基于特征聚合的新闻拆条
2021-01-07吴纲
吴 纲
(辽宁省广播电视及信息网络视听节目监测台,辽宁 沈阳 110000)
0 引言
随着移动互联网的蓬勃发展,碎片化式新闻内容传播更符合当下市场发展的需求。电视新闻节目逐渐开始采用“分段”的传播方式,即将一个完整的新闻视频依据内容进行拆分,从而形成短小、完整的新闻片段。
本文结合传统方法和前沿的人工智能研究成果,创新性地提出了一种特征聚合新闻拆条的办法,设计并实现了面向电视新闻节目的智能拆条软件系统,具有小样本、无需标注、识别速度快、准确率高的优点,快速智能地把一个长视频,按照新闻内容分成一个一个独立的新闻。系统通过机器学习系统,对特定的视频进行学习之后,就可以对同类型的视频进行自动拆条,大大提高了工作效率,有效地提高了新闻的传播速度。
1 新闻拆条常用技术
(1)转场识别:是在收录素材迁移的环节进行,通过底层识别库自动抽取素材转场帧来辅助快速定位片段切点,节省了拆条时 seek素材的时间,尤其对新闻类节目的拆条效率有很大提升。拆条客户端在执行拆条素材审核时,会根据数据库中记录的素材信息,自动加载素材对应的转场帧,用户可直接对转场帧进行操作。对于收录素材的边采边编,刷新素材的同时也实现了转场帧的刷新加载。
(2)人脸识别技术:主要应用于新闻主持人画面的精确定位,为后续智能处理区分主持人画面和其他画面提供基础数据。
(3)字幕识别技术:节目画面中往往已经有编辑好的标题,可以直接用于拆条后素材片段的标题。使用字幕识别技术,拆条系统只需要框选需要识别的标题画面,系统会自动将画面识别成标题文字,简单快捷。
(4)画面识别技术:通过画面识别技术,智能处理分析可以准确定位识别素材属于哪档节目,准确定位节目的开始位置。
(5)语音识别技术:语音识别模块通过对指定音频通道的音频基带信号进行解析,按照语音断句记录每个识别语句的起始时码、结束时码和识别的文本,识别结果会在物理素材的同目录下生成一个和物理素材同名的txt文档。拆条系统将此识别结果封装成字幕文件,并和素材的其他数据信息一同存入数据库的素材信息表中。
2 传统拆条系统问题
2.1 标注繁琐
标准的内容包括主持人标注和 OCR标注:
(1)主持人标注:需要人工标注视频中的主持人人脸,用来帮助图像算法关键帧,进而切割视频。
(2)OCR标注:用来画出新闻视频中常出现的标题版位置和大小,以确定新闻标题。
系统建设初期就需要标注一遍,并且每次新闻人员流动和频道改版都需要重新维护,一个省级的新闻监管中心往往有大约 30个左右的地方台,长期维护成本高昂。
2.2 切割不准
基于图像的方法(转场识别、人脸识别)在视频端点处往往会出现误判,导致切割不准,严重依赖人工编审修正过程。
2.3 计算速度慢
随着视频普遍高清化,原始视频文件也变得越来越大,传统拆条系统的性能不足以满足高速处理的需求,为了确保新闻能第一时间在新媒体渠道上发布,往往依赖人工手段解决,费时费力。
2.4 语音识别效果差
地方性的新闻内容口音现象是普遍现象,通用的语音识别引擎需要大量数据训练(>1,000小时)后才能有较好的效果。而实际中一年也仅能产生大约200小时不到的数据,语音识别引擎字幕翻译效果很差,进一步给内容监管造成了很大的困难。
3 特征聚合新闻拆条原理
首先获取需要进行拆条的原始视频文件,然后经过粗拆阶段以及细拆阶段拆分为多个新闻片段,同时提供人工变身模块用于对系统拆分结果进行修订。
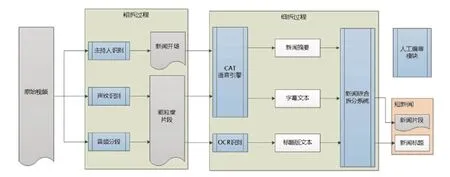
图1 基于特征聚合的新闻拆条流程
3.1 粗拆阶段
基于主持人识别、声纹识别和音频分段技术,快速确定主持人和新闻内容的大致分段。
(1)对于收集到的原始视频,首先通过预处理提取音视频信息。
(2)利用主持人在新闻节目中出镜率高的特点,先通过声纹识别、主持人脸识别技术快速明确节目主持人。
(3)结合人脸识别和音频端点检测技术,根据主持人播报的时间对视频进行粗拆。
大部分新闻节目都会有新闻介绍,所以我们把主持人集中播报的第一段粗粒度视频单独提出来作为新闻开场单独进行后续分析。
3.2 细拆阶段
通过综合运用语音识别、 OCR识别和 NLU技术,实现对大段内容的精细化拆分,并生成每段新闻的标题。
最终新闻识别率可达 99%,分割误差在1 s内。得到的短新闻送给人工编审模块,以方便用户发布修正,并做部分数据回流。
粗拆出来的视频是相当不精确的,除了起止时间不够准外,经常含有多条新闻内容,所以有必要进行进一步的拆分。
(1)我们先把所有的视频送到语音识别引擎中进行语音识别,采用清华大学基于 CRF-CTC[1]技术的新一代语音识别引擎,在小样本集上表现优异,非常适合这个场景。
(2)粗粒度的片段通过语音识别引擎可以生成字幕文本。新闻开场可以生成新闻摘要,供后面的NLU分析做参考。
(3)同时粗粒度片段进行关键帧的OCR识别,获得标题板文本。
(4)把得到的标题版文本,字幕文本和新闻摘要送入新闻综合拆分系统。
3.3 综合拆分系统
三种输入数据有以下特点:
(1)文本字幕:不够精确,并且有大量无意义的采访人字幕。
(2)OCR识别:无关背景干扰,无关的内容(采访人信息),采访字幕等。
(3)新闻摘要:总结性好,但粒度太大。
新闻综合拆分系统的工作原理如下:
(1)首先对数据进行一些预处理,去除标题版文本中和字幕文本的冗余信息。
(2)然后对文本字幕进行语义分割,分段的结果通过和标题版文本进行差分比对去除字幕内容,得到备选标题和权重,再对新闻摘要进行学习,调整备选标题权重,得到最终标题;对于无明显标题的小新闻,通过文本摘要生成一个标题。
(3)确定了文本内容分段后,根据文本起止的时间,对视频的切割点进行修正,得到细拆的新闻片段。
(4)新闻片段和标题一起构成短新闻存到知识库,配合人工编审模块提供人工修正;人工修正的结果回流到语义拆分系统的 NLU模块进行模型修正,以提升拆分准确率。
表1是各种方法各个数据集上的 F值横向对比,可以看到特征聚合的方法远优于传统办法或者端到端方法。迁移性强,数据要求低。
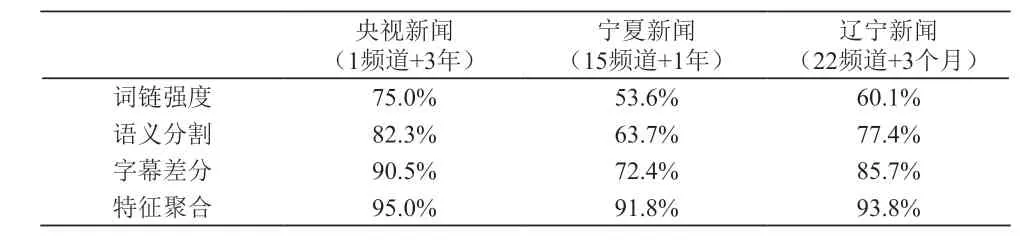
表1 拆条准确率对比表
4 结束语
通过特征聚合技术的新闻拆条,能够在新闻快速生产过程中非常迅速地实现对新闻的拆条,并同时对新闻标题字进行识别,大大提高了工作效率。
