西南油气田数据湖入湖技术研究
2021-01-07陈柯宇吕昕蓓
陈柯宇,吕昕蓓,孙 韵,秦 超
(中国石油西南油气田分公司通信与信息技术中心,四川 成都 610051)
0 引言
西南油气田分公司经过多年的信息化建设,积累了大量的系统与数据,目前面临着“信息系统多、数据库多、孤立应用多”的三多局面,亟需开展数据湖的建设,实现A1、A2、A4、A5等统建系统和勘探开发成果数据采集系统、作业区数字化管理平台、页岩气共享平台等分公司核心自建系统的共享数据和油田特色数据入湖,打破数据壁垒,实现数据共享,并与集团总部主湖构成连环湖架构,最终实现和主湖数据逻辑统一、分布存储、互联互通、就近访问的目标。
1 技术方案
1.1 结构化数据入湖
结构化数据共享存储采用MPP(大规模并行处理器Massively Parallel Processor)数据库技术,能够将任务均衡分解到多个节点同时进行运算,有效的解决了大规模的数据作业计算,缓存和IO带来的性能问题[1]。
结构化数据入湖前需要先开展数据模型的建设和主数据入湖。各数据源系统的数据通过ETL工具,汇聚到数据湖的贴源层,在贴源层进行归一化处理后,数据推送至数据治理区,进行业务质控审核,审核通过的数据进入到共享存储层,再推送至分析层,实现数据入湖。
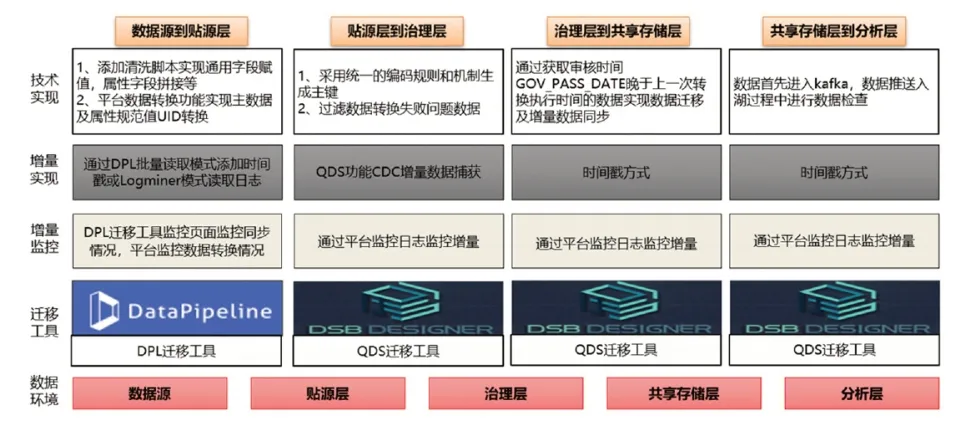
图1 结构化数据入湖
1.2 非结构化数据入湖
数据湖中非结构化数据存储,采用基于S3(简单存储服务Simple Storage Service)标准协议的软件定义分布式文件存储架构,主湖主控保证逻辑统一,用户基于统一的RESTful服务访问文件内容,支持软件定义数据多镜像与就近访问,满足地震等大块数据存储与高效应用[2]。
非结构化数据包括物探数据体、测井曲线和文档文件三类,按照存储方式可分为文件索引部分(文件名称、文件大小、作者等)和文件体部分(数据文件本身)。
(1)文件索引入湖:源数据索引通过DSB同步到FSS管理库,源数据管理库变更触发DBZ产生变化数据,处理程序1将DBZ产生得变化数据,变换格式后推送到RabbitMQ,处理程序2将RabbitMQ数据推送到ElasticSearch。
(2)文件体入湖:处理程序把数据体从源数据存储同步到数据湖的对象存储,同步配置对象存储集群同步策略,文件自动从数据湖对象存储同步到总部对象存储。
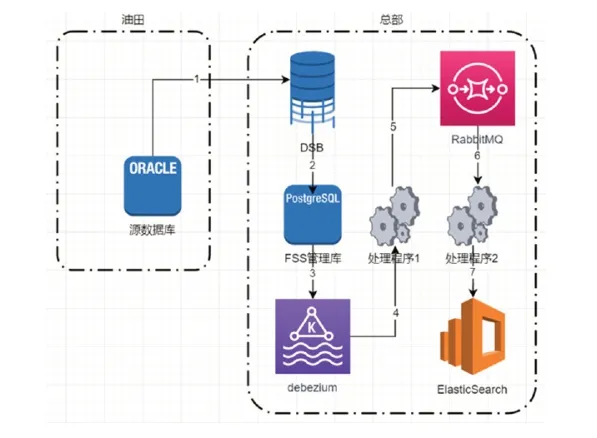
图2 非结构化数据入湖
1.3 时序数据入湖
数据湖时序数据存储,采用主流时序数据库技术,通过使用Kakfa开展时序数据流接收,清洗,标记,分析等功能。来源数据进入Kafka中,通过各种订阅进行处理;通过Hadoop 对历史数据进行保存;处理程序对时序数据整理标记,按照模型进行数据映射;挂接流处理引擎,对数据进行处理分析;标记后的时序数据进行写入数据湖中时序库保存,并进行查询应用。
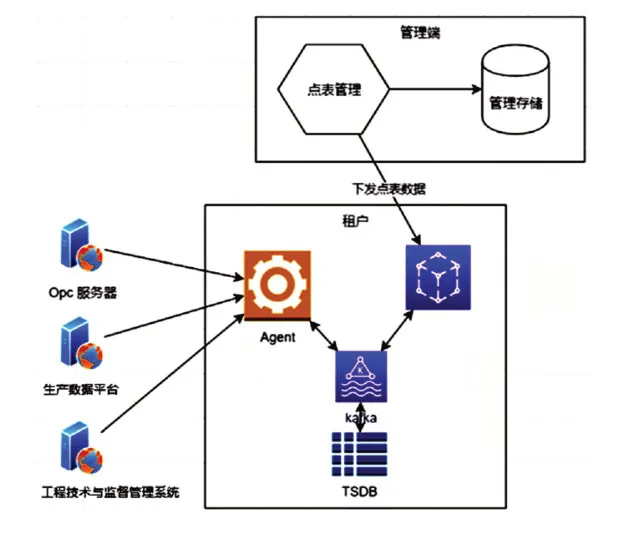
图3 时序数据入湖
2 应用效果
建立数据入湖形象进度展示模式,以地质导航为驱动,按照西南油气田分公司、区块、小区块层层递进的方式对各层人员关注的已入湖数据情况进行数据资产可视化展示,包括油田数据总体概览、基本实体的数量以及非结构化文档的展示等。

图4
3 结束语
针对不同类型的数据,采用成熟的技术,设计具有可操作性的数据入湖方案,保证数据能够全自动、无缝入湖。数据入湖经过实践,取得了良好的应用效果,对实现数据标准的统一,提升数据质量,支持数据共享,改变油田有数据无资产的被动局面具有重要的意义。
