差异、背景混乱以及目标遮挡等问题的存在给图像检索技术带来了巨大困难。
2003年,Sivic J等人首次提出特征词袋(Bag-of-Features,BoF)概念,将文本语义检索思路引入到图像检索领域。2005年,Grauman K等人提出了基于BoF的金字塔匹配核函数,将各特征集映射到一个多分辨率的直方图中。文献[1]采用多核学习算法巧妙融合多种不同维度的特征对果蔬图像进行分类识别。2015年,阮嘉等人将概率论引入到BoF中用于识别交通标志[2]。2019年,张泽晨等人提出了多特征融合的BoF图像检索算法,有效利用图像颜色和纹理清晰表述果蔬特征[3]。本实验采用改进式特征词袋图像检索算法对采集到的杜鹃花图像进行处理和识别。
传统单一特征的BoF模型中SIFT(Scale-Invariant Feature Transform)匹配在局部特征匹配中仅作为低级表示,对于复杂特征提取鲁棒性差,且容易产生假匹配[4-5]。为了解决这一问题,本实验首先从杜鹃植株叶片特征入手,在LAB(Logic Array Block)模式下提取图片的相对颜色特征和空间信息组成空间颜色聚合矩阵;随后,采用多特征学习算法将该矩阵与BoF中的加速鲁棒特性(Speed Up Robust Features,SURF)进行特征融合产生新的BoC-BoF(Bag of Color-Bag of Feature)特征向量;然后,经过特征词典进行量化编码,消除了传统颜色直方图量化范围大的缺陷;最后,采用图像分类器进行分类识别,实现花卉生长状态的自动化和智能化分析,节省了人力物力。
1 BoF模型
1.1 BoF模型基本原理
BoF型是词袋(Bag-of-view-Word,BovW)模型的一种,通过统计区域的全局相似性来表征图像,不受拍摄角度和光照的影响。相对于CNN(Convolutional Neural Network)[6]和神经网络等深度学习模型,BoF需要的样本数量少,对图片品质要求低。作为一种基于局部特征匹配的识别算法,BoF模型将每一幅图像分割成若干局部区域,并将这些特征映射到一组无序的视觉关键词上,图像的检索就转化为若干单词的匹配[7]。BoF创建过程包括:特征提取、特征描述、构建视觉词袋(特征汇集)和特征统计。BoF构建流程如图1所示。
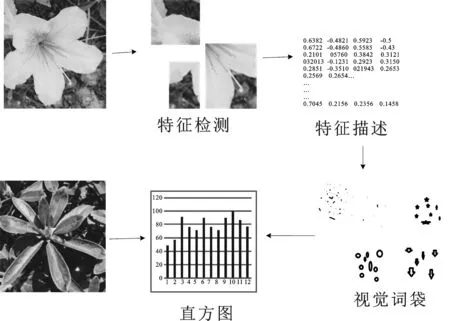
图1 BoF构建流程图Figure 1. Flow chart of BoF establishment
作为一种简单有效的基于区域层次的图像描述方法,BoF在处理复杂图像分类时存在明显缺陷:(1)空间金字塔BoF和分层BoF通过大量空间信息表征图像,计算繁琐,且特征矩阵与图像本身特征点的空间关系关联度很弱[8-10];(2)BoF模型的区域特征描述多采用单一特征,鲁棒性差,对自然界中复杂图像的特征很难清晰描述;(3)聚类算法适用于构建密集的区域特征空间,但是对于稀疏区域特征空间的构建仍然没有合适的方式[11]。
1.2 改进式BoF
针对BoF模型上述的3个缺陷,本研究在不降低识别率的条件下对BoF分类流程中的特征提取和特征汇集阶段进行改进,即采用空间颜色聚合矩阵融合SURF特征代替图1中的颜色直方图。
由于样本数量庞大,且颜色特征和SURF特征数据不规则,实验采用多特征学习算法将颜色特征与SURF特征进行特征融合形成新的特征。具体工作流程如图2所示。
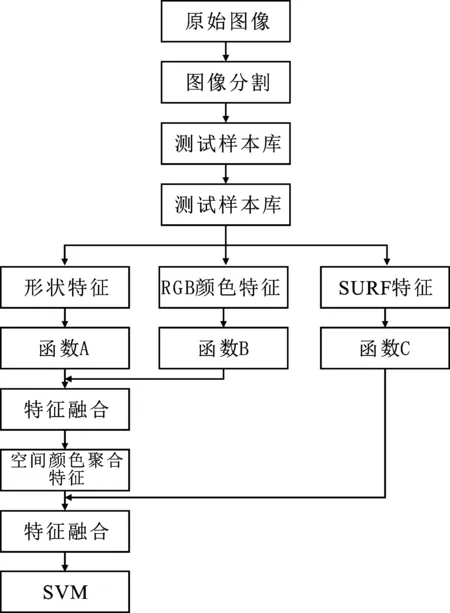
图2 改进式BOF分类流程图Figure 2. Flow chart of improved BOF classification algorithm
为适应未来AI(Artificial Intelligence)技术的发展趋势并增加代码可移植性,本实验将训练好的模型保存到文件中,应用层直接调用即可,无需重新训练和测试,为后期嵌入式系统的开发提供了良好应用平台。
2 特征提取与归一化
图像的特征值是图像识别和分类的依据。被捕捉的特征值越完整,图像识别率越高。从图3可以看出,杜鹃植株各生长期和病害的样本图像目标区域颜色存在巨大差异,所以本实验采用的图像特征之一为病叶上带有圆形异色斑点和异色尖点,即斑点的边缘梯度特征和Harris角点特征。

图3 部分样本图像展示Figure 3. Images of some samples
2.1 SURF特征提取
SURF算法具有尺度不变性和良好的鲁棒性,在不降低精度的条件下大量合理使用积分图像不需要进行降采样。SURF算法特征点识别率较SIFT算法高,运行速度大约是SIFT算法的3倍,因此在视觉转换和光照变化等环境下,该算法匹配效果优于SIFT算法,但其旋转不变性不如SIFT[12-13]。由于实验中相机位置固定,采集到的图像一般不会旋转,尺度变换相对较小,故本研究采用SURF算法进行图像分类。
从图4 可以看出SURF特征描述子数值较小,为增加特征可识别性,实验对特征矩阵每行求平方和并入特征矩阵,学习分4步完成:
步骤1多尺度特征提取;
步骤2将获取的特征描述子SURF Feature输入函数C。C的函数式为
(1)
式中,i表示行;j表示列;a(i,j)表示特征矩阵SURF Feature中第i行、j列个元素;si表示矩阵SURF Feature中第i行所有元素平方和;
步骤3步骤 2中所得向量S作为最后一列并入特征矩阵SURF Feature;
步骤4如图4所示,原始SURF特征取值范围0~0.016,比颜色特征小了很多,经函数C处理后所得结果为0~1。

图4 SURF特征Figure 4. Features of SURF
2.2 空间颜色特征提取
从图3中可以看出叶黄病病叶没有明显圆点和尖点,但是叶片颜色较健康叶片略黄,因此图像分类的另一个特征为颜色。
由于实验使用的样本图像分辨率较低,在RGB颜色空间提取的颜色特征存在很多0值。LAB颜色空间色域包含RGB颜色空间所有色域,此外还包括部分RGB所不能表现出来的色彩,在LAB颜色空间提取的颜色特征可以有效的覆盖这些0,补充图像颜色特征[14]。
LAB颜色特征的提取分为3步:
步骤1进入LAB空间学习各像素点的特征值,存入向量Col Feature;
步骤2使用reshape(·)在特征点不变的条件下将Col Feature重新整形成Feature[256,3];
步骤3将Feature[256,3]放入函数B,归一化为相对数值。B的计算式为
(2)
式中,i表示行;j表示列;a(i,j)表示矩阵Feature[256,3]中第i行、j列个元素;V(i,j)表示a(i,j)与其所在行的所有元素平方和的开方的比值。实验以图3中部分图像为例,计算归一化之后的相对颜色特征均值。仿真结果如图5所示。

图5 相对颜色特征Figure 5.Comparative color feature
从图5可以看出,归一化之后的L、A、B仍然可以清晰表达各类图像的特征。叶黄病图片颜色较浅,L分量最大,叶枯病图片背景颜色较深L分量均值小于健康图片;A分量保存的是红绿变化,开花图片中红色区域面积最大A分量最大,健康图片绿色区域面积最大A分量最小;B分量保存黄蓝变化。褐斑病图片总体颜色偏黄B分量数值最大,如果使用其它图片B值会有所下降,开花图片黄色成分最少B分量为负数,可见颜色特征的处理对于图像识别率有很大影响。
为增强颜色特征的表现力,实验进一步提取图像空间信息[15-17]。综合SURF特征、LAB特征以及空间坐标的差值,实验将坐标值归一化为-0.5~0.5以实现空间特征与颜色特征的融合。具体步骤为:
步骤1提取图像像素点坐标L(xi,yi) ;
步骤2将L(xi,yi)放入函数A,归一化为-0.5~0.5;A的计算式为
(3)
式中,i为元素的位置;xi为第i个像素点的坐标;f(xi)表示横坐标的相对值;f(yi)表示纵坐标的相对值;yi表示第i个像素点的纵坐标。
步骤3将第2步所得结果分成2个列向量与LAB特征矩阵合并,经式(2)处理形成空间颜色聚合向量,结果如图6所示。
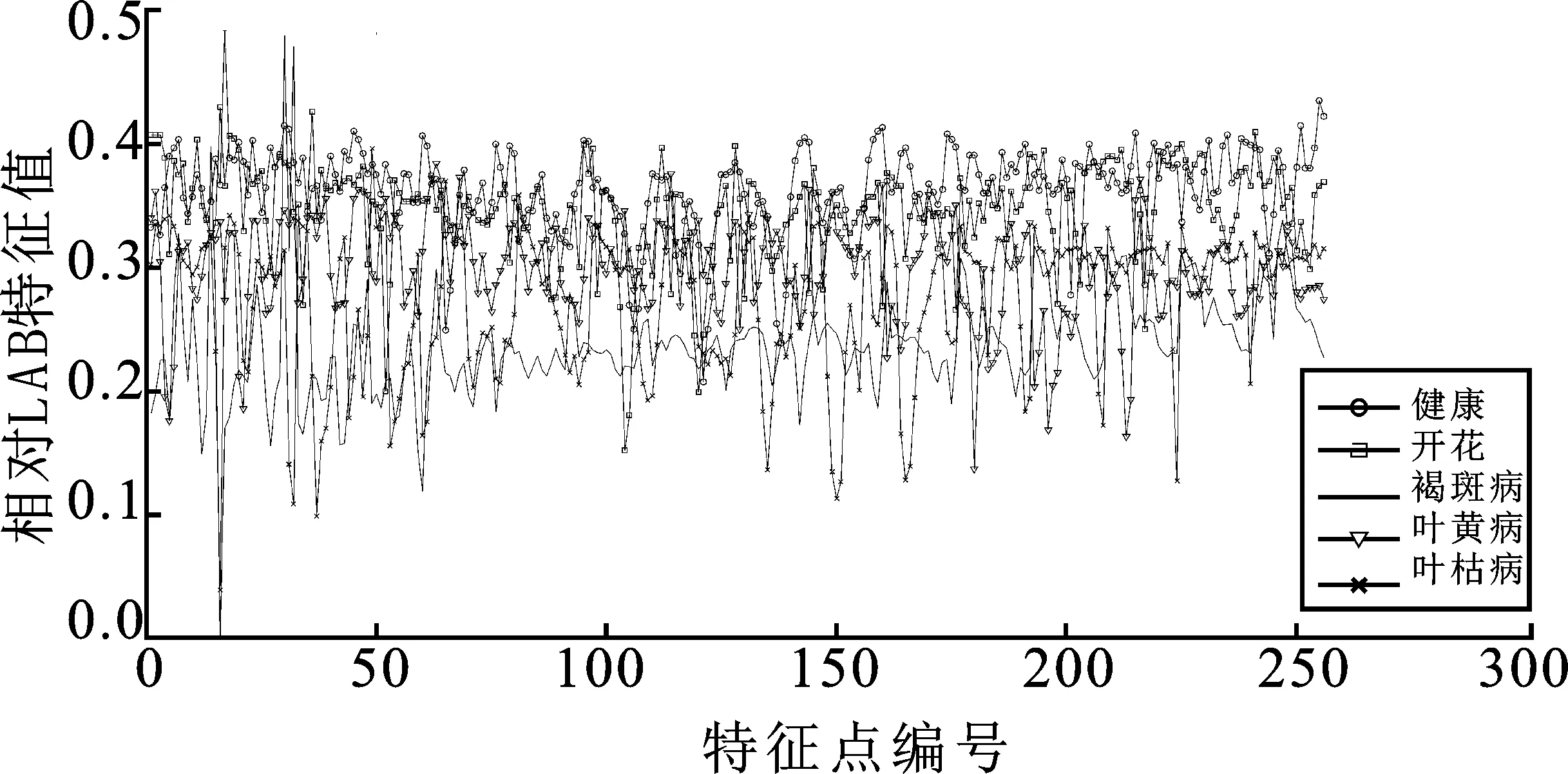
图6 部分样本的空间颜色聚合特征折线图Figure 6.Line chart of the spatial color feature of some samples
2.3 特征归一化
实验中,图像空间颜色特征值远大于SURF特征值,如果直接将特征矩阵进行合并放入分类器,空间颜色特征将完全覆盖SURF特征,SURF将失去使用价值。
传统特征组合方法主要是基于特征矩阵直接求和或者加权求和的方法融合多个特征。对样本中各区域数据进行平均或加权求和之后,表示多变信息的数据将被核函数“过滤”,导致最终的特征信息不完整,降低分类器的准确率[11]。综合以上问题,本研究采用3个不同的函数分别学习对应特征,使数据具有不同角度的特征。颜色特征和SURF特征同时映射到新的特征矩阵的两个元素中,形成视觉单词表,有效减少了特征损失,增加了分类准确率。
3 实验结果与分析
3.1 实验环境
实验采用的计算机环境是Windows10 64位操作系统,基于×64的处理器,CPU是Intel(R) Core(TM) i5-8250 CPU @1.60 GHz 1.80 GHz,内存4 GB,编程语言为MATLAB,软件采用MATLAB 2016a。
3.2 实验数据
样本数据来源于HM3S手机800W智能后置摄像头不同角度拍摄的图片。样本的采集分为:幼苗期、生长期、开花期,针对叶枯病、褐斑病、叶黄病、健康、幼苗、开花及其它等类别,拍摄植株叶片图像和花朵图像;采集时间为12:00、14:00、18:00;拍摄距离为0.05~1 m;天气情况分为晴天和多云;拍摄地点为无锡市;拍摄季节为春天至夏天。经过多次筛选,选出8种类型共计150张具有代表性的样本图片。经过预处理生成750张128×128大小相同的样本,如图3所示。
3.3 实验结果
实验采用的改进式BoF算法中提取的SURF特征为32维,提高样本训练效率的同时保证了分类器的识别率。图7详细描述了实验所采用的改进式BoF在不同样本数量的情况下,预测试识别率与验证集准确率的变化。

图7 改进式BoF预测试识别率与实际识别率Figure 7.Improved BoF pre-test recognition rate and actual recognition rate
由图7可以看出,在训练样本很少的情况下预测试准确率98%,实际准确率只有20%,假匹配现象严重,不可使用。随着样本数量的增加,识别准确率逐渐提高。当样本>200时,识别率损失趋向于0,实验所采用的空间颜色聚合特征对于样本的分类具有很大帮助,结合特征处理算法,最终识别率90.6%,相对于其它图像检索算法识别率有了明显提高。
图8为不同样本数量条件下,验证集准确率的变化情况。BoF+SURF算法中提取的SURF特征为64维,数量庞大,超出了硬件平台计算能力。尽管实验中不断加入新的样本,识别率仍然没有明显提高。BoF+SIFT算法计算速度最慢,且识别率变化较小。改进式BoF所使用的空间颜色聚合矩阵A[256,5],SURF特征32维,特征值数量少。增加样本时,矩阵A与矩阵SURF的特征值数量逐渐变得丰富,当样本数量大于150时,特征值分界线明显,识别率迅速增加。由此可见,在样本数量少、硬件平台计算能力较弱的情况下,改进式BoF仍然可以获得较高准确率。
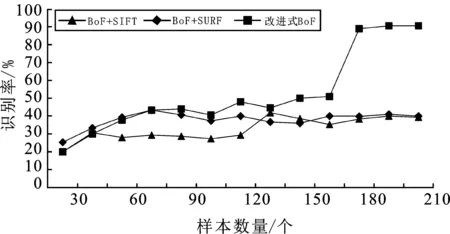
图8 不同训练数据下的识别率Figure 8.The recognition rate under different numbers of samples
实验将样本图像放入不同的分类模型进行分类对比。表1是改进式BoF、BoF模型+SIFT算法提取纹理特征、BoF模型+SURF算法提取纹理特征、CNN等方法的预测试结果。

表1 本文方法与其它方法对比Table 1. Comparison of different methods
由表1可以看出,BoF+SURF识别率高于本文所使用的改进式BoF,但是执行时间多了1.41 s。由于实验使用的样本图像尺寸较小,提取的特征值数量很少,导致CNN识别率未达到预期的水平,容易产生假匹配现象。BoF图像分类模型和SIFT特征提取算法的计算速度较慢且识别率较低。综合执行效率和识别率等多种元素,改进式的BoF更适用于细粒度图像分类。
4 结束语
为了快速识别杜鹃花植株的各主要生长期以及病害情况,实验采用了基于LAB的颜色聚合向量的改进式BoF模型,通过融合颜色特征和SURF特征实现图像分类。实验结果表明:(1)基于LAB模式下的空间颜色聚合矩阵代替传统的颜色量化方法对于颜色特征差距较小的图像库检索效果明显,可移植到嵌入式系统,具有较好的鲁棒性;(2)经过特征归一化,充分利用图像的各类特征,将SURF特征与颜色特征线性融合,有效提高了识别率。
经过多次测试发现,试验所采用的改进式BoF存在一个缺陷:当训练样本超出最大值时,图像分类会出现过拟合,因此样本的选择非常重要。
